【C++】IO流
C++的IO流

1.回顾C语言输入输出
C语言中我们用到的最频繁的输入输出方式就是scanf ()与printf()。 scanf(): 从标准输入设备(键盘)读取数据,并将值存放在变量中。
printf(): 将指定的文字/字符串输出到标准输出设备(屏幕)。
注意宽度输出和精度输出控制。C语言借助了相应的缓冲区来进行输入与输出
对输入输出缓冲区的理解:
输入输出(I/O)缓冲区是用于暂存数据的内存区域,这些区域用于提高I/O操作的效率。缓冲区可以减少实际的物理I/O操作次数,因为它们允许程序先将数据写入内存缓冲区,然后再一次性地将缓冲区中的数据写入外部设备(如文件、屏幕等),或者从外部设备读取数据到缓冲区,再从缓冲区读取数据。
1.屏蔽低级I/O实现的差异:
概念:低级I/O实现的差异指的是不同操作系统、硬件平台或文件系统在处理输入输出操作时所采用的内部机制和方法的不同
输入输出缓冲区的一个主要作用是提供一个抽象层,使得程序能够以统一的方式进行I/O操作,而不必关心底层操作系统的具体实现。能够增强代码的可移植性和简化编程(不需要深入了解特定操作系统的I/O细节)
2.实现“行”读取的行为:
使用场景:
在计算机的底层,数据通常是以字节流的形式存储和传输的,并没有“行”这个概念。然而,在处理文本数据时,我们经常需要以“行”为单位进行操作,例如读取用户输入、解析文本文件等。
行缓冲:C语言标准库提供了行缓冲机制,使得程序可以以“行”为单位进行读取操作。当输入流(如键盘输入或文件读取)遇到换行符(\n)时,标准库会将从上一个换行符到当前换行符之间的数据作为一个“行”存储在缓冲区中。然后,程序可以使用如fgets()这样的函数一次性读取整“行”。
灵活性:除了行缓冲,标准库还支持全缓冲和无缓冲模式,允许程序根据需要选择最合适的缓冲策略。例如,对于大量的数据传输,可能会选择全缓冲以减少I/O操作的次数;而对于需要即时响应的场景,则可能选择无缓冲模式。在C语言中,标准I/O库(如 <stdio.h>)自动管理缓冲区。
setvbuf():设置流的缓冲区模式。_IOFBF全缓冲 _IONBF无缓冲 _IOLBF行缓冲。
fflush():强制将缓冲区中的数据写入文件或设备。
fopen():在打开文件时可以指定缓冲模式。
系统默认的缓冲模式取决于具体的实现,但大多数情况下,标准输出是行缓冲,标准错误输出是无缓冲或行缓冲,标准输入是全缓冲。对于文流,默认通常是全缓冲。了解这些默认行为有助于我们更好地控制程序的I/O性能和行为。
2.C++IO流
流是什么:
“流”即是流动的意思,是物质从一处向另一处流动的过程,是对一种有序连续且具有方向性的数据( 其单位可以是bit,byte,packet )的抽象描述。
C++流是指信息从外部输入设备(如键盘)向计算机内部(如内存)输入和从内存向外部输出设备(显示器)输出的过程。这种输入输出的过程被形象的比喻为“流”。
C++系统实现了一个庞大的类库,其中ios为基类,其他类都是直接或间接派生自ios类
图中可以看出C++和C语言的IO流函数的对应关系,区别在于:C++
1.运算符重载 operator<<和operator >>
2.自动识别类型(函数重载)
3.面向对象,可以更好支持自定义类型,更形象

