深度学习:小米 MiMo-VL 技术报告学习
论文地址:
[2505.07608] MiMo: Unlocking the Reasoning Potential of Language Model -- From Pretraining to PosttrainingAbstract page for arXiv paper 2505.07608: MiMo: Unlocking the Reasoning Potential of Language Model -- From Pretraining to Posttraining![]() https://arxiv.org/abs/2505.07608
https://arxiv.org/abs/2505.07608
[2506.03569] MiMo-VL Technical ReportAbstract page for arXiv paper 2506.03569: MiMo-VL Technical Report![]() https://arxiv.org/abs/2506.03569学习视频链接:
https://arxiv.org/abs/2506.03569学习视频链接:
【小米】MiMo-VL技术报告解读,非常扎实的工作!_哔哩哔哩_bilibili【小米】MiMo-VL技术报告解读,非常扎实的工作!, 视频播放量 13667、弹幕量 6、点赞数 615、投硬币枚数 222、收藏人数 221、转发人数 28, 视频作者 李小羊学AI, 作者简介 上海交通大学硕士,算法研究员,致力于AI领域知识分享。某乎同名。,相关视频:小米MiMo全网首评:这个模型两极分化!,【IGN】小米×《GT赛车》合作宣传视频,小米Vela官网与Open harmony官网的对比,垃圾小米发热严重,都能烤肉吃了,《华为粉丝私信问候科技美学那岩买小米su7一周年纪念日》,小米自研大模型现场录屏,小米YU7还没开,档把就断了。,小米VelaOS初体验,小米开源“Xiaomi MiMo”大模型:为推理而生,以 7B 参数超越 OpenAI o1-mini,奥运冠军提小米su7ultra,🌸粉在评论区祝福![]() https://www.bilibili.com/video/BV1fCTEznEQ9/?spm_id_from=333.337.search-card.all.click&vd_source=a52a3669ad6cdf46378fa8dc9927aa2d
https://www.bilibili.com/video/BV1fCTEznEQ9/?spm_id_from=333.337.search-card.all.click&vd_source=a52a3669ad6cdf46378fa8dc9927aa2d
MiMo-VL
摘要
文章开源了两个7B级别的强大VL模型:
MiMo-VL-7B-SFT (经过监督微调) 和 MiMo-VL-7B-RL (经过强化学习)
在与其他VL模型的比较下,显示出强大性能:
-
全面超越竞品: 在40个评估任务中,MiMo-VL-7B-RL有35个超越了同级别的强劲对手Qwen2.5-VL-7B。
-
超强的推理能力: 在高难度科学推理基准 OlympiadBench 上得分59.4,这个成绩甚至超越了参数量高达78B的更大模型(Intern-VL3, QVQ-Preview等),展示了极高的效率和能力。
