Redis 通用命令

Redis 重要文件及作用
启动/停止命令或脚本
-
/usr/bin/redis-server:Redis 服务器程序。 -
/usr/bin/redis-check-aof->/usr/bin/redis-server:修复 AOF 文件的工具。 -
/usr/bin/redis-check-rdb->/usr/bin/redis-server:修复 RDB 文件的工具。 -
/usr/bin/redis-sentinel->/usr/bin/redis-server:Redis 哨兵程序。 -
/usr/bin/redis-cli:命令行客户端程序,学习阶段频繁使用。 -
/usr/bin/redis-benchmark:对 Redis 进行性能基准测试的工具。 -
/usr/libexec/redis-shutdown:停止 Redis 的专用脚本。
提示:相比直接使用这些命令,建议使用 systemd 托管的方式进行 Redis 的启动/停止。
配置文件
-
/etc/redis.conf:Redis 服务器的配置文件。 -
/etc/redis-sentinel.conf:Redis Sentinel 的配置文件。
持久化文件存储目录
-
/var/lib/redis/:Redis 持久化生产的 RDB 和 AOF 文件默认生成于此目录下。后续章节会观察持久化现象。
日志文件目录
-
/var/log/redis/:保存 Redis 运行期间生成的日志文件,默认按天分割,一定日期的日志文件会以 gzip 格式压缩保存。可使用任意文本编辑器打开,后续章节会通过日志观察现象。
Redis 命令行客户端
现在已启动 Redis 服务,接下来介绍如何使用 redis-cli 连接、操作 Redis 服务。客户端与服务端的交互过程如下图所示。
Redis 客户端与服务端的交互过程:
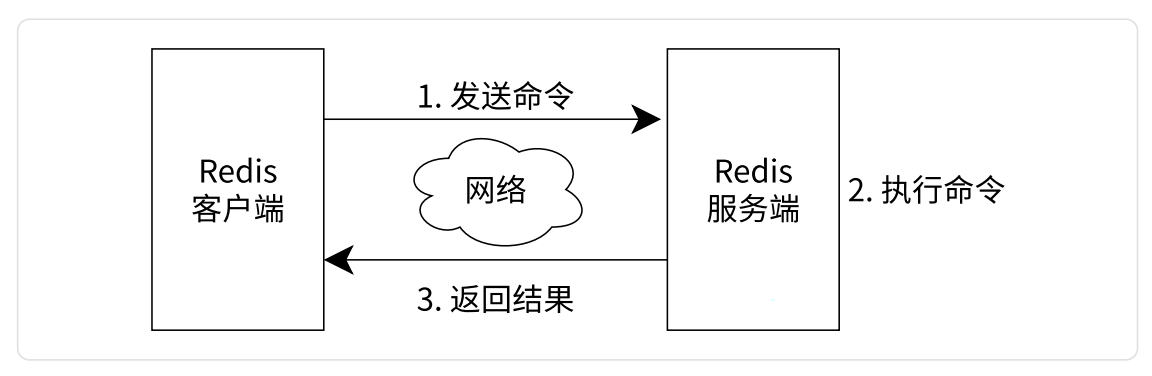
Redis 客户端和服务端可以在同一个主机上,也可以在不同主机上(当前阶段,我们一般只有一台机器,此时客户端和服务端就是在同一个机器上)
Redis 服务器本体是负责存储和管理数据的!
