从env到mm_struct:环境变量与虚拟内存的底层实现
一、命令行参数
1. main函数可以有参数吗?可以有几个参数?是哪几个?
不知道大家有没有见过这样的main函数?

我们来介绍一下它。
第一个参数 int argc 代表的是char* argv[]元素的个数,第二个参数char* argv[]指向一个个字符串的指针数组。我们来验证一下。
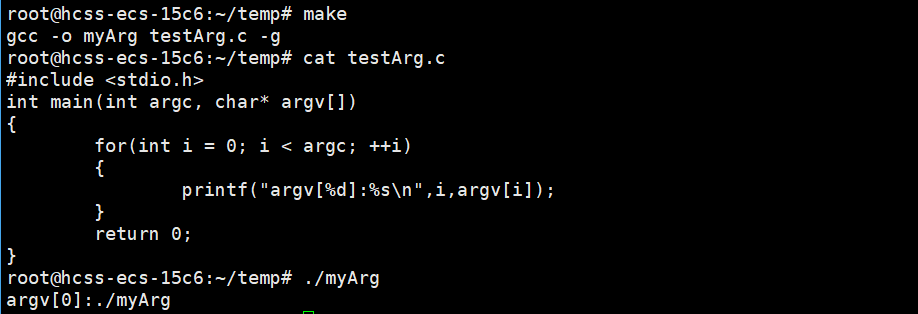
它里面存的竟然是命令行参数。那我们再试一次。
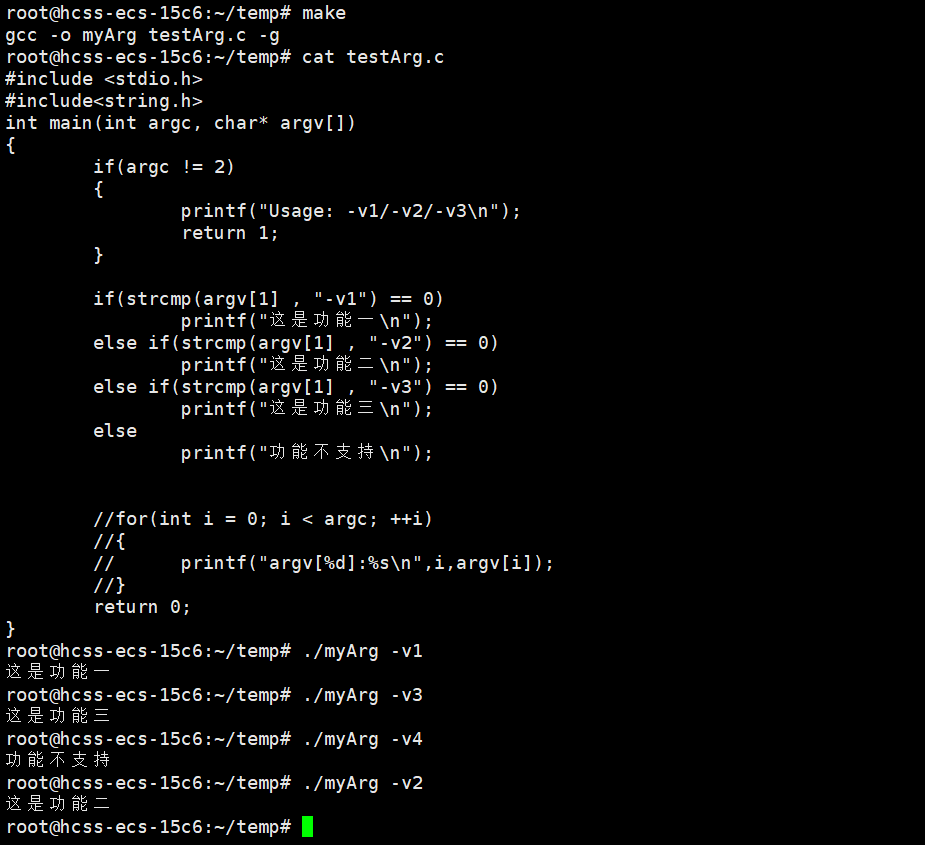
2.为什么这么做?
以前我们在命令行上执行的 ls -l -a 命令,它的本质其实就是程序。-l , -a 是选项。那么什么是选项呢?
选项本质是字符串,可以以一定的方式传递给ls内部的main函数,在ls内部实现的时候,就可以根据不同的选项,实现类似功能不同的表现形式。
3.谁来做?
我们启动进程之前,在命令行上输入的参数是被谁拿到的呢?
首先肯定不是进程,因为进程都没有被启动。它是被父进程bash拿到的,因为在命令行上启动的进程都是bash的子进程。
4.怎么做?
这个目前解答不了,在讲程序替换时会进行解答。
结论:
1.命令行参数至少一个(因为要启动进程)。
2.进程对应的程序的名字,一般是argv[0]。
3.有几个子串,argc就是几。
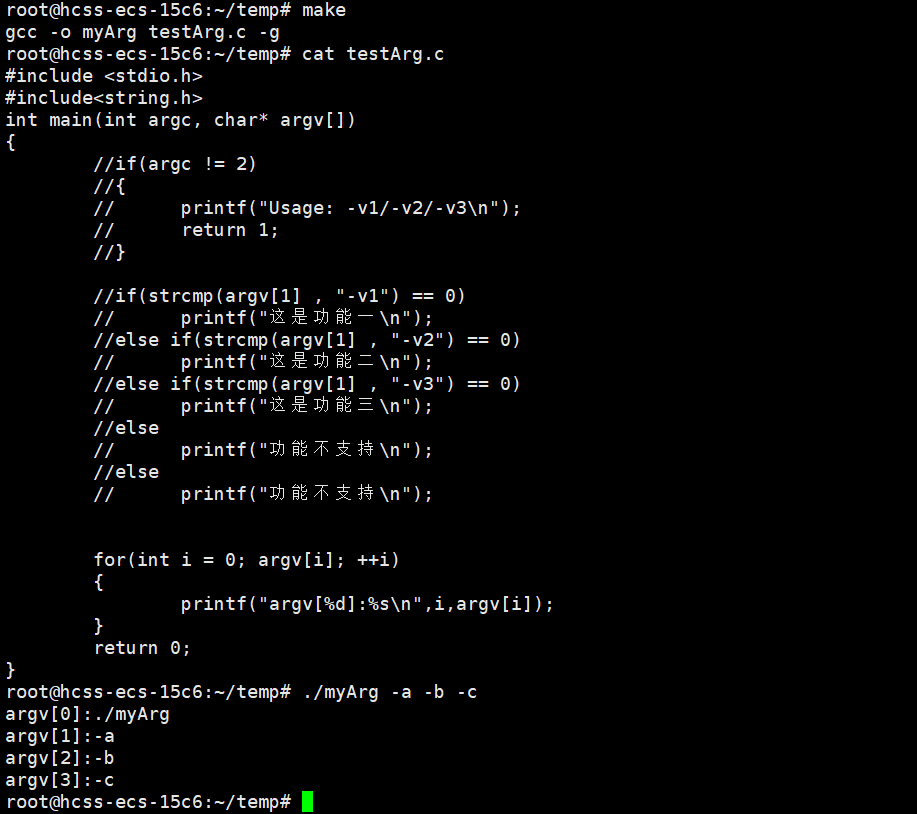
命令行参数会被父进程维护成一个char* argv指针数组,父进程会把这个指针数组传给子进程。这个指针数组的最后一个元素必须以NULL结尾。
我们可以进行验证。
二、环境变量
不知大家有没有遇到过这种情况,有时候你在安装某些软件时,系统会询问你是否要安装在环境变量里。没遇到的话也没关系,今天我们就来正式学习环境变量。
1.什么是环境变量?
是系统级别的一些全局变量,具有不同的用途。
2.简单的linux环境变量罗列。
PATH环境变量。
看现象