C++标准IO流
C++标准库提供了4个全局流对象cin、cout、cerr、clog,使用cout进行标准输出,即数据从内存流向控制台(显示器)。使用cin进行标准输入即数据通过键盘输入到程序中,同时C++标准库还提供了cerr用来进行标准错误的输出,以及clog进行日志的输出,从上图可以看出,cout、cerr、clog是ostream类的三个不同的对象,因此这三个对象现在基本没有区别,只是应用场景不同。
注意:在使用时候必须要包含文件并引入std标准命名空间
一些注意细节:
- cin为缓冲流。键盘输入的数据保存在缓冲区中,当要提取时,是从缓冲区中拿。如果一次输入过多,会留在那儿慢慢用,如果输入错了,必须在回车之前修改,如果回车键按下就无法挽回了。只有把输入缓冲区中的数据取完后,才要求输入新的数据。
处理错误输入时,可以使用 cin.clear() 清除错误标志,使用 cin.ignore() 忽略缓冲区中剩余的输入,并根据需要使用 std::noskipws 禁用空白字符跳过。
- 输入的数据类型必须与要提取的数据类型一致,否则出错。出错只是在流的状态字state中对应位置位(置1),程序继续
C++中,输入输出流(如 cin 和 cout)使用状态字(state)来跟踪流的状态,包括是否出错、是否到达文件末尾(EOF)等。状态字是一个位掩码(bitmask),其中的每个位代表流的一种特定状态。流状态字包括以下几个主要状态:
ios::goodbit:流处于良好状态,没有错误
ios::failbit:输入或输出操作失败,例如尝试将一个字符串转换为整数,但字符串中包含非数字字符。
ios::eofbit:到达文件末尾或流结束。
ios::badbit:发生严重错误,如读取或写入失败,导致数据丢失。
使用 std::cin.clear() 可以清除流的错误状态,包括 failbit 和 badbit。这使得流可以继续使用,而不会因为之前的错误而一直停留在错误状态。同时C++继承了C语言中设计非零值表示错误,0表示成功,流的初始状态都置为0,出错改1,可以使用按位或操作(|)来设置状态,使用按位与操作(&)来检查状态,使用按位取反操作(~)来清除状态。非常便利
3.空格和回车都可以作为数据之间的分格符,所以多个数据可以在一行输入,也可以分行输入。但如果是字符型和字符串,则空格(ASCII码为32)无法用cin输入,字符串中也不能有空格。回车符也无法读入。如果需要读取包含空格或回车的字符串,应使用 std::getline 函数,它可以读取整行输入,包括空格和回车符。
- cin和cout可以直接输入和输出内置类型数据,原因:标准库已经将所有内置类型的输入和输出全部重载了
- 对于自定义类型,如果要支持cin和cout的标准输入输出,需要对<<和>>进行重载。
- 在线OJ中的输入和输出:
对于IO类型的算法,一般都需要循环输入:
输出:严格按照题目的要求进行,多一个少一个空格都不行。
连续输入时,vs系列编译器下在输入ctrl+Z时结束,ctrl+c是杀进程。ctrl
+Z+换行安全结束
- istream类型对象转换为逻辑条件判断值
实际上我们看到使用while(cin>>i)去流中提取对象数据时,调用的是operator>>,返回值是istream类型的对象,那么这里可以做逻辑条件值,源自于istream的对象又调用了operator bool,operator bool调用时如果接收流失败,或者有结束标志,则返回false。
class Date
{friend ostream& operator << (ostream& out, const Date& d);friend istream& operator >> (istream& in, Date& d);
public:Date(int year = 1, int month = 1, int day = 1):_year(year), _month(month), _day(day){}operator bool(){// 这里是随意写的,假设输入_year为0,则结束if (_year == 0)return false;elsereturn true;}
private:int _year;int _month;int _day;
};//返回输入或输出流的引用,允许链式调用
istream& operator >> (istream& in, Date& d)
{in >> d._year >> d._month >> d._day;return in;
}
ostream& operator << (ostream& out, const Date& d)
{out << d._year << " " << d._month << " " << d._day;return out;
}
// C++ IO流,使用面向对象+运算符重载的方式
// 能更好的兼容自定义类型,流插入和流提取
int main()
{// 自动识别类型的本质--函数重载// 内置类型可以直接使用--因为库里面ostream类型已经实现了int i = 1;double j = 2.2;cout << i << endl;cout << j << endl;// 自定义类型则需要我们自己重载<< 和 >>Date d(2022, 4, 10);cout << d;while (d){cin >> d;cout << d;}return 0;
}

