检索增强型生成助力无人机精准数学推理!RAG-UAV:基于RAG的复杂算术推理方法

作者:Mehdi Azarafza, Mojtaba Nayyeri, Faezeh Pasandideh, Steffen Staab, Achim Rettberg
单位:Hamm-Lippstadt应用科学大学计算机科学系,斯图加特大学人工智能研究所
论文标题:Mathematical Reasoning for Unmanned Aerial Vehicles: A RAG-Based Approach for Complex Arithmetic Reasoning
论文链接:https://arxiv.org/pdf/2506.04998
代码链接:https://github.com/Mehdiazarafza/UAV-RAG
主要贡献
提出了RAG-UAV框架,改善无人机(UAV)场景中大型语言模型(LLMs)的数学和物理推理能力。
构建了UAV-Math-Bench问题集,包含20个UAV中心数学推理问题的分类问题集,涵盖四个难度级别,用于初步评估。
通过实验比较了RAG增强型和非RAG LLM(如ChatGPT-Turbo)的性能,量化了在不同模型和问题复杂度下,答案准确性、公式选择和数值误差的改进。
证明了RAG在更复杂、多步骤问题上能带来显著的性能提升,验证了其在增强基于LLM的工程分析方面的潜力。
研究背景
无人机(UAV)的应用与挑战:
无人机在监视、测绘、运输和应急响应等多个领域有广泛应用,其自主任务需要多步骤的数学推理,如在变化的风中重新规划蜂群时平衡能量预算。
然而,现有的飞行控制代码只能处理固定的方程,工程师仍需花费时间查找正确的空气动力学、通信信道或功耗公式,并检查算术运算,这一过程需要扎实的物理、系统工程和领域特定公式的理解以及可靠的数学推理能力。
大型语言模型(LLMs)的潜力与局限性:
LLMs在物理相关文本和无人机设计文献上进行了预训练,能够协助工程师识别相关方程、提出性能评估策略、验证推理步骤,甚至自动化部分无人机规划和分析工作。
但它们也存在局限性,如预训练数据的静态性可能导致缺乏对最新领域特定文档、标准或实验数据集的访问,且可能会“幻觉”出看似合理但错误的方程或假设,尤其是在面对技术边缘案例或不完整的提示时。
研究方法
RAG-UAV框架
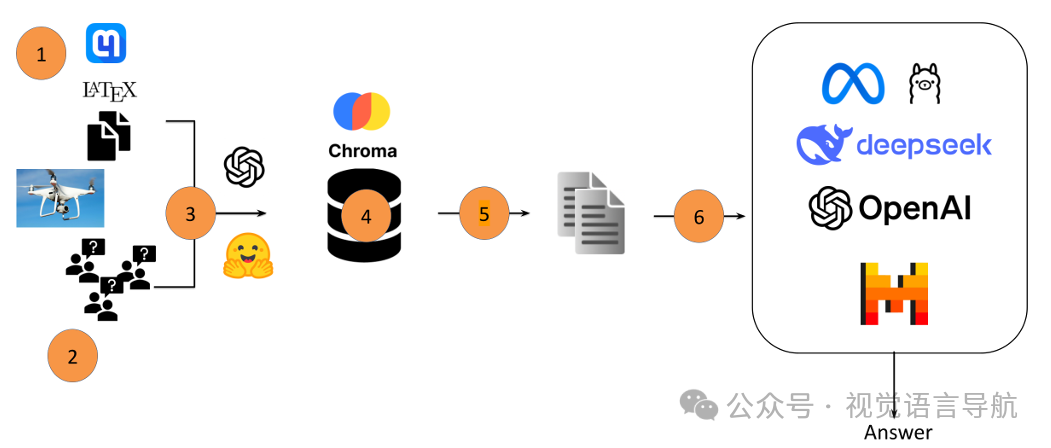
论文提出 RAG-UAV 框架,旨在通过检索增强型生成(Retrieval-Augmented Generation, RAG)的方式,为大型语言模型(LLMs)提供特定领域的数学知识,以增强其在无人机(UAV)场景中的数学和物理推理能力。该框架的工作流程如下:
用户查询输入:用户输入一个与无人机相关的数学问题。
查询嵌入:将查询嵌入到一个向量表示中,使用选定的嵌入模型。
相似性搜索:利用查询嵌入,在包含无人机文献文本片段的向量数据库中进行相似性搜索。
检索相关文本片段:检索出与查询最相关的文本片段。
构建增强提示:将检索到的文本片段与原始用户查询结合,生成一个结构化的提示。
LLM生成响应:将增强后的提示输入到LLM中,LLM生成包含数学问题解决方案的响应。
