pytorch 与 张量的处理
系列文章目录
文章目录
- 系列文章目录
- 一、Tensor 的裁剪
- 二、Tensor 的索引与数据筛选
- torch.where
- torch.indices
- torch.gather
- torch.masked_select
- torch.take
- torch.nonzero(省略)
- 三、Tensor 的组合与拼接
- torch.cat
- torch.stack
- 四、Tensor的切片
- chunk
- split
- 五、Tensor 的变形操作
- torch.reshape
- torch.t
- torch.transpose
- torch.squeeze 和 torch.unsqueeze
- torch.unbind
- torch.flip
- rot90
一、Tensor 的裁剪
- 对 tensor 中的元素进行过滤
- 梯度裁剪,发生在梯度离散或者梯度爆炸时对梯度的处理
- a.clamp(2,3)
对数据集进行裁剪有一个好处,可以防止算法过拟合。在损失函数中,我们需要对离散的数据进行处理,梯度的离散化,我们需要解空间变小,更容易收敛。当然在有些数值处理,涉及到指数的增长,爆炸式的增长,我们使用张量裁剪控制数据范围是常用的手段。
import torch
a = torch.rand(2,2)*10
print("a 的数据范围:\n",a)
print("张量裁剪后:\n",a.clamp(1,2))

二、Tensor 的索引与数据筛选
深度学习常用到的函数:
torch.where(condition,x,y)按照条件从 x 和 y 中筛选出元素组成新的Tensor
torch.gather(input, dim, index, out = None)在指定的纬度按照索引赋值输出Tensor
torch.index_select(input, dim, index, out = None)按照指定的索引输出Tensor
torch.masked_select(input, mask, out = None)按照mask 输出Tensor,输出为向量