为什么Linux操作系统中的命令就可以直接使用呢,而我们自己的却需要带路径才能使用?
首先bash给我们阐述了失败的原因,是因为没有找到该命令。那也就是说,系统是给我们进行查找了该命令的,那么,它要去哪里找?
我们知道 ls 命令是被放在usr/bin路径下的,这个路径是被包含在PATH环境变量中的。所以能够被系统找到。但是我们的命令是没有被放在系统指定的路径下的,所以是无法被系统找到的。

为什么要说这个呢?
操作系统查找可执行命令是在环境变量PATH中查找的。
怎么证明?
既然操作系统是在环境变量中查找的,那我们就从环境变量入手。
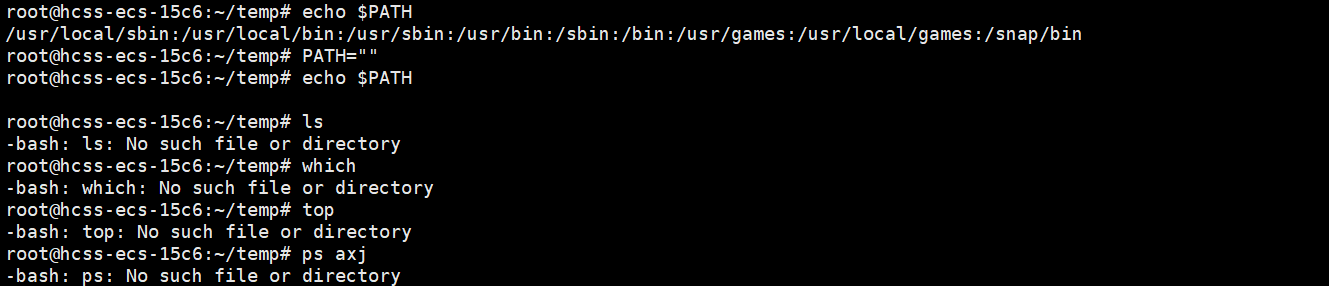
证明一:清空环境变量,系统命令也无法执行。
证明二:将当前命令的路径添加到环境变量中
方法一:export 命令
例如:export PATH=$PATH:/路径
方法二:PATH=$PATH:/路径

系统在查找命令时,会以冒号作为分隔符,分别在不同的路径下进行查找,如果都没找到就会报错。
env //显示所有的环境变量
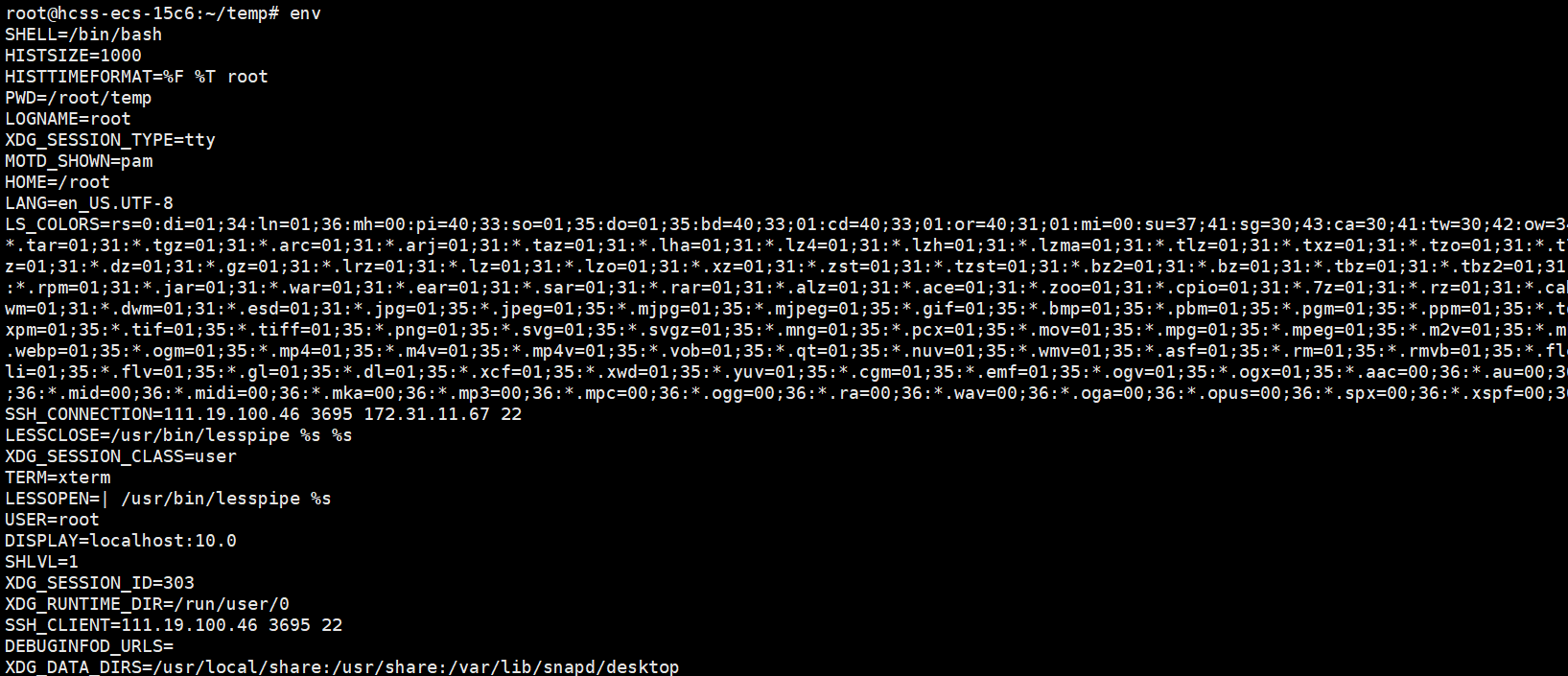
history //查看历史命令

