时序预测力作PatchMixer论文理解
paper: https://arxiv.org/abs/2310.00655
code: https://github.com/Zeying-Gong/PatchMixer
一、模型总览
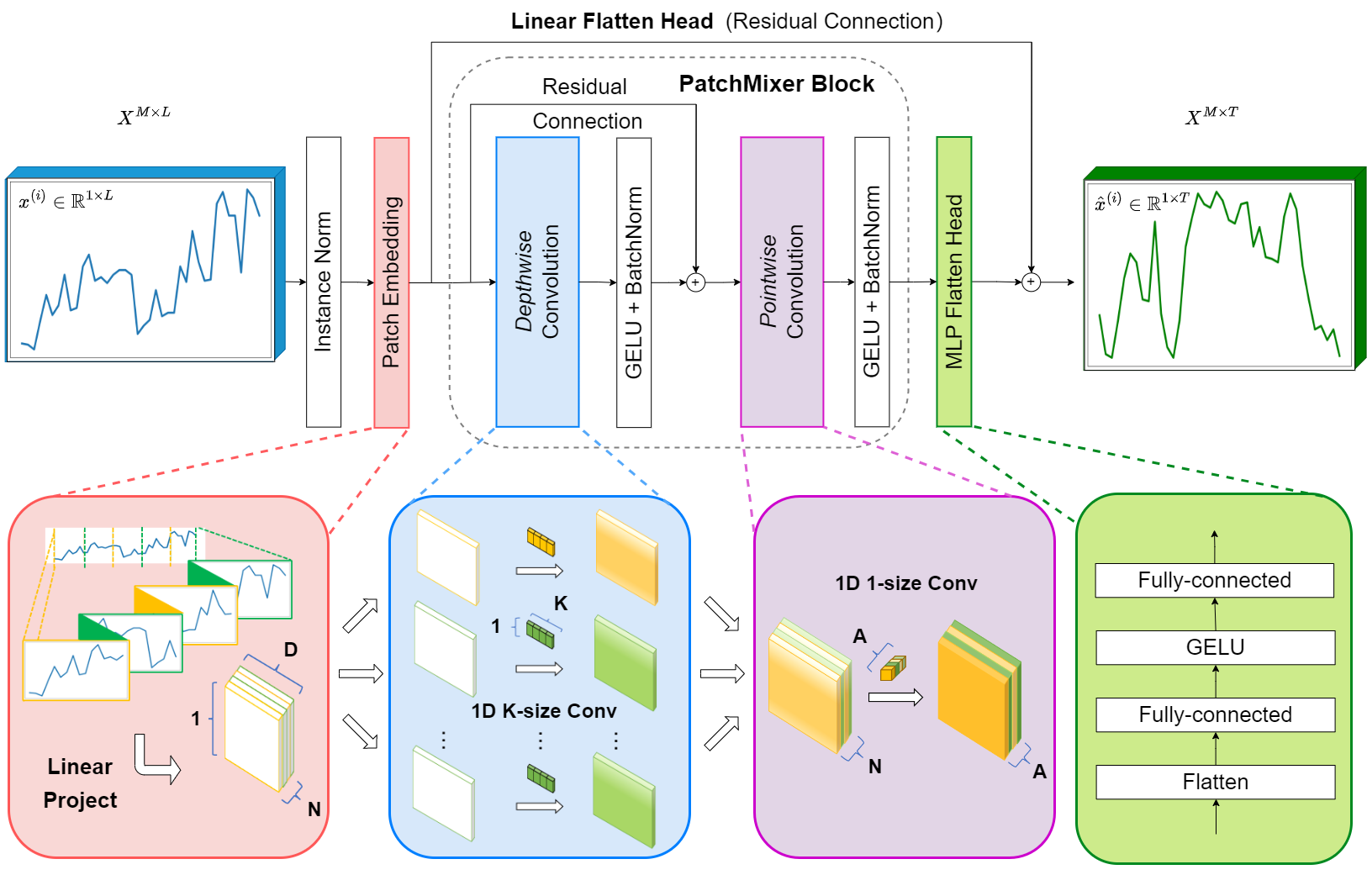
二、训练的流程
2.1 训练流程可以分为以下几个主要步骤
1. 数据准备:
-
数据预处理:首先,对时间序列数据进行标准化或实例归一化,以保持数据的分布一致,减少模型训练时的波动。
-
补丁划分:将时间序列数据切分成多个补丁,每个补丁长度固定,以保留时间顺序的特征。
2. 建立模型:
- 模型架构初始化:基于深度可分离卷积(Depthwise Separable Convolution)和补丁混合设计初始化 PatchMixer 模型的结构,包含必要的层如补丁嵌入层、深度可分离卷积层和双头预测机制。
3. 定义损失函数和优化器:
-
损失函数:选择合适的损失函数(如均方误差或其他适用于时间序列预测任务的损失函数),以量化预测输出与真实值之间的差异。
-
优化器:选择一种优化算法(如Adam、SGD等),用于更新网络中的参数以最小化损失函数。
4. 训练过程:
-
前向传播:将训练数据输入模型,通过各层进行计算,输出预测结果。
-
损失计算:根据输出的预测值和真实值计算损失。
-
反向传播:使用反向传播算法计算梯度,并通过优化器更新模型参数,从而降低损失。
-
迭代步骤:重复执行前向传播、损失计算和反向传播的过程,直到达到预设的训练轮数或损失收敛。
5. 超参数调整:
- 在训练过程中,利用验证集监控性能并根据需要调整超参数,例如学习率、批量大小等,确保模型的泛化能力得到提升。
6. 评估与验证:
- 使用独立的验证集对训练得到的模型进行评估,确保模型能够有效地捕捉到时间序列的动态变化并进行准确预测。
7. 模型保存:
- 训练结束后,将性能最佳的模型参数保存,便于后续的预测或进一步的微调。
通过这一系列步骤,PatchMixer 模型能够在长时间序列预测任务中有效地学习数据中的潜在模式和依赖关系,最终实现高效的预测能力。
2.2 训练调整的参数
在训练 PatchMixer 模型时,以下是一些关键的超参数和需要调整的参数,以确保模型的最佳性能和泛化能力:
1. 学习率 (Learning Rate):
- 学习率控制模型参数更新的步幅,选择合适的学习率非常重要,过高可能导致模型不收敛,过低则可能导致训练速度过慢。
2. 批量大小 (Batch Size):
- 批量大小影响每次更新模型参数所用的数据量,较小的批量大小可能导致更好的泛化性能,而较大的批量大小可以加快训练速度,但可能导致模型陷入局部最优解。
3. 训练轮次 (Epochs):
- 训练轮次是指整个数据集用于训练的次数。过多的轮次可能导致过拟合,因此需要根据验证集性能监控早停(Early Stopping)。
4. 補丁大小 (Patch Size):
- 在补丁混合架构中,补丁大小直接影响模型学习的时间序列特征的 granularity,选择适当的补丁大小可以提升模型的预测性能【T6】【T7】。
5. 补丁步幅 (Patch Strides):
- 补丁的步幅决定了从原始数据中提取补丁的间隔,这也可能影响模型的输入信息和学习能力,适当的步幅可以优化模型学习到的信息【T7】。
6. 网络结构参数:
- 包括卷积层的数量、每层的深度、每层的输出维度等。这些参数定义了模型的复杂度和学习能力。
7. 正则化参数:
- 包括 Dropout 率和 L2 正则化等,用于防止过拟合,保证模型的泛化能力。
8. 损失函数的选择:
- 不同的损失函数(如均方误差、平均绝对误差等)可能适用于不同的任务和数据特性,因此选择合适的损失函数也非常重要【T9】。
9. 优化器的选择:
- 根据模型的特点和数据的分布,选择合适的优化器(如 Adam、SGD、RMSprop 等),并调整相关的参数(如动量参数等)。
通过对这些超参数的调整和优化,可以提升 PatchMixer 模型在长时间序列预测任务中的性能。这些参数的调整通常需要通过实验验证,并结合模型在训练集和验证集上的表现进行细致的评估。
三、预测的流程
3.1 预测流程可以分为以下几个主要步骤
1. 数据预处理:
- 将原始时间序列数据按需进行标准化或实例归一化,以保持输入数据的分布。这一步是确保模型稳定性的关键。
2. 补丁划分:
- 将时间序列数据划分为多个补丁。每个补丁是在时间序列中连续的一组观察值,这样可以保留时间的顺序特征。
3. 补丁嵌入:
- 对每个补丁进行嵌入,将其转换为适合后续处理的特征表示。这个过程涉及对补丁内的信息进行编码,通常是通过嵌入层实现。
4. 模型前向传播:
- 使用深度可分离卷积(Depthwise Separable Convolution)对补丁进行处理。这种处理允许模型独立地对每个通道进行卷积,有助于减少复杂性且提高效率。
- 通过双头预测机制,分别对线性和非线性模式进行建模,从而捕捉时间序列中的多种动态变化。
5. 参数优化:
- 在训练过程中,通过优化补丁嵌入参数和损失函数,以提升模型的预测性能。采用合适的损失函数(如均方误差)能够帮助模型稳定地适应数据。
6. 预测输出:
- 最终通过模型的输出层生成预测结果。这些结果是未来时间点的预测值,根据不同的预测任务,可以是多变量的预测结果【T3】【T5】。
3.2 需要调整的参数:
1. 补丁大小:
- 定义每个补丁的时间窗口长度,这会影响模型捕捉时间序列短期与长期依赖关系的能力。
2. 卷积核大小(K):
- 深度可分离卷积中卷积核的大小,通常取K的值会影响模型的局部感知能力。
3. 嵌入维度(D):
- 输入嵌入的维度设置,这影响到模型表示能力的复杂度。
4. 学习率:
- 模型训练过程中使用的学习率,这会对训练的收敛速度和稳定性产生显著影响。
5. 批量大小:
- 每次迭代时输入的样本数量,选择合适的批量大小能够在训练时均衡计算效率与内存使用。
6. 优化算法:
- 选择适当的优化算法(如Adam、SGD等),对模型的训练效果和收敛速度有重要影响。
通过调整这些参数,可以优化 PatchMixer 模型的性能,使其更好地适应特定的预测任务和数据集特征。
三、实验
3.1 关于训练/验证/测试数据集的划分
从data_loader.py中可以看到更详细的数据处理方式,详细解释如下:
1. 关于训练/验证/测试数据集的划分
- 对于自定义数据集(Dataset_Custom),数据划分比例是:
num_train = int(len(df_raw) * 0.7) # 70%训练集
num_test = int(len(df_raw) * 0.2) # 20%测试集
num_vali = len(df_raw) - num_train - num_test # 10%验证集
- 选取的具体方式(结合输入和预测序列具体见2)