torch.take(input,indices)将输入看成 1D-tensor,按照索引得到输出Tensor
torch.nonzero(input, out = None)输出非零元素的坐标
下面进行代码实操
torch.where
import torch
# torch.Where(condition,a,b)
a1 = torch.rand(4,4)*10
b1 = torch.rand(4,4)*10print("a1 的内容:\n",a1)
print("b1 的内容:\n",b1)
print("where 后的内容:\n",torch.where(a1>5,a1,b1))
输出结果:
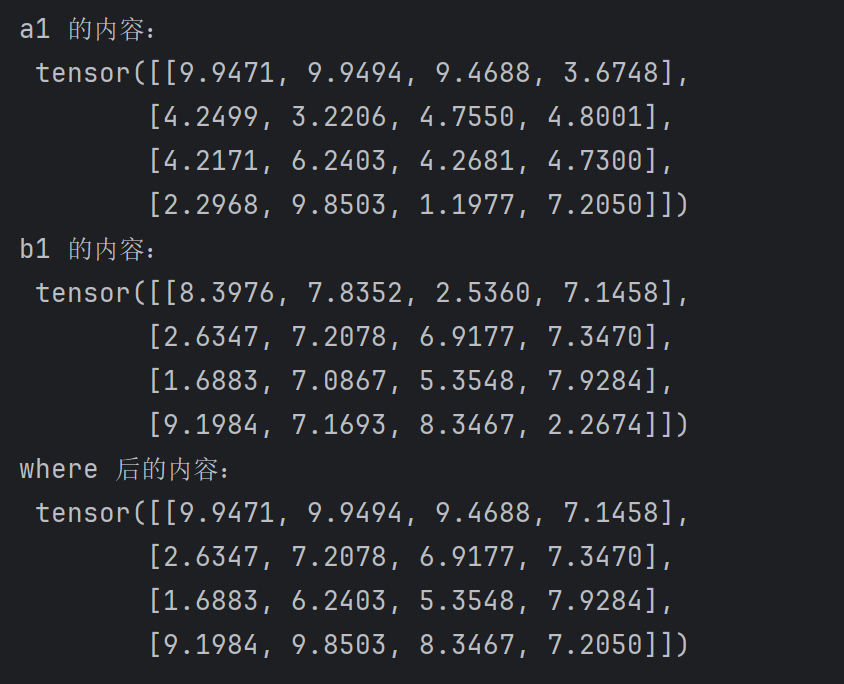
torch.where(a>5,a,b) 意思是:a 的每个元素与 5 进行比较,大于 5 的部分保留,小于 5 的部分使用 b 中对应位置的元素进行填充。
torch.indices
# torch.index_select()
print("a1 的内容:\n",a1)
print("torch.indices:\n",torch.index_select(a1,dim=1,index=torch.tensor([0,3,2])))
输出结果:

选择输入、维度、索引。特别注意索引的选择 torch.tensor([该维度数组索引]) 。dim = 0,表示从列开始循环,每一列选择对应的元素,我这里从行开始,每一行按照0, 3, 2的索引顺序选择元素,最终组成 4 x 3 的矩阵。选择哪个维度,该维度的长度不变。
torch.gather
# torch.gather(a1,dim = 0,index=)
import torch
a11 = torch.linspace(1,16,16).view(4,4)
print("a11 的内容:\n",a11)
print("torch.gather:\n",torch.gather(a11,dim=1,index=torch.tensor([[3,2,0,1],[3,2,0,1]])))
