【三维重建】无位姿图像的大场景On-the-fly重建

标题:《On-the-fly Reconstruction for Large-Scale Novel View Synthesis from Unposed Images》
项目:https://repo-sam.inria.fr/nerphys/on-the-fly-nvs/
文章目录
- 摘要
- 一、引言
- 二、相关工作
- 三、算法
- 3.1 轻量的初始位姿估计
- 3.2 采样高斯基元
- 3.3 联合位姿和高斯优化
- 3.4 可扩展的增量高斯重建
- 四、实验
- 新视图合成质量
摘要
辐射场方法,如3D高斯喷溅(3DGS),能够从照片中轻松重建图像,支持自由视角导航。然而,使用运动结构和3DGS优化进行姿态估计,在拍摄完成后仍需几分钟到几小时的计算时间。SLAM方法与3DGS结合虽然速度快,但在处理宽基线相机和大型场景时存在困难。我们提出了一种即时方法,可以在拍摄后立即生成相机姿态和训练好的3DGS模型。该方法适用于密集且宽基线的有序照片序列和大规模场景。为此,我们首先引入了fast initial pose estimation,利用学习到的特征,和GPU友好的mini bundle adjustment。接着,我们引入了高斯原语位置和形状的直接采样技术,根据需要逐步生成原语,显著加快了训练速度。这两个高效的步骤能够快速且稳健地联合优化姿态和高斯基元。我们的增量方法通过引入可扩展的辐射场构建,逐步聚类3DGS 原语,将其存储在锚点中,并从GPU加载这些基元,从而处理大规模场景。聚类后的原语会逐步合并,确保在任何视角下都能保持3DGS所需的适当尺度。
一、引言
略
二、相关工作
略
三、算法
我们提出了一种on-the-fly的快速方法,用于估计相机姿态并计算完整的辐射场,该方法设计用于处理大型场景。我们的方法包含四个主要部分:
- 1) 一种快速但近似的初始姿态估计,通过精心设计,使GPU友好型的小束调整成为可能;
- 2) 一种直接采样方法,通过估计每个像素生成高斯的概率来确定高斯基元的位置和形状,显著减少了对密度化的需要;
- 3) 一种高效的姿态和3D几何结构(3DGS)联合优化方法,得益于前两步,这种方法改进了初始的姿态和辐射场版本;
- 4) 一种在线可扩展的优化方法,使用滑动的锚点集逐步在空间中聚类3DGS基元,从而能够处理大规模场景。图2概述了这些步骤。
3.1 轻量的初始位姿估计
我们首先计算出近似的初始姿态,这些姿态将在后续通过联合优化进一步改进;因此,我们的设计更侧重于速度而非灵活性。具体来说,为了充分利用GPU,我们首先使用有限数量的关键点,减少GPU上的内存访问成本;其次,我们将问题建模为固定大小的问题,以利用GPU核心的并行处理能力。因此,初始姿态估计分为 三个阶段:特征提取、引导(bootstrapping)和后续帧估计 。
特征提取 。针对每张输入图像,应用了由Potje等人(2024)开发的快速特征关键点检测器和描述符,每帧生成6144个关键点。
bootstrapping 。首先等待前 N i n i t N_{init} Ninit个初始帧到达,然后对每对这些帧(实验中初始帧数为8)进行exhaustive matching。通过最小化重投影误差,从这些匹配中优化焦距、位姿和3D关键点的位置。按照标准做法,我们采用Levenberg-Marquardt优化方法[Levenberg 1944;Madsen et al. 2004;Marquardt 1963]来实现这一过程。与其它方法[如Matsuki et al. 2024]所使用的全3D全局光照渲染SGD优化相比,我们的mini bundle adjustment更加轻量且高效。
高效的 solvers 核心在于,确保每个3D点都能从固定数量的图像中被捕捉。这样可以生成一个大小固定的稀疏雅可比矩阵J,用于表示重建误差,该矩阵易于构建,并且能够在GPU上实现高效的求解方法。具体的,计算了相机姿态 J c a m J_{cam} Jcam和3D点位置 J x y z J_{xyz} Jxyz关于重投影误差的雅可比矩阵,类似于standard solvers,矩阵J由 J c a m J_{cam} Jcam和 J x y z J_{xyz} Jxyz构建,两者均为稀疏矩阵。由于我们固定了non-zero block的大小,可以预先分配内存,并以fixed-size的计算独立处理每个块,从而利用GPU的批处理能力。这种简化的布局避免了使用像Ceres [Agarwal等2023]这样的常用于bundle adjustment灵活求解器。
后续帧的估计 。在每个新帧中,我们将该帧的关键点与最后注册的 N N N个帧(实验中设为6)的关键点进行匹配。为了建立3D-2D对应关系,我们利用已知的(之前的)相机姿态和三角测量技术,估计每个过去帧中关键点的3D位置。如果这种估计失败,我们将使用渲染的深度信息。接着,我们利用这些3D-2D对应关系,通过GPU并行RANSAC算法和最小束调整作为估计器来估计相机姿态和内点。完成初始化后,我们使用所有内点运行20次最小束调整迭代,以微调姿态。最后,为每个三角化关键点创建一个三维高斯基元。尽管由于transitive matches,一个关键点可以从多张图像中识别,但我们仅将监督限制在最后 N N N帧注册的图像上,以保持问题的固定大小。
为了确保方法在复杂场景(如纯旋转、尺度漂移)中仍能有效恢复,当最后二十个摄像头之间的平均距离低于0.1/3时,我们会重新执行bootstrapping。若投影误差小于1像素,我们将通过与先前估计的姿态对齐,更新初始帧的姿态参数。
3.2 采样高斯基元
为了避免密集化带来的开销和不足,我们提出了一种针对高斯基元的直接采样方法。每一帧采样一组密集的3D高斯基元,需满足两个条件: 1)覆盖之前未见过的区域,或在场景的粗略重建部分添加更多细节; 2)避免在任何给定区域内放置超过实际需要的基元。采样方法步骤如图5所示。
现有的3DGS-SLAM方法 通常通过两种方式处理高斯初始化:一种是将高斯分布均匀地分布在图像中[Sun等人,2024a],另一种是将高斯分布放置在关键点上[Huang等人,2024]。然而,均匀分布的方法无法适应输入图像的特定特征,而仅使用关键点则往往过于稀疏,需要进一步密集化,这会导致优化时间延长和原始元素数量增加。
在特定像素生成原始图元的两个标准:1) 高斯基元应集中在不连续性的高频细节区域;2)高斯基元应位于每个不连续性的两侧,以准确表示边缘(见图3)。


