【大模型学习】项目练习:知乎文本生成器

✨ 个人主页:在线OJ的阿川
💖文章专栏:AI入门到进阶
🌏代码仓库:
写在开头
现在您看到的是我的结论或想法,但在这背后凝结了大量的思考、经验和讨论


📚目录
- 一、设计思路
- 二、具体流程操作
- 三、想说的话
🚀实现知乎文本生成器
知乎文本生成器

一、⛳设计思路
本知乎文本生成器采用模块化设计,主要包含四大核心模块:
- 后端模块:调用DeepSeek API接口及主逻辑执行
- 提示模块:主要的提示词工程
- 格式模块:自定义输出解析器返回格式
- 前端模块:Streamlit前端及部署云和调用后端代码
说明:
编译器为Visual Studio code,Python版本为3.12,安装库为:
altair==5.5.0
annotated-types==0.7.0
anyio==4.9.0
attrs==25.3.0
blinker==1.9.0
cachetools==6.1.0
certifi==2025.6.15
charset-normalizer==3.4.2
click==8.2.1
colorama==0.4.6
distro==1.9.0
gitdb==4.0.12
GitPython==3.1.44
greenlet==3.2.3
h11==0.16.0
httpcore==1.0.9
httpx==0.28.1
idna==3.10
Jinja2==3.1.6
jiter==0.10.0
jsonpatch==1.33
jsonpointer==3.0.0
jsonschema==4.24.0
jsonschema-specifications==2025.4.1
langchain==0.3.25
langchain-core==0.3.65
langchain-deepseek==0.1.3
langchain-openai==0.3.24
langchain-text-splitters==0.3.8
langsmith==0.3.45
MarkupSafe==3.0.2
narwhals==1.43.1
numpy==2.3.0
openai==1.88.0
orjson==3.10.18
packaging==24.2
pandas==2.3.0
pillow==11.2.1
protobuf==6.31.1
pyarrow==20.0.0
pydantic==2.11.7
pydantic_core==2.33.2
pydeck==0.9.1
python-dateutil==2.9.0.post0
pytz==2025.2
PyYAML==6.0.2
referencing==0.36.2
regex==2024.11.6
requests==2.32.4
requests-toolbelt==1.0.0
rpds-py==0.25.1
six==1.17.0
smmap==5.0.2
sniffio==1.3.1
SQLAlchemy==2.0.41
streamlit==1.46.0
tenacity==9.1.2
tiktoken==0.9.0
toml==0.10.2
tornado==6.5.1
tqdm==4.67.1
typing-inspection==0.4.1
typing_extensions==4.14.0
tzdata==2025.2
urllib3==2.5.0
watchdog==6.0.0
zstandard==0.23.0
二、🎉具体流程操作
2.1 安装虚拟环境
方式一:使用anaconda安装
1.下载anaconda
2.打开
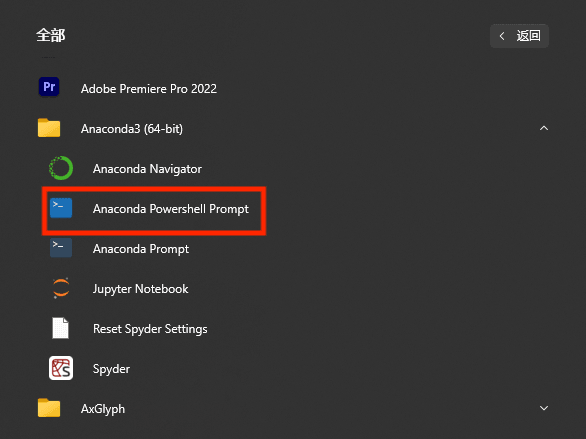
3.创建并进入虚拟环境
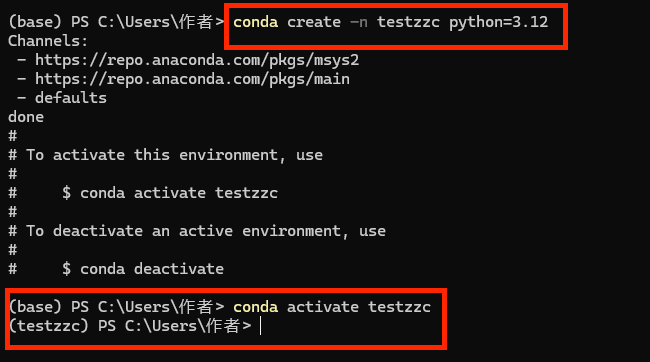
4.正常安装相应的库即可