结果图:
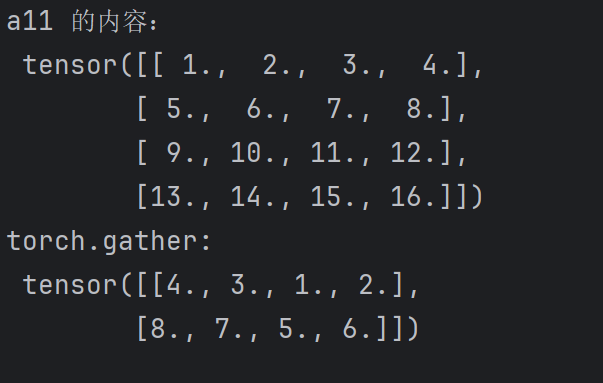
结合代码和运行结果,gather和index_select构造参数不一样,index_select 可以根据Tensor选择维度索引数组,以此来循环。但是 gather 需要我们明确给出矩阵的形状,而且还要附加索引,感觉更加复杂。而且 gather 无论选择行索引还是列索引,选择好该维度元素,按照行优先构造出新的矩阵 。 代码中出现了 torch.linspace(起始值,末值,个数) ,可以生成一个序列
torch.masked_select
# masked_select
masked = torch.gt(a11,8)
print("masked:\n",masked)
print("torch.masked_select(a11,masked):\n",torch.masked_select(a11,masked))
结果图:
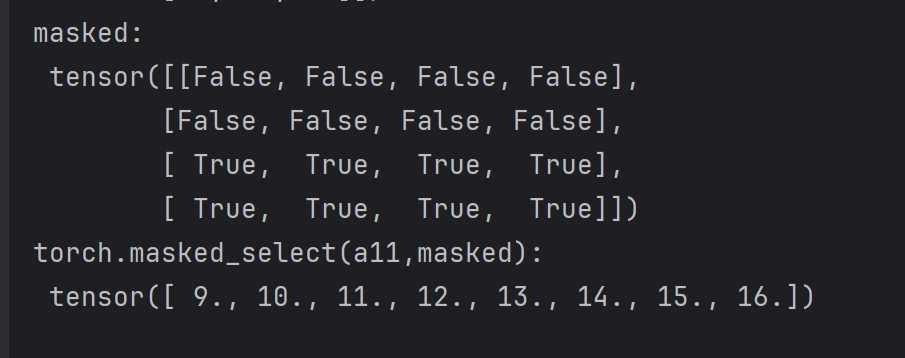
此处的代码接上面的背景。mask 掩码,就是张量类型的 bool 值,通过图 2.4 中的masked就可以看到。采用Tensor的判断语句就可以生成这种掩码,调用torch.masked_select() 传递的参数就只有输入和掩码mask,自动输出一维向量。当然可以通过view来重构张量。
torch.take
print("torch.take:\n",torch.take(a11,index=torch.tensor([3,2,0])))
运行结果:
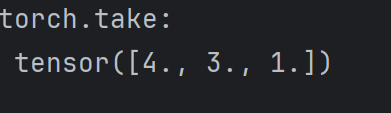
torch.take 要把整个张量看作是一个一维数组,所以传递的张量数组是一维的,选择对应的元素作为输出,输出结果和 masked_select 一样,是一个向量。
torch.nonzero(省略)
就传递对应的张量,然后返回给我们零元素的索引数组。
三、Tensor 的组合与拼接
在做卷积神经网络的时候,我们会在通道使用拼接。