Redis 客户端与服务端的交互过程如下:
-
客户端发送命令。
-
服务端执行命令。
-
服务端返回结果。
redis-cli 可以通过以下两种方式连接 Redis 服务器:
-
交互式方式:通过
redis-cli -h {host} -p {port}连接到 Redis 服务,后续操作通过交互式实现,无需再执行redis-cli。例如:[root@host ~]# redis-cli -h 127.0.0.1 -p 6379 127.0.0.1:6379> ping PONG 127.0.0.1:6379> set key hello OK 127.0.0.1:6379> get key "hello" -
命令方式:通过
redis-cli -h {host} -p {port} {command}直接得到命令返回结果。例如:[root@host ~]# redis-cli -h 127.0.0.1 -p 6379 ping PONG [root@host ~]# redis-cli -h 127.0.0.1 -p 6379 set key hello OK [root@host ~]# redis-cli -h 127.0.0.1 -p 6379 get key "hello"
注意:
-
由于连接的 Redis 服务位于 127.0.0.1,端口为默认的 6379,可省略
-h {host} -p {port}。 -
redis-cli是学习 Redis 的重要工具,后续大量章节会用到它。redis-cli提供的更强大功能将在后续章节详细介绍。
Redis 的客户端也是有多种形态的,不仅仅是上面的自带了命令行客户端,还有图形化客户端(桌面程序,web 程序)
还有第三种形态:基于 Redis 的 API 自行开发的客户端【工作中最主要的形态!】
前面章重点回顾
-
Redis 的 8 个特性:速度快、基于键值对的数据结构服务器、功能丰富、简单稳定、客户端语言多、持久化、主从复制、支持高可用和分布式。
-
Redis 并非万能,有些场景不适合使用 Redis 开发。
-
开发运维结合以及阅读源码是用好 Redis 的重要方法。
Redis 通用命令
在正式介绍 5 种数据结构之前,了解 Redis 的一些全局命令、数据结构和内部编码、单线程命令处理机制是十分必要的,它们能为后面内容的学习打下一个良好的基础。主要体现在两个方面:
-
Redis 的命令有上百个,如果纯靠死记硬背比较困难,但是如果理解 Redis 的一些机制,会发现这些命令有很强的通用性。
-
Redis 不是万金油,有些数据结构和命令必须在特定场景下使用,一旦使用不当可能对 Redis 本身或者应用本身造成致命伤害。
通过 Redis-cli 客户端和 Redis 服务器交互,涉及到很多的 Redis 命令。不过我们只需要:
1. 掌握常用命令 --- 多操作,多练习
2. 学会使用 Redis 文档 --- 查看相关命令的用法 --- 中文文档
建议看英文!!!
Redis 中最核心的两个命令:set 和 get
Redis 是通过键值对的方式进行存储数据的,键值对无非就是存入键值对,然后通过简键值去取值。
set :把 key 和 value 存储进去。
get :根据 key 来取 value。
注意:这里的 key 和 value 都是字符串!
必须要先进入 redis-cli 客户端程序,才可以使用 redis!
对于 Redis 的命令是不区分大小消息的!
基本全局命令
Redis 支持很多种数据结构,有 5 种数据结构,但它们整体都是键值对中的值,对于键来说有一些通用的命令。
也就是说 Redis 整体是键值对结构,key 固定就是字符串,value 实际上会有很多种类型!(字符串,哈希表,列表,集合,有序集合......)--- 操作不同的数据结构,就会有不同的命令!!!
但是除了专用于操作某一种数据结构的命令之外,还会有一些命令,在上面着一些数据结构中都可以用得上的,这种就称为全局命令!!!
全局命令就是能够搭配任意一个数据结构来使用的命令!
keys --- 用来查询当前服务器上匹配的 key
KEYS 返回所有满足样式(pattern)的 key。支持如下统配样式。--- 通过一些特殊符号(通配符)来描述 key 的模样,匹配上述模样的 key ,这样就可以被查询出来!
-
h?llo 匹配 hello、hallo 和 hxllo --- 一个问好匹配任意一个字符
-
h*llo 匹配 hllo 和 heeeello --- " * "匹配任意0个或者多个字符
-
h[ae]llo 匹配 hello 和 hallo 但不匹配 hillo --- 只能匹配 [] 里面的任意一个字符
-
h[^e]llo 匹配 hallo、hbllo,... 但不匹配 hello --- 除了[]里面的字符,任意一个字符都可以!
-
h[a-b]llo 匹配 hallo 和 hbllo 语法 --- 匹配a到b的闭区间的字符
KEYS pattern
命令有效版本:1.0.0 之后 时间复杂度:O(N) 返回值:匹配 pattern 的所有 key。 示例:
redis> MSET firstname Jack lastname Stuntman age 35
"OK"
redis> KEYS *name*
1) "firstname"
2) "lastname"
redis> KEYS a??
1) "age"
redis> KEYS *
1) "age"
2) "firstname"
3) "lastname"因为需要遍历所有的key,所以时间复杂度是O(N)的,所以,在生产环境上,一般会禁止使用 keys 命令,尤其是大杀器 " keys * " ! --- redis 只是一个单线程的服务器,执行 redis 服务器就会被阻塞了,无法给其他客户端提供服务了!!!
Redis 经常会用于做缓存,挡在 MySQL 前面,替 MySQL 负重前行的人!万一 Redis 被一个 "keys *"命令阻塞住了,此时其他的查询 Redis 操作就超时了,此时这些请求就会直接查询数据库,这突然一大波请求过来了,MySQL 措手不及,就容易挂掉!
整个系统就基本瘫痪了,如果不及时恢复,年终奖就要没了!更严重,连工作带走都可能没了!
