单卡即可微调大模型!内存占用仅1/8
诸如Qwen,GPT,DeepSeek R1等基础大模型已成为现代深度学习的基石。
然而,在应用于具体下游任务时,它们庞大的参数规模使得额外微调成本较高。
为了解决这一问题,近期的研究聚焦于低秩适应 (LoRA) 方法,通过保持基座模型参数冻结,仅对新增的小型轻量级适配器进行微调,从而降低微调成本。
尽管LoRA具有较高的效率,然而其微调性能往往不及全量微调。
面对这一挑战,华中科技大学和香港中文大学团队提出了一项全新的LoRA微调框架——GOAT,该工作已成功被ICML 2025正式接收。
这项研究提出了一套自适应奇异值初始化与混合专家梯度对齐策略,成功缓解低秩适应(LoRA)性能不足的难题,在25个多领域任务中实现接近甚至超越全参数微调(Full FT)的效果,同时仅需调整极小比例参数。

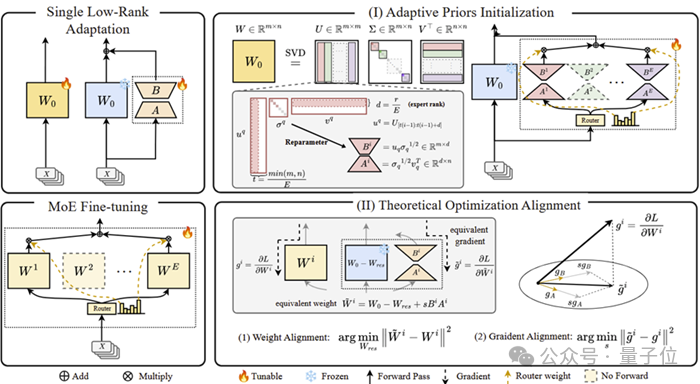
低秩适应效果不如预期
传统LoRA通过在预训练权重矩阵中添加低秩适配器(如BA矩阵),大幅减少可训练参数(通常仅需调整0.1%-5%参数),但其性能往往显著落后于全参数微调。
现有方法通常通过随机初始化或者静态奇异值分解(Singular Value Decomposition, SVD)子空间进行初始化,以优化LoRA性能,但这类方式未能充分挖掘预训练模型中已有的知识。
另一条提升LoRA表现的路径是引入混合专家架构(Mixture-of-Experts, MoE)。然而,复杂的梯度动态使得在LoRA MoE架构中应用SVD初始化方法面临较大挑战。
取最大/小分量不一定好?重新审视SVD初始化
先前基于SVD初始化的方法通常会对最大或最小奇异值对应的子空间进行微调:PiSSA仅对具有最大范数的部分进行微调,而MiLoRA和KaSA则冻结较大的分量,对较小的部分进行低秩适应。如图所示:
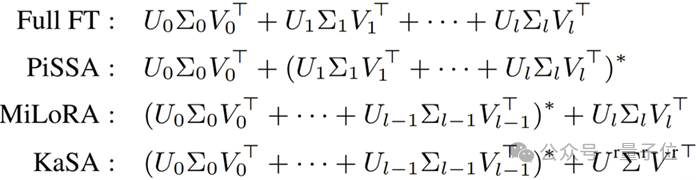
实际使用中,由于忽略了其他的SVD片段,PISSA和MiLoRA的方法并不能保证其有较好的效果,尤其是在秩较低的情况下。
作者针对不同数据集,使用不同的SVD片段来初始化进行分析发现,不同任务对应的最佳SVD片段不同,同时其很可能在中间片段表现最好。
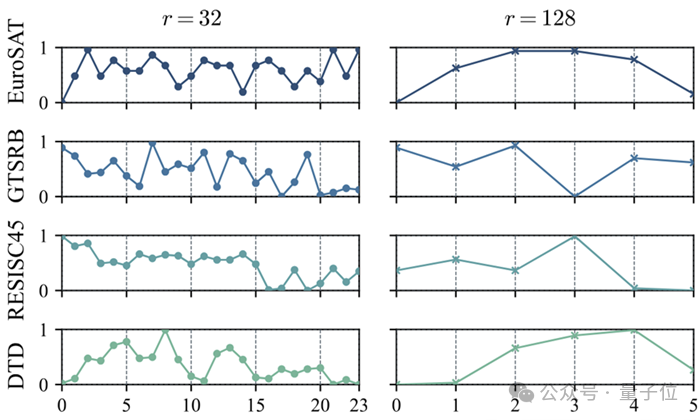