torch.cat(sq, dim, out = None)按照已经存在的纬度进行拼接torch.stack(sq, dim, out = None)按照新的维度进行拼接- torch.gather(input, dim, index, out = None) 在指定维度上按照索引赋值,输出Tensor。(上面已经有案列)
torch.cat
import torch
a = torch.zeros((2,4))
b= torch.ones((2,4))
print("a 的内容:\n",a)
print("b 的内容:\n",b)
print("cat 列拼接\n",torch.cat((a,b),dim=0))
print("cat 行拼接\n",torch.cat((a,b),dim=1))
运行结果:

这里生成了一个 2x4 的 0 矩阵和全 1 矩阵,注意写法。cat 拼接 dim = 0,在列的维度上拼接,增加列的长度,列的数目不变。直观来看是在 a 上面加了两行,当然 dim = 0 就是增加行的长度了。
torch.stack
# stack 拼接:
a1 = torch.linspace(1,6,6).view(2,3)
b1 = torch.linspace(7,12,6).view(2,3)
print("a1的内容:\n",a1)
print("b1的内容:\n",b1)
c = torch.stack((a1,b1),dim=0)
c1 = torch.stack((a1,b1),dim=1)
print("stack列:\n",torch.stack((a1,b1),dim=1))
print("stack 行的形状:\n",torch.stack((a1,b1),dim=1).shape)
print("stack列:\n",torch.stack((a1,b1),dim=0))
print("列拼接后的形状:\n",c.shape)
结果图:
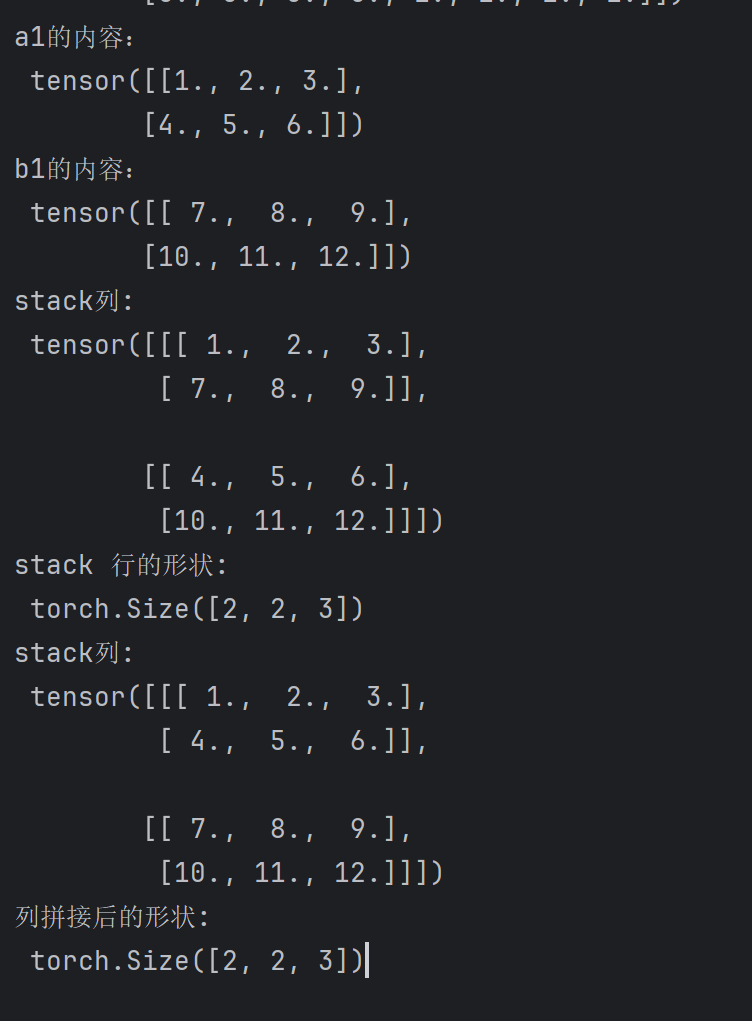
torch.stack 直接把这两个矩阵看做是一个元素,然后形成一个高维度的矩阵。cat 是在原有的基础上进行扩展。我们可以使用这串代码从高维度张量中得到原始分量。