历史命令只记录了1000条,就是因为环境变量HISTSIZE = 1000。

为什么要说这个OLDPWD呢,还记得 cd - 命令吗?跳转到最近一次工作目录。


之所以能够跳转,就是因为环境变量OLDPWD记录了最近一次的工作目录。
与此类似的还有PWD,USER,HOME…。看到这里,大家以前的疑问就解开了,知识就串起来了。
3. 如何多方法获取环境变量
方法一:
main函数有一个char* env[]指针数组,它也是指向一个个字符串,就是环境变量K=V的字符串,我们把它叫做环境变量表,最后也要以NULL结尾。
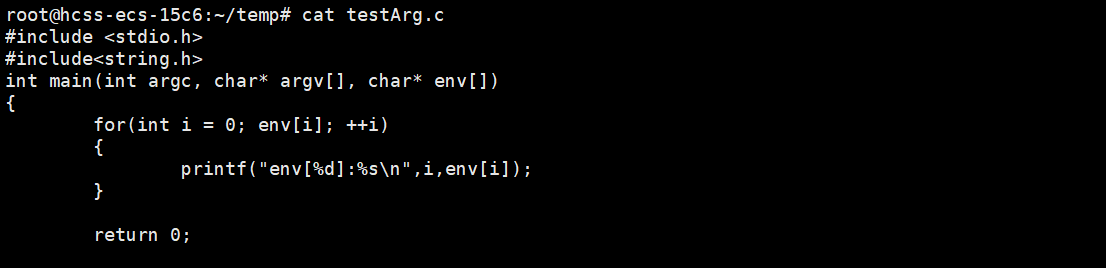
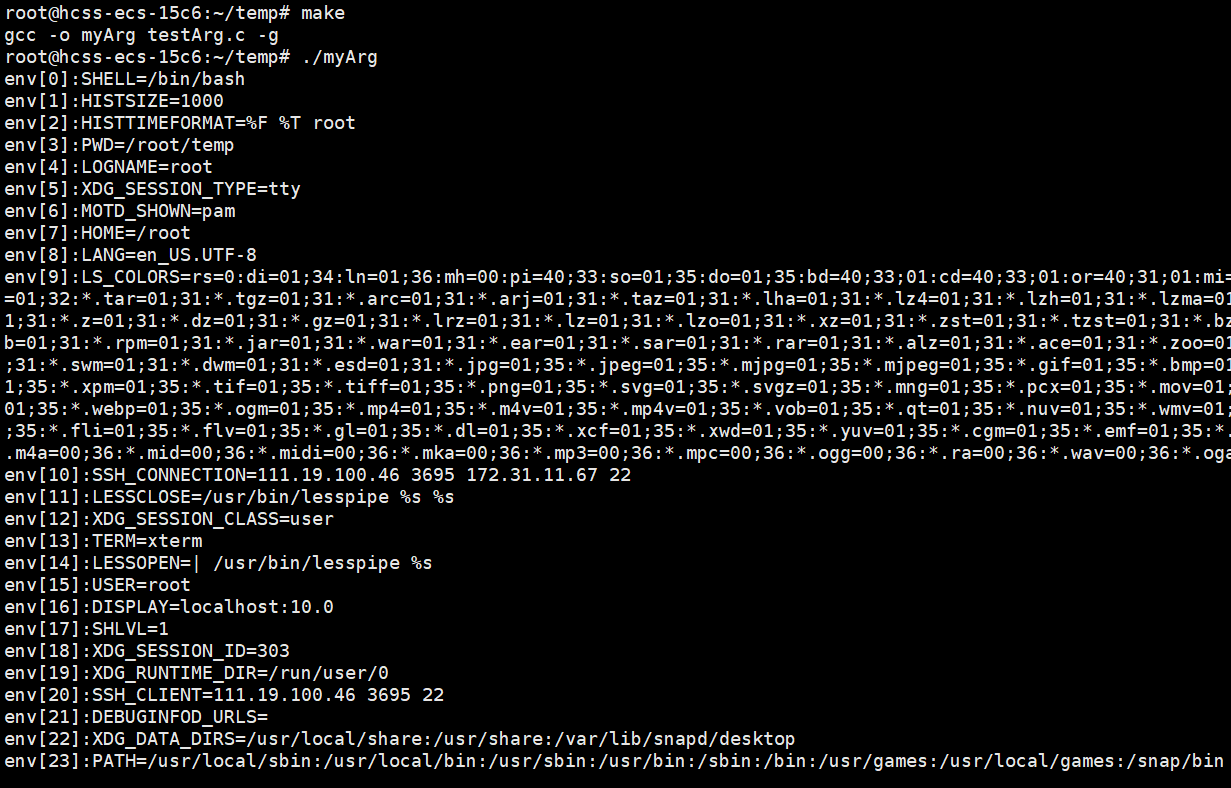
方法二:系统调用获取单个环境变量
char* getenv(const char* name)
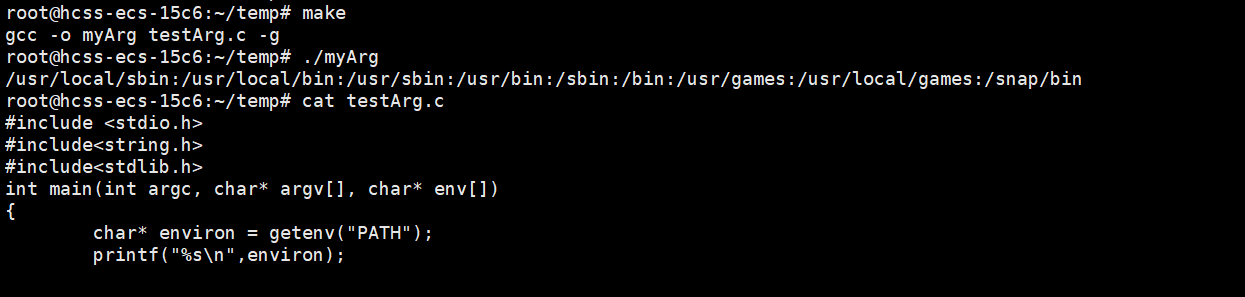
方法三:char** environ

