DINOv3:自监督视觉模型的新里程碑!
DINOv3:自监督视觉模型的新里程碑!
在计算机视觉领域,自监督学习正迅速成为构建强大视觉表示的核心方法。最近发布的 DINOv3 模型,作为 DINO 系列的最新成员,展示了在密集视觉任务上的显著进步。本文将深入解读其最新研究成果,探讨其性能表现、局限性以及未来方向。

论文地址:https://arxiv.org/pdf/2508.10104
仓库地址:https://github.com/facebookresearch/dinov3
DINOv3 在语义分割中的卓越表现
DINOv3 的核心优势体现在密集预测任务上,尤其是语义分割。根据研究论文中的补充结果(Table 24),DINOv3 在多个主流语义分割数据集上均取得了顶尖性能:
- COCO-Stuff
- PASCAL VOC 2012
- Cityscapes
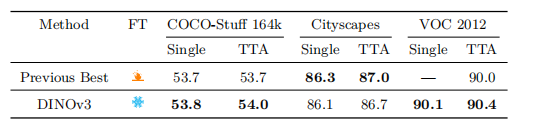
这些结果验证了 DINOv3 在像素级理解方面的强大能力,为自动驾驶、图像编辑、场景理解等应用提供了高质量的视觉基础模型。
挑战 OCR 密集型任务:字符识别的短板
尽管在语义分割上表现出色,但 DINOv3 在需要字符识别能力的分类任务中仍面临挑战。研究在 Table 25 中评估了模型在以下任务上的表现:
- 街道标志分类(Street-sign)
- 标志识别(Logo)
- 产品分类(Product)


性能对比
| 模型 | 类型 | 表现 |
|---|---|---|
| DINOv3 7B/16 | 自监督 | 显著优于 DINOv2 g/14 |
| DINOv2 g/14 | 自监督 | 基线模型 |
| PE-core G/14 | 弱监督 | 当前最佳 |
结果显示,DINOv3 虽然大幅超越了其前代 DINOv2,但仍远落后于最佳弱监督模型 PE-core G。
原因分析
根本原因在于:DINOv3 完全不使用图像-文本配对数据进行训练。这意味着它难以建立“字形-语义”之间的关联(glyph associations),例如无法理解图像中的文字“STOP”代表“停止”这一含义。
正如 Fan 等人(2025)的研究指出,训练数据的构成对这类任务的性能有决定性影响。DINOv3 的设计重点是提升密集特征的质量,而非文本理解。
“Since the main focus of our work is on improving dense features, we leave closing this gap for future work.”
—— 研究团队
公平性分析与未来展望
论文还提到了对模型的公平性分析(Fairness Analysis),表明研究者不仅关注性能,也重视模型的社会影响与鲁棒性。虽然具体内容未在此节展开,但这体现了负责任 AI 的发展趋势。

未来方向
- 融合多模态信号:将自监督学习与大规模图像-文本数据结合,可能在不牺牲密集特征质量的前提下,增强模型的语义与文本理解能力。
- 改进数据构建:如 Vo 等人(2024)提出的基于聚类的自动数据整理方法,可进一步优化自监督训练的数据质量。
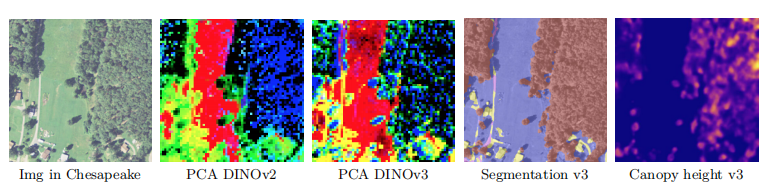
- 扩展至遥感与医疗影像:已有研究(如 Wang et al., 2024a; Vorontsov et al., 2024)表明,基础模型在遥感和病理学领域潜力巨大,DINOv3 的架构或可迁移至这些专业领域。
总结
DINOv3 代表了纯自监督学习在视觉表示学习中的最新高度,尤其在语义分割等密集任务上树立了新标杆。然而,它在 OCR 相关任务上的局限也揭示了一个关键问题:没有文本监督,模型难以理解图像中的语言信息。
这并非缺陷,而是一种设计取舍。DINOv3 的成功表明,专注于视觉结构学习可以产生强大的通用特征。未来的工作或将探索如何在保持这一优势的同时,有效融合语言信号,迈向真正的“通用视觉智能”。