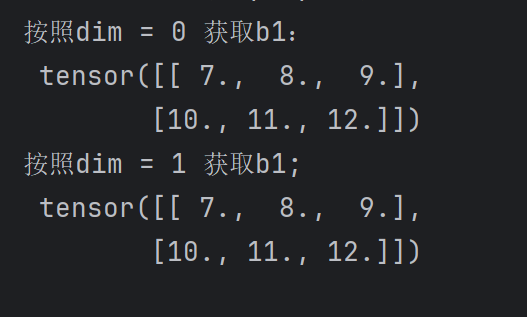
print("按照dim = 0 获取b1:\n",c[1,:,:])
print("按照dim = 1 获取b1;\n",c1[:,1,:])
四、Tensor的切片
torch.chunk(tensor,chunks, dim = )按照某个维度平均分块,最后一个块可能小于平均值,chunks 就是块的数目,自己定义。torch.split(tensor, split_size_or_sections, dim = )按照某个维度,按照第二个参数给定的 list 或者 int 进行分割。
chunk
import torch
a = torch.randn(2,3)
print("a 的内容:\n",a)
print("chunk 切片:\n",torch.chunk(a, 2, dim=1))
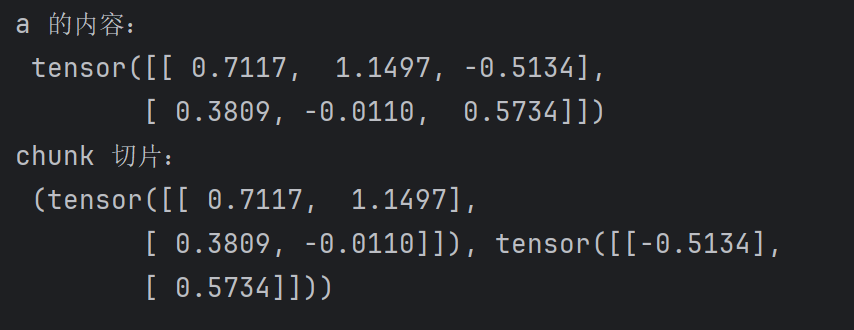
很好理解,类似于用小刀去分一个张量方块,按照一定的步长切割,最后剩下一坨小的。
split
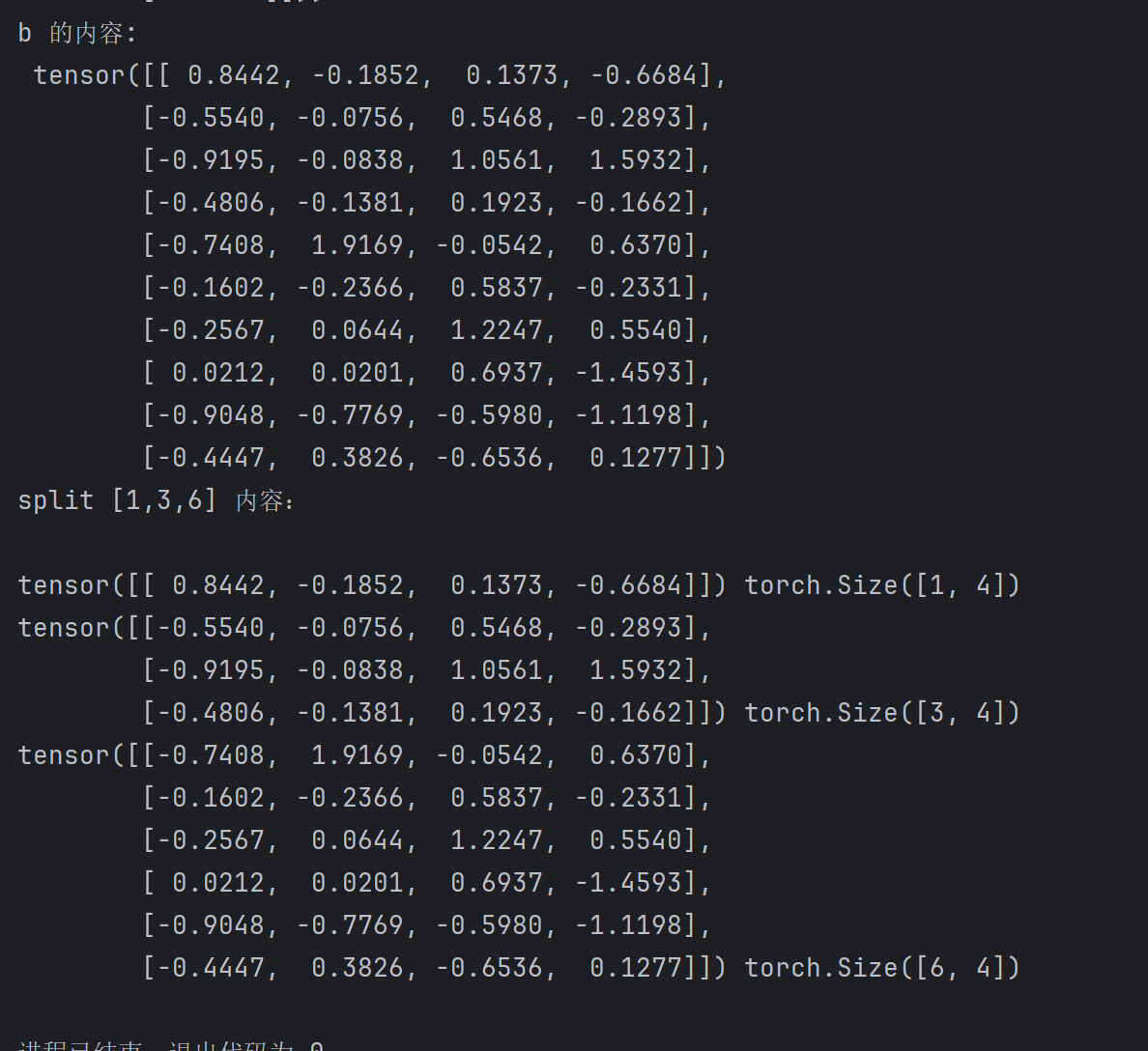
b = torch.randn(10,4)
print("b 的内容:\n",b)
print("split [1,3,6] 内容:\n")
out = torch.split(b,[1,3,6],dim=0)for item in out:print(item,item.shape) 初始化了一个 10 x 4 的矩阵张量,split 如果第二个参数是整数,那么就和 chunk 一致了。所以我们经常使用 spit ,兼容比较大。当传入一个列表的时候,我们会发现会把矩阵按照这个步长列表分割,就会形成这个容量的分割成员。使用 for 循环打印,如图 4.2 所示:
五、Tensor 的变形操作
