transformer-位置编码
一、PositionEncoding
-
论文地址
https://arxiv.org/pdf/1706.03762
位置编码介绍
-
位置编码在Transformer模型中是用来将位置信息与输入序列相结合的一种技术。在传统的序列模型(如RNN)中,输入的序列数据是有顺序的,模型本身能够感知输入数据的顺序。然而,Transformer是一种不具备内置顺序敏感性的模型,因此需要通过位置编码来将位置信息显式地添加到输入数据中。
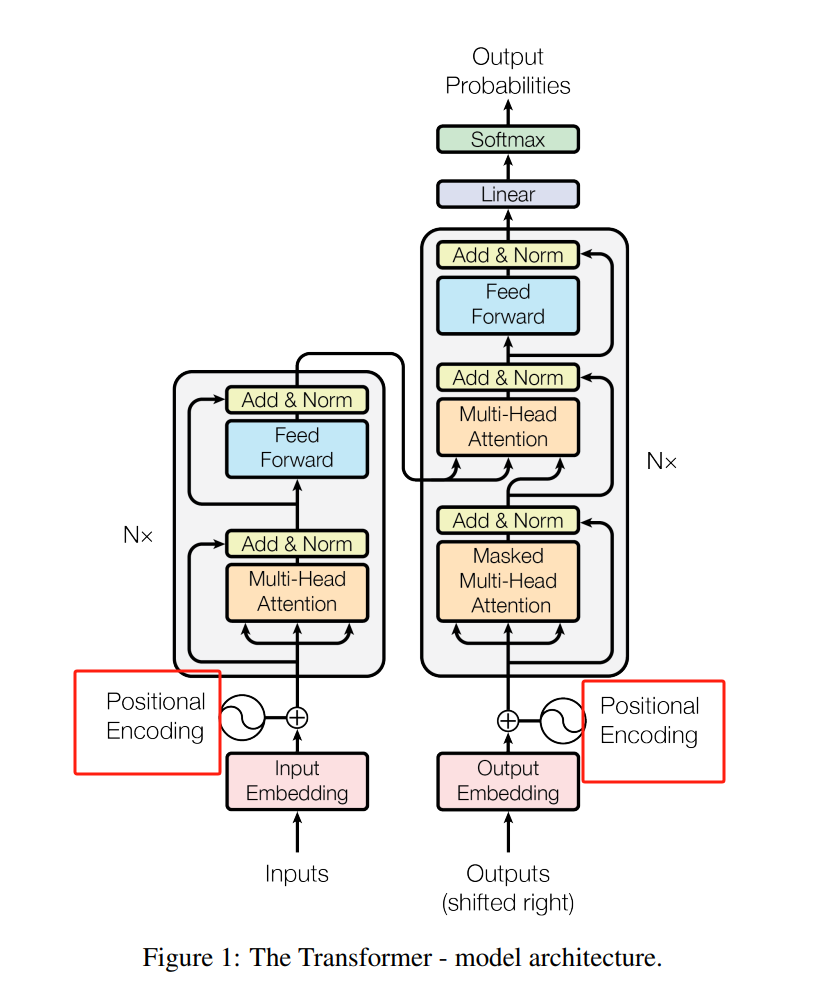
位置编码的数学公式
-
在Transformer中,位置编码通过一组确定性的正弦和余弦函数的组合来产生。这种编码方式允许模型学习位置信息,同时也保留了相对位置的不变性。具体的数学公式如下
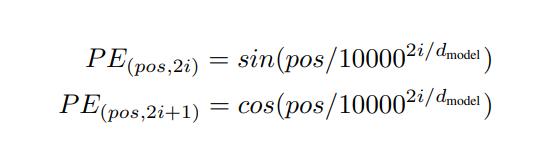
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i d m o d e l ) P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i d m o d e l ) PE_(pos,2i) = \sin ( \frac{pos}{10000^{ \frac{2i}{d_{model}} } } ) \\ \quad \\ PE_(pos,2i+1) = \cos ( \frac{pos}{10000^{ \frac{2i}{d_{model}} } } ) \\ PE(pos,2i)=sin(10000dmodel2ipos)PE(pos,2i+1)=cos(10000dmodel2ipos)其中, p o s pos pos 表示位置, i i i 是维度索引, d m o d e l d_{model} dmodel 是模型的维度 (即embedding的维度)。
代码
-
根据上述公式,实现
PositionlEncodingfrom torch import nn import torchclass PositionEncoding(nn.Module):"""位置编码"""def __init__(self, d_model, max_seq_len=512):super(PositionEncoding, self).__init__()# shape[max_seq_len]position = torch.arange(0, max_seq_len)# shape[max_seq_len, 1]position = position.unsqueeze(1) # 升维# shape [d_model/2]item = 1 / 10000 ** (torch.arange(0, d_model, 2) / d_model)# shape[max_seq_len, d_model/2]tmp_pos = position * item# shape[max_seq_len, d_model]pe = torch.zeros(max_seq_len, d_model)pe[:, 0::2] = torch.sin(tmp_pos) # 偶数pe[:, 1::2] = torch.cos(tmp_pos) # 奇数# shape: [max_seq_len, d_model] --> [batch, max_seq_len, d_model]pe = pe.unsqueeze(0) # 在第一个维度上升维# 将位置编码pe注册为缓冲区self.register_buffer(name="pe", tensor=pe, persistent=False)def forward(self, x):batch, seq_len, d_model = x.shapepe = self.pereturn x + pe[:, :seq_len, :] -
相关解释
-
初始化参数解释:d_model : 模型维度(embedding维度)
max_seq_len : 是模型支持的最大序列长度,确保模型能够处理任意长度不超过 max_seq_len 的序列。
-
注册缓冲区self.register_buffer方法通过将位置编码 pe 注册为缓冲区,可以在模型的前向传播中直接使用 self.pe,而不需要每次都重新计算。
缓冲区不会被优化器更新,因此位置编码在训练过程中保持不变,这符合位置编码的设计初衷。 -
前向传播参数x : 输入序列,shape为 [batch_size, seq_len, d_model]
-
使用示例
-
测试代码
# 假设我们有一个大小为 (batch_size=32, seq_len=20, d_model=512) 的输入 batch_size = 32 seq_len = 20 d_model = 512# 创建位置编码的实例 pos_encoding_layer = PositionEncoding(d_model=d_model)# 生成随机输入数据 input_data = torch.randn(batch_size, seq_len, d_model)# 获取带有位置编码的数据 output_data = pos_encoding_layer(input_data)print(output_data.shape) # 输出应为 (32, 20, 512)创建一个
PositionEncoding类的实例,并通过传入一个随机生成的输入张量来获取添加了位置信息的输出张量。注意,PositionalEncoding 不改变输入序列的长度