这个二级指针就是指向char* env[]指针数组的,通过它也可以访问环境变量。
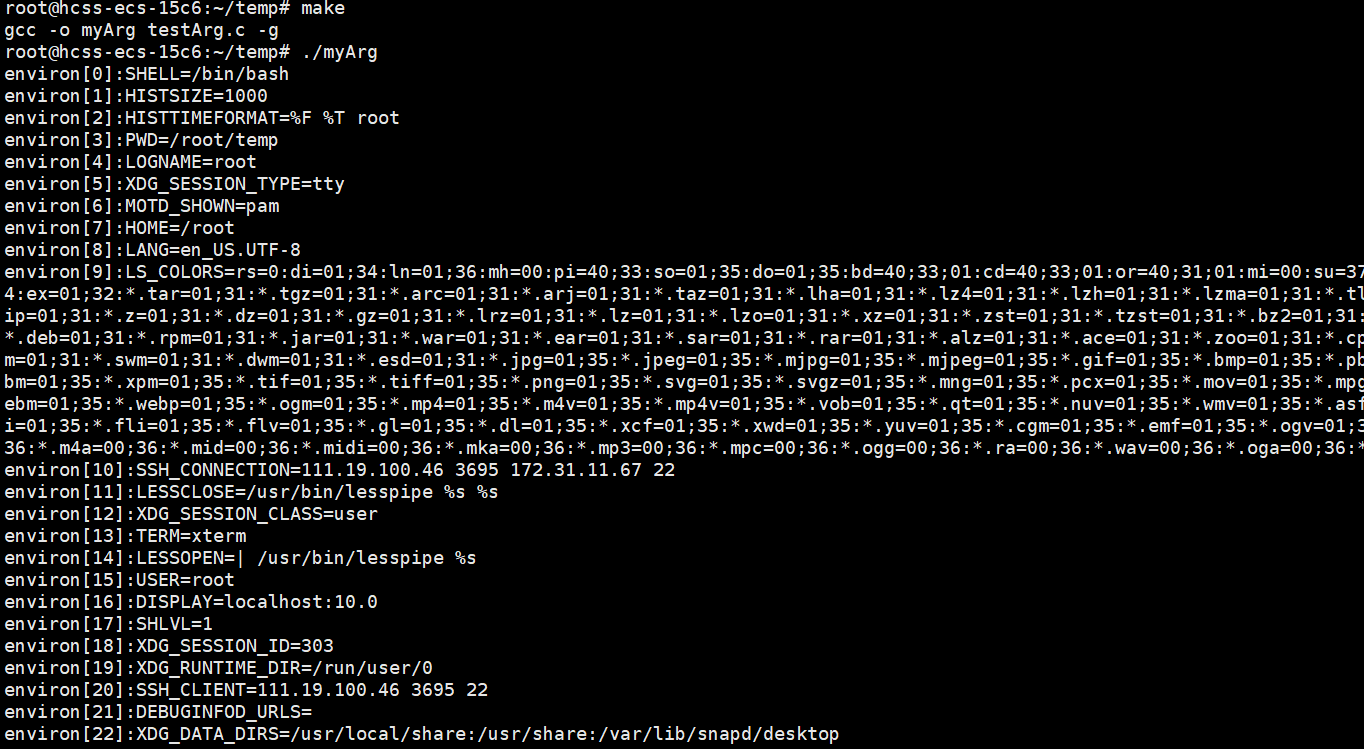
不知道大家有没有疑问呢?命令行上的进程是怎么获得环境变量的呢?
首先不是你的进程获得了环境变量,是你的父进程bash获得了环境变量,形成环境变量表的。
那我们的进程是如何获得父进程bash的环境变量表的呢?
父进程bash的环境变量表是父进程的数据吗?当然是。那么子进程是可以继承父进程bash的代码和数据的。
那么父进程又是如何获得环境变量表的呢?
是从系统的配置文件中来。

父进程会形成两张表:命令行参数表(一直在变),环境变量表(比较稳定),这两张表是内存级的。
4. 为什么要有环境变量
如果我们要写一个只有自己可以执行的程序呢?
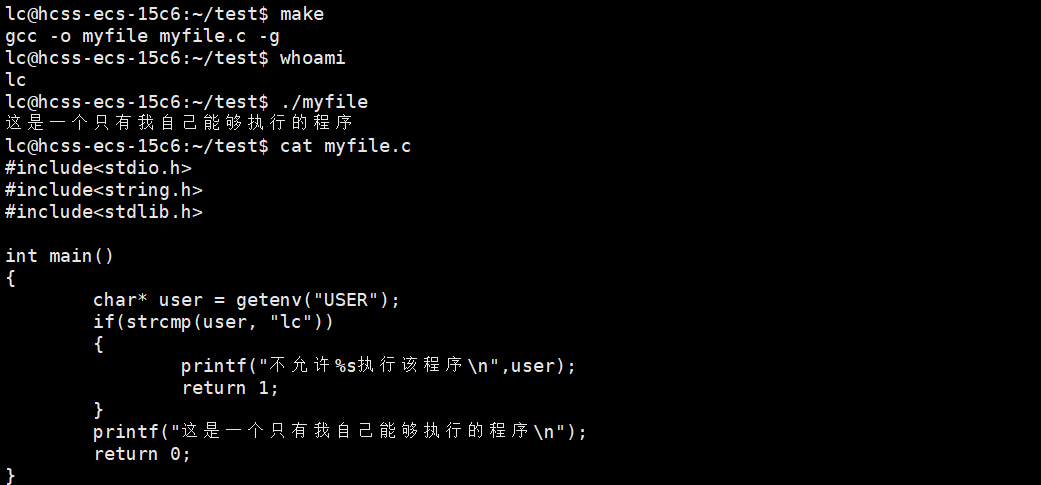
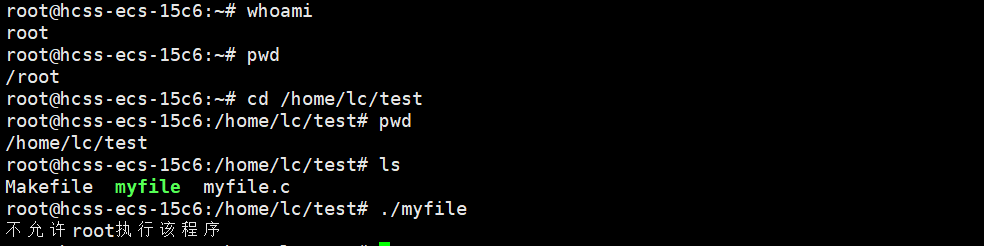
即便强如root也是不允许的,之所以要有环境变量,就是因为不同环境变量,有不同的用途。
还记得pwd吗?进程会记录下来自己的工作路径cwd,父进程bash有cwd吗?肯定是有的。在bash进程自己的task_struct 内部保存,创建子进程是以父进程为模版的。
那么,子进程的pwd从哪里来?从bash来。那么父进程的pwd从哪里来呢?既然cwd是task_struct内部的属性,那么就可以通过系统调用来获得。
char* getcwd(char* buf, size_t size); //获取当前工作路径
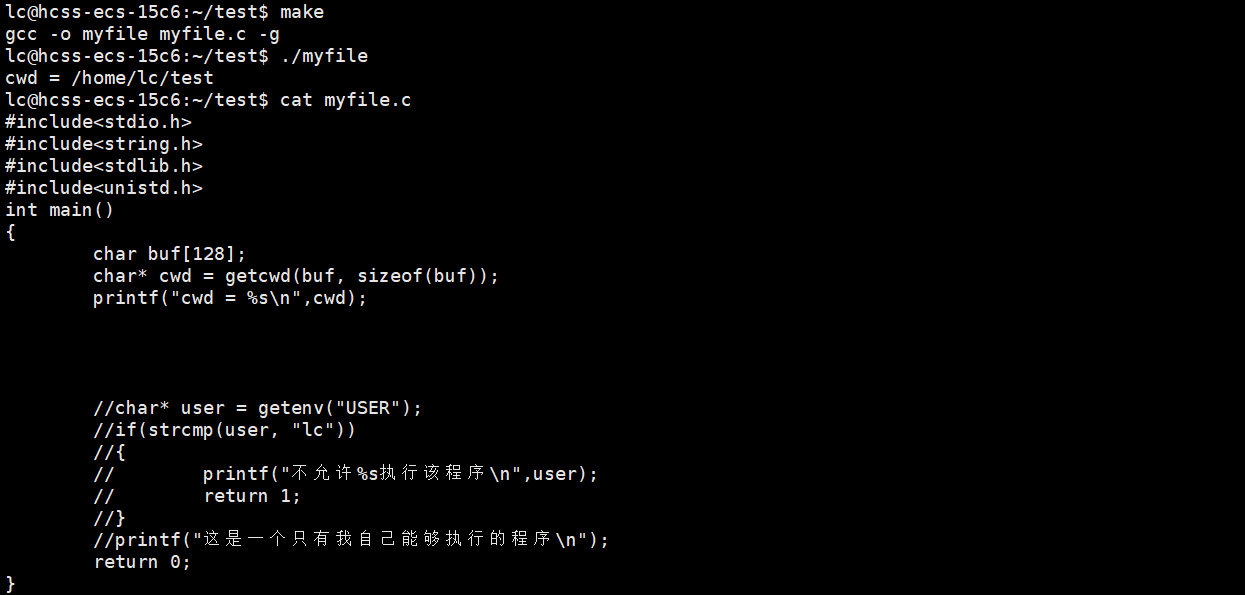
bash进程的cwd是通过系统调用获得的,然后用来更新环境变量。
修正概念:所以环境变量大部分从配置文件中来,也有少部分是启动之后,动态获取或者创建的。
5. 环境变量的特点和总结
环境变量为什么具有全局属性?