torch.reshape(input,shape)torch.t(input)2D 矩阵转置torch.transpose(input,dim = 0,dim = 1)交换两个维度torch.squeeze(input, dim = None, out = None)去除那些大小为 1 的矩阵torch.unbind(tensor, dim = 0)去除某个维度torch.unsqueeze(input,dim,out = None)在指定位置添加维度torch.flip(input, dims)按照指定的维度反转张量orch.rot(input, k,dims)按照指定的维度和旋转次数进行张量旋转
torch.reshape
import torch
a = torch.rand(2,3)
print("a 的内容:\n",a)
print("a reshape:\n",a.reshape(3,2))
运行结果:

reshape 用于重构任意矩阵,从代码看出,不是转置运算。核心思想是把一个张量看成一个数组(也是存储的底层逻辑),然后按照给定的规模进行重构,顺序选择元素,填入新的张量中。结合运行结果图,更加直观。
torch.t
print("a 的内容:\n",a)
print("a t 转置:\n",a.t())
转置就是 t,和线性代数的 A T A^T AT 挺像,太简单了,运行结果图就不放了。
torch.transpose
b = torch.rand(1,2,3)
print("b 的内容:\n",b)
print("b transpose:\n",torch.transpose(b,0,1))
print("b shape",torch.transpose(b,0,1).shape)
随机生成了一个(1,2,3)三维的张量,然后调用torch.transpose 交换前两个维度。
运行结果:
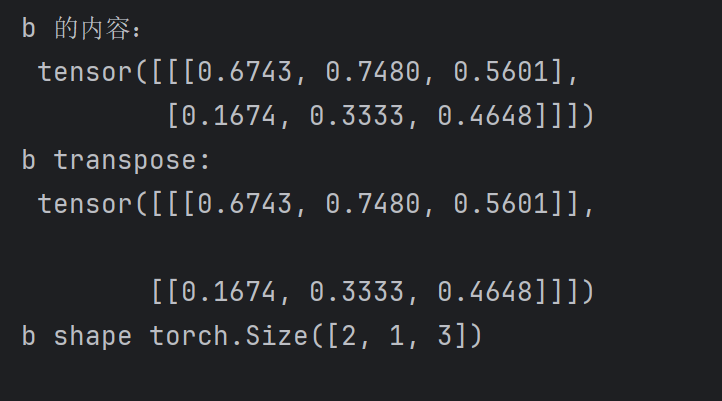
这张图注意看,前后的中括号位置,是有变化的,张量交换后变成了(2,1,3)
torch.squeeze 和 torch.unsqueeze
# squeeze 和 unsqueeze
c = torch.squeeze(b,0)
print("b squeeze:\n",c,c.shape)
