2026python实战——如何利用海外代理ip爬取海外数据
家人们!随着跨境电商的发展,是不是越来越多的小伙伴们也开始搞海外的数据分析了?不过虽然我们已经整天爬虫、数据采集打交道了,但一到海外数据,还是有不少人掉进坑里。你们是不是也遇到过以下情况:花了一堆时间结果被网站拦截、IP被封、爬虫跑几次就挂掉……海外数据采集分析起来远没有那么轻松简单。别慌,今天就手把手教你用海外代理IP高效爬取 Zillow 房产数据,看完保准能上手!
一、为什么需要用海外代理IP?
大家都知道,像 Zillow 这样的热门房产网站,用户流量巨大,页面访问保护肯定是非常严密的。使用本地ip多爬2下,分分钟弹窗“您可能是机器人,请验证”,或者直接就刷新不出来了……
为啥呢?原因很简单:
1.你用的是本地ip;
2.你的访问都来自相同的IP地址,网站已经识别到“这段流量可能异常”。
这时候,海外代理IP就能帮到我们了!海外代理IP可以让你的请求来自不同的IP,而不是让同一个IP不停地爬取。高质量的代理还能保证请求的稳定性、防止运行中断,能高效帮助你完成数据采集任务。这点,相信很多小伙伴也知道要用海外代理IP,但具体使用哪家就个花入各眼了,比如我自己用的是用惯的青果网络家的海外代理。
至于海外公司提供的代理IP,这part今天不是我们的重点,感兴趣的可以评论一下,我们后续再来说这部分。
ok,接下来还是围绕我们今天的主题,如何用海外代理爬 Zillow 房产数据。
二、实战爬 Zillow:从页面分析到代码落地
2.1 配置环境
在开始爬虫之前,我们需要以下工具和环境:
Python 编程环境:Python 3,搭配基础包 requests 和 lxml。
2.2 扒页面结构,明确目标数据
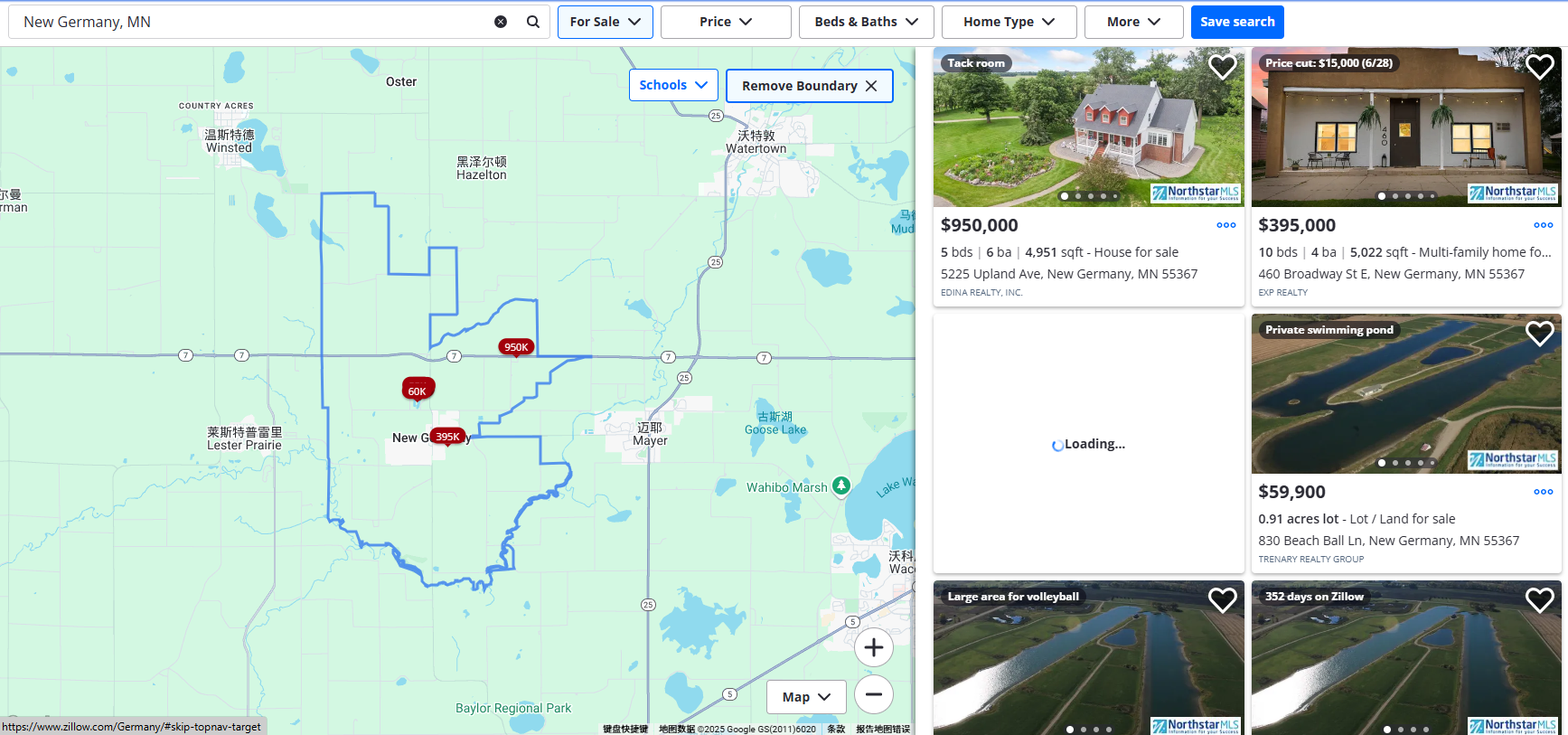