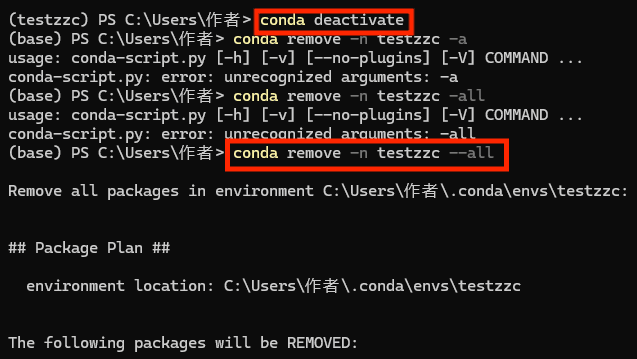
5.删除虚拟环境(可选)
先退出当前虚拟环境,再删除虚拟环境
方式二:在Visual Studio code创建虚拟环境
1.根据图操作
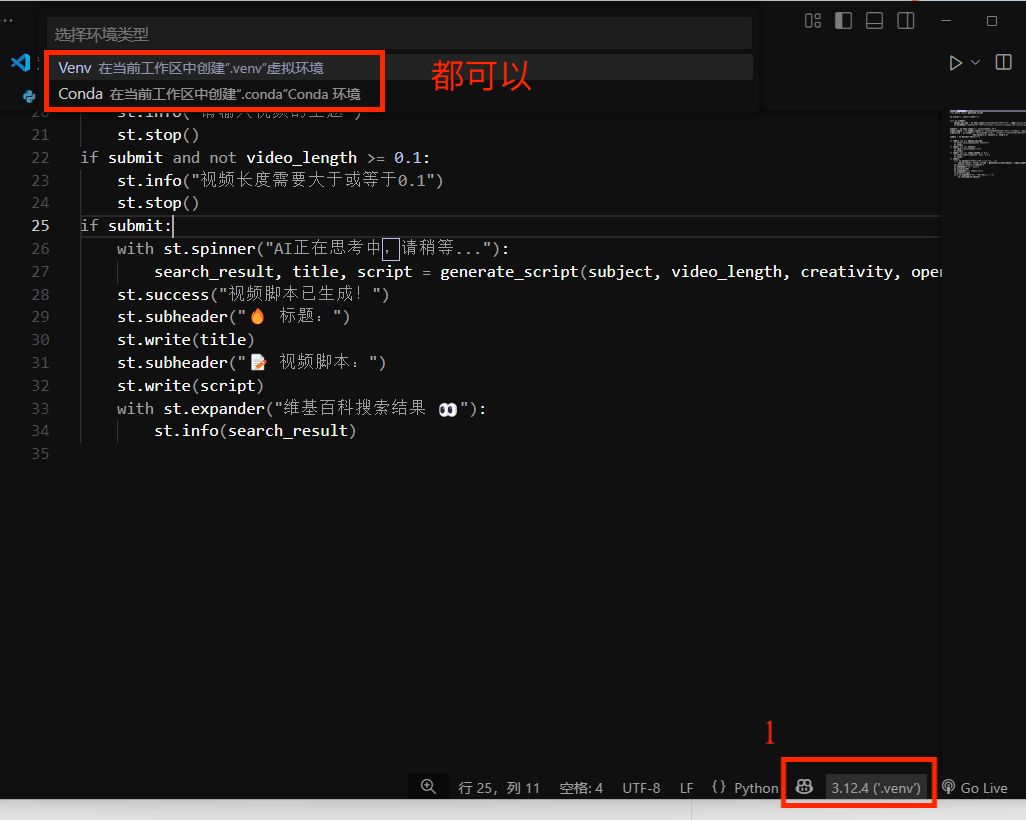
2.找到Python安装环境配置即可
2.2 安装相应的库
1.打开终端
2.输入