print("c unsqueeze:\n",c.unsqueeze(0),c.unsqueeze(0).shape)
运行结果:
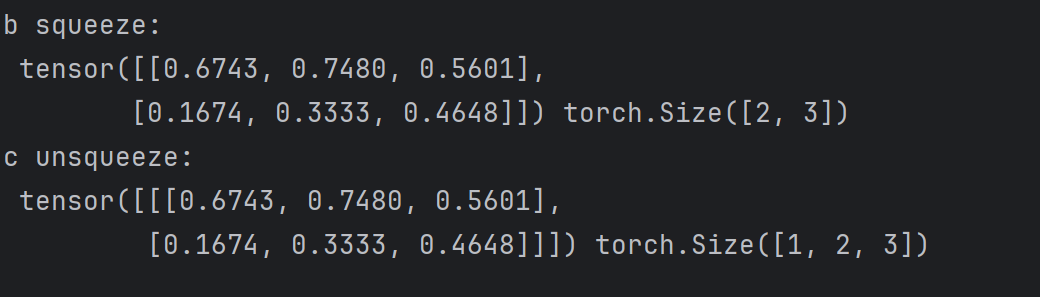
张量的压缩,只能处理张量是 1 的,比如一个张量(1,2,3),我们使用squeeze 压缩,只能压缩1,也就是 dim = 0,unsqueeze 就是把对应的维度提升到1,加一个中括号。
torch.unbind
# unbind 去除某个维度
d =torch.rand(2,2,3)
print("d 的内容:\n",d)
print("d 去除第一个维度:\n",torch.unbind(d,dim=0))
print("d的成员\n",d[0,:,:])
print("d 去除中间维度:\n",torch.unbind(d,dim=1))
print("d的成员\n",d[:,0,:])
print("d 去除中间维度:\n",torch.unbind(d,dim=2))
print("d的成员\n",d[:,:,0])
结果图:
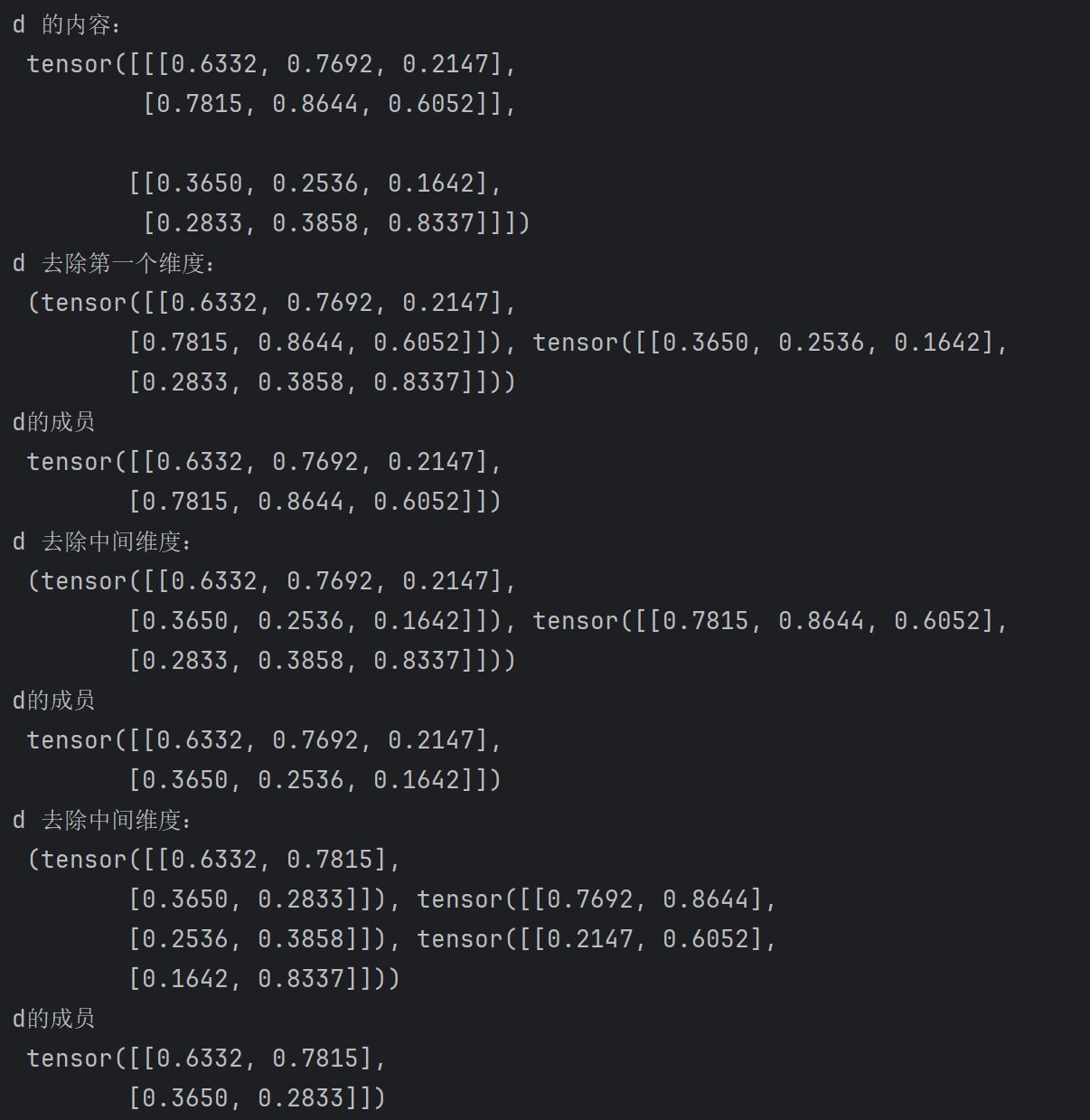
消去维度,这个理解不难,比如一个张量(2,2,3)去除第三个维度,会形成三个(2,2)的张量,就是成员变量。难点就是你怎么去找准高维度张量的成员。
torch.flip
x = torch.tensor([[1, 2, 3],[4, 5, 6],[7, 8, 9]])result1 = torch.flip(x, dims=[0])
result2 = torch.flip(x, dims=[0, 1])print(result1)
print(result2)
运行结果:
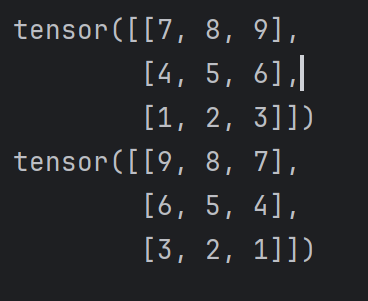
张量反转就是把张量维度进行倒序排列。关键点还是要找准成员,其实不难理解,反而unbind消除维度,找到分解维度的成员难度变得更大。
rot90
这个输入最好就是一张图片,进行旋转,这里就不展示了,用的时候再了解。