我们将所有的环境变量写进管道,再对key进行过滤,发现并没有过滤出来,说明环境变量里没有key,但是使用echo命令却可以将key显示出来,这种变量我们称之为本地变量。
本地变量只在bash内部有效。
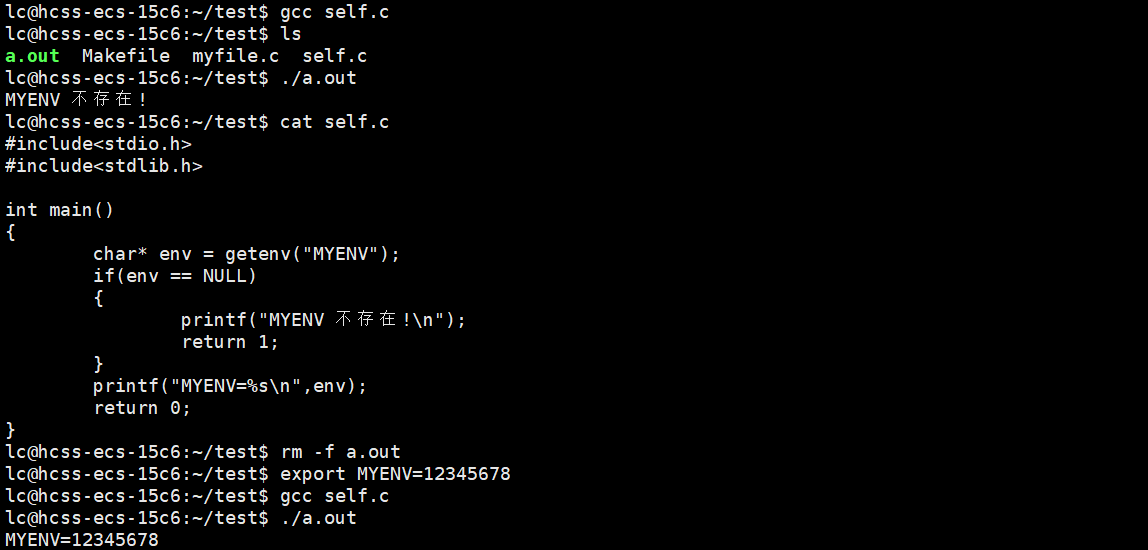
./self是一个子进程,环境变量MYENV果然被子进程继承下去了,而本地变量不会被子进程继承。那么./self也会有它的子进程,孙子进程…。所有进程都会获得环境变量,所以我们说环境变量具有全局属性。
unset //用来取消环境变量

内建命令的引出。

echo是命令吗?要不要创建子进程?echo自己,怎么获得的本地变量?
修正概念:大部分的命令本质是可执行程序,需要通过创建子进程的性质执行。
在linux中,有一部分命令,执行的时候没有风险,需要bash自己执行,我们把这种命令叫做内建命令。
三、程序地址空间
1. C/C++内存空间布局验证
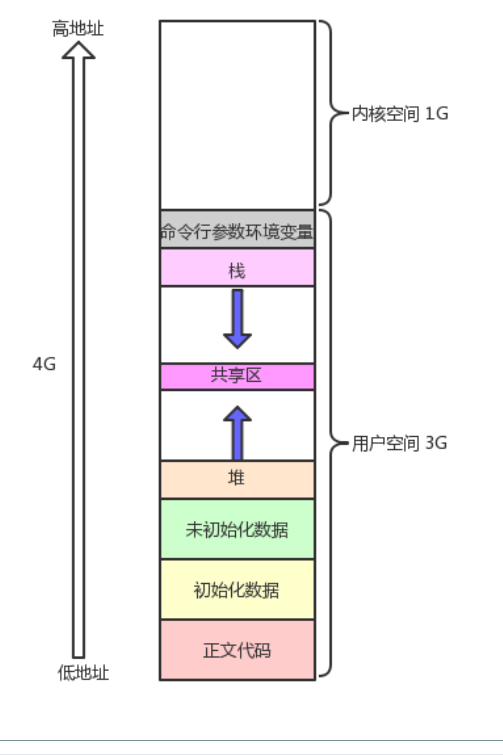
可以看到,正文代码到内核空间的地址是由低到高的。我们可以写一段程序验证该结论是否正确。
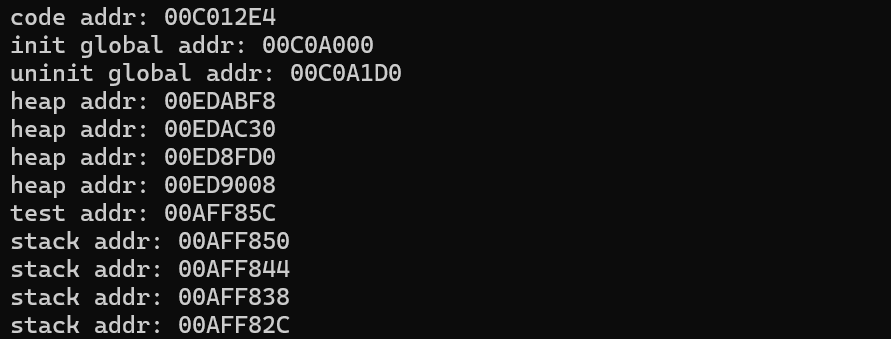
通过结果,可以判定是对的。以前我们还学过静态变量的生命周期是和全局变量一样的,那么这是为什么呢?我们将int test改为static int test。


