Paimon——官网阅读:Flink 引擎
Flink 引擎
快速入门
本文档是在Flink中使用Paimon的指南。
相关JAR包
Paimon目前支持Flink 1.20、1.19、1.18、1.17、1.16、1.15 。为获得更好的体验,我们推荐使用最新的Flink版本。
下载对应版本的JAR文件。
目前,Paimon提供两种类型的JAR包:一种(捆绑JAR包)用于读取/写入数据,另一种(操作JAR包)用于手动压缩等操作。
| 版本 | 类型 | JAR包 |
|---|---|---|
| Flink 1.20 | Bundled Jar | paimon-flink-1.20-0.9.0.jar |
| Flink 1.19 | Bundled Jar | paimon-flink-1.19-0.9.0.jar |
| Flink 1.18 | Bundled Jar | paimon-flink-1.18-0.9.0.jar |
| Flink 1.17 | Bundled Jar | paimon-flink-1.17-0.9.0.jar |
| Flink 1.16 | Bundled Jar | paimon-flink-1.16-0.9.0.jar |
| Flink 1.15 | Bundled Jar | paimon-flink-1.15-0.9.0.jar |
| Flink Action | Action Jar | paimon-flink-action-0.9.0.jar |
你也可以从源代码手动构建捆绑JAR包。
要从源代码构建,克隆git仓库。
使用以下命令构建捆绑JAR包:
mvn clean install -DskipTests
你可以在./paimon-flink/paimon-flink-<flink-version>/target/paimon-flink-<flink-version>-0.9.0.jar找到捆绑JAR包,在./paimon-flink/paimon-flink-action/target/paimon-flink-action-0.9.0.jar找到操作JAR包。
开始使用
步骤1:下载Flink 如果你还没有下载Flink,可以下载Flink,然后使用以下命令解压归档文件:
tar -xzf flink-*.tgz
步骤2:复制Paimon捆绑JAR包 将Paimon捆绑JAR包复制到Flink安装目录的lib目录中:
cp paimon-flink-*.jar /lib/
步骤3:复制Hadoop捆绑JAR包 如果机器处于Hadoop环境,请确保环境变量HADOOP_CLASSPATH的值包含常见Hadoop库的路径,这种情况下无需使用以下预捆绑的Hadoop JAR包。
下载预捆绑的Hadoop JAR包,并将其复制到Flink安装目录的lib目录中:
cp flink-shaded-hadoop-2-uber-*.jar /lib/
步骤4:启动Flink本地集群 为了同时运行多个Flink作业,你需要修改<FLINK_HOME>/conf/flink-conf.yaml中的集群配置:
taskmanager.numberOfTaskSlots: 2
要启动本地集群,运行Flink自带的bash脚本:
<FLINK_HOME>/bin/start-cluster.sh
你应该能够通过localhost:8081访问Web界面,查看Flink仪表板并确认集群已启动并正在运行。
现在你可以启动Flink SQL客户端来执行SQL脚本:
<FLINK_HOME>/bin/sql-client.sh
步骤5:创建目录和表
目录
-- if you're trying out Paimon in a distributed environment,
-- the warehouse path should be set to a shared file system, such as HDFS or OSS
CREATE CATALOG my_catalog WITH ('type'='paimon','warehouse'='file:/tmp/paimon'
);USE CATALOG my_catalog;-- create a word count table
CREATE TABLE word_count (word STRING PRIMARY KEY NOT ENFORCED,cnt BIGINT
);步骤6:写入数据
-- create a word data generator table
CREATE TEMPORARY TABLE word_table (word STRING
) WITH ('connector' = 'datagen','fields.word.length' = '1'
);-- paimon requires checkpoint interval in streaming mode
SET 'execution.checkpointing.interval' = '10 s';-- write streaming data to dynamic table
INSERT INTO word_count SELECT word, COUNT(*) FROM word_table GROUP BY word;步骤7:OLAP查询
