【数据结构】队列
目录
1.1 队列的抽象数据类型
1.2 顺序队列
1.3 链式队列
1.4 队列的深入讨论
1.4.1 顺序队列与链式队列的比较
1.4.2 限制存取点的表
本章小结
与栈类似,队列(queue)也是一种限制访问点的线性表。队列的元素只能从表的一端插人,另一端删除。按照习惯,通常会把只允许删除的一端称为队列的头,简称队头(font),把删除操作本身称为出队(dequeue);而称表的另一端为队列的尾,简称队尾(rear),这一端只能进行插人操作,称为入队(enqueue)。如同现实生活中的队列一样,在没有人为破坏的前提下,队列是按照到达的顺序来释放元素的,即先进入队列中的元素会先离开,因此队列通常也被称为先进先出(first in frst out)表,简称FIFO表。图3.9所示为队列的一个示例。售票窗口排队等待买票的人即为队列的一个日常实例。

1.1 队列的抽象数据类型
根据数据抽象和封装的原则,对队列的操作只能通过队列的抽象数据类型所定义的运算来进行。代码1.1给出了一个采用C++类模板的队列抽象数据类型定义,包括队列的入队、出队、查看队头等常用运算。
【代码1.1】队列的抽象数据类型定义
//栈的元素类型为T
template <class T>
class Queue {
public: //队列的运算集void clear(); //变为空队列bool enQueue(const T item); //将item插人队尾,成功则返回真,否则返回假bool deQueue(T& item); //返回队头元素并将其从队列中删除,成功则返回真bool getFront(T& item); //返回队头元素,但不删除,成功则返回真bool isEmpty(); //返回真,若队列已空bool isFull(); //返回真,若队列已满
}根据具体应用的不同需要,可以适当增删抽象数据类型中所定义的运算。例如,链式队列并不需要判断队列是否满。队列抽象数据类型中运算的实现方法依赖于队列的存储结构。下面介绍常用的顺序队列和链式队列两种存储结构。
1.2 顺序队列
用顺序存储结构来实现队列就形成了顺序队列(array-based queue)。与顺序表一样,顺序队列需要分配一块连续的区域来存储队列的元素,需要事先知道或估算队列的大小。与栈类似顺序队列也存在溢出问题,队列满时人队会产生上溢,而当队列为空时出队则会产生下溢。在队列出现上溢出时,如果需要,也可以考虑对队列进行适当的扩容。
如何有效地实现顺序队列,需要一些灵活的变通。如果只是沿用顺序表的实现方法,就很难取得良好的效率。假设队列中有个元素,顺序表的实现需要把所有元素都存储在数组的前n个位置上。如果选择把队列的尾部元素放在位置0,则出队列操作的时间代价为0(1),因为队列最前面的元素是数组最后面的元素,但是此时人队列操作的时间代价为0(n),因为必须把队列中当前元素都向后移动一个位置。反之,如果把队列尾部放在位置n-1,则人队列操作只需在最后添加即可,时间代价仅为0(1);而出队列操作需要移动剩余"-1个的元素以确保它们在表的前n-1个位置,其代价为0(n)。
如果在保证队列元素连续性的同时允许队列的首尾位置在数组中移动,则可以得到更加有效的实现方法,如图3.10所示。在经过多次的入队和出队操作之后,队头元素由12变成了8而队尾元素也变成了新入队的16。即随着出队操作的执行,表示队头的front值不断后移,同时随着人队操作的执行,表示队尾的rear值也在增加。
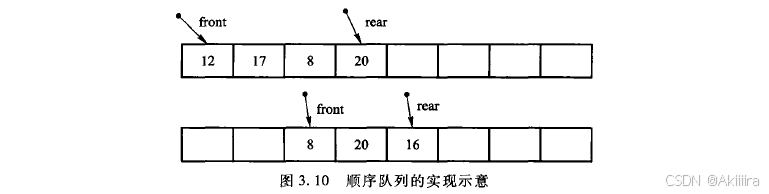
随着时间的推移,整个队列会向数组的尾部移动,一旦到达数组的最末端,即rear 等于 mSize-1,即使数组的前端可能还有空闲的位置,再进行人队操作也会发生溢出。这种数组实际上尚有空闲位置而发生上溢的现象称为“假溢出”。解决假溢出的方法便是采用循环的方式来组织存放队列元素的数组,在逻辑上将数组看成一个环,即把数组中下标编号最低的位置(0位置)看成是编号最高的位置(mSize-1)的直接后继,这可以通过取模运算实现。即数组位置x的后继位置为(x+1)% mSize,这样就形成了循环队列,也称环形队列。图3.11所示为一个环形队列的示例。起初,队首存放在数组中编号较低的位置,队尾则存放在数组中编号较高的位置,沿顺时针方向存放队列。这样,人队操作增加rear的值,出队操作增加front的值。
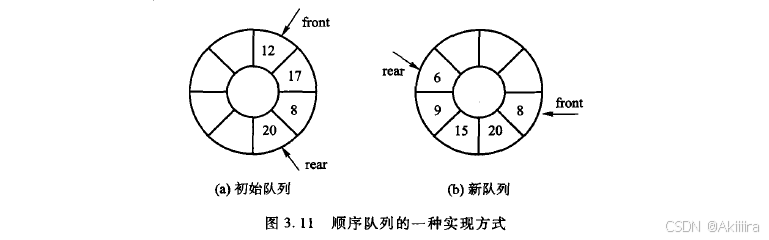
初始时队列中有4个元素12、17、8和20,如图3.11(a)所示。经过两次出队操作和三次人队操作之后形成了包括元素8、20、15、9、6的新队列,如图3.11(b)所示。
按图3.11所示的方式组织顺序队列时,用front存储队列头元素的位置,rear存储队尾元案的位置。若 font 和rear的位置相同,则表明队列中只有一个元素。下面介绍如何表示一个空队列,如何表示队列已被元素填满。