C++文件IO流
1.内存中存储时按字节存是有类型的;文件中只有字节流,将一个个字节对应识别为一个个字符,输入在文件中无法理解是什么内容,只有将输入内容转换为字符串我们才能在文件中看懂
2.文件分为覆盖写和追加写,覆盖写就是不管之前的内容都给直接覆盖,追加写就是找到文件尾接着写。
out 模式用于覆盖写入文件,如果文件已存在,其原有内容会被清空。
app 模式用于向文件追加内容,不会覆盖原有内容。
在进行二进制文件操作时,通常会与 binary 标志一起使用,以确保数据以二进制形式正确读写。
iostream头文件里的ios_base类的成员常量,这些成员常量用来定义文件打开模式。
可以使用位或操作符 | 来组合多个文件打开模式,作用是将不同的文件打开选项组合起来,以便在打开文件时指定多种模式,适应各种不同的文件处理需求。

- 测试代码
class Date
{friend ostream& operator << (ostream& out, const Date& d);friend istream& operator >> (istream& in, Date& d);
public:Date(int year = 1, int month = 1, int day = 1):_year(year), _month(month), _day(day){}//支持日期类转stringoperator string(){string str;str += to_string(_year);str += ' ';str += to_string(_month);str += ' ';str += to_string(_day);return str;}operator bool(){// 这里是随意写的,假设输入_year为0,则结束if (_year == 0)return false;elsereturn true;}
private:int _year;int _month;int _day;
};
//返回输入或输出流的引用,允许链式调用
istream& operator >> (istream& in, Date& d)
{in >> d._year >> d._month >> d._day;return in;
}
ostream& operator << (ostream& out, const Date& d)
{out << d._year << " " << d._month << " " << d._day;return out;
}
C语言写法:
这里就是二进制写入的方法,转化为字节流我们看不懂
转为字符串写入文件,在Date类中重载string的实现即可支持
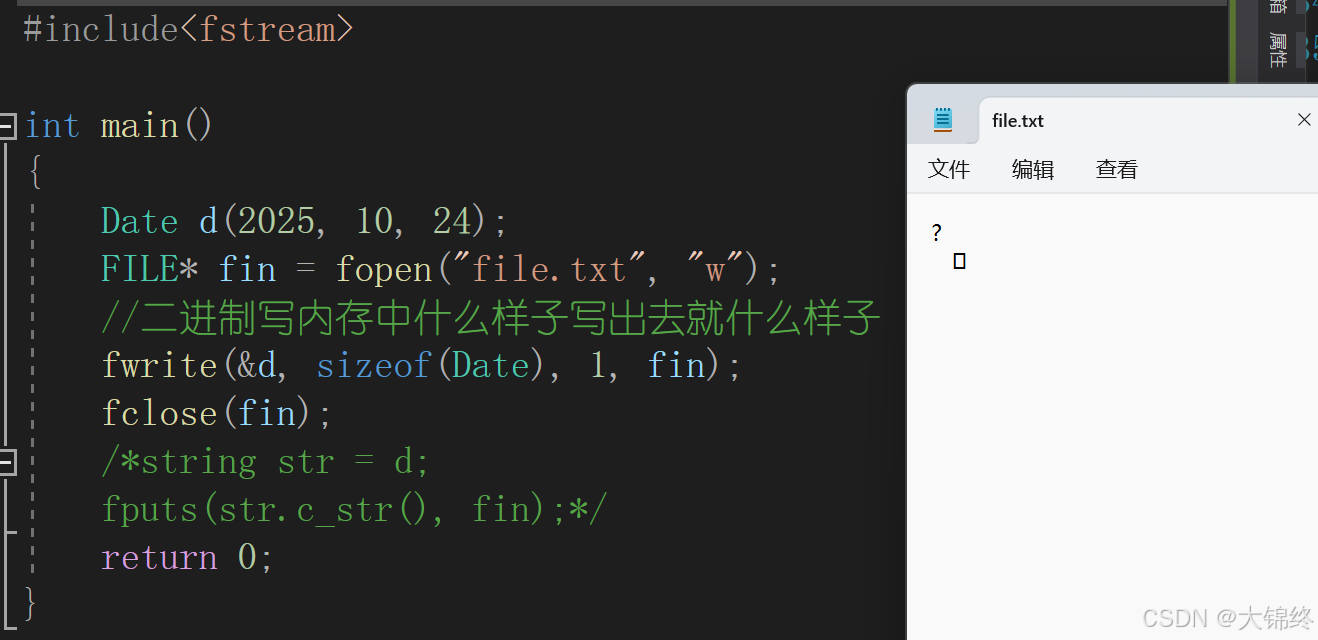