可以看到,静态变量的地址和全局变量是很接近的,这就说明静态变量已经和全局变量的声明周期是一样的了。
那么,我们上面所说的内存空间布局是物理内存吗?不是的。它叫做进程地址空间,也叫做虚拟内存。
2. 虚拟地址
看下面的程序。
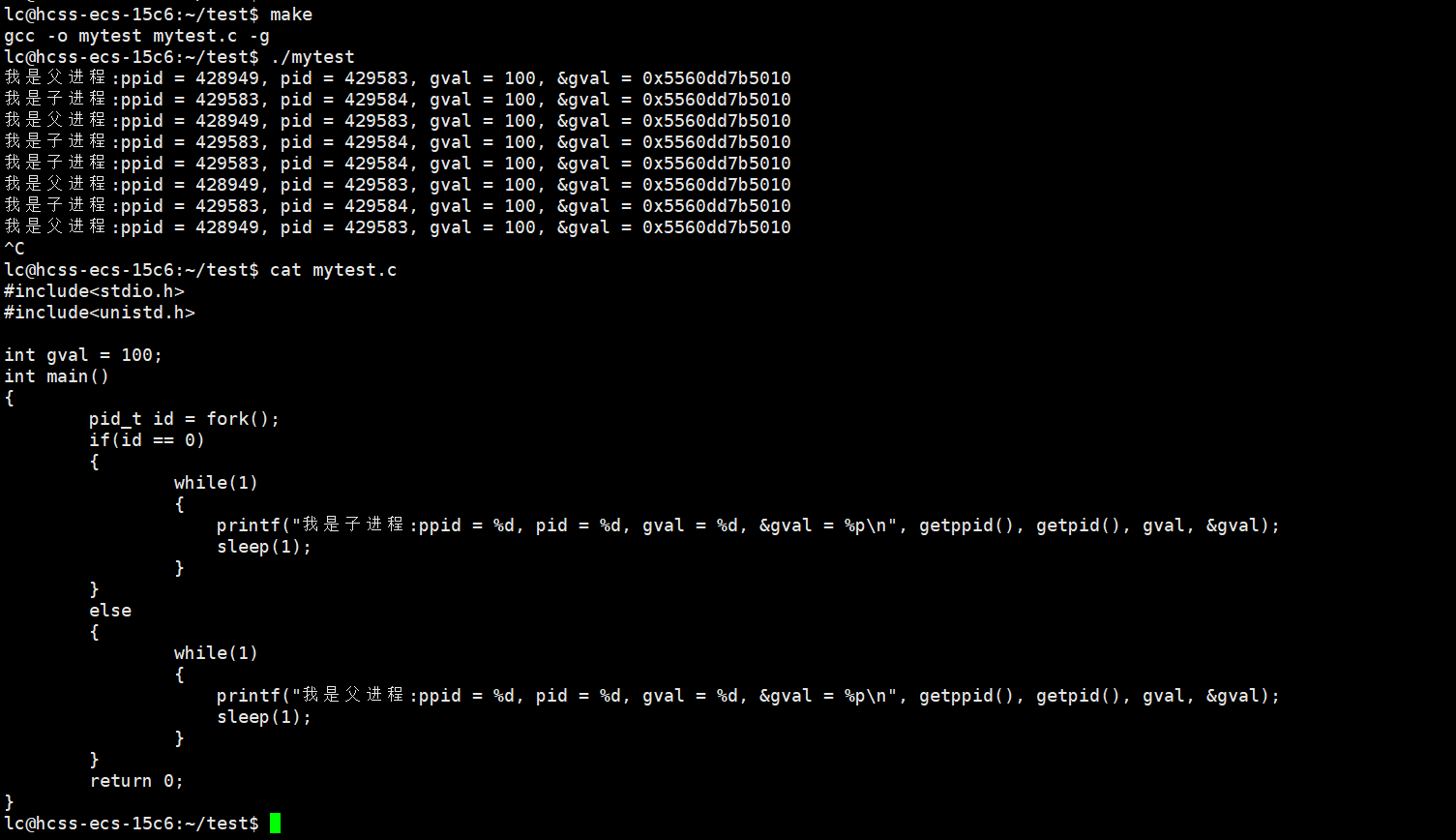
可以看到,父子进程访问的是同一个全局变量,这说明父子进程的代码和数据确实是共享的。
现在,我们对代码做出一点修改,再看看结果。
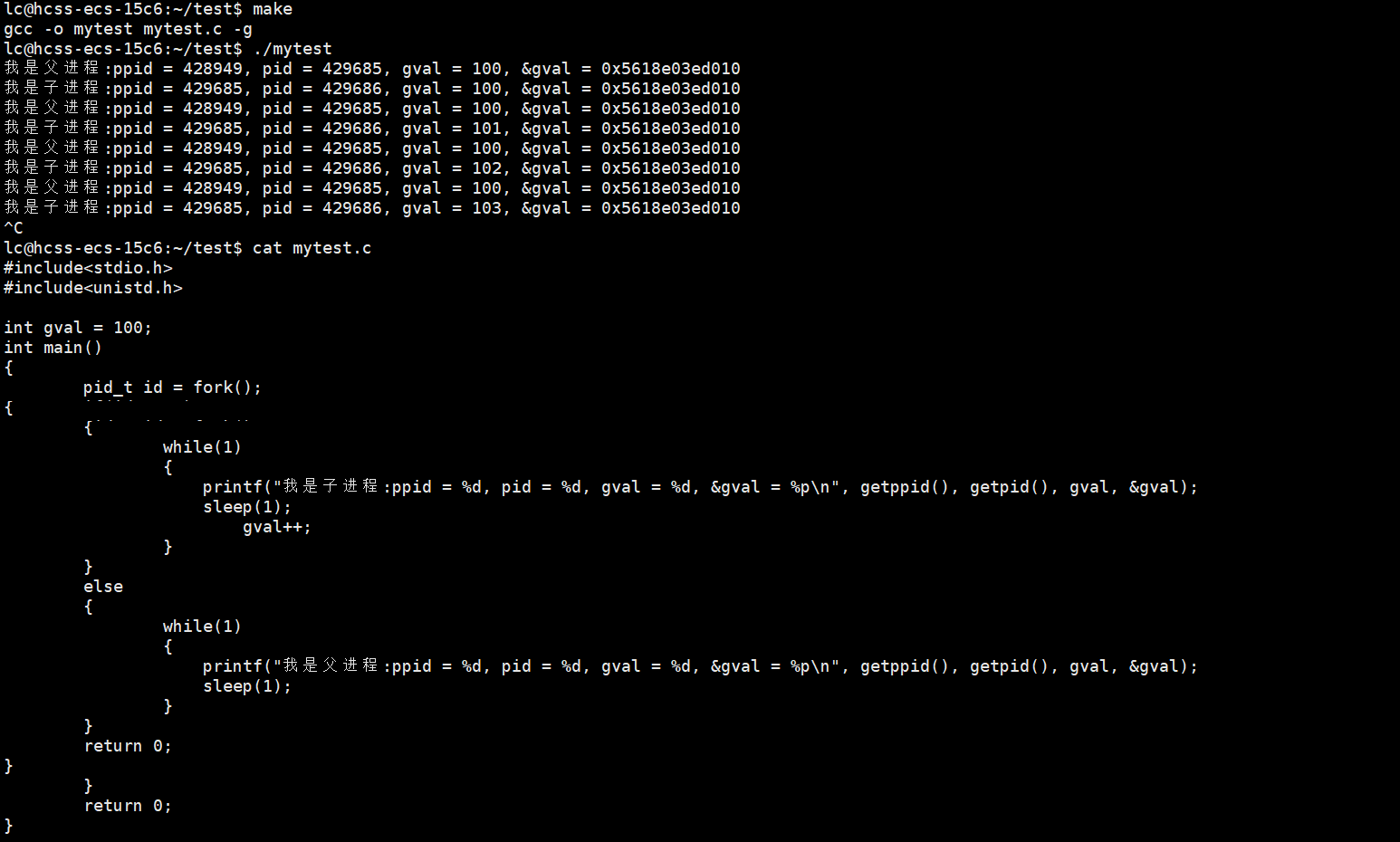
可以看到,父子进程访问的是同一个变量(因为地址是一样的),但是数据却不一样,这是为什么呢?
进程是具有独立性的,即便亲如父子也是不能够影响彼此的,根据以前所学的知识勉强能够解释原因。但是同一个地址怎么可能查出来不同的值?
我们虽然不知道这个地址怎么回事,但我们可以百分百肯定,这个地址根本不是物理内存的地址。因为如果它是物理内存的地址,就不可能同一个地址查出来两个不同的值。那么它是什么呢?它就是虚拟地址。
我们以前所学的所有的地址,都是虚拟地址,物理地址我们看不到。
要想解释清楚这个问题,我们就必须了解虚拟地址。
你的程序经过编译链接形成可执行程序被放在磁盘里,将来你的程序会被加载到内存里,同时操作系统会创建PCB,PCB包含硬件上下文数据,进程优先级,pid…,它会指向你的代码和数据,但其实并不是直接让PCB指向代码和数据的,操作系统为进程创建PCB的同时,也创建了虚拟地址空间和页表,虚拟地址空间的地址范围是从全0到全F的,虚拟地址空间上的每一个地址都是虚拟地址。
以32位机器为例,虚拟地址空间的范围是[0,2^32-1],将来虚拟地址要和物理地址进行一 一映射,就需要通过一种数据结构页表来实现。你的虚拟地址将来会有代码地址,已初始化数据的地址,未初始化数据的地址…,每一个合法的虚拟地址都要经过页表映射到物理内存上,给上层用户的都是虚拟地址,将来用户使用虚拟地址访问的时候,要经过页表查找到对应的物理地址。
换句话说,进程在进行访问内存的时候,要先经过虚拟地址到物理地址的映射,找到物理内存,才可以访问数据。
假设,我们现在有一个已初始化的全局变量gval,将来访问内存的时候,就可以通过这个地址在页表中查找对应的物理内存,如果我们创建了一个子进程呢,子进程也会有自己的PCB,虚拟地址空间,页表,子进程的这些都是以父进程为模版来的(浅拷贝),所以子进程gval的地址和父进程是一样的,这就是刚才我们父子进程访问同一个变量数据和地址相同的原因。
当子进程修改数据时,操作系统会在物理内存上开辟新的空间,拷贝原来的数据,再进行写入,并更改映射关系。之所以不能在原来的物理地址上更改,是因为进程之间具有独立性,如果直接在原来的物理地址上更改,就会影响父进程的数据,破坏了进程的独立性。如果这个数据是密码或者其它重要的数据,那不是完蛋了。我们把这种技术叫做写时拷贝。
刚刚这些工作全部由操作系统完成,用户不知道。所有的工作都没有改变虚拟地址,但是在底层虚拟地址通过页表的映射,子进程已经有了新的物理地址,这就是刚才我们父子进程访问数据不一样,但地址是一样的原因。
现在我们就可以解答之前的文章里遗留下来的问题了。
