【DRL】强化学习中的概念和术语
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn]
如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~
深度强化学习(Deep Reinforcement Learning, DRL)是强化学习(RL)与深度学习(DL)的交叉领域,其核心在于利用深度学习的表征能力处理 RL 中的高维状态空间、复杂决策问题。传统 RL 在面对图像、语音等非结构化数据时难以有效提取特征,而 DRL 通过神经网络(如 CNN、RNN、Transformer)自动学习状态表示,实现了从感知到决策的端到端优化。
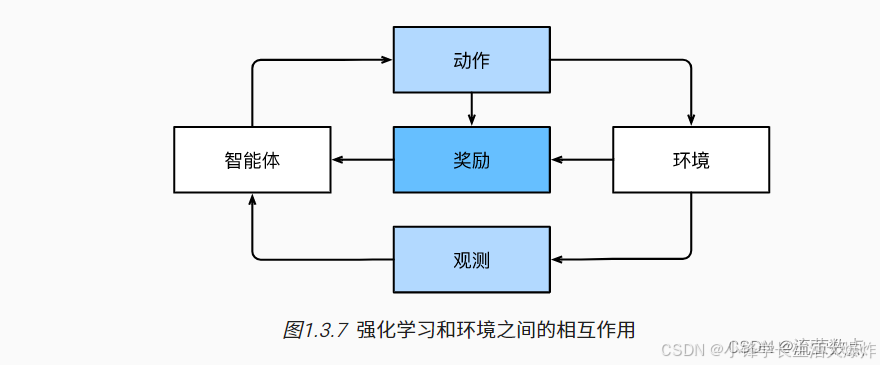
DRL 算法可按核心思想分为三大类,每类均有代表性算法及改进版本:
- 基于策略(Policy-Based):直接优化策略函数。在 DRL 中,最终目标是找到能最大化累积奖励的最优策略。Policy Gradients 方法是直接对策略进行建模和学习,将策略表示为一个参数化的函数,比如神经网络,通过调整参数来优化策略,而不是像基于值函数的方法那样间接获取策略。例如,对于一个机器人行走的任务,策略网络的输入可能是机器人当前的状态(如关节角度、位置等),输出是机器人下一步的动作(如腿部的运动指令)。Policy Gradients 直接学习如何根据状态产生最优的动作,而不是先学习值函数再根据值函数来确定动作。以近端策略优化(PPO)算法为例,它通过重要性采样复用旧策略数据,并采用裁剪目标函数约束策略更新幅度,在连续动作空间任务中展现出高效的样本利用率与稳定的收敛性 ,与基于价值的方法形成鲜明对比。
- 基于价值(Value-Based):学习最优动作价值。核心思想是不直接学习策略,而是通过构建价值函数来评估在状态s下执行动作a的优劣 ,进而通过贪心策略(如 ϵ-greedy)选择动作。代表算法为深度 Q 网络(DQN),它用 CNN 处理游戏图像,结合经验回放和目标网络,首次在 Atari 游戏中超越人类水平。改进算法包括:
- Double DQN:解耦动作选择与价值评估,缓解最大化偏差。
- Dueling DQN:分离价值函数的状态价值和动作优势,提高收敛速度。
- Rainbow DQN:融合多种改进技术(如优先经验回放、分布式价值估计)。
(1) 状态(State, s)是什么?
- 表示智能体在环境中的当前信息,包含做出决策所需的全部必要数据。
- 可以是离散的(如围棋棋盘布局)或连续的(如机器人传感器的数值)。
- 在部分可观测马尔可夫决策过程(POMDP)中,智能体可能无法获取完整状态(仅观测到部分观测值 o),但在完全可观测场景(如经典 RL)中,状态即观测值。
(2) 观察(Observation, o)是什么?
- 智能体从环境中实际感知到的信息,它可能只是状态的部分或噪声版本。
- 在完全可观测环境中(如经典棋盘游戏),观察等于状态(o_t = s_t),此时环境被建模为马尔可夫决策过程(MDP)。
- 在部分可观测环境中(如机器人仅通过噪声传感器感知环境),观察仅包含状态的部分信息,甚至可能存在观测噪声,此时环境被建模为POMDP。

(3) 动作(Action, a)是什么?
- 智能体在某一状态下可执行的操作,由环境允许的动作空间决定。
- 离散动作:有限个可选动作(如 “上 / 下 / 左 / 右” 或 “开火 / 移动”)。
- 连续动作:无限连续的动作空间(如机械臂的旋转角度、自动驾驶的方向盘转角)。