以德国房屋租赁的搜索页面为例:https://www.zillow.com/Germany/,想把这类页面上的房源信息“抓下来”,我们需要做以下几个步骤:
-
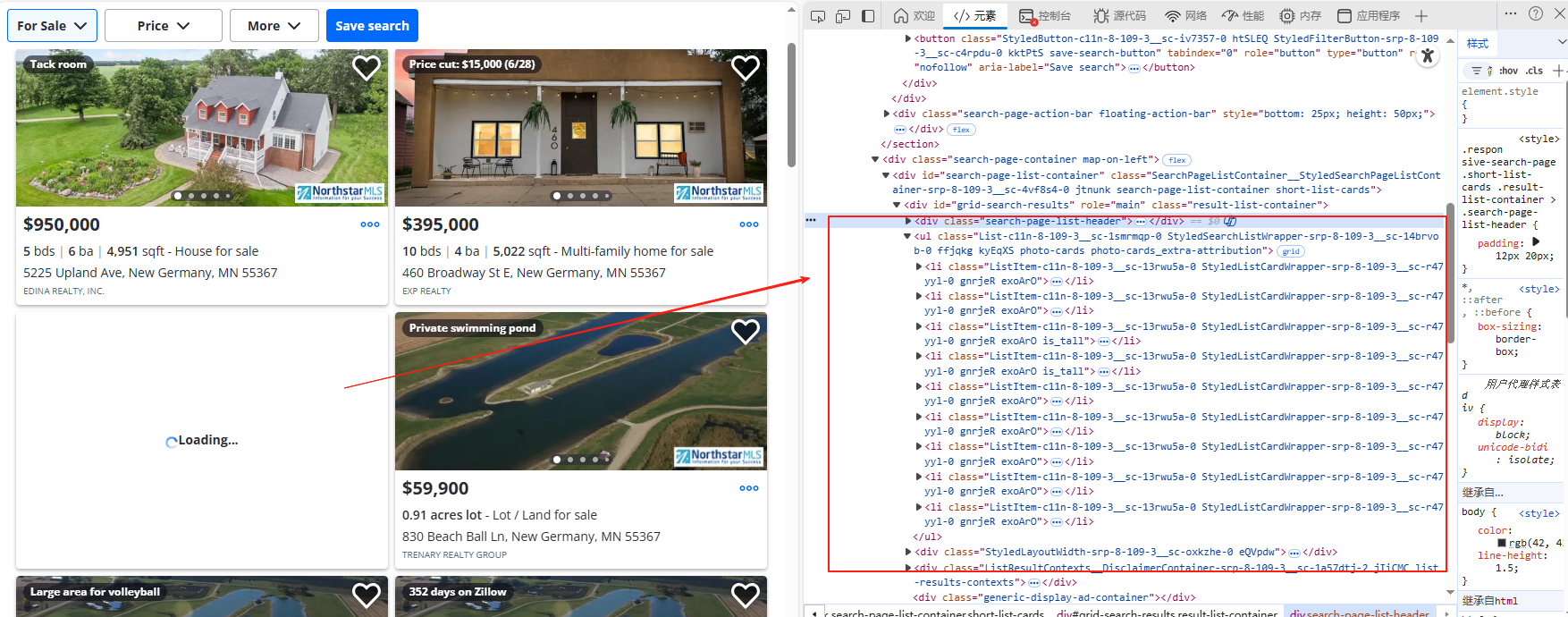
打开目标页面,找到右侧的房源列表区域。按下 F12 看 HTML 结构。
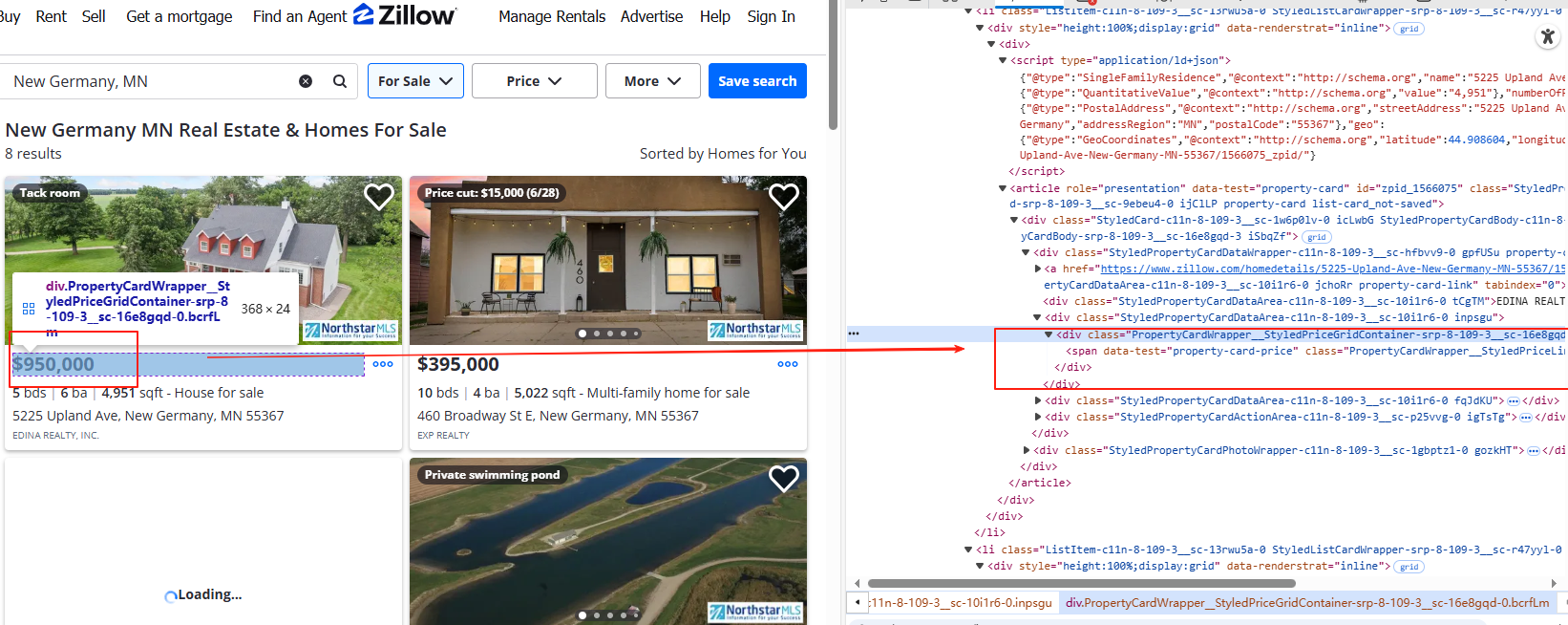
-
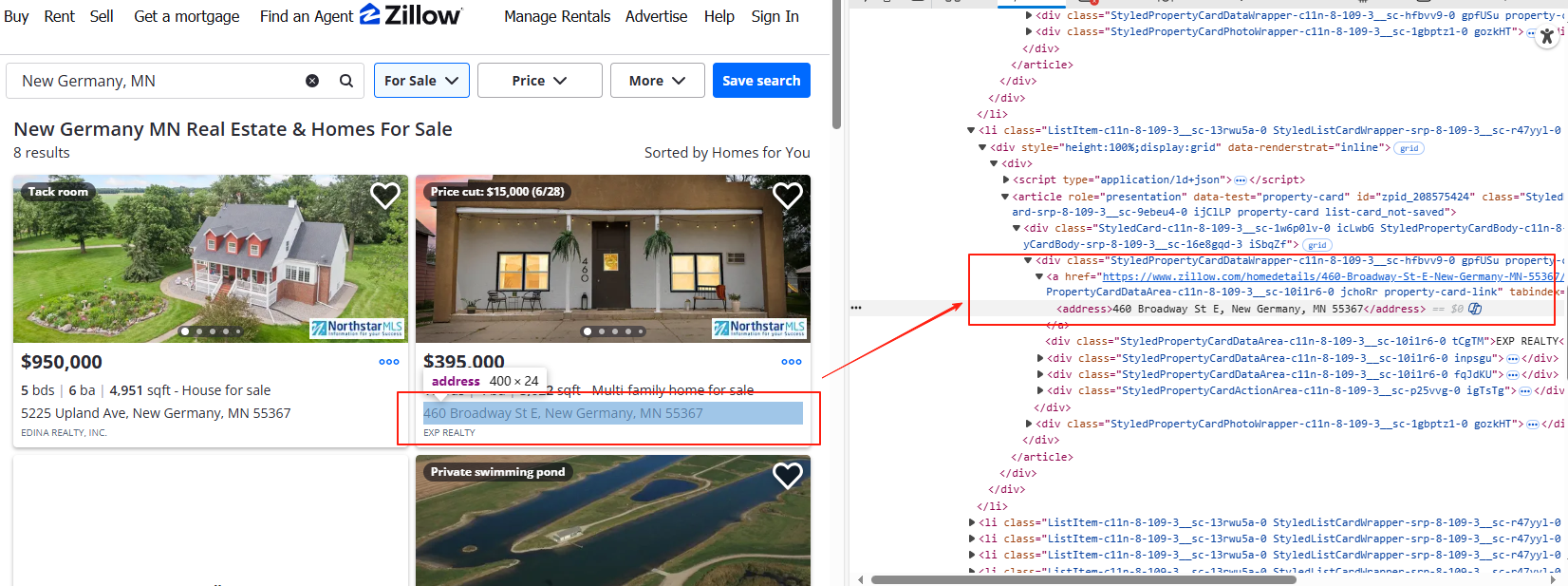
我们可以得出:一般每一个房源信息会用一个 <li> 标签包裹起来,主要包含以下内容:
-
房子地址:存放在
<address>标签内; -
房子价格:在
property-card-price的<span>标签中; -
房子链接:位于
<a>标签的href属性; -
详细信息:如房间数、浴室数和面积,会分散在
<ul>标签的<li>子标签中。
-
这时候我们就可以确定爬取数据的路径了,比如价格的 Xpath 是:
//span[@class="property-card-price"]/text()同理,其他数据的路径定义了提取的精准方向。
2.3 爬数据的部分代码
我们用 Python 搭建一个基于代理IP的爬虫程序,分三步走。
2.3.1 配置代理和请求信息
要让请求从代理IP发出,我们可以用青果生成的API信息,加载到代码中:
import requests# 功能:发送带青果网络海外代理IP的请求def get_proxy():proxy_url = "https://overseas.proxy.qg.net/get?key=yourkey&num=1&area=&isp=&format=txt&seq=\r\n&distinct=false" # 青果网络海外代理IP API地址" # 请求头headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0",}# 目标网址url = 'https://www.zillow.com/Germany/'2.3.2 下载目标页面