为什么fork之后,同一个变量既可以大于0又可以等于0?这是因为,fork之后会return,return的本质就是进行写入,对于父子进程而言,会发生写时拷贝,它们会拿着同样的虚拟地址通过页表映射到不同的物理地址上,所以同一个变量才既可以大于0又可以等于0。
3. 理解虚拟地址空间划分
举个例子:在遥远的大洋彼岸,有一个大富翁,他有很多私生子,私生女,大富翁给他的第一个私生子说,等他百年之后,大富翁的全部财产10个亿都是他的,给他的第二个私生子也是这样说的,私生女…也是一样的。根据我们的理解,这不就是在给他的每一个私生子,私生女画大饼吗。我们把私生子,私生女叫做进程,大富翁叫做操作系统,大饼叫做虚拟地址空间。大富翁的私生子,私生女越多,大富翁画的饼就越多,后来大富翁自己都不记得自己画的大饼了。所以,虚拟地址空间需要被管理吗?但是需要的,先描述在组织。
我们虽然并不清楚虚拟地址空间到底是什么,但我们可以肯定的是它本质一定是一个内核数据结构。虚拟地址空间包含代码地址,已初始化地址,未初始化地址,堆,栈…这些不就是虚拟地址空间里的属性吗。
现在,我们已经大概理解了虚拟地址空间,那么该如何理解空间划分呢?
例子:一张桌子两个人一起用,一个男生,一个女生。但是这个男生脏兮兮的,老是找人家女生玩,这个女生就在桌子上划了一条三八线,告诉男生以后不准越过这条线,否则以后就不理他了。
小女孩画三八线的本质:划分区域。我们用数学的方法来表示小女孩的行为,不就是[0,49]属于小男孩,[50,100]属于小女孩。
用计算机语言划分区域不就是
struct area
{int start;int end;
}
那我们要划分桌子呢?那不就是
struct desktop
{struct area boy;struct area girl;
}
未来你想对这个桌子进行划分,不就是struct desktop t = {{0,49},{50,100}};所以,我们终于得到一个结论,所谓区域划分,本质其实只要有线性空间的一段开始地址和结束地址,表明一段范围即可。
在linux中,虚拟地址空间被表示为
struct task_struct
{struct mm_struct* mm;
}struct mm_struct
{unsigned long start_code, end_code, start_data, end_data;unsigned long start_brk, brk, start_stack;unsigned long arg_start, arg_end, env_start, env_end;
}
可以看到的是,虚拟地址空间被划分成了两大部分,用户空间,内核空间。用户空间可以直接让程序员用地址来进行访问,而要访问内核空间,必须要用系统调用。
所以,如何理解进程是独立的?
进程 = 内核数据结构(PCB,mm_struct,页表) + 进程的代码和数据。
进程的底层是通过写时拷贝来达到数据分离的,在不修改数据的情况下,父子进程的数据是共享的,一旦修改,父子进程的数据就会保证独立,所以进程是具有独立性的。
现在,我们就来简单的介绍一下页表。
我们都知道代码区是只读的,已初始化,未初始化可以读也可以写。这是因为在页表中会有一个属性来表示它们的权限。就像文件有r,w,x一样。
1、定义全局变量时,为什么它全局有效?