-
GUI Agent领域新标杆: 在GUI(图形用户界面)定位任务 OSWorld-G 上得分56.1,创造了新纪录,甚至优于UI-TARS等专门为此类任务设计的Agent模型。
模型的成功归功于一套精心设计的训练流程:
-
四阶段预训练: 整个预训练过程消耗了2.4万亿个token,为模型打下了坚实的多模态基础。
-
混合式在线强化学习 (MORL - Mixed On-policy Reinforcement Learning): 这是其核心创新之一。SFT模型之后,通过MORL框架进行优化,该框架巧妙地整合了多种不同来源的奖励信号(比如可验证的逻辑推理奖励和基于人类偏好的奖励),从而全面提升模型能力。
通过开发过程,团队总结出两条重要经验:
-
预训练阶段加入高质量推理数据至关重要: 团队发现,在预训练后期就大量融入高质量、长思维链(long Chain-of-Thought)的推理数据,对于提升模型的复杂推理能力至关重要。
-
混合强化学习的价值与挑战: 混合多领域的强化学习(RL)虽然效果显著,但团队也指出了在同时优化不同类型任务时存在挑战(例如,推理任务和定位任务的目标可能相互冲突)。
-

预训练Pre-Training
这部分,文章介绍了MiMo-VL的模型架构、数据处理流程和预训练阶段。
模型架构
1. 一个ViT作为视觉编码器,输入为图片和视频。MiMo-VL采用Qwen2.5-ViT作为视觉编码器。
2. 一个与pretrained LLM 对其的m将视觉编码投影到潜空间的投影器。MiMo-VL采用一个简单的MLP作为投影器。
3. 大语言模型本身,已经具有文本理解能力和推理能力。MiMo-VL采用MiMo-7B作为backbone模型。
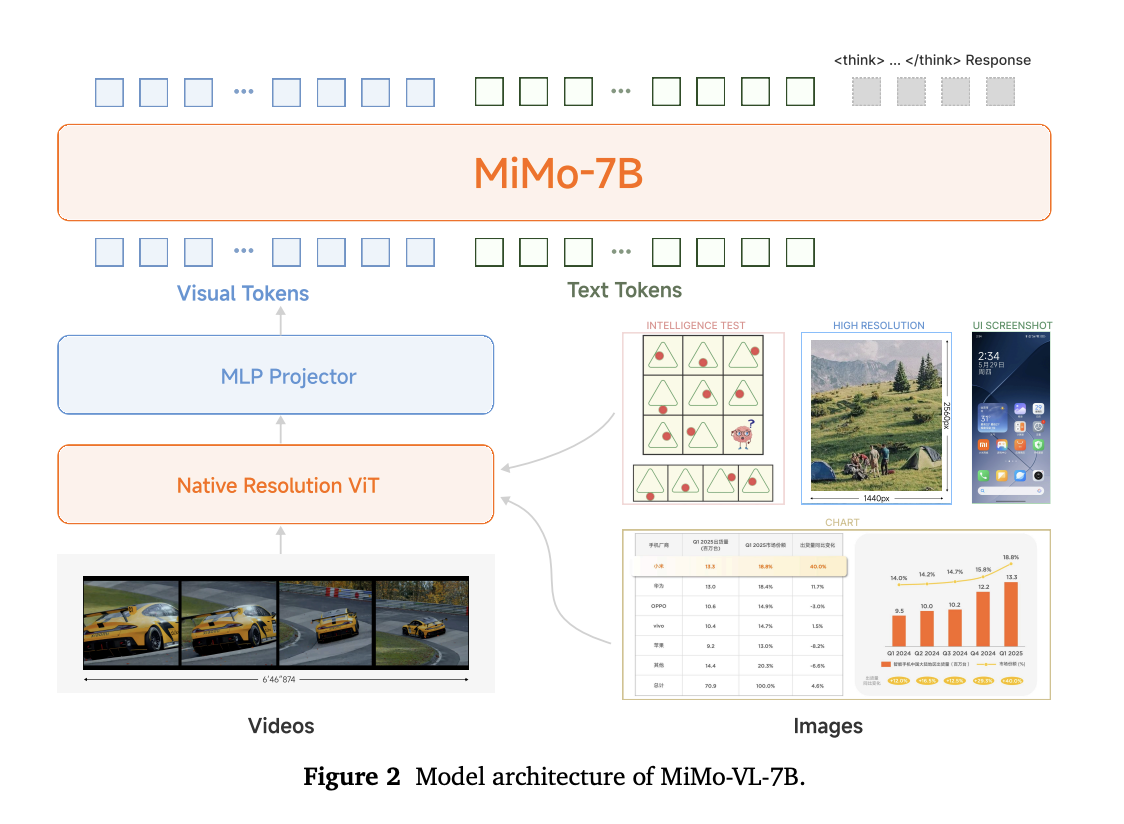
预训练数据
MiMo-VL预训练使用2.4T高质量的多模态tokens进行训练。包含图文对、图文潜入数据、OCR数据、定位数据、视频数据、GUI交互数据、推理数据和文本数据。
1. 图片文本对数据

图源:https://arxiv.org/pdf/2408.12637
数据聚合与去重:首先,从多个公开网络数据源聚合了大规模的原始图像-文本对。随后,通过结合图像感知哈希(phash)与文本内容过滤,对该原始语料库进行严格的去重处理,得到一个初步提纯的唯一图文对集合。
描述重新生成 (Re-captioning):为提升描述的丰富性和准确性,我们利用一个专门训练的图像描述模型,以原始图像及其文本描述作为先验信息(priors),对整个数据集进行重描述生成。
质量过滤与分布优化:生成的描述文本会经过一系列过滤机制的筛选,这些机制基于语言一致性和重复模式检测来保证文本质量。为解决固有的数据不均衡问题,采用了类似MetaCLIP的方法论,构建了双语(中英)元数据,以优化描述的分布,从而有效缓解高频条目的过表达并降低数据集噪声。
2. 图文交错数据

图源:https://arxiv.org/pdf/2408.12637
构建了一个包含网页、书籍和学术论文等多种来源的大规模图文交错语料库。
内容提取与清洗 (Content Extraction and Cleansing): 对于书籍和论文等PDF格式的文档,采用先进的PDF解析工具包进行内容提取与清洗。
