VIT速览
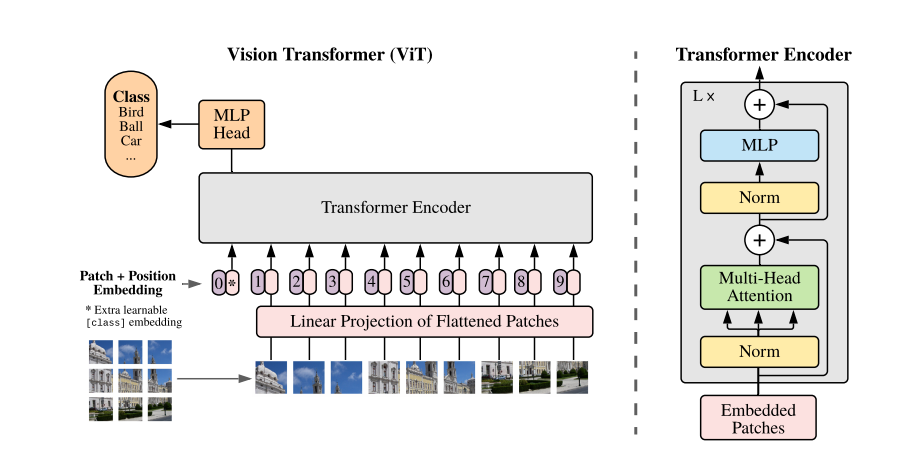
当我们取到一张图片,我们会把它划分为一个个patch,如上图把一张图片划分为了9个patch,然后通过一个embedding把他们转换成一个个token,每个patch对应一个token,然后在输入到transformer encoder之前还要经过一个class token,带有分类信息,然后加上位置信息如图123456789。
Transformer Encoder由右图所示的部分组成,一共L个,然后再输出到MLP Head,然后做一个分类。
当我们取到一张图片,我们会把它划分为一个个patch,如上图把一张图片划分为了9个patch,然后通过一个embedding把他们转换成一个个token,每个patch对应一个token,然后在输入到transformer encoder之前还要经过一个class token,带有分类信息,然后加上位置信息如图123456789。
Transformer Encoder由右图所示的部分组成,一共L个,然后再输出到MLP Head,然后做一个分类。