(4) 动作空间(Action Spaces)是什么?
不同的环境允许不同类型的操作。给定环境中所有有效动作的集合通常称为动作空间 。一些环境,如 Atari 和 Go,具有离散的动作空间 ,其中只有有限数量的动作可供智能体使用。其他环境,比如智能体在物理世界中控制机器人的地方,有连续的动作空间 。在连续空间中,动作是实值向量。
(5) 轨迹(Trajectory, \tau)是什么?
- 智能体与环境交互的完整序列,由状态和行动交替组成,始于初始状态,终于终止状态(若环境为 episodio 式)。
- 数学形式:\tau = (s_0, a_0, s_1, a_1, \dots, s_T) 其中 s_t 是时刻 t 的状态,a_t 是对应行动,T 为终止时刻(可能为无穷大,对应连续型环境)。
- 意义: 轨迹体现了智能体的决策路径,其概率由策略和环境动态(状态转移概率 P(s'|s,a))共同决定。
(6) 策略(policy, \pi(a|s))是什么?
简单来说,策略就是agent在不同环境状态下决定采取何种动作的规则或方法。比如在一个游戏中,智能体面对敌人来袭的状态,策略会告诉它是选择攻击、躲避还是防御。
策略可以是确定性的,即给定一个状态,明确指定要采取的动作;也可以是随机性的,给出在该状态下采取每个可能动作的概率分布。例如,在自动驾驶中,看到红灯时,确定性策略是停车;而在股票交易中,随机性策略可能是根据当前市场状态,以 60% 的概率买入某只股票,40% 的概率保持观望。
确定性策略 (Deterministic Policies)
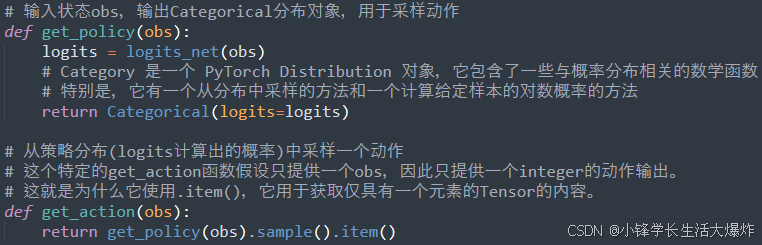
下面的代码表示用于使用 torch.nn 包为 PyTorch 中的连续动作空间构建简单的确定性策略:
pi_net = nn.Sequential(nn.Linear(obs_dim, 64),nn.Tanh(),nn.Linear(64, 64),nn.Tanh(),nn.Linear(64, act_dim))这构建了一个多层感知器网络,其中有两个大小为 64 的隐藏层和 \tanh 激活函数。如果 obs 是一个包含一批观测值的 Numpy 数组,pi_net 可以用来获取一批动作,如下所示:
obs_tensor = torch.as_tensor(obs, dtype=torch.float32) actions = pi_net(obs_tensor)随机策略 (Stochastic Policies)
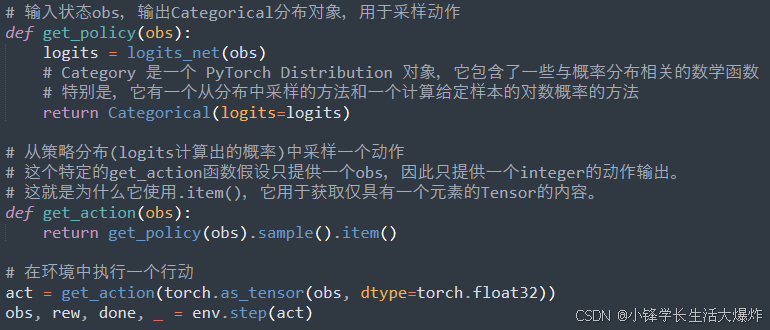
深度强化学习中最常见的两种随机策略是分类策略和对角高斯策略 。分类策略可用于离散动作空间,而对角高斯策略可用于连续动作空间。两个关键计算对于使用和训练随机策略至关重要:从策略中采样动作 和 计算特定动作的log likelihoods。
- 分类策略就像是对离散行为的分类器。为分类策略构建神经网络的方式与分类器相同:输入是观察,然后是一些层(可能是卷积或密集连接,取决于输入的类型),然后有一个最终的线性层,为每个动作提供 logits,然后是 softmax 将 logits 转换为概率。
- 多元高斯分布(或多元正态分布)由均值向量和协方差矩阵描述。对角高斯分布是协方差矩阵仅在对角线上具有条目的特殊情况。因此,我们可以用向量来表示它。对角高斯策略总是有一个神经网络,从观察映射到平均动作。
(7) 奖励(Reward, r)是什么?
- 环境在智能体执行动作后返回的标量反馈信号,衡量该动作的 “好坏”。
- 奖励是强化学习的核心驱动力,智能体的目标是最大化累积奖励(通常为折扣累积奖励 \sum_{t=0}^\infty \gamma^t r_t,其中 \gamma \in [0,1] 为折扣因子)。
- 奖励设计需符合任务目标,可能需要领域知识(如机器人导航中,到达目标点奖励 + 100,碰撞障碍物奖励 - 50)。
(8) 价值函数(Value Function, V^\pi(s))是什么?
- 评估状态s的长期价值,即从状态s出发,遵循策略\pi所能获得的期望累积奖励。用于评估在某个策略下,从特定状态开始能获得的期望累积奖励。包括状态值函数V(s)和状态-动作值函数Q(s, a)。 V(s) 表示从状态 s 开始,按照给定策略执行能得到的期望总回报;Q(s, a) 表示在状态 s 下执行动作 a ,然后按照给定策略继续执行能得到的期望总回报。例如,在一个寻宝游戏中,状态值函数可以告诉智能体当前位置的价值(即从当前位置开始找到宝藏的期望奖励),而状态-动作值函数可以告诉智能体在当前位置采取某个动作(如向前走、向左转等)后的价值。
- 数学公式:其中期望由策略\(\pi\)和环境动态共同决定。
![]()
- 意义: 价值函数帮助智能体判断 “当前状态的优劣”,是策略评估的核心工具。例如,在状态s下,若V^\pi(s)高,则说明该状态容易获得高奖励。
为何值函数是间接获取策略?
值函数本身并不直接指定智能体在每个状态下应该采取什么动作,而是通过评估不同状态和动作的价值来引导智能体选择最优动作,从而间接确定策略。例如,在基于值函数的强化学习算法中,如 Q-learning,智能体首先学习状态-动作值函数 Q(s, a),然后在每个状态下选择具有最高Q值的动作作为当前的最优动作,这样逐渐形成一个策略。也就是说,先通过学习值函数来了解每个状态-动作对的好坏,再根据这些信息来确定采取什么动作,而不是像直接对策略建模那样直接学习一个从状态到动作的映射。
(9) 行动-价值函数(Action-Value Function, Q^\pi(s,a))是什么?
- 又称Q 函数,评估在状态s下执行动作a后的长期价值,即从状态s执行动作a后,再遵循策略\pi的期望累积奖励。
![]()
- 与价值函数的区别:
- V^\pi(s) 仅依赖状态s,是对状态的整体评估;
- Q^\pi(s,a) 依赖状态s和动作a,用于比较同一状态下不同动作的优劣(如 “在状态s下,选动作a_1还是a_2”)。
- 在 Q-learning 中,智能体直接学习 Q 函数,通过\arg\max_a Q(s,a)选择最优动作,无需显式定义策略。
(10) 策略参数是什么?
用来描述和调整策略的一些变量。如果把策略想象成一个函数,那么策略参数就是这个函数的参数。以神经网络为例,神经网络的权重和偏置就是策略参数。通过调整这些参数,可以改变策略函数的输出,也就是改变智能体在不同状态下选择动作的方式。比如在一个下棋的智能体中,策略参数决定了它在不同棋局状态下选择下一步棋的概率。优化策略参数的目的是让智能体的行为能够最大化累积奖励,也就是让智能体做出最优的决策。