可以看到,静态变量的地址是在已初始化和未初始化之间的。
结论1:地址空间只要存在,那么全局数据区就要存在,所以,全局变量会一直存在,包括静态变量。
2、字符串常量为什么是只读的?


可以看到,字符串常量的地址和代码的地址是非常相近的。
结论2:字符串常量,其实和代码是编译在一起的,都是只读的(因为代码就是只读的)。
现在可以解释 *str = ‘C’;为什么会崩溃了。这是因为操作系统拿着字符串常量的地址在经过页表转为物理地址的同时会对权限进行检查,权限不匹配就会杀掉进程。
总结:字符常量区,被页表映射的时候,有权限约束,不让写入操作进行转换。
const char* str = “hello world”;这个const是在干什么呢?
const是用来约束编译器的,让编译器进行写入检查,如果有,就报错。
那子进程又是如何得到父进程的命令行参数表和环境变量表的呢?
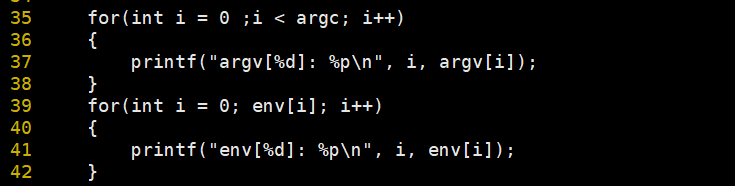
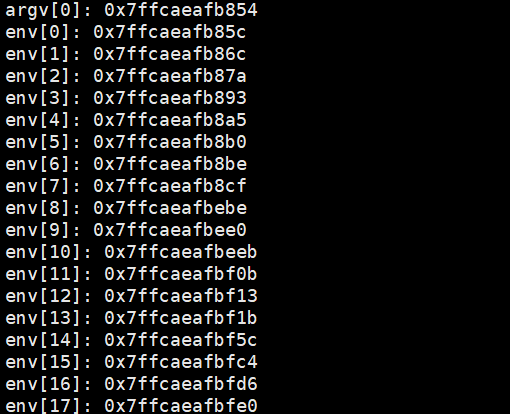
可以看到,在虚拟地址空间中也有命令行参数表和环境变量表的虚拟地址。
结论3:命令行参数和环境变量属于父进程的地址空间内的数据资源,和代码区数据区一样,子进程会继承父进程的地址空间,所以子进程也能够看到命令行参数和环境变量。
4. 为什么要有虚拟地址空间
如果没有虚拟地址空间,直接让PCB指向物理内存,那么一旦有野指针等类似的问题,访问的数据不是自己的,那么可能就会影响到其它进程,这样就无法保护进程的独立性了。而有了虚拟地址空间,就相当于给计算机添加了一层软件层。用虚拟地址空间访问物理内存的时候,必须经过转换,那么在虚拟到物理内存转换的时候,就可以进行安全审核。
结论1:变相的保证了物理内存的安全,维护进程的独立性。
可执行程序是在磁盘上的,加载到物理内存的时候就变成了进程,那么理论上可以加载到物理内存的任意位置吗?答案是可以的。而我们都知道,虚拟地址空间是按照一定的区域划分好的,也就是说,在一段范围内它一定都是代码或者已初始化数据或者未初始化数据,而在整体上,它一定是按照虚拟地址空间的布局进行划分区域的,而在物理内存上却是随机的。
结论2:进程在看到自己的代码和数据,全部都是”有序看待“。
我们都知道,创建一个进程的时候,是先有内核数据结构的。但是创建一个进程时,一定要立即加载进程自己的代码和数据吗?可不可以一行都不给你呢?进程创建好,直接让进程的PCB去调度队列里进行排队,等进程调度时,在加载代码和数据,构建映射关系,边执行边加载呢?答案是可以的。我们把这种加载方式叫做惰性加载。
举个例子:过年了,你收到了一千块的压岁钱,明天你妈要拿这笔钱去给你交报名费,半夜三更你老舅来找你妈,说是有急事需要一千块钱,等明天天亮就还回来,反正你现在也用不到,就借给你老舅了,天亮之后你老舅把钱还回来了。在你休眠的这段时间,这笔钱就可以多解决很多问题了。
所以,新建的进程并不是立即调度的,可以先不加载代码和数据,本来给你用的就可以给别人用了。等你要用的时候,别的进程就不用了,在加载你的代码和数据。这可以提高内存的使用率。
代码和数据加载到内存,就必须要进行内存申请。我们把加载过程当中内存申请的模块叫做内存管理模块,PCB,虚拟地址空间叫做进程管理,进程运行也需要内存呀,它就通过页表来映射到物理内存。但是因为只是映射关系,在一定程度上,我们的进程和内存不就解耦合了吗。
如果没有虚拟地址空间,那加载代码和数据时,PCB就要记录进程的pid,优先级…,如果是野指针,访问到别人的数据怎么办,内存申请失败了,进程怎么办,这不就是强耦合吗。而有了虚拟地址空间,我们只需要更改页表的映射关系就可以了。
结论3:进程管理和内存管理进行解耦合。
扩展知识:栈空间,代码区…可以用start,end来限定范围,那我们的堆空间呢?堆空间可以申请很多次,每一次申请都有起始地址和大小啊?这又该作何解释。
在进程中该如何实现呢?
struct vm_area_struct
{struct mm_struct* vm_mm;unsigned long vm_start;unsigned long vm_end;struct vm_area_struct* vm_next;struct rb_node vm_rb;...
}
我们看到的mm_struct是汇总了虚拟地址空间的整体情况,是虚拟内存区域的总览。而struct vm_area_struct描述的是地址空间中一段连续的,具有相同属性的内存区域(要么都是堆,要么都是栈的小区域)。当申请堆空间的时候,不可能把整个堆的空间都拿来使用,操作系统是通过申请struct vm_area_struct来表明一段堆空间的起始地址(unsigned long vm_start)和结束地址(unsigned long vm_end),申请多次堆空间,操作系统就会申请多个struct vm_area_struct。那么,这些struct vm_area_struct也是要被管理起来的。struct vm_area_struct是通过双链表的形式来管理的。
今天的文章分享到此结束。觉得不错的给个一键三连吧。若是文章哪里阐述的有问题,可以私信或者评论哦。