利用MoE的动态选择特性,研究人员提出了一种自适应SVD初始化,设计一个LoRA MoE的结构实现收敛速度和最终收敛性能的权衡。
首先对预训练大模型权重做奇异值分解,将其分解为多段,由MoE路由动态选择最相关的奇异值组合,灵活适配不同任务需求。其中每个和的expert由均匀切片的SVD片段构成,,使其能捕获 的更全面的先验信息。
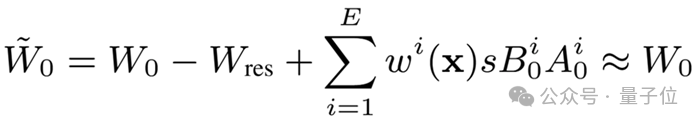
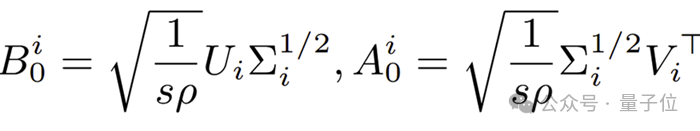
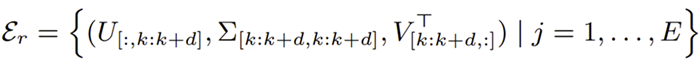
缩放因子过小?LoRA的低秩梯度偏差
先前的LoRA方法中,常见的做法是使用缩放形式,且通常设为2。
基于SVD的方法则通过将和同时除以,从而在权重大小不依赖于。
通过实验分析,仅通过调整 能对LoRA的收敛速度和最终性能产生较大影响,尤其是极度低秩的场景下(在LoRA MoE中非常常见)。
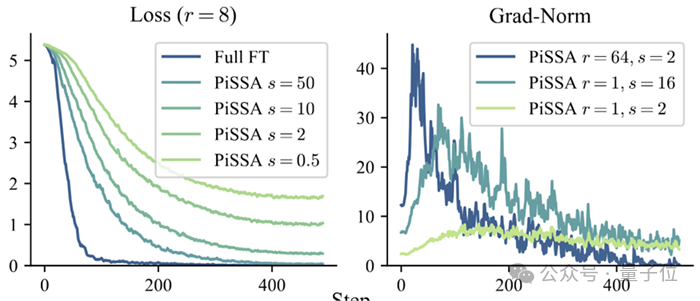
为详细研究这一点,研究人员引入理论对齐假设:
使用全量微调的Upcycled MoE(也即直接使用预训练权重初始化)作为性能上界。
如果在微调LoRA MoE的过程中,对每个专家,在初始化时保证LoRA专家的等效权重与全量微调MoE的专家权重一致,并在每次更新中使LoRA专家等效梯度与MoE全秩微调梯度对齐,LoRA MoE就可以与全秩微调的 Upcycled MoE 在每一步优化都实现对齐,理论上能达成相同的性能。
利用该假设,对于等效权重对齐,研究人员推导出SVD初始化中使接近,需要减去额外减去矩阵最优期望为:
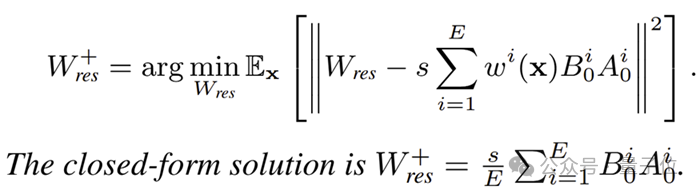
对于等效梯度对齐,研究人员通过代数分析,联立每个专家的LoRA等效梯度与全量微调(Full Fine-Tuning, FFT)的梯度,近似推导出一个闭式解。
其中,表示模型维度,表示FFT与LoRA学习率的比值,表示LoRA的秩,通常该秩远小于模型维度,使得推导出的明显大于经验取值2。
这一结果从理论上证明了当前广泛采用的经验缩放因子过小的问题,同时也提供了一种与模型架构无关的偏差调整机制——即通过合理设置缩放因子来弥补LoRA在低秩子空间中梯度偏移所带来的性能差距,从而更贴近全量微调的行为表现。