-- use tableau result mode
SET 'sql-client.execution.result-mode' = 'tableau';-- switch to batch mode
RESET 'execution.checkpointing.interval';
SET 'execution.runtime-mode' = 'batch';-- olap query the table
SELECT * FROM word_count;你可以多次执行查询并观察结果的变化。
步骤8:流查询
-- switch to streaming mode
SET 'execution.runtime-mode' = 'streaming';-- track the changes of table and calculate the count interval statistics
SELECT `interval`, COUNT(*) AS interval_cnt FROM(SELECT cnt / 10000 AS `interval` FROM word_count) GROUP BY `interval`;步骤9:退出 在localhost:8081取消流作业,然后执行以下SQL脚本退出Flink SQL客户端:
-- uncomment the following line if you want to drop the dynamic table and clear the files
-- DROP TABLE word_count;-- exit sql-client
EXIT;停止Flink本地集群:
./bin/stop-cluster.sh
使用Flink管理内存
Paimon任务可以基于执行器内存创建内存池,该内存池将由Flink执行器管理,例如Flink任务管理器中的管理内存。通过执行器为多个任务管理写入器缓冲区,这将提高接收器的稳定性和性能。
如果使用Flink管理内存,可以设置以下属性:
| 选项 | 默认值 | 描述 |
|---|---|---|
| sink.use-managed-memory-allocator | false | 如果为true,Flink接收器将为合并树使用管理内存;否则,它将创建一个独立的内存分配器,这意味着每个任务分配并管理自己的内存池(堆内存)。如果一个执行器中有太多任务,可能会导致性能问题甚至内存溢出(OOM)。 |
| sink.managed.writer-buffer-memory | 256M | 管理内存中写入器缓冲区的权重,Flink将根据该权重计算写入器的内存大小,实际使用的内存取决于运行环境。目前,此属性中定义的内存大小等于运行时分配给写入缓冲区的实际内存。 |
在SQL中使用时,用户可以在SQL中为Flink管理内存设置内存权重,然后Flink接收器操作符将获取内存池大小并为Paimon写入器创建分配器:
INSERT INTO paimon_table /*+ OPTIONS('sink.use-managed-memory-allocator'='true', 'sink.managed.writer-buffer-memory'='256M') */
SELECT * FROM ....;设置动态选项
与Paimon表交互时,可以在不更改目录选项的情况下调整表选项。Paimon将提取作业级动态选项,并在当前会话中生效。动态选项的键格式为paimon.${catalogName}.${dbName}.${tableName}.${config_key} 。catalogName/dbName/tableName可以是*,表示匹配所有特定部分。
例如:
-- set scan.timestamp-millis=1697018249000 for the table mycatalog.default.T
SET 'paimon.mycatalog.default.T.scan.timestamp-millis' = '1697018249000';
SELECT * FROM T;-- set scan.timestamp-millis=1697018249000 for the table default.T in any catalog
SET 'paimon.*.default.T.scan.timestamp-millis' = '1697018249000';
SELECT * FROM T;拓展:
分桶追加表:在大数据存储和处理中,分桶追加表通过定义桶和桶键,将数据按照一定规则分布到不同桶中。这种方式不仅可以在流处理中保证同一桶内数据的顺序,便于按序处理数据,还能在批处理查询时优化性能,如避免数据混洗,提高查询效率。例如,在电商数据分析中,按商品ID分桶存储订单数据,在分析特定商品的销售趋势时,同一桶内的数据按时间顺序排列,方便快速获取相关信息。
桶内压缩策略:桶内压缩策略通过控制文件数量来优化存储和查询性能。