num_train = int(len(df_raw) * 0.7)
num_test = int(len(df_raw) * 0.2)
num_vali = len(df_raw) - num_train - num_test
border1s = [0, num_train - self.seq_len, len(df_raw) - num_test - self.seq_len]
border2s = [num_train, num_train + num_vali, len(df_raw)]
border1 = border1s[self.set_type]
border2 = border2s[self.set_type]
- 具体示例
假设你有1000行数据,seq_len=96, label_len=48, pred_len=96:
seq_len:这个比较重要,这是每次训练的输入序列长度
数据划分:
- 训练集:1-700行 # 700
- 验证集:701-800行 # 100
- 测试集:801-1000行 # 200
数据划分结构:(训练集) (测试集)train=700 test=200+96__________________ ________________| | | |
时间点: [1,2,3,...,604,...,700,...,704,...,800,...,1000]|_____________________|vali=100+96 (验证集)
- CSV文件的要求:
'''
df_raw.columns: ['date', ...(other features), target feature]
'''
- 必须有一个’date’列
- 一个或多个特征列
- 一个目标特征列
3.2 数据集内部输入/预测序列的划分
1. 每个样本的构成
s_begin = index
s_end = s_begin + self.seq_len
r_begin = s_end - self.label_len
r_end = r_begin + self.label_len + self.pred_len
seq_x = self.data_x[s_begin:s_end]
seq_y = self.data_y[r_begin:r_end]
具体示例:
seq_len=96, label_len=48, pred_len=96
解释:
seq_len=96: 用96个时间点作为输入
label_len=48: 解码器可以看到的历史数据长度
pred_len=96: 需要预测的未来96个点
单个样本的结构:(输入) seq_len=96_________________| |
时间点: [1,2,3,...,48,...,96,...,192]|______||_______| label_len=48 pred_len=96(重叠部分) (预测)
2. 数据集内样本的个数
- 在每个数据集内部,会生成多个训练样本:
def __len__(self):return len(self.data_x) - self.seq_len - self.pred_len + 1
以训练集为例(700条数据),生成的样本个数:
样本1: 输入[1:96], 预测[97:192]
样本2: 输入[2:97], 预测[98:193]
样本3: 输入[3:98], 预测[99:194]
...