这种方法为提升LoRA的微调效果提供了一个理论驱动的改进方向。
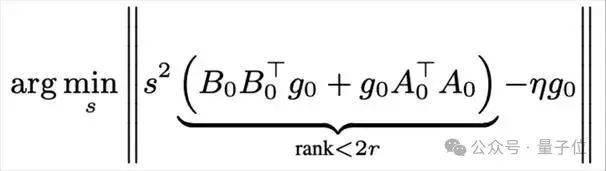
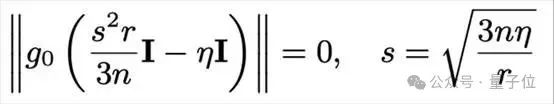
实验结果:25项任务全面领先
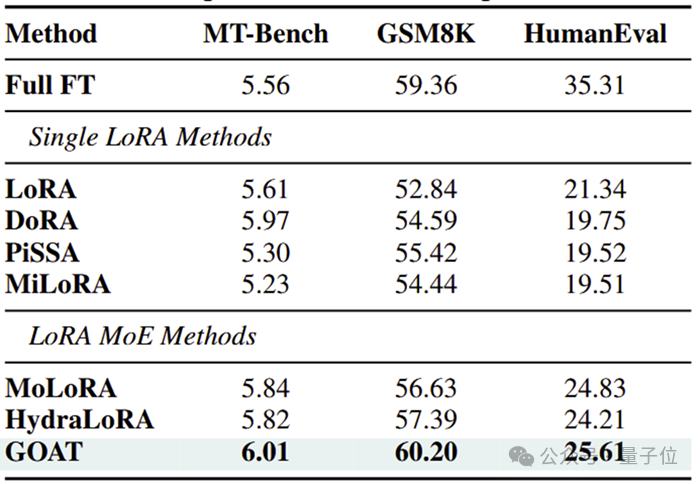
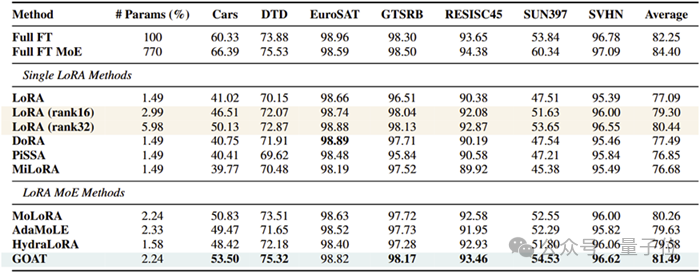
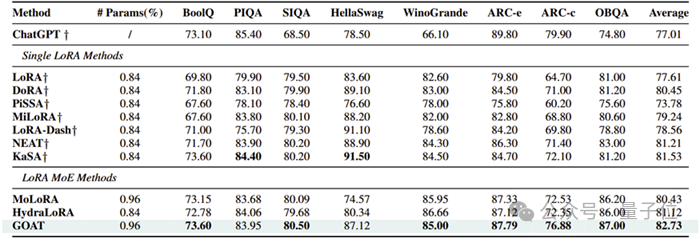
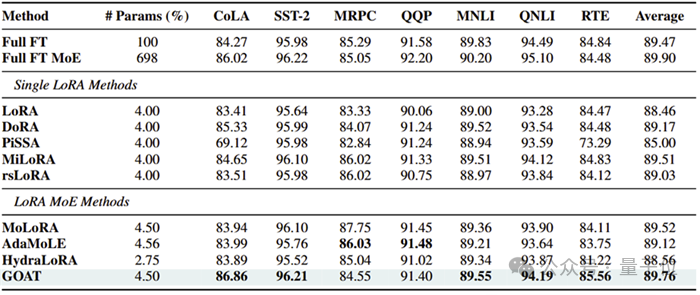
团队在自然语言生成(GSM8K, HumanEval, Mt-Bench)、自然语言理解(GLUE)、常识推理(CommonsenseQA)、图像分类(ImageNet子集)等4个领域25个数据集上验证GOAT的优越性:
自然语言生成:比主流的LoRA MoE变体,在Mt-Bench中超越4.2%,GSM8K中超越6.3%,HumanEval中超越3.1%,逼近全量微调水平;
图像分类:在CLIP-ViT微调中,仅用2.24%参数即达到全参数微调99%性能,超越主流LoRA变体6%,主流LoRA MoE变体2.4%;
常识推理:平均准确率82.73%,超越ChatGPT7.42%,展现强大知识迁移能力;
自然语言理解:领先于全量微调,和FT MOE的差距缩小至0.1%;
GOAT无需修改模型架构或训练算法,仅通过初始化策略与梯度缩放即可实现性能飞跃,具备极强实用性:
内存占用降低8倍:训练LLaMA7B时,相比全参数微调MoE,GOAT内存需求从640GB压缩至35GB,单卡即可训练;
收敛速度快效果好:比起其他的LoRA MoE,收敛有着更快的收敛速度和更好的效果;
灵活扩展:支持动态调整专家数量与激活比例,平衡性能与效率。
未来,GOAT优化方法有望在后训练阶段提供有效指导,同时为预训练场景开辟新的思路,从而进一步挖掘和释放人工智能性能的潜能。
论文地址: https://arxiv.org/pdf/2502.16894v3
Github地址: https://github.com/Facico/GOAT-PEFT