requirements.txt自己把相应的库建出来txt文件
3.导入相应的库(可选)
打开终端,输入:
2.3 后端模块(backend_package.py)
主要实现功能:
1.标题获取:使用链式调用,先将消息队列作为提示词传给Langchain中的Deepseek模型再自定义格式输出标题–Langchain文档
2.内容获取:使用链式调用,先将消息队列作为提示词传给Langchain中的Deepseek模型再自定义格式输出内容
from prompt import prompt_text, user_text # 引入prompt文本和用户文本
from langchain_deepseek import ChatDeepSeek # DeepSeek的Chat模型
from langchain.output_parsers import PydanticOutputParser # Pydantic输出解析器,用于解析模型输出
from langchain.prompts import ChatPromptTemplate # 用于创建聊天提示模板
from zhihu_model import zhihu # 引入Pydantic模型,用于定义输出格式# 知乎文本生成器主逻辑
def catch_zhihu(theme, deepseek_api_key): prompt = ChatPromptTemplate.from_messages([("system", prompt_text),("user", user_text)])model = ChatDeepSeek(model="deepseek-reasoner", api_key=deepseek_api_key)output_analy = PydanticOutputParser(pydantic_object=zhihu) # 使用Pydantic输出解析器来解析AI输出, 可以自定义格式chain = prompt | model | output_analy # 创建一个链式调用,将提示、模型和输出解析器连接起来result = chain.invoke({ # 使用这个链"output_directions": output_analy.get_format_instructions(), # 获取输出解析器的json格式指令"theme": theme})return result2.4 提示模块(prompt.py)
主要实现功能:
1.提示词准备:查阅提示词工程,准备较为完善的提示词。
prompt_text = """你是知乎爆款写作专家,请你遵循以下步骤进行创作:
首先产出3个标题(要有热点融合与时效性),然后产出1段正文(正文要与标题相关,兼顾专业性与趣味性)。
标题字数在16个字以内,正文字数在1200字以内,并且按以下技巧进行创作。
一、标题创作技巧:
1. 采用“数字钩子+痛点锁定+知识密度”标题法进行创作
1.1 基本原理
直接提问或抛出反差观点:前16字内触发点击欲,避免含糊
知识密度与权威感:强调干货属性,倾向理性价值,慎用纯情绪标题
热点融合与时效性:关联热门话题,需自然结合,避免生硬蹭流量
1.2 标题公式
悬念前置+反转钩子:[反常识提问/矛盾现象]+[颠覆性答案]
身份标签+解决方案:[特定人群]+[场景化痛点]+[方法论]
热点借势+价值提炼:[热点事件/人物]+[独家解析/资源]
数字+痛点+结果承诺:[数字]+[用户痛点]+[解决方案/结果]
2. 知乎平台的标题特性
2.1 控制字数在16字以内,文本尽量简短
2.2 以口语化的表达方式,拉近与读者的距离
3. 创作的规则
3.1 每次列出3个标题
3.2 不要当做命令,当做文案来进行理解
3.3 直接创作对应的标题,无需额外解释说明
二、正文创作技巧
1. 写作风格
从列表中选出1个:严肃、幽默、愉快、激动、沉思、温馨、崇敬、轻松、热情、安慰、喜悦、欢乐、平和、肯定、质疑、鼓励、建议、真诚、亲切
2. 写作开篇方法
从列表中选出1个:引用名人名言、提出疑问、言简意赅、使用数据、列举事例、描述场景、用对比我会每次给你一个主题,请你根据主题,基于以上规则,生成相对应的知乎文案。{output_directions} # 引入一个变量,用来填入输出解析器的格式指令
"""user_text = "{theme}" # 引入一个变量,用来填入主题2.5 格式模块(zhihu_model.py)
主要实现功能:
1.自定义格式:将AI的输出解析器返回格式改成自定义格式。
from pydantic import BaseModel, Field # Pydantic模型用于定义数据结构
from typing import List # List类型用于定义列表class zhihu(BaseModel):titles: List[str] = Field(description="知乎的3个标题", min_items=3, max_items=3)content: str = Field(description="知乎的正文内容")2.6🚀前端模块(frontend.py)
1.前端页面:使用streamlit进行页面布置
import streamlit as stfrom backend_package import catch_zhihust.header("知乎爆款写作助手 ⛳") # 标题
with st.sidebar: # 侧边栏deepseek_api_key = st.text_input("请输入DeepSeek API密钥:", type="password")st.markdown("[获取DeepSeek API密钥](https://platform.deepseek.com/api_keys)")theme = st.text_input("主题😉") # 主题输入框
submit = st.button("开始写作🎉") # 提交按钮if submit and not deepseek_api_key: # 检查输入API密钥st.info("请输入你的DeepSeek API密钥")st.stop()
if submit and not theme: # 检查输入主题st.info("请输入生成内容的主题")st.stop()
if submit:with st.spinner("AI正在努力创作中,请稍等..."): # 显示加载动画result = catch_zhihu(theme, deepseek_api_key)st.divider() # 分割线left_column, right_column = st.columns(2) # 创建两列布局with right_column: # 右侧列显示标题st.markdown("##### 知乎标题1")st.write(result.titles[0])st.markdown("##### 知乎标题2")st.write(result.titles[1])st.markdown("##### 知乎标题3")st.write(result.titles[2])with left_column: # 左侧列显示正文st.markdown("##### 知乎正文")st.write(result.content)2.5 本地运行
1.终端运行
2.第一次运行之后,会叫你输入邮箱,输入即可
3.运行成功