首先,忽略队首front的实际位置和其内容时,队列中可能没有元素(空队列)、有一个元素有两个元素等。如果数组有n个位置,则队列中最多有n个元素。因此,队列有n+1种不同的状态。如果把队首font的位置固定下来,则rear应该有n+1种不同的取值来区分这n+1种状态,但实际上rear 只有n种可能的取值,除非有表示空队列的特殊情形。换言之,如果用位置0~n-1间的相对取值来表示font和rear,则n+1种状态中必有两种不能区分。因此,需寻求其他途径来区分队列的空与满。
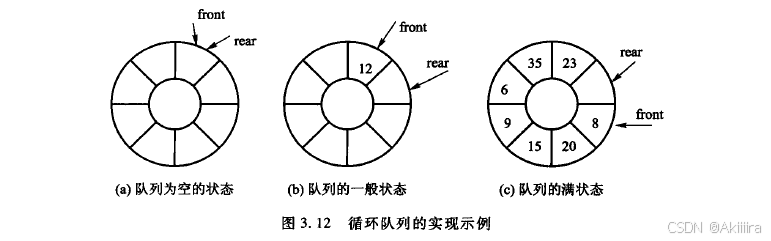
一种方法是记录队列中元素的个数,或者用至少一个布尔变量来指示队列是否为空。此方法需要每次执行人队或出队操作时设置这些变量。另一种方法,也是顺序队列通常采用的方法是把存储n个元素的数组的大小设置为n+1,即牺牲一个元案的空间来简化操作的实现和提高操作的效率。图3.12所示为一个如此实现的循环队列,8个元素大小的数组在放入7个元素后即称满,如若再要插入就会发生溢出。其中,图3.12(a)表示队列的空状态,此时front=rear;图3.12(b)表示队列的一般状态,此时rear=(front+1)%(n+1);图3.12(c)则表示队列的满状态,此时(rear +1)%(n+1)=front。
代码 1.2 给出了一个顺序队列的实现方法。
【代码1.2】队列的顺序实现
template <class T>
class arrQueue: public Queue <T> {
private :int mSize; //存放队列的数组的大小int front; //表示队头所在位置的下标int rear; //表示队尾所在位置的下标T * qu; //存放类型为T的队列元素的数组
public : //队列的运算集arrQueue(int size) { //创建队列的实例mSize = size + 1; //浪费一个存储空间,以区别队列空和队列满qu = new T [mSize];front = rear =0;}~arrQueue() { //消除该实例,并释放其空间delete [] qu;}void clear() { //清空队列front = rear;}bool enQueue(const T item) { //item 人队,插人队尾if(((rear + 1) % mSize) == front) {cout << "队列已满,滥出" << endl;return false;}qu[rear] = item;rear = (rear + 1) % mSize; //循环后继return true;}bool deQueue(T& item) { //返回队头元素并从队列中删除if(front == rear) {cout << "队列为空" << endl;return false;}item = qu[front];front = (front + 1) % mSize;return true;}bool getFront(T& item) { //返回队头元素,但不删除if(front == rear) {cout << "队列为空" << endl;return false;}item = qu[front];return true;}
}
1.3 链式队列
链式队列(linked queue)是队列的链式实现,是对链表的简化。代码1.3给出了链式队列的实现方法,其中链接的方向从队列的前端指向队列的尾端。成员front和rear是分别指向队首和队尾的指针,结点类型采用 【数据结构】线性表-CSDN博客 中已定义过的Iink类模板:同时,为了方便统计队列中元素的个数,增加成员size来表示队列中当前元素的个数。
template <class T>
class lnkQueue: public Queue <T> {
private:int size; //队列中当前元素的个数Link <T>* front; //表示队头的指针Link <T>* rear; //表示队尾的指针
