HAWQ 取代传统数仓实践(十八) —— 层次维度
目录
一、层次维度简介
二、固定深度的层次
三、多路径层次
四、参差不齐的层次
五、递归
一、层次维度简介
大多数维度都具有一个或多个层次,例如,示例数据仓库中的日期维度就有一个四级层次:年、季度、月和日,这些级别用 date_dim 表里的列表示。日期维度是一个单路径层次,因为除了年-季度-月-日这条路径外,它没有任何其他层次。为了识别数据仓库里一个维度的层次,首先要理解维度中列的含义,然后识别两个或多个列是否具有相同的主题。例如,年、季度、月和日具有相同的主题,因为它们都是关于日期的。具有相同主题的列形成一个组,组中的一列必须包含至少一个组内的其他成员(除了最低级别的列),如在前面提到的组中,月包含日。这些列的链条形成了一个层次,例如,年-季度-月-日这个链条是一个日期维度的层次。除了日期维度,邮编维度中的地理位置信息,产品维度的产品与产品分类,也都构成层次关系。表1 显示了三个维度的层次。
| zip_code_dim | product_dim | date_dim |
|---|---|---|
| zip_code | product_name | date |
| city | product_category | month |
| state | quarter | |
| year |
表1
本篇描述处理层次关系的方法,包括在固定深度的层次上进行分组和钻取查询,多路径层次和参差不齐层次的处理等。我们从最基本的情况开始讨论。
二、固定深度的层次
固定深度层次是一种一对多关系,例如,一年中有四个季度,一个季度包含三个月等等。当固定深度层次定义完成后,层次就具有固定的名称,层次级别作为维度表中的不同属性出现。只要满足上述条件,固定深度层次就是最容易理解和查询的层次关系,固定层次也能够提供可预测的、快速的查询性能。可以在固定深度层次上进行分组和钻取查询。
分组查询是把度量按照一个维度的一个或多个级别进行分组聚合。下面的脚本是一个分组查询的例子,该查询按产品(product_category 列)和日期维度的三个层次级别(year、quarter 和 month 列)分组返回销售金额。
select product_category,year,quarter,month,sum(order_amount) s_amount from v_sales_order_fact a,product_dim b,date_dim c where a.product_sk = b.product_sk and a.year_month = c.year * 100 + c.month group by product_category, year, quarter, month order by product_category, year, quarter, month; 这是一个非常简单的分组查询,结果输出的每一行度量(销售订单金额)都沿着年-季度-月的层次分组。
与分组查询类似,钻取查询也把度量按照一个维度的一个或多个级别进行分组。但与分组查询不同的是,分组查询只显示分组后最低级别、即本例中月级别上的度量,而钻取查询显示分组后维度每一个级别的度量。下面使用两种方法进行钻取查询,结果显示了每个日期维度级别,即年、季度和月各级别的订单汇总金额。
-- 使用 union all
select product_category, time, order_amount from (select product_category, case when sequence = 1 then 'year: '||timewhen sequence = 2 then 'quarter: '||time else 'month: '||time end time, order_amount, sequence, date from (select product_category, min(date) date, year time, 1 sequence, sum(order_amount) order_amount from v_sales_order_fact a, product_dim b, date_dim c where a.product_sk = b.product_sk and a.year_month = c.year * 100 + c.month group by product_category , year union all select product_category, min(date) date, quarter time, 2 sequence, sum(order_amount) order_amount from v_sales_order_fact a, product_dim b, date_dim c where a.product_sk = b.product_sk and a.year_month = c.year * 100 + c.month group by product_category , year , quarter union all select product_category, min(date) date, month time, 3 sequence, sum(order_amount) order_amount from v_sales_order_fact a, product_dim b, date_dim c where a.product_sk = b.product_sk and a.year_month = c.year * 100 + c.month group by product_category , year , quarter , month) x) yorder by product_category , date , sequence , time;-- 使用 grouping sets