使用代理IP发起网页请求,并抓取返回的HTML源码:
def get_page(target_url):try:response = requests.get(target_url, proxies=proxy, headers=headers)response.raise_for_status() # 检查是否返回错误return response.textexcept requests.RequestException as e:print(f"请求失败:{e}")return None2.3.3 提取数据内容
有效数据藏在HTML的某些标签中,我们用 lxml.etree 解析,然后逐步提取。
from lxml import etreedef parse_page(html):root = etree.HTML(html)results = []# 定位每条房源的 `<li>` 标签houses = root.xpath('//li[contains(@class, "ListItem")]') for house in houses:try:link = house.xpath('.//a[@class="property-card-link"]/@href')[0]address = house.xpath('.//address/text()')[0]price = house.xpath('.//span[@data-test="property-card-price"]/text()')[0]details = ', '.join(house.xpath('.//ul/li/text()')) # 拼接房型等信息results.append({"link": link,"address": address,"price": price,"details": details})except IndexError:continuereturn results2.3.4 链接整个流程
最终,我们把这些步骤连起来,获取采集结果:
if __name__ == "__main__":html = get_page(url)if html:data = parse_page(html)for item in data:print(item)运行后结果如:
{'link': '/homedetails/123-Main-St/1410000_zpid/', 'address': '123 Main St, New York, NY', 'price': '$2,500/month', 'details': '2 Beds, 1 Bath, 1200 sqft'}...2.3.5 存数据!
import csv# ... 前面爬取和解析得到 property_list ...# 存成CSV文件filename = "zillow_ny_properties.csv"with open(filename, 'w', newline='', encoding='utf-8-sig') as csvfile: # utf-8-sig 防止中文乱码fieldnames = ['address', 'price', 'link', 'details', 'beds', 'baths', 'sqft'] # 定义列名writer = csv.DictWriter(csvfile, fieldnames=fieldnames)writer.writeheader() # 写入标题行for prop in property_list:# 假设你在解析时已经把户型拆分成 beds, baths, sqft 