C++写法:
ofstream和ostream是继承关系,ofstream是派生类。ofs << d本质调用流插入,流插入在ostream实现被ofstream继承。
需注意:流插入和流提取操作不仅是针对控制台写的同时也是针对文件写的,针对于谁写取决于out参数是控制台流对象(标准输入输出std::istream 和 std::ostream 类的实例)还是文件流对象本质:
都是把这些数据转化为字符串,无论是控制台流还是文件流底层都是文件,里面都只有字节流。字符串和文件流的格式是一样的都按照一个一个字符来解析,而内存中按字节存储分类型,所以不管在内存中还是字节流中我们都能读懂字符串


文件IO流具体案例解析
存储服务器信息
struct ServerInfo
{char _address[32];//地址或域名int _port;//端口号Date _date;//日期信息
};
二进制读写中不能使用 string 或 vector 这样的对象来存储数据,这些对象在内存中包含首地址的指针,而较长字符串本身存在堆上(可能栈溢出,string类对象可能会在内部使用堆内存来存储较长字符串数据),当进程结束时,这些指针指向已经释放的内存区域,成为野指针。另一个进程再读的时候写入的就是野指针,导致未定义行为或程序崩溃。
可能存在结果正确的情况:当字符串短的时候会存在buffer数组(缓冲区,并不不是每个容器都有,取决于容器的设计和目的)里面,恰好将buffer中内容写出去又读进来,但字符串较长时程序就就会像上述情况样崩溃
配置管理器
struct ConfigManager
{
public:ConfigManager(const char* filename = "file.txt"):_filename(filename){}// 二进制读写 -- 简单高效,缺点:写到文件中的内容看不懂void WriteBin(const ServerInfo& info){ofstream ofs(_filename, ios_base::out | ios_base::binary);ofs.write((const char*)&info, sizeof(info));}void ReadBin(ServerInfo& info){ifstream ifs(_filename, ios_base::in | ios_base::binary);ifs.read((char*)&info, sizeof(info));}//文本读写void WriteText(const ServerInfo& info){ofstream ofs(_filename);ofs << info._address << " " << info._port << " " << info._date;}void ReadText(ServerInfo& info){ifstream ifs(_filename);ifs >> info._address >> info._port >> info._date;}
private:string _filename; // 配置文件
};
C语言在处理二进制读写时需要转string,C++就方便许多了直接调用流插入,自定义对象需要重载,内置类型在库里面已经实现。
注意写的时候用空格(或换行符)去分割,在cin和scanf读的时候多个值间的分割项默认为空格,直接读就行了。不加间隔符在写的时候自己不太分得清,读的时候因为分割读出来的数据会偏离预期C++在二进制读写时本质也是要转换成字符串的,但这个工作交给流插入流提取调用底层库函数来实现,底层和C语言没啥区别只是面向过程的差别,C++帮我们完成了更多工作
3.stringstream
在内存中存储的数据根据占用字节大小会有类型区分,是为了方便识别类型和进行计算。但如果存储到数据库或文件中去不需要那么复杂的存储,只需要单纯的表示数据管理数据,用字节流存储即可。
在网络中通常将结构或对象的信息转成字节流发送出去,再解析回来。
C语言将整型转化为字符串格式
1.使用_itoa函数。是一个非标准的 C 语言函数,能正确处理负数。在某些编译器(如 GCC)中可能不可用。最好用标准库函数(如 sprintf())来实现
value:要转换的整数。str:用于存储转换结果的字符数组(字符串)。
base:转换的进制基数2,8,10,16
2.使用sprintf()函数。 C 标准库函数,用于将格式化的数据写入字符串
str:目标字符数组,用于存储格式化后的字符串。
format:格式化字符串,用于指定输出格式。
…:可变参数列表,根据 format 指定的格式提供相应的数据。
返回写入目标字符串的字符数(不包括结尾的空字符 ‘\0’)。如果发生错误,返回负值。SS