write-only选项用于跳过压缩和快照过期,适用于与专用压缩作业配合使用的场景。compaction.min.file-num和compaction.max.file-num分别从最小和最大文件数的角度触发压缩,平衡了压缩成本和性能。full-compaction.delta-commits则控制完全压缩的触发频率。在实际应用中,合理调整这些参数能有效管理存储资源,提高系统整体性能。流读取顺序:明确的流读取顺序保证了数据在不同分区和桶之间的处理顺序,有助于确保数据处理结果的一致性。例如,在实时数据分析任务中,按顺序处理数据对于正确计算指标和分析趋势至关重要。不同的顺序规则(如按分区值、创建时间或写入顺序)适用于不同的业务场景,用户可以根据实际需求进行配置。
水印定义与应用:水印在流处理中用于处理乱序数据和定义窗口操作。通过为Paimon表定义水印,结合Flink水印对齐功能,可以更好地控制数据处理的进度和准确性。有界流模式下,水印还可以作为流读取的结束条件,确保在处理完特定范围的数据后停止读取。例如,在实时监控系统中,通过水印机制可以准确计算一段时间内的事件统计信息,同时避免因乱序数据导致的计算错误。
批处理中的分桶优化:在Spark SQL中,为V2数据源启用分桶功能后,当两个表具有相同的分桶策略和桶数时,在连接操作中可以避免数据混洗。数据混洗通常是一个代价高昂的操作,涉及数据的重新分区和传输,而分桶优化可以显著减少这种开销,提高批处理查询的性能。例如,在大规模数据的关联分析中,通过合理的分桶策略,可以将需要连接的数据预先分布在相同的桶中,直接进行连接操作,节省大量时间和资源。
SQL数据定义语言(SQL DDL)
创建目录(Create Catalog)
Paimon目录目前支持三种类型的元存储:
-
文件系统元存储(默认),它在文件系统中同时存储元数据和表文件。
-
Hive元存储,它额外将元数据存储在Hive元存储中。用户可以直接从Hive访问这些表。
-
JDBC元存储,它额外将元数据存储在关系型数据库中,如MySQL、Postgres等。 创建目录时的详细选项请参考CatalogOptions。
创建文件系统目录(Create Filesystem Catalog)
以下Flink SQL注册并使用一个名为my_catalog的Paimon目录。元数据和表文件存储在hdfs:///path/to/warehouse下。
CREATE CATALOG my_catalog WITH ('type' = 'paimon','warehouse' = 'hdfs:///path/to/warehouse'
);USE CATALOG my_catalog;你可以使用前缀table-default.为在该目录中创建的表定义任何默认表选项。
创建Hive目录(Creating Hive Catalog)
通过使用Paimon Hive目录,对该目录的更改将直接影响相应的Hive元存储。在此目录中创建的表也可以直接从Hive访问。
要使用Hive目录,数据库名、表名和字段名应为小写。
Flink中的Paimon Hive目录依赖于Flink Hive连接器捆绑JAR包。你应首先下载Hive连接器捆绑JAR包并将其添加到类路径中。
| 元存储版本 | 捆绑包名称 | SQL客户端JAR包 |
|---|---|---|
| 2.3.0 - 3.1.3 | Flink Bundle | Download |
| 1.2.0 - x.x.x | Presto Bundle | Download |
以下Flink SQL注册并使用一个名为my_hive的Paimon Hive目录。元数据和表文件存储在hdfs:///path/to/warehouse下。此外,元数据也存储在Hive元存储中。
如果你的Hive需要安全认证,如Kerberos、LDAP、Ranger,或者你希望Paimon表由Apache Atlas管理(在hive-site.xml中设置‘hive.metastore.event.listeners’)。你可以将hive-conf-dir和hadoop-conf-dir参数指定为hive-site.xml文件路径。
CREATE CATALOG my_hive WITH ('type' = 'paimon','metastore' = 'hive',-- 'uri' = 'thrift://<hive-metastore-host-name>:<port>', default use 'hive.metastore.uris' in HiveConf-- 'hive-conf-dir' = '...', this is recommended in the kerberos environment-- 'hadoop-conf-dir' = '...', this is recommended in the kerberos environment-- 'warehouse' = 'hdfs:///path/to/warehouse', default use 'hive.metastore.warehouse.dir' in HiveConf
);USE CATALOG my_hive;你可以使用前缀table-default.为在该目录中创建的表定义任何默认表选项。
此外,你可以创建FlinkGenericCatalog。
当使用Hive目录通过alter table更改不兼容的列类型时,你需要配置hive.metastore.disallow.incompatible.col.type.changes=false。详见HIVE-17832。