内容筛选 (Content Filtering): 筛选过程优先保留富含世界知识的数据类型,如教科书、百科全书、技术手册、专利和传记等。文本部分,依据知识密度(knowledge density)和可读性等指标进行评估。视觉部分,实施了过滤器以排除尺寸过小、长宽比异常、内容不安全以及视觉信息量极少(如装饰性章节标题)的图像。
图文对质量评估 (Image-Text Pair Scoring): 最后,基于相关性、互补性和信息密度平衡等维度对图文对进行评分,确保保留的数据均为高质量。
3. OCR数据和定位数据
从开源数据集中汇编了一个大规模的专用语料库。
OCR数据: 图像内容涵盖文档、表格、通用场景、产品包装和数学公式等多种类型。为增加学习难度,除了标准印刷文本,引入了包含手写体、排版变形文本以及模糊/遮挡文本的图像,以提升模型的识别鲁棒性。部分数据还标注了文本区域的边界框,使模型能同时进行文本识别与定位。
定位数据 (Grounding Data): 图像场景覆盖了单目标和多目标的场景。在所有涉及定位的任务中,均采用绝对坐标进行表示。
4. 视频数据
视频数据集主要源于公开的在线视频,覆盖了广泛的领域、类型和时长。
密集时间戳描述 (Dense, Fine-grained Event-level Descriptions): 设计了一个视频重描述流水线,为视频生成密集的、细粒度的事件级描述。每个描述都通过精确的起止时间戳进行时间上的定位,这使得模型能够建立具备时间感知的通用视频理解能力。
长时序分析 (Global Semantics Analysis): 整理了对视频全局语义(如叙事结构、风格元素、隐含意图)进行分析的段落文本,以培养模型对视频内容的深度理解能力。
视频对话与补充数据: 为增强模型的对话连贯性,收集了关于视频的多样化问题并合成了相应的回答。同时,也整合了开源的视频描述和对话数据集以丰富预训练数据。
5. GUI( Graphic User Interface) 数据
为提升模型在图形用户界面(GUI)导航方面的能力,我们收集了覆盖移动、网页和桌面等多种平台的开源预训练数据。
数据合成与增强 (Data Synthesis and Augmentation): 设计了一个合成数据引擎,以弥补开源数据的局限性并强化模型的特定能力,
定位与交互理解 (Grounding and Interaction Comprehension):
- 元素定位 (Element Grounding): 训练模型基于文本描述精确定位界面元素。
- 指令定位 (Instruction Grounding): 训练模型根据用户指令识别截图中的目标对象。
- 动态感知任务: 根据操作前后的截图来预测中间发生的交互动作。
动作空间标准化 (Standardized Action Space): 对于GUI动作(GUI Action),我们收集了大规模的长GUI动作轨迹。为确保跨平台的一致性,我们将来自移动、网页和桌面环境的动作统一到一个标准化的动作空间中,如点击、悬停等。
6. 合成推理数据 (Synthetic Reasoning Data)
生成合成推理数据的方法始于对开源问题的全面整理,涵盖了感知问答、文档问答、视频问答和视觉推理等任务。
预训练阶段
MiMo-VL预训练共分为四步:

第一阶段:投影器热身。冻结所有模型结构,除了随机初始化Projector,基于图文对数据,用于帮助projector实现将视觉信息映射到语言模型的表征空间。
第二阶段:视觉语言对齐。在Projector的基础上,解冻ViT,加入图文交错数据进行训练,用于增强视觉语言的统一性。
第三阶段:全参多模态预训练。解冻所有参数,加入纯文本数据、OCR数据、定位数据、图文问答数据、视频数据、GUI数据、指令遵循数据和推理数据。部分纯文本数据是为了保留MiMo-7B-Base的文本语言能力。
第四阶段:长上下文SFT。保持所有参数解冻,为了增强模型的长上下文能力,加入长文本数据、长稳定、高分辨率图片、长视频和长推理数据,奖上下文窗口由8k增强至32k。
经过上述四个阶段,便得到了:MiMo-VL-7B-SFT,后续阶段,将基于这个模型,进行基于强化学习的后训练。
后训练Post-Training
在预训练阶段构建了模型强大的视觉感知与多模态推理基础之后,后训练阶段的目标是通过强化学习进一步精调和对齐模型,以增强其在特定高难度任务上的表现,并使其行为更符合人类偏好。
本研究提出并采用了一种新颖的混合式在线策略强化学习 (MORL, Mixed On-policy Reinforcement Learning) 框架,该框架无缝集成了两类主要的强化学习范式:基于可验证奖励的强化学习 (RLVR) 和基于人类反馈的强化学习 (RLHF)。
基于可验证奖励的强化学习 (Reinforcement Learning with Verifiable Rewards, RLVR)
RLVP基于规则奖励函数,具体来说,分为如下几个奖励:
视觉推理 (Visual Reasoning)
数据集构建: 从开源社区和专有的K-12教育资源库中汇编了多样化的可验证STEM问题。为缓解奖励被“破解”(reward hacking)的风险,利用一个大型语言模型(LLM)将多项选择题重写为开放式自由回答格式,并筛选出基于证明的问题。
数据筛选: 通过基于模型的难度评估对问题进行进一步筛选,排除了对于高级VLM而言过于简单或即使没有图像输入也能解决的问题。经过数据清洗和类别平衡,最终形成了一个包含80K个问题的高质量视觉推理数据集。
奖励计算: 模型的响应正确性通过开源的Math-Verify库进行程序化判定回复正确性。
文本推理 (Text Reasoning)
为充分释放模型的推理潜力,我们引入了纯文本推理任务。
数据集: 整合了来自Xiaomi (2025) 的数学推理数据,这些数据包含了更高难度的、达到大学或竞赛水平的查询。
奖励函数: 同样采用Math-Verify库计算奖励,确保了视觉和文本推理任务在奖励评估上的一致性。
图像定位 (Image Grounding)
奖励度量:
- 对于边界框(bounding box)预测,奖励使用广义交并比 (Generalized Intersection over Union, GIoU) (Rezatofighi et al., 2019) 计算(衡量预测框与真实框之间的重叠度和对齐情况)。
- 对于点坐标(point-style)输出,奖励被定义为一个二元函数:若预测点落在真实边界框内部,则奖励为1,否则为0。
视觉计数 (Visual Counting)
训练增强模型的计数能力,奖励函数直接定义为模型预测的计数值与真实计数值之间的准确度。