因此,给定像素生成原始基元的概率基于局部空间梯度。使用高斯拉普拉斯算子(LoG)的范数 [Haralock和Shapiro 1991] 作为概率的代理,为像素 ( x , y ) (x,y) (x,y)分配一个初始概率 p p p,表示在该位置生成原始基元的可能性。

为了避免在已有足够原始图像表示边缘的区域放置多余的高斯基元,我们从新帧的视角渲染了一个视图 I ~ \tilde{I} I~。接着,我们计算了与等式1中相同的量,但这次是针对渲染后的图像 I ~ \tilde{I} I~,提供了一个像素级别的惩罚 P ~ \tilde{P} P~,以减少在已重建区域放置新高斯分布的概率:

在内容已重建的区域,参数 P ~ \tilde{P} P~将与 P L P_L PL相似,将降低在已由渲染图像良好表示的区域中生成基本元素的概率。因此,在像素(x,y)处添加高斯的最终概率为:

高斯基元的深度 。使用Depth-Anything-2 来估计单目深度,并使用Kerbl等[2024]描述的相同方法与三角化匹配对齐。然后采用以单目深度为中心的 standard correlation volume 方法来估计深度。这种引导匹配至关重要,因为单目深度可能会出现显著误差。计算的具体细节见附录。

基元的尺寸参数。3DGS基元的形状尺度是根据与最近3D的三个近邻的平均距离来初始化的。然而,这种方法容易在不连续区域周围产生过大的高斯分布,并且对异常值非常敏感,导致初始化结果与输入帧的匹配度较差(见图6)。

为了解决这一问题,我们首先在图像空间中估算一个合适的尺度。根据等式(1)的概率,我们计算了假设像素 ( x , y ) (x,y) (x,y)周围存在强度为 P L ( x , y ) P_L(x,y) PL(x,y)的局部二维泊松过程时,到最近邻的预期距离:

这一计算利用了惩罚项之前的概率 P L P_L PL,因为高惩罚意味着已经存在许多高斯分布。
接下来,我们利用相机的焦距 f f f和像素的估计深度 z z z,将像素空间转换到三维空间: s = z s ′ f s= \frac {zs'}{f} s=fzs′。这种方法无需进行最近邻搜索,就能提供合适的尺度,因此非常高效。随后,我们将 s s s值分配给三维高斯尺度向量 S S S的每个维度。
3.3 联合位姿和高斯优化
对于每幅新图,现在获得了初始估计的pose,以及高斯基元的position与size的直接采样结果。
对于每幅接收到的新图像,仅当关键点的median displacement(中位位移)超过屏幕宽度3%时才注册该帧;这些被注册的帧即为关键帧。这种做法确保仅使用具有显著视差的帧,从而提升几何估计精度并避免冗余帧。
每幅新注册图像,运行30次高斯泼溅优化迭代,采用[Mallick等人2024年]提出的快速反向传播与稀疏-Adam优化器来提升迭代速度。
学习率按高斯分布分配,衰减率根据每个高斯分布引入的时间点进行调整。相机位姿采用6D旋转表示法[Hempel等人2022]进行联合优化。位姿会接收来自高斯位置和旋转优化的梯度更新,但不接收球谐函数的更新,因为通过视角相关颜色信息传播梯度会降低位姿质量[Liu等人2023]。
为优先捕捉低频场景细节、加速优化过程并避免陷入局部极小值,我们采用coarse-to-fine 的渐进策略[Huang等人2024;Sun等人2024a]。具体,每当新增图像时,先以 2 l 2^l 2l倍降采样(实验中 l l l=3)进行训练。随后每进行五次迭代,就将 l l l值递减,直至恢复图像原始尺寸。我们采用恰当的滤波技术[Yu等人2024]来确保多尺度训练的正确性。虽然不执行稠密化操作,但如原始3D高斯泼溅(3DGS)方法所述,我们实施了透明度筛选机制——剔除具有极低不透明度的图元
我们初始的姿态估计能避免在联合优化姿态和高斯分布时陷入局部极小值,这使得相比基于SLAM的方法,我们能处理更宽基线(相机或视角之间的相对运动较大)的场景。
3.4 可扩展的增量高斯重建
在图像处理过程中,维护一组包含当前正在优化和渲染的基元的"Active Gaussians"。经过一段时间后,早期放置和优化的图元在当前相机视角下可能显得非常微小甚至亚像素级尺寸,对渲染图像的贡献微乎其微。这些基元会从GPU卸载至CPU内存,以anchor形式存储。由此形成的场景表征是一组可按需重新加载至GPU的聚类集合。该聚类流程包含三个步骤:1)检测创建锚点的时机 2)执行聚类与图元合并 3)采用滑动窗口进行增量式优化。
1.检测创建anchor的时机。我们将相机 i i i中基元的尺寸 S S S定义为 S / D S/D S/D,其中 D D D表示基元中心到相机的距离, S S S为高斯分布的尺度。当处于序列中的相机 i i i时,检查在相机 i − 1 i-1 i−1视角下是否有超过40%的Active Gaussians的尺寸 S < τ m i n S<\tau_{min} S<τmin( τ m i n \tau_{min} τmin=1像素)。若满足条件,则触发更新以创建anchor并合并这些高斯。
2.聚类与基元合并。更新前的Active Gaussians被复制至新anchor中,存储其位置信息、高斯基元集合、其优化状态以及用于优化的关键帧。
合并对远距离区域贡献较小的高斯分布,以获得粗略的表示:随机选取检测步骤中被判定为过于精细的第 1 k + 1 \frac {1}{k+1} k+11个基元,然后采用Papantonakis等人[2024]的方法为每个选定基元寻找 k k k个最近邻,并按照Kerbl等人[2024]采用的方案进行合并(此处 k = 3 k=3 k=3)。其余所有基元均保持原状不变
3.滑动窗口增量优化。合并过程使我们获得场景的粗略表示,该表示成为新的活跃高斯集。该集合将在下一次迭代中进行优化。后续聚类步骤将创建新的锚点,而由于合并操作,远处内容将逐渐变得粗糙。在采集路径的末端,活跃高斯集被存储于最后一个锚点中。补充视频中展示了锚点的使用方式。
当我们构建完场景的完全表示(不同尺度的表征通过anchor存储)后,就能在空间中自由导航。为了基于该表征实现新视角的渲染,我们会选取距离相机当前位置最近的anchor,并渲染其包含的高斯元素。当两个anchor与相机的距离相近时,我们将对两者的高斯元素进行混合处理。假设相机视点下最近的两个anchor距离分别为 d 1 d₁ d1和 d 2 d₂ d2(满足 d 1 ≤ d 2 d₁≤d₂ d1≤d2),定义重叠参数 o ∈ ( 0 , 0.5 ) o∈(0,0.5) o∈(0,0.5)(例如 o = 0.1 o=0.1 o=0.1),计算比率 r = d 1 / d 2 r=d₁/d₂ r=d1/d2。若 r ≤ 1 − o r≤1−o r≤1−o,则最近anchor的混合权重为1,另一anchor权重为0;否则将进行线性权重混合:

四、实验
我们在3DGS代码库的基础上实现了我们的方法,添加了一个基于Python的交互式查看器,用于训练和优化后的在线可视化。源代码:https://repo-sam.inria.fr/nerphys/on-the-fly-nvs/.
数据集。使用常用于SLAM方法评估的密集采集TUM数据集[Sturm等人,2012];针对中等宽基线与较大尺度采集,选用Static Hikes数据集[Meuleman等人,2023];针对NVS宽基线采集,测试MipNeRF360数据集[Barron等人,2022]的部分场景;针对大尺度场景,评估改编自H3DGS[Kerbl等人,2024]的SmallCity和Wayve场景(仅使用前置摄像头)。我们筛选了这些数据集中具有有序图像序列的场景——这是本方法的必要条件。此外,我们还使用佳能EOS R6相机以每秒3帧的驾驶模式采集了大型数据集CityWalk。TUM数据集(fr1,fr2,fr3)平均图像数为2289帧,MipNeRF360数据集(花园/柜台/盆景)为239帧,StaticHikes数据集(森林1/森林2/大学2)为972帧。H3DGS数据集平均2285帧;自采集的CityWalk场景达4055帧,其空间跨度达1.1公里为当前最大。
配置。英特尔酷睿i9 14900K处理器、128GB内存和英伟达RTX 4090显卡的工作站上运行了所有测试与评估。若需采用不同配置(例如当方法需要更多显存时),我们会通过在每台设备上调用1000次CUDA光栅化程序来将耗时数据折算至基准配置。所有场景均采用同一组参数进行测试。
对比方法。我们与两类方法进行了比较。首先对比的是无需相机位姿输入的最先进方法,SLAM/3DGS和无位姿3DGS解决方案(Photo-SLAM[黄等人2024]、DROIDSplat[霍迈尔等人2024]、MonoGS[松木等人2024]以及最终入选的CF-3DGS[傅等人2024])进行了对比。
我们还提出了两个基准方法。首先,标准3DGS(即从官方github仓库发布的版本,使用标准COLMAP参数)在7K和30K次迭代中的表现;报告的时间是所有COLMAP处理和3DGS优化的总时间。第二个基准方法采用了Taming 3DGS[Malick等人,2024],这是目前最快的3DGS优化方法,结合了最佳努力加速SfM姿态估计的方法,使用GLOMAP [Pan等人,2024]。具体来说,我们运行了COLMAP特征提取器、顺序匹配器,然后使用GLOMAP映射器来获取姿态和SfM点。这一基准方法可以视为当前最快的最佳实践,是非增量的解决方案,用于姿态估计和3DGS优化。由于TUM数据集的捕获更为密集,我们在较少的图像上运行了不选择关键帧的方法(Taming 3DGS、3DGS和COLMAP Free 3DGS)。具体而言,我们分别选择了fr1、fr2和fr3的每第3帧、第15帧和第10帧。这种方法使总帧数更接近我们注册的关键帧数量,同时保留了测试集中的所有图像。请注意,我们方法报告的时间包括了自动选择关键帧的时间。