如果你正在使用Hive3,请禁用Hive ACID:
hive.strict.managed.tables=false
hive.create.as.insert.only=false
metastore.create.as.acid=false将分区同步到Hive元存储(Synchronizing Partitions into Hive Metastore)
默认情况下,Paimon不会将新创建的分区同步到Hive元存储。用户在Hive中看到的将是一个未分区的表。分区下推将通过过滤器下推来实现。
如果你希望在Hive中看到一个分区表,并且也将新创建的分区同步到Hive元存储,请将表属性metastore.partitioned-table设置为true。另见CoreOptions。
向Hive表添加参数(Adding Parameters to a Hive Table)
使用表选项有助于方便地定义Hive表参数。以hive.为前缀的参数将自动在Hive表的TBLPROPERTIES中定义。例如,使用选项hive.table.owner = Jon将在创建过程中自动向表属性中添加参数table.owner = Jon。
在属性中设置位置(Setting Location in Properties)
如果你正在使用对象存储,并且不希望Paimon表/数据库的位置通过Hive的文件系统访问,这可能会导致诸如 “No FileSystem for scheme: s3a” 之类的错误。你可以通过location-in-properties配置在表/数据库的属性中设置位置。详见在属性中设置表/数据库的位置。
创建JDBC目录(Creating JDBC Catalog)
通过使用Paimon JDBC目录,对该目录的更改将直接存储在关系型数据库中,如SQLite、MySQL、postgres等。
目前,锁配置仅支持MySQL和SQLite。如果你使用不同类型的数据库进行目录存储,请不要配置lock.enabled。
Flink中的Paimon JDBC目录需要正确添加连接数据库的相应JAR包。你应首先下载JDBC连接器捆绑JAR包并将其添加到类路径中,例如MySQL、postgres。
| 数据库类型 | 捆绑包名称 | SQL客户端JAR包 |
|---|---|---|
| mysql | mysql-connector-java | Download |
| postgres | postgresql | Download |
CREATE CATALOG my_jdbc WITH ('type' = 'paimon','metastore' = 'jdbc','uri' = 'jdbc:mysql://<host>:<port>/<databaseName>','jdbc.user' = '...', 'jdbc.password' = '...', 'catalog-key'='jdbc','warehouse' = 'hdfs:///path/to/warehouse'
);USE CATALOG my_jdbc;你可以通过“jdbc.”配置任何已由JDBC声明的连接参数,不同数据库之间的连接参数可能不同,请根据实际情况进行配置。
你还可以通过指定“catalog-key”对多个目录下的数据库进行逻辑隔离。
此外,在创建JdbcCatalog时,你可以通过配置“lock-key-max-length”指定锁键的最大长度,默认值为255。由于此值是{catalog-key}.{database-name}.{table-name}的组合,请相应调整。
你可以使用前缀table-default.为在该目录中创建的表定义任何默认表选项。
创建表(Create Table)
使用Paimon目录后,你可以创建和删除表。在Paimon目录中创建的表由该目录管理。当从目录中删除表时,其表文件也将被删除。
以下SQL假设你已注册并正在使用Paimon目录。它在目录的默认数据库中创建一个名为my_table的管理表,该表有五列,其中dt、hh和user_id是主键。
CREATE TABLE my_table (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
);你可以创建分区表:
CREATE TABLE my_table (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) PARTITIONED BY (dt, hh);如果你需要跨分区插入更新(主键不包含所有分区字段),请参见跨分区插入更新模式。
通过配置partition.expiration-time,可以自动删除过期分区。
指定统计模式(Specify Statistics Mode)
Paimon将自动收集数据文件的统计信息以加速查询过程。支持四种模式:
-
full:收集完整的指标:null_count(空值计数)、min(最小值)、max(最大值)。
-
truncate(length):length可以是任意正整数,默认模式是truncate(16),这意味着收集空值计数、截断长度为16的最小/最大值。这主要是为了避免过大的列,以免增大清单文件。
-
counts:仅收集空值计数。
-