时序视频定位 (Temporal Video Grounding)
将RLVR框架从静态图像扩展到动态视频内容,以捕捉时序依赖关系。
-
任务: 引入时序视频定位任务,要求模型根据自然语言查询来定位视频中的特定片段。
-
输出格式与奖励: 模型输出[mm:ss, mm:ss]格式的时间戳来表示目标片段的起止时间。奖励通过计算预测时间段与真实时间段之间的时序交并比 (Temporal Intersection over Union, IoU) 来确定。
基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF)
为使模型输出与人类偏好对齐并减少不良行为,我们采用RLHF作为对可验证奖励框架的补充。
查询收集与筛选 (Query Collection and Curation)
-
来源: 从开源指令微调数据集和内部人工编写的来源中收集了多模态和纯文本的查询。
-
多样性增强: 为确保查询的多样性,使用嵌入聚类(embedding clustering)等技术分析查询分布,并平衡了中英文查询、有益性(helpfulness)与无害性(harmlessness)查询的比例。
-
响应生成: 对每个筛选后的查询,我们使用MiMo-VL-7B及其他多个顶尖VLM生成响应。
奖励模型训练 (Reward Model Training)
-
成对排序: 我们利用一个更先进的VLM对生成的响应进行成对排序(pairwise ranking),构建了奖励模型的训练数据集。
-
双模型策略: 我们开发了两个专用的奖励模型:一个基于MiMo-7B的纯文本奖励模型,以利用其强大的语言理解能力;另一个基于MiMo-VL-7B 的多模态奖励模型,以有效处理包含视觉输入的查询。这种双模型策略确保了在不同模态下的最优性能。
-
训练目标: 奖励模型使用Bradley-Terry模型的目标函数进行训练。
混合式在线策略强化学习 (Mixed On-Policy Reinforcement Learning, MORL)
MORL是后训练阶段的核心框架,它将上述的RLVR和RLHF目标整合在一个统一的流程中进行同步优化。
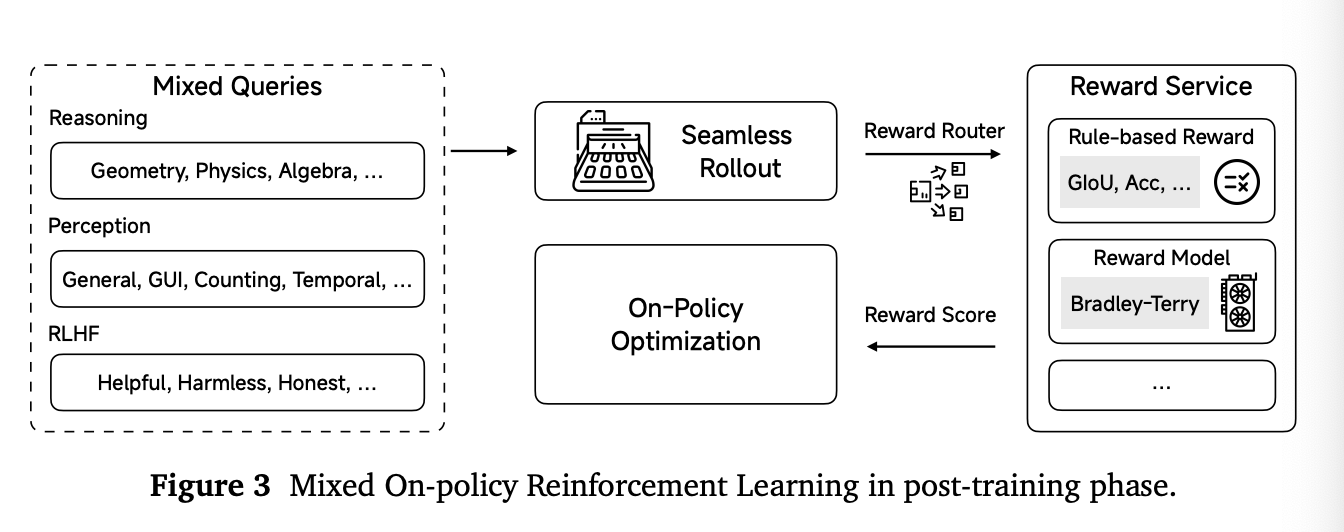
训练策略:模型采用fully on-policy的GRPO变体进行训练。
On-Policy 和 Off Policy的区别
On-Policy策略指模型训练数据采用“现采现用,用完就扔”的训练方式。
数据收集:
我们有一个当前版本的模型,称之为 模型A。
我们使用 模型A 去生成 train_batch_size(即 1024 个)prompt-response 对。
我们计算出这 1024 个响应的奖励 (Reward)。
现在,我们有了一个包含 1024 个样本的经验池 (Experience Pool),这些样本全部由模型A产生。
参数更新:
现在,我们开始用这 1024 个样本来更新 模型A 的参数。
为了高效训练和节省显存,我们并不会一次性计算 1024 个样本的梯度。而是将其切分为 1024 / 256 = 4 个 mini-batches。
我们进行一个循环(通常称为 epoch):
取出第一个 256 大小的 mini-batch,计算梯度,更新一次模型参数。
取出第二个 256 大小的 mini-batch,计算梯度,更新一次模型参数。