DROID-Splat和CF-3DGS无法处理全分辨率图像。因此,我们提供了一个单独的表格(表2),列出了这些方法在每个数据集上的最佳分辨率(TUM数据集为446x336,MipNeRF360和StaticHikes数据集为640像素)。我们的方法需要更高分辨率的输入,因为XFeat [Potje等,2024]在1到2百万像素范围内表现最佳。为了进行比较,我们在使用我们的方法处理图像之前,将调整后的图像在两个维度上放大两倍。然后,我们在适当降采样的图像上报告了指标。另一个问题是测试图像集的指定。不同的方法使用不同的方法,因为在某些情况下,并非所有图像都有估计的姿态,因此即使对于相同的场景,每个方法的测试集也往往不同。我们定义了一个单一的评估协议,使用每第n张图像作为测试视图,其中n对于MipNeRF360和StaticHikes是8和10(根据其作者的建议),而对于TUM是30,因为帧之间的基线较小。这要求对每种方法进行特定的修改。
第二个比较,针对的是大规模3D场景的方法。具体来说,我们与H3DGS [Kerbl等人,2024] 进行了对比。在此次对比中,我们使用了SmallCity和Wayve数据集以及我们的CityWalk数据集中的前摄像头。还评估了测试视图的位姿估计质量,按照标准做法使用COLMAP姿态作为“伪真实”值,采用RMSE APE和RPE指标[Grupp,2017]
新视图合成质量
表1和表2展示了SLAM方法,按数据集类型划分的平均结果。指标有PSNR、SSIM和LPIPS,以及平均时间,即姿态估计和3DGS优化的总时间。GLOMAP姿态优化的平均时间分别为:TUM(图森大学)0:02:02,MipNeRF360(MipNeRF360)0:07:17,StaticHikes(静态徒步)1:00:26。对于TUM,我们使用了图像子集进行CF-3DGS和SfM方法的测试,因为这些方法不包含关键帧,而其他方法则处理所有图像。此外,基于SfM的方法需要在处理前获取整个数据集,因为这些方法的映射器会重新排列图像,这阻碍了实时反馈和在捕捉结束后立即获得重建。
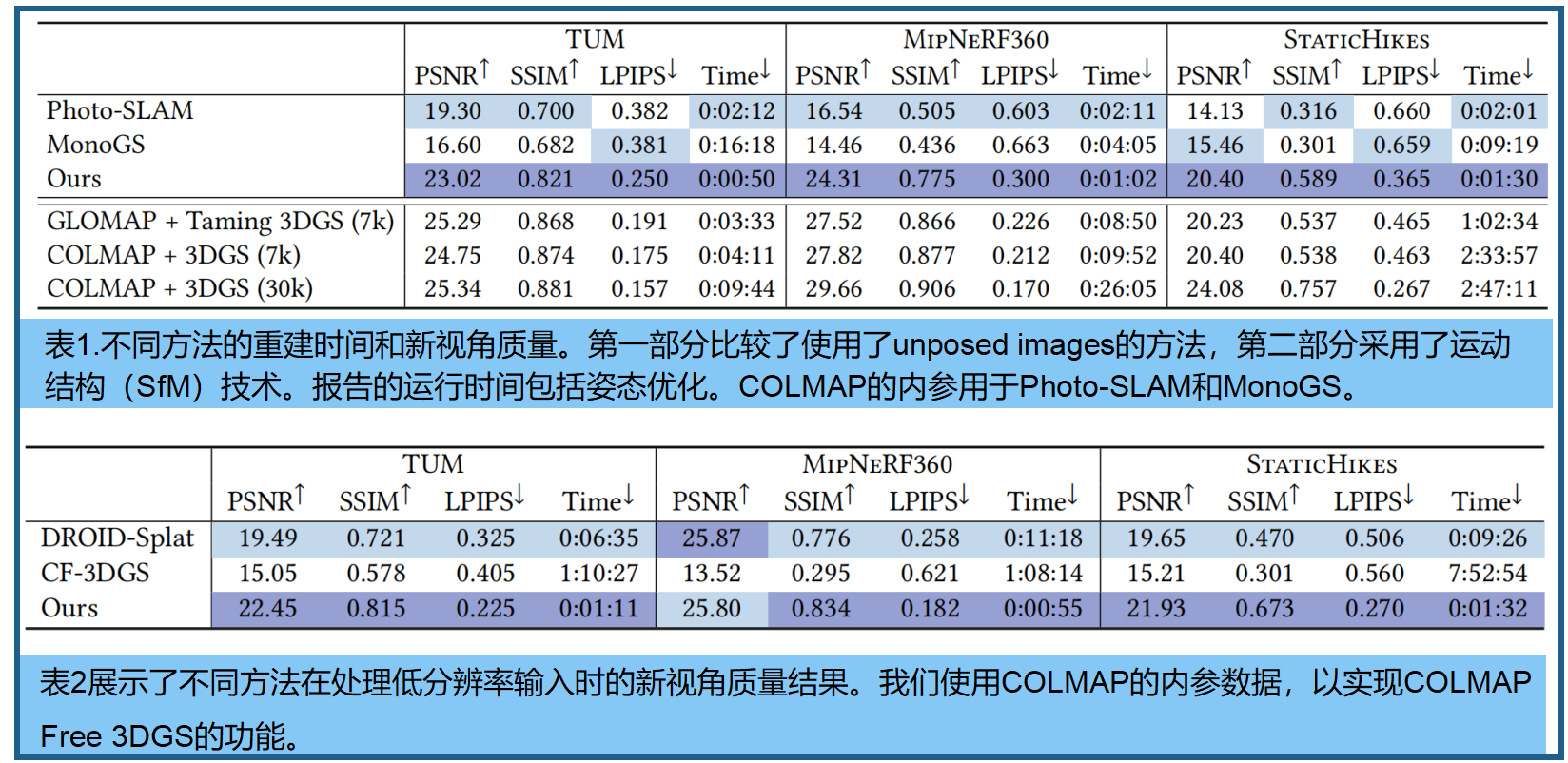
图7和图8中展示了定性结果。DROID-Splat的视觉质量表现良好;我们的方法虽然通常更清晰,但保真度可能略低。SLAM方法在设计用于密集捕捉的场景中表现出色,但随着相机基线变宽,视觉质量可能会下降,甚至导致方法失效。Taming 3DGS和标准3DGS的视觉质量更好,适用于所有场景,但由于之前提到的高计算开销,它们不适合我们的即时重建需求。