public: //队列的运算集lnkQueue(int size) { //创建队列的实例size = 0;front = rear = NULL;}~lnkQueue() {clear(); //消除该实例,并释放其空间}void clear() { //清空队列while(front != NULL) {rear = front;front = front -> next;delete rear;}rear = NULL;size = 0;}bool enQueue(const T item) //item 人队,插人队尾if(rear == NULL) { //空队列front = rear = new Link <T >(item,NULL);}else { //添加新的元素rear -> next = new Link <T>(item,NULL);rear = rear ->next;}size++;return true;}bool deQueue(T& item) { //返回队头元素并从队列中删除Link<T> *tmp;if(size == 0) { //队列为空,没有元素可出队cout << "队列为空" << endl;return false;}&item = front -> data;tmp = front;front = front -> next;delete tmp ;if( front == NULL)rear = NULL;size--;return true ;} bool getFront(T& item) { //返回队头元素,但不删除if(size == 0) { //队列为空,无法获取队头cout << "队列为空" << endl;return false;}item = front -> data;return true;}
}从代码1.3可以看出,链式队列的各成员函数是对链表相应函数的修改。本质上,入队操作 enQueue 只是简单地把新元素放到链表的尾部,并修改rear 使其指向新的结点;出队操作deQueue 只是简单地删除表中最前面的那个结点,并修改font指针使其指向新的队首。为了减少访问队首结点的时间代价,这种实现方法中没有链表中的专用表头虚结点,因此enOueue操作中必须单独处理插入到空队列的情况,deQueue 操作也需考虑出队后导致空队列的情况。
1.4 队列的深入讨论
1.4.1 顺序队列与链式队列的比较
由于存储空间固定,顺序队列无法满足队列规模变化很大且最大规模无法预测的情况,而链式队列则可以轻松应对这种类型的应用。另一方面,顺序队列在存取访问上很简单,可以适用那些对队列内部元素(不仅限于队列的两端)有访问需求的应用。如果可以预测浪涌统计特性就可以大致估计缓冲队列的长度。
顺序队列和链式队列中常用的人队和出队操作都需要常数时间,二者在时间效率上没有优劣之分。在空间代价上与栈的情况类似。只是顺序队列不像顺序栈那样,不能在一个数组中存储两个队列,除非总有数据项从一个队列转人另一个队列。
队列通常作为消息或数据缓冲器在很多领域得到广泛应用,但要满足先来先服务特性。例如,计算机的硬件设备之间需要队列作为其数据通信的缓冲。操作系统中使用队列对内存、打印机等各种资源进行管理,而且根据不同优先级别的服务请求,按优先类别把服务请求分别组织成多个不同的队列。
另外,在后续章节中将会看到,队列是广度优先搜索中采用的主要中间数据结构。
1.4.2 限制存取点的表
利用栈和队列的思想可以设计出一些变种的栈或队列结构。虽然它们的应用没有栈和队列那样广泛,但在一些特定情况下具有很好的应用价值。
(1)双端队列:限制插人和删除在线性表的两端进行。栈和队列都是特殊的双端队列,对其存取设置了限制。
(2)双栈:两个底部相连的栈。双栈是一种添加限制的双端队列,它规定从end1 插入的元素只能从end1端删除,而从end2 插人的元素只能从 end2 端删除。
(3)超队列:一种删除受限的双端队列,删除只允许在一端进行,而插入可在两端进行。
(4)超栈:一种插人受限的双端队列,插人只限制在一端而删除允许在两端进行。
由此可见,这几种限制存取点的表都是某种受限的双端队列。STL提供的基本序列中就有双端队列 deque,栈和队列都是通过 deque 实现的。
本章小结
队列也是一种限制访问端口的特殊线性表。其元素的删除只限于队列头一端进行;而元素的插人则被限制于队列尾一端。队列的特点是新来的成员总是加人到队的末尾,而每次取出的元素总是来自队列的前端。队列通常称为先进先出(FIFO)表。
队列的运算主要包括进队列、出队列、取队头元素、判断队列是否为空、判断队列是否已满等运算,运算的时间代价均为常数时间。
队列的存储结构和实现方法主要分为顺序和链式两种。顺序队列是比较普遍的一种队列实现方式,采用环状顺序表来存放队列元素,并用两个变量分别指向队列的头和尾,往队列中加人元素或从队列中取出元素时分别改变队列头和尾这两个变量的计数。链式队列一般用单链表方式存储队列,其中链接指针的方向是从队列的前端向尾端链接。
顺序队列采用固定的存储空间,一方面在读访问时非常简单,在特殊应用中需要访问内部元素时也很方便:但另一方面在某些无法事先估计其大小的情况下会出现溢出现象:链式队列可以通过动态申请空间来满足队列长度的大幅变动。
队列也是一种应用很广泛的数据结构。常见的应用包括广度优先搜索、消息缓冲器、操作系统的各种资源管理等,只要符合先进先出特性的应用均可运用队列。