none:禁用元数据统计信息收集。 统计信息收集器模式可以通过'metadata.stats-mode'配置,默认是'truncate(16)'。你可以通过设置'fields.{field_name}.stats-mode'来配置字段级别。
字段默认值(Field Default Value)
Paimon表目前支持通过'fields.item_id.default-value'在表属性中为字段设置默认值,请注意,分区字段和主键字段不能指定默认值。
Create Table As Select
可以根据查询结果创建并填充表,例如,我们有这样一个SQL:CREATE TABLE table_b AS SELECT id, name FORM table_a,结果表table_b将等同于使用以下语句创建表并插入数据:CREATE TABLE table_b (id INT, name STRING); INSERT INTO table_b SELECT id, name FROM table_a;
当使用CREATE TABLE AS SELECT时,我们可以指定主键或分区,语法请参考以下SQL。
/* For streaming mode, you need to enable the checkpoint. */CREATE TABLE my_table (user_id BIGINT,item_id BIGINT
);
CREATE TABLE my_table_as AS SELECT * FROM my_table;/* partitioned table */
CREATE TABLE my_table_partition (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING
) PARTITIONED BY (dt, hh);
CREATE TABLE my_table_partition_as WITH ('partition' = 'dt') AS SELECT * FROM my_table_partition;/* change options */
CREATE TABLE my_table_options (user_id BIGINT,item_id BIGINT
) WITH ('file.format' = 'orc');
CREATE TABLE my_table_options_as WITH ('file.format' = 'parquet') AS SELECT * FROM my_table_options;/* primary key */
CREATE TABLE my_table_pk (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
);
CREATE TABLE my_table_pk_as WITH ('primary-key' = 'dt,hh') AS SELECT * FROM my_table_pk;/* primary key + partition */
CREATE TABLE my_table_all (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) PARTITIONED BY (dt, hh);
CREATE TABLE my_table_all_as WITH ('primary-key' = 'dt,hh', 'partition' = 'dt') AS SELECT * FROM my_table_all;Create Table Like
要创建一个与另一个表具有相同模式、分区和表属性的表,可以使用CREATE TABLE LIKE。
CREATE TABLE my_table (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
);CREATE TABLE my_table_like LIKE my_table (EXCLUDING OPTIONS);Work with Flink Temporary Tables
Flink临时表仅在当前Flink SQL会话中记录而不受其管理。如果删除临时表,其资源不会被删除。Flink SQL会话关闭时,临时表也会被删除。
如果你想在使用Paimon目录的同时使用其他表,但又不想将它们存储在其他目录中,可以创建一个临时表。以下Flink SQL创建一个Paimon目录和一个临时表,并展示了如何同时使用这两个表。
CREATE CATALOG my_catalog WITH ('type' = 'paimon','warehouse' = 'hdfs:///path/to/warehouse'
);USE CATALOG my_catalog;-- Assume that there is already a table named my_table in my_catalogCREATE TEMPORARY TABLE temp_table (k INT,v STRING
) WITH ('connector' = 'filesystem','path' = 'hdfs:///path/to/temp_table.csv','format' = 'csv'