在训练处理完所有视图后,我们可以利用已识别的关键帧来微调3DGS和相机。为此,我们逐一加载这些关键帧。对于每个关键帧,通过随机选取其所有关键帧,进一步优化相关相机和高斯分布的参数。由于仅执行3DGS优化,这一过程足够快速,因此可以重复多次以找到理想的开销与质量平衡。表3显示,我们达到了Taming 3DGS(7k)的质量水平。然而,要达到更高的质量,则需要更复杂的解决方案;我们将在第6节中讨论这一未来的工作方向。

大规模场景的结果(与H3DGS对比)。从表4可以看出,使用SfM方法进行相机校准的额外成本随着场景规模的增大而显著增加。捕捉CityWalk场景耗时30分钟,这比我们的方法处理该场景所需的时间(25分钟)要长;而使用H3DGS(少数能够处理如此大规模场景的方法之一),在捕捉完成后需要22小时的处理时间。此外,姿态估计的质量非常低,导致路径中多个部分的新视角合成失败。

位姿估计质量。我们使用表5中的APE和RPE指标来评估姿态估计的质量。我们的方法在MipNeRF360数据集上表现良好,但在TUM数据集上遇到了困难。这主要是因为该视频的拍摄质量较差,许多帧模糊不清,并且存在显著的滚动快门效应,而我们没有对此进行专门处理,导致了异常姿态的出现。SLAM方法通常针对此数据集进行了优化。此外,我们还与基于Transformer的Spann3r方法进行了对比,其姿态估计质量低于我们的方法,原因是存在较大的姿态漂移。

表6详细列出了算法在Garden数据集上各步骤的运行时间。每个步骤都会针对每一个关键帧执行。对于每个输入帧,都会进行特征检测和提取,以判断是否应保留为关键帧。我们分别以40帧/秒、4帧/秒和9帧/秒的速度处理输入图像,并将9%、86%和31%的图像分别作为TUM、MipNeRF360和StaticHikes的关键帧。

#pic_center =80%x80%
d \sqrt{d} d 1 8 \frac {1}{8} 81 x ˉ \bar{x} xˉ D ^ \hat{D} D^ I ~ \tilde{I} I~ ϵ \epsilon ϵ
ϕ \phi ϕ ∏ \prod ∏