select product_category, case when gid = 3 then 'year: '||year when gid = 1 then 'quarter: '||quarter else 'month: '||month end time, order_amountfrom (select product_category, year, quarter, month, min(date) date, sum(order_amount) order_amount,grouping(product_category,year,quarter,month) gidfrom v_sales_order_fact a, product_dim b, date_dim c where a.product_sk = b.product_sk and a.year_month = c.year * 100 + c.month group by grouping sets ((product_category,year,quarter,month),(product_category,year,quarter),(product_category,year))) xorder by product_category , date , gid desc, time;以上两种不同写法的查询语句结果相同,如图1 所示。
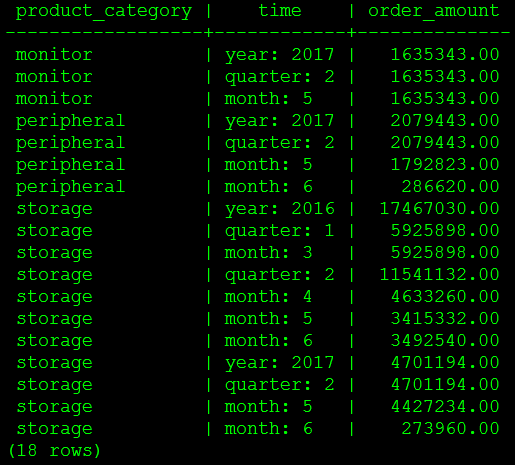
图1
第一条语句的子查询中使用 union all 集合操作将年、季度、月三个级别的汇总数据联合成一个结果集,注意 union all 的每个查询必须包含相同个数和类型的字段。附加的 min(date) 和 sequence 导出列用于对输出结果排序显示。这种写法使用标准的 SQL 语法,具有通用性。
第二条语句使用 HAWQ 提供的 grouping 函数和 group by grouping sets 子句。Grouping set 就是对列出的每一个字段组进行 group by 操作,如果字段组为空,则不进行分组处理。因此该语句会生成按产品类型、年、季度、月;类型、年、季度;类型、年分组的聚合数据行。grouping(<column> [, …]) 函数用于区分查询结果中的 null 值是属于列本身的还是聚合的结果行。该函数为每个参数产生一位 0 或 1,1 代表结果行是聚合行,0 表示结果行是正常分组数据行。函数值使用了位图策略(bitvector,位向量),即它的二进制形式中的每一位表示对应列是否参与分组,如果某一列参与了分组,对应位就被置为 1,否则为 0。最后将二进制数转换为十进制数返回。通过这种方式可以区分出数据本身中的 null 值。
三、多路径层次
多路径层次是对单路径层次的扩展。现在数据仓库的月维度只有一条层次路径,即年-季度-月这条路径,现在增加一个新的“促销期”级别,并且加一个新的年-促销期-月的层次路径。这时月维度将有两条层次路径,因此是多路径层次维度。
下面的脚本给 month_dim 表添加一个叫做 campaign_session 的新列,并建立 rds.campaign_session 过渡表。
alter table tds.month_dim add column campaign_session varchar(30) default null;
comment on column tds.month_dim.campaign_session is '促销期'; create table rds.campaign_session
(campaign_session varchar(30),month smallint,year smallint);假设所有促销期都不跨年,并且一个促销期可以包含一个或多个月份,但一个月份只能属于一个促销期。为了理解促销期如何工作,表2 给出了一个促销期定义的示例。
| 促销期 | 月份 |
|---|---|
| 2017 年第一促销期 | 1月—4月 |
| 2017 年第二促销期 | 5月—7月 |
| 2017 年第三促销期 | 8月 |
| 2017 年第四促销期 | 9月—12月 |
表2
每个促销期有一个或多个月。一个促销期也许并不是正好一个季度,也就是说,促销期级别不能上卷到季度,但是促销期可以上卷至年级别。假设 2017 年促销期的数据如下,并保存在 /home/gpadmin/campaign_session.csv 文件中。