EXISTS 判断某/多个 key 是否存在。
EXISTS key [key ...]
命令有效版本:1.0.0 之后 时间复杂度:O(1) 返回值:key 存在的个数,是查询多个不同的 key 。 示例:检查到几个 key ,就是返回几!
redis> SET key1 "Hello"
"OK"
redis> EXISTS key1
(integer) 1
redis> EXISTS nosuchkey
(integer) 0
redis> SET key2 "World"
"OK"
redis> EXISTS key1 key2 nosuchkey
(integer) 2因为网络的封装分用的开销是有的,所以 Redis 支持一次进行多量的查询!
Redis 支持很多数据结构,其指的是一个 value 可以是一些复杂的数据结构,Redis 自身的这些键值对,是通过哈希表的方式来组织的!Redis 具体的某个值又可以是一些数据结构,简称套娃
DEL 删除指定的 key。
DEL key [key ...]
命令有效版本:1.0.0 之后 时间复杂度:O(1) 返回值:删除掉的 key 的个数。 示例:
redis> SET key1 "Hello"
"OK"
redis> SET key2 "World"
"OK"
redis> DEL key1 key2 key3
(integer) 2之前学习 MySQL 的时候,强调过,删除类的操作:
drop database;
drop table;
delete from ...
都是些非常危险的操作!!!一旦删除了之后,数据就没了!
Redis 相比于 MySQL 的删除操作的危险程度是比较低的,因为 Redis 常常被用作于缓存,作为缓存,此时 Redis 只是存放了热点数据,全量数据是存放在 MySQL 中的!删除几个 Redis 中的缓存数据影响是不大的,但是删除了一大半的数据,那就会有比较大的影响!
如果将 Redis 作为数据库,此时误删数据的影响就大了!!!
如果将 Redis 作为消息队列(mq),误删数据的影响就需要具体问题具体分析了!
EXPIRE 为指定的 key 添加秒级的过期时间(Time To Live TTL)。
EXPIRE key seconds
key 存活时间超过设置的指定的值,就会被自动删除!设置的时间单位是秒级的!
很多的业务场景是有时间限制的,就比如手机验证码:该验证码在5分钟内有效!
命令有效版本:1.0.0 之后 时间复杂度:O(1) 返回值:1 表示设置成功。0 表示设置失败。 示例:
redis> SET mykey "Hello"
"OK"
redis> EXPIRE mykey 10
(integer) 1
redis> TTL mykey
(integer) 10我们可以利用这个操作来基于 Redis 实现分布式锁! 为了避免出现不能正常解锁的情况,通常都会在加锁的时候设置一下过期时间(所谓的使用 Redis 作为分布式锁,就是给 Redis 里写一个特殊的 key value,删除掉就是解锁了!)
总的来所,过期时间还是很有用的!!!
pexpire 就是以微秒为单位了!!!
TTL 获取指定 key 的过期时间,秒级。
TTL key
在网络协议中---IP协议,IP协议报头中,就有一个字段:TTL,但是IP中的TTl不是用时间来衡量过期的,而是"跳一跳"的次数!
命令有效版本:1.0.0 之后 时间复杂度:O(1) 返回值:剩余过期时间。-1 表示没有关联过期时间,-2 表示 key 不存在。 示例:
redis> SET mykey "Hello"
"OK"
redis> EXPIRE mykey 10
(integer) 1
redis> TTL mykey
(integer) 10当然了,还有一个PTTL!对应PEXPIRE
Redis 的 key 的过期策略是怎么实现的?
一个 Redis 中可能同时存在很多 key ,这些 key 中有很大一部分都有过期时间,此时 Redis 服务器咋知道哪些 key 已经过期要被删除,哪些 key 还没过期?--- 经典面试题
如果遍历所有的 key,显然是行不通的,效率太低了!这是不科学的,也就是不应该有定时删除策略,Redis 整体的策略是两方面:
- 定期随机量删除:相比于惰性删除的机制,还需要一个辅助的机制,定期删除,但是每次不是全部遍历一遍,而是抽取了部分出来进行过期检测,保证检查的过程足够快!
- 惰性删除:假设 key 已经到了过期时间,但是暂时还没被删除,后面又一次访问,正好用到了这个 key,那么这次访问,就会让 Redis 服务器触发删除 key 的操作,同时再返回一个 nil !
是两种策略相结合使用的!
虽然有了上述两种策略结合,整体的效果一般,但是仍然可能会有很多过期的 key 被残留了,没有及时删除掉!这样就会占用内存,本来内存就不大!