构建无人机的向量数据库
为了构建知识库,论文使用了五篇与无人机数学建模相关的研究论文。具体步骤如下:
文档处理:最初尝试直接将PDF文档输入到模型中,但发现模型输出中的错误是由于PDF解析不准确,而非模型本身的推理能力不足。因此,论文使用 Mathpix2 将PDF文档转换为LaTeX格式,以更准确地捕获数学公式。
文本分割:将LaTeX输出分割成页面级别的片段,共得到162个片段。
嵌入与存储:使用两种不同的模型对这些片段进行嵌入:
all-mpnet-base-v2(768维):用于开源LLM。
OpenAI的text-embedding-ada-002(1536维):用于OpenAI模型。 嵌入后的向量表示存储在 Chroma 向量数据库中。
LLM提示策略
为了查询LLM,论文设计了一个提示模板,该模板结合了原始问题陈述和检索到的文本片段。具体策略如下:
- 提示模板:模板指令模型仅使用提供的文档来识别相关公式,但允许模型利用其内部能力进行数值计算。模板结构为:
Use only the provided documents: [Retrieved Documents]. Question: [Original Question]. 策略目的:这种策略旨在隔离检索对公式选择的影响,同时允许LLM利用其固有的算术能力进行计算。它也反映了现实世界中的一种潜在用例,即LLM可能被提供领域知识,但仍依赖其内部计算引擎。
UAV-Math-Bench:评估问题集
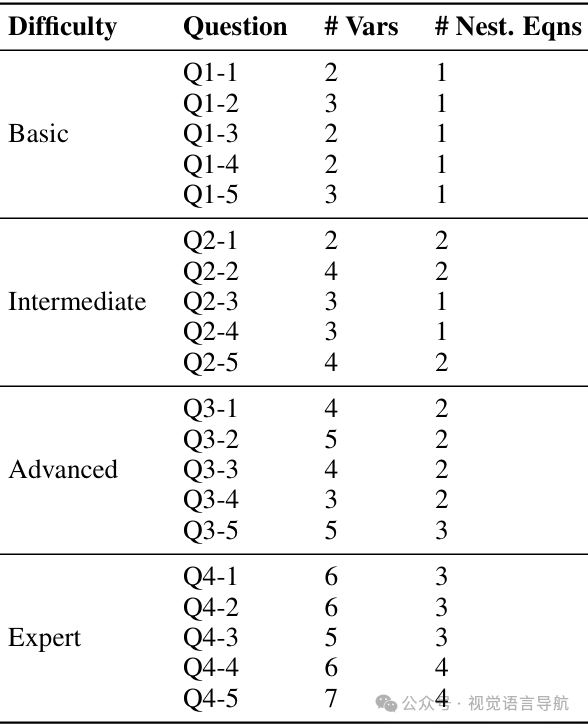
为了评估模型在解决无人机相关数学问题上的复杂性和推理能力,论文构建了一个名为 UAV-Math-Bench 的问题集,包含20个数学问题,分为四个难度级别:基础、中级、高级和专家级。每个级别的问题具有不同的特点:
基础级别问题:需要基于给定参数进行直接计算,通常涉及简单的数学公式,不需要广泛的领域知识。
示例问题:Computation of elevation angle speed based on coordinate positions.
中级级别问题:需要额外的步骤,如概率计算或对数变换,涉及中等水平的工程知识和数学公式。
示例问题:Probability computation of a line-of-sight (LoS) connection based on given probability constants.
高级别问题:涉及多步骤问题解决方法,需要整合多个数学原理,需要对信号处理、空气动力学和无线通信概念有扎实的掌握。
示例问题:Path loss calculation for a LoS connection incorporating frequency and speed of light.
专家级别问题:需要广泛理解多个概念,并将其整合到一个单一的计算框架中,通常需要优化、迭代解决方案或高级概率和统计分析。
示例问题:Average path loss computation involving LoS and NLoS path loss models.