最后一个样本: 输入[507:603], 预测[604:700]可生成的样本数 = 700 - 96 - 96 + 1 = 509个训练样本
在三个数据集中的应用:
训练集(700条数据):
- 可以生成约509个训练样本
- 每个样本都是(seq_len=96)→(pred_len=96)的映射验证集(100条数据):
- 可以生成约(100-96-96+1)=9个验证样本
- 用于调整模型参数测试集(200条数据):
- 可以生成约(200-96-96+1)=9个测试样本
- 用于最终评估模型性能
- 数据集和
seq_len和pred_len参数的关系
seq_len和pred_len决定了每个数据集能生成多少个样本- 数据集的大小必须要大于
seq_len + pred_len - 每个数据集(训练/验证/测试)都是独立的,使用各自的数据生成样本
- 样本的生成是滑动窗口方式,步长为1
- 关于数据集一些建议
- 确保你的数据量足够大,至少要比
seq_len + pred_len大很多 - 如果数据量较小,可以考虑减小
seq_len和pred_len的值 - 验证集和测试集的大小要足够生成多个样本进行评估
3. 数据处理其他细节
这里是数据标准化以及时间特征编码的细节
# 数据标准化
if self.scale:train_data = df_data[border1s[0]:border2s[0]]self.scaler.fit(train_data.values)data = self.scaler.transform(df_data.values)# 时间特征编码
df_stamp['month'] = df_stamp.date.apply(lambda row: row.month, 1)
df_stamp['day'] = df_stamp.date.apply(lambda row: row.day, 1)
df_stamp['weekday'] = df_stamp.date.apply(lambda row: row.weekday(), 1)
df_stamp['hour'] = df_stamp.date.apply(lambda row: row.hour, 1)
4. 使用示例
如果你有一个自己的CSV文件,可以这样使用:
python run_longExp.py \--data custom \ # 使用自定义数据集--root_path ./your_data/ \ # 数据目录--data_path your_data.csv \ # 数据文件名--target your_target_column \ # 目标列名--seq_len 96 \ # 输入序列长度--label_len 48 \ # 标签长度--pred_len 96 \ # 预测长度--features M # 使用多变量预测
总结一下:
- 你的CSV文件至少需要:96(输入) + 96(预测) = 192个时间点的数据
- 建议数据量至少有1000个时间点以上,这样可以有足够的训练样本
- 数据会自动按7:1:2的比例分为训练/验证/测试集
- 每个样本包含seq_len长度的输入和pred_len长度的预测目标
- 数据会自动进行标准化处理和时间特征编码
3.3 关于预测数据集的划分
从代码中可以看到,预测数据集(Dataset_Pred)的处理方式与训练/验证/测试集不同。让我解释预测数据集的划分:
- 预测数据集的创建:
elif flag == 'pred':shuffle_flag = False # 不打乱顺序drop_last = False # 不丢弃最后的数据batch_size = 1 # 批次大小为1freq = args.freqData = Dataset_Pred # 使用专门的预测数据集类
- 预测数据集的数据选择:
# 在Dataset_Pred类中
border1 = len(df_raw) - self.seq_len # 起始位置:倒数第seq_len个点
border2 = len(df_raw) # 结束位置:最后一个点self.data_x = data[border1:border2] # 只取最后一段数据
- 样本生成方式:
def __len__(self):return len(self.data_x) - self.seq_len + 1 # 预测数据集可生成的样本数
具体例子:
假设你有1000个数据点,seq_len=96, pred_len=96:
预测数据的选择:
- 使用最后96个点:[905,906,...,1000]
- 这96个点作为输入
- 预测未来96个点:[1001,1002,...,1096]与训练集的区别:
训练集:会生成多个滑动窗口的样本
预测集:只使用最后一段数据,生成一个预测样本
关键区别:
- 预测数据集不需要划分(不像训练集分成70/20/10)
- 只使用最后一段数据(长度为seq_len)
- batch_size固定为1
- 不需要打乱数据顺序
- 预测的是实际数据之后的未来值
使用流程:
# 1. 加载全部数据
df_raw = pd.read_csv(data_path)# 2. 只取最后seq_len个点
data_x = data[len(data)-seq_len:]# 3. 用这些点预测未来pred_len个点
pred = model(data_x) # 预测未来96个点
所以,预测数据集实际上不存在"划分",它只是简单地使用最后一段连续数据来预测未来值。