Redis 为了对上述进行补充,还提供给了一系列内存淘汰策略!--- 这些比较复杂,我们后续详细探讨,目前要清楚过期策略!!
定时删除的策略 Redis 是没有采用的,并没有采取定时器的方式来实现过期 key 删除。太多的 key 就会导致过分占用CPU!主要还是每一个 key 就带了一个定时器,但是:
如果有多个 key 过期,也可以通过一个定时器来高效的/节省CPU的前提下来处理多个 key。
对于定时器,我们可以基于优先级队列或者基于时间轮来实现比较高效的定时器!
redis 采取定时器的方式其实也是可以比较高效的,只要不是通过每一个 key 就设置一个定时器,但是 redis 没有采取这种定时器的方式可能是还有其他的原因的,但是很难考证为啥,个人认为:基于定时器实现,势必就要引入多线程,redis 早期版本就是奠定了单线程的基调 --- 引入多线程就打破了作者的初衷。
定时器的实现:在某个时间到达之后,执行指定任务:
1.基于优先级队列/堆
正常的队列是先进先出,优先级队列则是按照指定的优先级,先出,这个优先级的说明是自定义的。在 redis 过期 key 的场景中,就可以通过“过期时间越早,就是优先级越高”!
现在假设有很多 key 设置了过期时间,就可以把这些 key 加入到一个优先级队列中,指定优先级队列规则则是过期时间早的,先出队列。
队首元素,就是最早的要过期的key!
此时定时器中,只需要分配一个线程去检查队首元素是否过期即可!!!如果队首元素没有过期,后续元素一定没过期!这时候扫描线程就不需要遍历所有的 key!
另外,在扫面线程检查队首元素过期时间的时候,也不能检查得太频繁,导致有时候的白等!此时的做法就是可以根据当前的时刻喝队首元素的过期时间,设置一个等待时间,就相当于这个检查线程被阻塞一个等待时间!等有新 key 的过期时间被设置了,可以让新任务添加的时候,唤醒线程,再重新同上的操纵(假设队首的元素的过期时间是1:00,当前时刻是00:00,那么这个等待时间就将近1小时,到了等待时间再将线程唤醒)这样也就节省了CPU的时间!
2.基于时间轮(可看文章)
把时间换分成很多小段,具体的划分粒度,看实际需求!然后将划分好的小段放在一个圆环上:
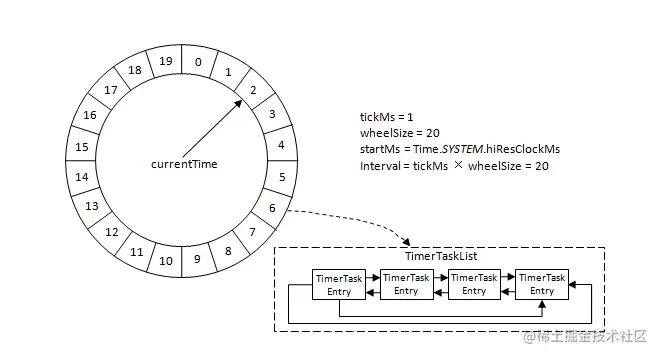
currentTime 这个指针往一定的方向进行旋转,圆环上的每一个小段都是一个链表 TimerTaskList ,每个链表都代表一个要执行的任务(相当于函数指针,以及对应的参数.../函数对象),假设每一段的粒度是 100ms,此时需要添加一个 key,这个 key 在 300ms 之后过期,那么就会添加在3好格子内,挂在对应的列表上,此时 currentTime 指针就会每隔固定的间隔(100ms),每次走到一个格子,就会把这个格子上链表的任务尝试执行一下!是尝试,因为如果指定的过期时间特别特别长,那么就会取模去放入对应的格子内,到时间就删除,没到就等下一次了!
在 Redis 源码中,有一个比较核心的机制,是时间循环,和时间轮有点像。
TYPE 返回 key 对应 value 的数据类型。
TYPE key
命令有效版本:1.0.0 之后 时间复杂度:O(1) 返回值:none、string、list、set、zset、hash 和 stream( redis 作为消息队列的时候,使用这个类型的 value)。 示例:
redis> SET key1 "value"
"OK"
redis> LPUSH key2 "value"
(integer) 1
redis> SADD key3 "value"
(integer) 1
redis> TYPE key1
"string"
redis> TYPE key2
"list"
redis> TYPE key3
"set"本小结只是抛砖引玉,给出几个通用的命令,为 5 种数据结构的使用做一个热身,后续章节将对键管理做一个更为详细的介绍。