(11) 如何直接对策略进行建模和学习?
- 策略网络:通常使用神经网络来表示策略,将状态作为网络的输入,输出是动作的概率分布(对于随机性策略)或者直接是动作(对于确定性策略)。例如,在一个机器人导航任务中,将机器人当前的位置、周围环境的感知信息等作为策略网络的输入,网络输出机器人下一步移动的方向和速度。

- 基于梯度的优化:定义一个目标函数,通常是期望累积奖励,然后计算目标函数关于策略参数的梯度,利用梯度上升算法来更新策略参数,使得目标函数值不断增大,即策略不断优化。如在训练一个玩游戏的智能体时,根据游戏的得分(奖励)来计算梯度,调整策略网络的参数,让智能体在游戏中表现得越来越好。

- 采样与学习:智能体根据当前的策略与环境进行交互,收集状态、动作和奖励等样本数据。然后基于这些样本估计梯度并更新策略参数。例如,在一个股票交易模拟环境中,智能体根据当前的交易策略进行买卖操作,记录每次操作的状态(如股票价格、市场趋势等)、动作(买入、卖出或持有)和获得的收益(奖励),通过这些数据来改进交易策略。
(12) 优势函数(Advantage Functions)是什么?
有时在强化学习中,我们不需要描述一个动作在绝对意义上有多好,而只需要描述它比其他动作平均好多少。也就是说,我们想知道这种行为的相对优势 。我们用优势函数使这个概念精确化 。对应于策略 \pi 的优势函数 A^{\pi}(s,a) 描述了在状态 s 中采取特定动作 a 比根据 \pi(\cdot|s) 随机选择动作好多少,假设你永远根据 \pi 行动。在数学上,优势函数定义为:
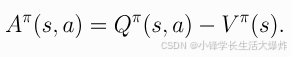
参考资料:
1、Part 1: Key Concepts in RL — Spinning Up documentation