实验
评估指标
精确答案准确率:衡量模型产生与专家提供的真实答案精确匹配的最终数值答案的百分比。
公式选择错误率:量化模型选择错误数学公式或未能从上下文中识别出任何相关公式的百分比。
均方误差(MSE):计算模型最终数值答案与真实答案之间的MSE,由于模型输出和真实答案之间的差异可能很大,因此使用log10(MSE)进行结果报告,以便更清晰地可视化。
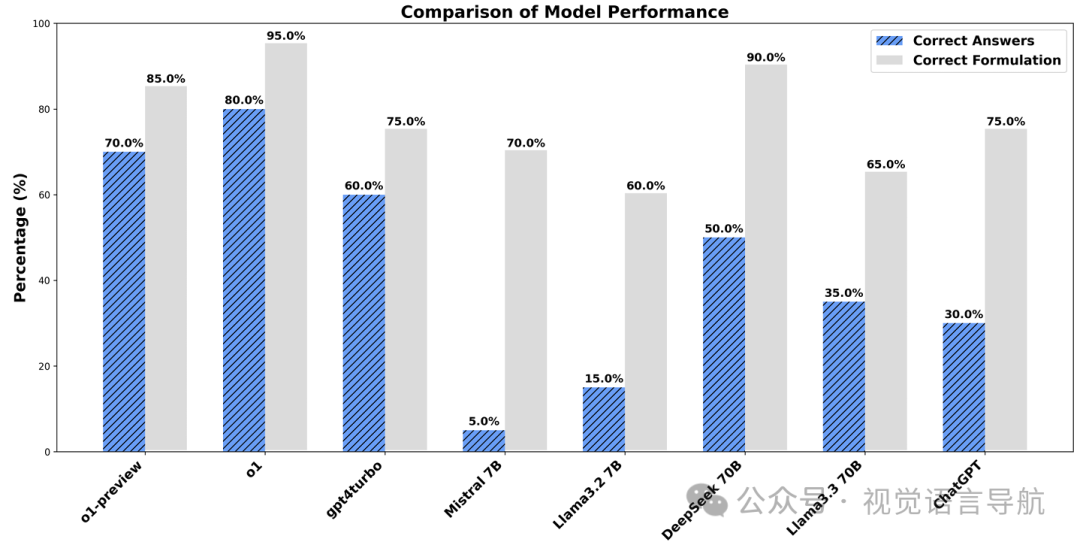
模型性能比较

在所有模型中,o1模型表现最佳,其正确答案率为75%,计算错误率最低。o1模型能够一致地识别正确的公式,并计算出接近参考答案的值,因此与其他模型相比,其MSE显著较低。
Mistral 7B和LLaMA 3.2 3B等模型给出的大多是错误答案,并且犯了很多错误。
DeepSeek 70B和LLaMA 3.3 70B给出的答案比小模型更准确,DeepSeek的错误更少,被认为是本次评估中最佳的开源LLM模型。
ChatGPT-4-Turbo(无RAG)和Turbo(有RAG)处于中间位置,它们可以回答一些问题,但经常计算错误。
按难度级别划分的性能

o1模型在所有难度级别上均实现了最高的准确率,即使在专家级问题上也达到了80%的准确率。
大多数模型在基础问题上表现良好,但在更难的级别上表现显著下降。
Mistral 7B和LLaMA 3.2 3B等模型整体表现较差,尤其是在高级和专家级任务上。
ChatGPT和DeepSeek R1显示出中等准确率,但只有o1模型在所有级别上都保持了一致的高准确率。
注意力模式的检查
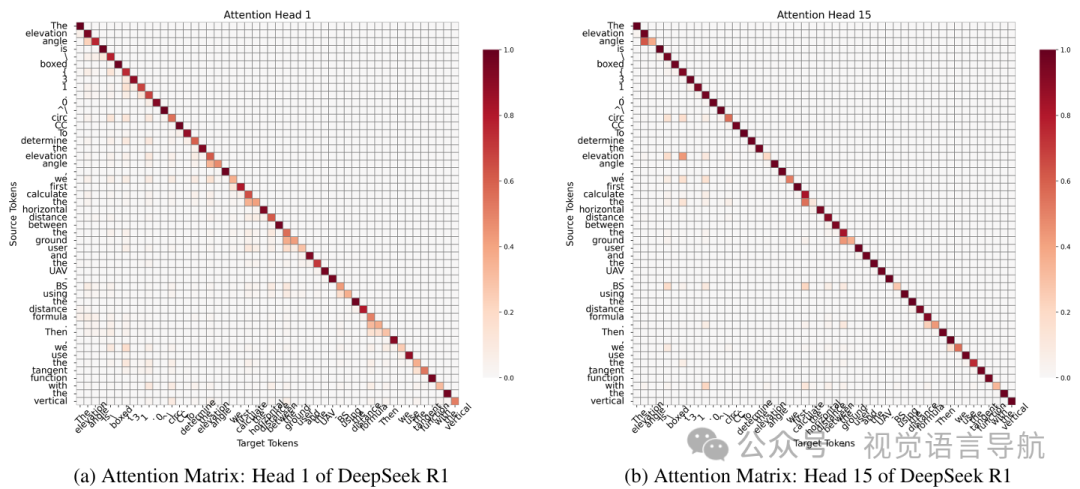
通过可视化DeepSeek R1模型第一层的注意力模式,初步了解其如何处理输入并可能利用信息。
结果显示,模型在生成序列中显示出相似的对角线和局部注意力结构,并且在计算过程中会关注输入中的相关数值标记。
结论与未来工作
结论:
检索增强型生成(RAG)可以显著提高大型语言模型(LLMs)的数学推理能力,尤其是在涉及多步骤和嵌套操作的问题上,RAG有效地减少了独立LLMs在复杂数学任务上常见的失败模式。
尽管该研究使用的基准规模较小,但结果表明,RAG在使LLMs成为无人机开发等技术领域中更可靠的工程分析工具方面具有显著潜力。
未来工作:
该研究的发现受到其小规模基准的限制,未来需要对RAG框架的延迟、计算成本和实时性能进行严格的评估。
此外,由于安全关键的考虑,LLMs直接集成到无人机的自主决策过程中的可行性仍需要进一步的研究和验证。