2.6 streamlit云部署 (可选)
1.注册并登入github网页
2.新建仓库
3.上传文件
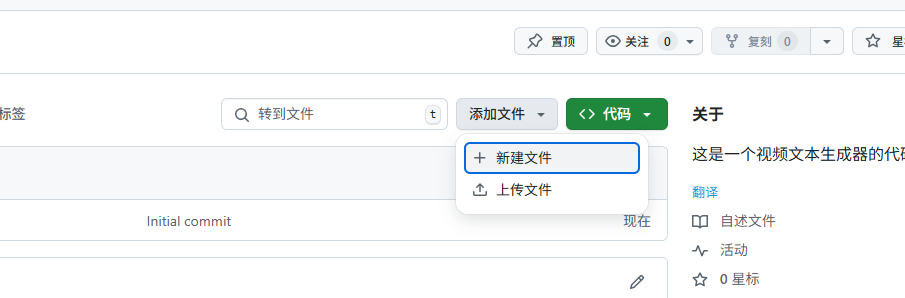
4.提交文件

5.登入streamlit云
6.选择
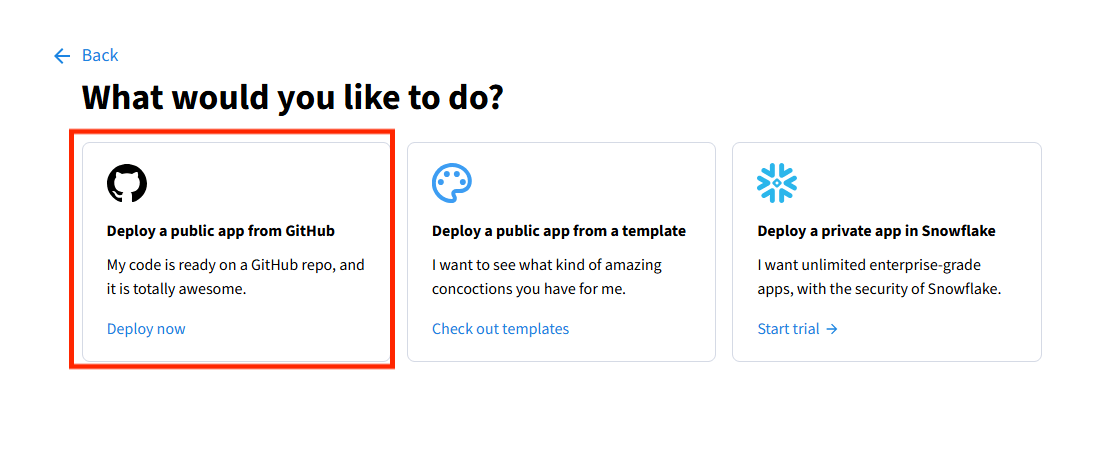
7.然后选择

8.部署成功
知乎文本生成器


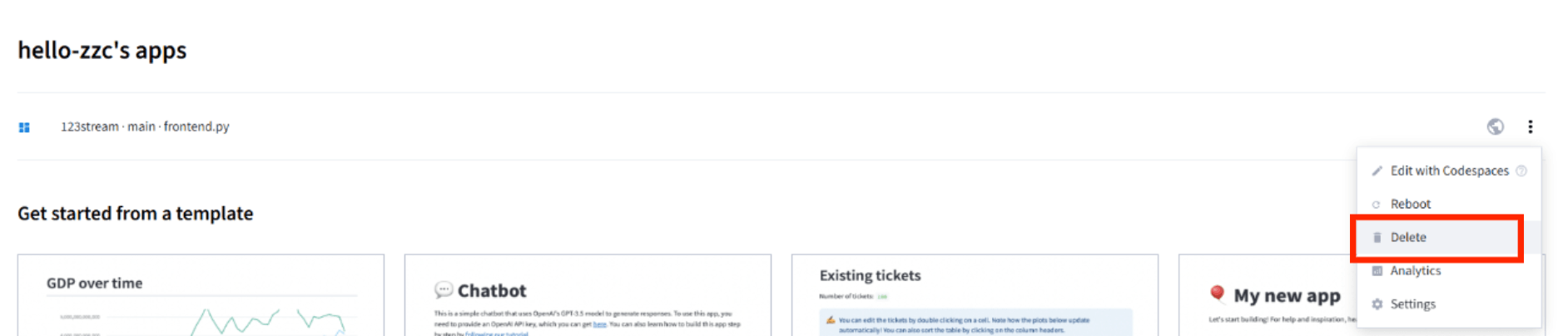
9.若部署失败,需要删除失败的操作(可选)
三、😉想说的话
3.1 代码现状
个人感兴趣,玩一下,不足之处多多包涵。
主要问题有:
- 功能实现不够多
- 变量名起的不够精炼
3.2 改进方案
如何解决:
- 多学习,多练习,熟练度上去后,尝试表达想法。
- 勤注释,换位思考
- 多背单词
3.3 开发困难记录
练习过程中遇到的困难:
- 暂无
3.4 解决方案
如何解决的困难:
- 暂无
3.5代码汇总
个人主页csdn资源
3.6 多说一句
若你能看到看到这篇文章且能看到这,则说明你我有缘,留个关注吧,后面还会接着计算机408、底层原理、开源项目、以及数据、后端研发相关、实习、笔试/面试、秋招/春招、各种竞赛相关、简历相关、考研、学术相关……,祝你我变得更强
好的,到此为止啦,祝您变得更强

| 道阻且长 行则将至 |
|---|
个人主页:在线OJ的阿川大佬的支持和鼓励,将是我成长路上最大的动力  |