了writer.writerow(prop) # 写入一行数据print(f"【数据已保存】: 共 {len(property_list)} 条记录到 {filename}")更高级点存数据库(比如SQLite)适合数据量大或者需要复杂查询的情况,稍微麻烦点,但更规范。
2.4 小小tips,别踩雷~
-
尊重
robots.txt: 不只是说Zillow,是看看自己的目标站点允许不允许爬虫爬你要的页面。虽然技术上能爬,但了解规则是基本要求。很多商业网站明确禁止爬取,自己权衡风险。 -
控制频率,温柔点: 前面说的
time.sleep()就是让你温柔点。别开多线程几百个请求同时轰炸人家服务器,你的海外IP池再大也扛不住被封。 -
代理质量是关键:海外代理IP的质量直接影响成功率。遇到大量失败、验证码,先检查代理IP还能不能正常访问其他网站,不行就找客服,还不行就换一家质量好点服务好点的代理IP厂商。
-
注意法律: 爬公开的房源信息(地址、价格)一般问题不大。也别拿数据去做坏事(比如恶意骚扰、不正当竞争)。
三、终极总结
-
选对代理
-
轮换+延时: 每次请求换IP(自动池或代码随机),爬一页歇几秒 (
time.sleep(random.uniform(1, 5)))。 -
直捣黄龙: 优先找数据API接口(看Network里的XHR/Fetch请求),直接拿JSON数据,比解析HTML爽多了。
-
解析要灵活: 多用相对稳定的属性(
data-testid),写好容错代码(if element exists),网站改版就更新选择器。 -
数据存下来: 存CSV或数据库,别让辛苦爬的数据飞了。
-
低调干活: 控制速度,看
robots.txt,别碰不能爬的。灵活调整策略,才能在数据的“战场”上立于不败之地
好啦,从代理配置到代码落地全讲完了,剩下的就是动手实操啦~爬数据的时候遇到啥奇葩问题,评论区喊一声,咱一起唠唠咋解决!