总结:
这两个函数在转化时,都得需要先给出保存结果的空间,那空间要给多大呢,就不太好界定,而且转化格式不匹配时,可能还会得到错误的结果甚至程序崩溃。C++的使用起来更加便利
stringstream使用简介
使用要包含sstream头文件。stringstream继承istream和ostream,能同时进行输入和输出。在该头文件下,标准库三个类istringstream,ostringstream 和 stringstream,分别用来进行流的输入、输出和输入输出操作
- 将数值类型数据格式化为字符串
- clear():注意多次转换时,必须使用clear将上次转换状态清空掉, stringstreams在转换结尾时(即最后一个转换后),会将其内部状态设置为badbit, 因此下一次转换是必须调用clear()将状态重置为goodbit才可以转换,但是clear()不会将stringstreams底层字符串对象清空掉

2.字符串拼接
拼接过程中输入的就是字符串类型是不会发生转换的所以不会将状态重置badbit。拼接过程中是一个需要累计的操作,但一般在复用stringstream的时候,都建议清空和重置的。

- 序列化和反序列化结构数据
简述概念:
两个非常重要的概念,主要用于数据的存储、传输和恢复。它们在多种场景中都有广泛应用,例如网络通信、文件存储、对象持久化等。
1.序列化:
指将数据结构或对象状态转换为可存储或可传输的格式的过程。序列化后的数据通常是字节流、JSON、XML 或其他格式,可以被写入文件、存储到数据库或通过网络传输。
2.反序列化:
反序列化是指将序列化后的数据恢复为原始数据结构或对象的过程。反序列化是序列化的逆过程,它将字节流、JSON、XML 等格式的数据转换回原始对象或数据结构。
int main()
{//序列化ChatInfo winfo = { "小鹅",1024,{2025,10,24},"晚上一起看电影吧" };stringstream oss;oss << winfo._name << " " << winfo._id << " " << winfo._date << " " << winfo._msg;string str = oss.str();cout << str << endl;//反序列化ChatInfo rInfo;stringstream iss(str);iss >> rInfo._name >> rInfo._id >> rInfo._date >> rInfo._msg;cout << "-------------------------------------------------------" << endl;//输出反序列化内容cout << "姓名:" << rInfo._name << "(" << rInfo._id << ") ";cout << rInfo._date << endl;cout << rInfo._name << ":>" << rInfo._msg << endl;cout << "-------------------------------------------------------" << endl;return 0;
}
1.序列化过程:通过 std::stringstream 的流插入运算符 <<,可以将不同类型的数据逐个插入到字符串流中,并最终生成一个格式化的字符串。这个过程是自动完成的,有些类型需手动处理
2.反序列化过程:通过 std::stringstream 的流提取运算符 >>,可以从字符串流中逐个读取数据,并恢复为原始对象的字段。同样自动完成,也需要手动处理特殊类型。
注意:stringstream不适合做复杂的序列化,数据的顺序会受到限制