2016 First Campaign,1,2017
2017 First Campaign,2,2017
2017 First Campaign,3,2017
2017 First Campaign,4,2017
2017 Second Campaign,5,2017
2017 Second Campaign,6,2017
2017 Second Campaign,7,2017
2017 Third Campaign,8,2017
2017 Last Campaign,9,2017
2017 Last Campaign,10,2017
2017 Last Campaign,11,2017
2017 Last Campaign,12,2017现在可以执行下面的脚本把 2017 年的促销期数据装载进月维度。
copy rds.campaign_session from '/home/gpadmin/campaign_session.csv' with delimiter ','; set search_path = tds;create table tmp as
select t1.month_sk month_sk,t1.month month1, t1.month_name month_name, t1.quarter quarter, t1.year year1, t2.campaign_session campaign_session from month_dim t1 left join rds.campaign_session t2 on t1.year = t2.year and t1.month = t2.month;
truncate table month_dim;
insert into month_dim select * from tmp;
drop table tmp; 此时查询月份维度表,可以看到 2017 年的促销期已经有数据,其他年份的 campaign_session 字段值为 null,如图2 所示。
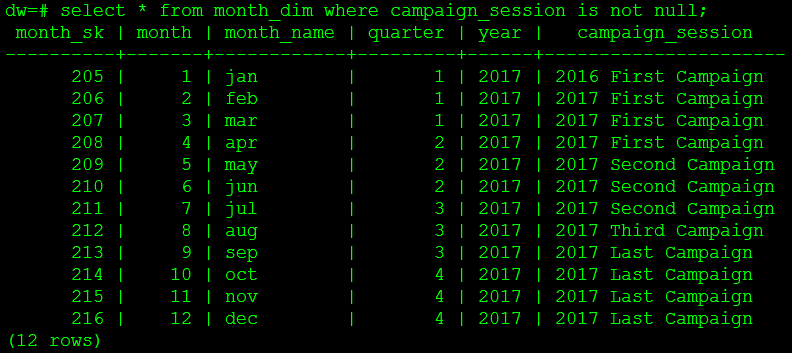
图2
注意:
- 本地文件必须在 HAWQ master 主机上的本地目录中。
- copy 命令需要使用 gpadmin 用户执行。
四、参差不齐的层次
在一个或多个级别上没有数据的层次称为不完全层次,例如在特定月份没有促销期,那么月维度就具有不完全促销期层次。下面是一个不完全促销期的例子,数据存储在 ragged_campaign.csv 文件中。2017年1月、4月、6月、9月、10月、11月和12月没有促销期。
,1,2017
2017 Early Spring Campaign,2,2017
2017 Early Spring Campaign,3,2017
,4,2017
2017 Spring Campaign,5,2017
,6,2017
2017 Last Campaign,7,2017
2017 Last Campaign,8,2017
,9,2017
,10,2017
,11,2017
,12,2017重新向 month_dim 表装载促销期数据。
truncate table rds.campaign_session;
copy rds.campaign_session from '/home/gpadmin/ragged_campaign.csv' with delimiter ','; set search_path = tds;create table tmp as
select t1.month_sk month_sk,t1.month month1, t1.month_name month_name, t1.quarter quarter, t1.year year1, null campaign_session from month_dim t1; truncate table month_dim; insert into month_dim
select t1.month_sk, t1.month1, t1.month_name, t1.quarter, t1.year1,case when t2.campaign_session != '' then t2.campaign_session else t1.month_name end campaign_sessionfrom tmp t1 left join rds.campaign_session t2
on t1.year1 = t2.year and t1.month1 = t2.month; drop table tmp; 在有促销期的月份,campaign_session 列填写促销期名称,而对于没有促销期的月份,该列填写月份名称。轻微参差不齐层次没有固定的层次深度,但层次深度有限,如地理层次深度通常包含 3 到 6 层。与其使用复杂的机制构建难以预测的可变深度层次,不如将其变换为固定深度位置设计,针对不同的维度属性确立最大深度,然后基于业务规则放置属性值。
五、递归
HAWQ 不支持递归查询,但支持递归函数,具体可参考“九、UDF 实例 —— 递归树形遍历”。