...重复 4 次,直到所有 1024 个样本都被使用过一遍。
关键点:
当这 1024 个数据被充分利用、模型参数更新完毕后,这批数据就会被完全丢弃。
下一次训练时,我们必须用**更新后的新模型(模型B)**去重新生成一批全新的 1024 个数据。
结论: On-Policy 的核心是,学习用的数据必须由当前正在学习的策略所产生。数据的“保质期”非常短。
off-Policy策略则会充分利用模型生成的所有数据。
数据收集 (来自于一个“回放池” Replay Buffer):
我们有一个巨大的数据池,叫做 回放池 (Replay Buffer)。
这里面的数据来源可以非常广泛:
- 可能是由好几个版本之前的旧模型 (Old Policy) 生成的。
- 也可能是由人类标注的 SFT (监督微调) 数据。
- 也可能是其他模型的输出。
当我们要训练时,我们从这个巨大的回放池中,随机采样 train_batch_size(即 1024 个)数据。
参数更新:
我们用当前的 模型A 去学习这 1024 个可能不是它自己产生的数据。
和 On-Policy 一样,我们也会把这 1024 个数据切分为 4 个 256 大小的 mini-batches。
同样进行循环,每处理一个 mini-batch 就更新一次模型参数。
关键点:
这一次训练使用的 1024 个数据,在用完之后并不会被丢弃。它们仍然会留在回放池里,未来还有可能被再次采样到,用于模型的训练。
结论: Off-Policy 的核心是,可以用过去策略产生的数据来训练当前策略。数据可以被反复利用,样本效率 (Sample Efficiency) 极高。
DeepSeek R1中采用的GRPO是Mixed-Policy的,也就是论文中所称的“Vanilla GRPO”。
R1训练时,先会其他模型对不同的prompt进行回复采样,在多个样本中通过RM选出质量最好的回答,放置off-policy的回放池中。随后在训练时,使用当前的policy-model生成不同的回复sample,随后结合off-policy生成的最佳回复,通过GRPO计算优势。
同时MiMO-VL还做出了多项改进:如移除KL散度损失、动态采样、简易数据过滤和重采样策略。
MORL流程集成了推理、感知、定位、多模态RLHF和纯文本RLHF等多种任务,每种任务都需要不同的奖励函数或专用的奖励模型。
-
统一接口: 为提供统一的接口并实现近乎零延迟的奖励计算,我们引入了“奖励即服务”(RaaS)架构。
-
动态路由: 一个奖励路由器 (reward router) 会根据查询的任务类型动态选择合适的奖励函数。
-
服务化部署: 为最小化延迟,奖励模型被部署为独立的、可通过HTTP访问的微服务,确保了可扩展的奖励计算。
-
奖励标准化: 所有奖励信号都被归一化到[0, 1]区间,并且训练过程中不引入任何额外的格式奖励(format rewards)。
总结: 后训练阶段通过MORL框架,系统性地结合了来客观规则(RLVR)和主观偏好(RLHF)的奖励信号。其核心技术包括为多个领域(数理推理、定位、计数等)设计可验证的奖励函数,训练专用的双模态奖励模型,以及采用一个高效、稳定的完全在线策略RL算法。通过RaaS架构,整个复杂的奖励计算过程被简化和加速,最终产出了性能卓越的MiMo-VL-7B-RL模型。