);SELECT my_table.k, my_table.v, temp_table.v FROM my_table JOIN temp_table ON my_table.k = temp_table.k;拓展:
Paimon目录类型:Paimon提供多种目录类型,每种都有其特点和适用场景。文件系统元存储简单直接,适用于基础的文件系统存储场景;Hive元存储方便与Hive集成,便于在Hive生态中共享数据;JDBC元存储则将元数据存储在关系型数据库,可利用数据库的一些特性,如事务支持等。不同类型目录的选择取决于项目的数据管理需求和现有技术栈。
Hive目录细节:使用Hive目录时,与Hive的集成需要注意诸多细节。例如,名称大小写规范、依赖的JAR包下载及添加、安全认证配置等。同时,在处理Hive相关配置时,如更改列类型的配置以及禁用Hive ACID的设置,都是为了确保Paimon与Hive之间的兼容性和数据处理的正确性。
JDBC目录配置:JDBC目录的配置涉及数据库连接相关的众多参数,如数据库URI、用户名、密码等,不同数据库类型还需下载相应的JDBC连接器捆绑JAR包。锁配置的支持情况以及锁键最大长度的设置,为数据的并发访问和管理提供了控制手段。通过“catalog-key”进行逻辑隔离,则增加了多目录多数据库管理的灵活性。
表的创建与操作:Paimon表的创建方式多样,包括基本创建、按查询结果创建、像其他表一样创建等。每种方式都提供了丰富的可配置选项,如主键、分区、统计模式、字段默认值等。这些选项的设置不仅影响表的结构,还对数据存储、查询性能等方面产生重要作用。例如,合理选择统计模式可以在保证查询性能的同时,控制元数据的存储开销。
临时表的使用:Flink临时表为用户在特定SQL会话中提供了一种临时存储和处理数据的方式,它与Paimon目录结合使用,使得用户可以在不改变Paimon目录结构的前提下,灵活地与其他外部数据源进行联合查询,增强了数据处理的灵活性和便捷性。
SQL写入(SQL Write)
语法(Syntax)
INSERT { INTO | OVERWRITE } table_identifier [ part_spec ] [ column_list ] { value_expr | query };
更多信息,请查看语法文档:Flink INSERT语句
INSERT INTO
使用INSERT INTO将记录和更改应用到表中。
INSERT INTO my_table SELECT ...
INSERT INTO同时支持批处理模式和流处理模式。在流处理模式下,默认情况下,它还会在Flink Sink中执行压缩、快照过期,甚至分区过期操作(如果已配置)。
对于多个作业写入同一个表的情况,你可以参考专用压缩作业获取更多信息。
聚类(Clustering)
在Paimon中,聚类是一项功能,它允许你在写入过程中根据某些列的值对追加表中的数据进行聚类。这种数据组织方式可以显著提高下游任务读取数据时的效率,因为它能够实现更快且更有针对性的数据检索。此功能仅支持追加表(bucket = -1)和批处理执行模式。
要使用聚类功能,你可以在创建表或写入表时指定要聚类的列。以下是启用聚类的简单示例:
CREATE TABLE my_table (a STRING,b STRING,c STRING,
) WITH ('sink.clustering.by-columns' = 'a,b',
);你也可以使用SQL提示动态设置聚类选项:
INSERT INTO my_table /*+ OPTIONS('sink.clustering.by-columns' = 'a,b') */
SELECT * FROM source;数据使用自动选择的策略(如ORDER、ZORDER或HILBERT)进行聚类,但你可以通过设置sink.clustering.strategy手动指定聚类策略。聚类依赖于采样和排序。如果聚类过程耗时过长,你可以通过设置sink.clustering.sample-factor减少总采样数,或者通过设置sink.clustering.sort-in-cluster为false禁用排序步骤。
有关上述配置的更多信息,你可以参考FlinkConnectorOptions。
覆盖整个表(Overwriting the Whole Table)
对于未分区表,Paimon支持覆盖整个表。(或者对于禁用了dynamic-partition-overwrite选项的分区表)。
使用INSERT OVERWRITE覆盖整个未分区表。
INSERT OVERWRITE my_table SELECT ...
覆盖一个分区(Overwriting a Partition)
对于分区表,Paimon支持覆盖一个分区。
使用INSERT OVERWRITE覆盖一个分区。
INSERT OVERWRITE my_table PARTITION (key1 = value1, key2 = value2, ...) SELECT ...
动态覆盖(Dynamic Overwrite)
Flink的默认覆盖模式是动态分区覆盖(这意味着Paimon仅删除被覆盖数据中出现的分区)。你可以配置dynamic-partition-overwrite将其更改为静态覆盖。
-- MyTable is a Partitioned Table-- Dynamic overwrite
INSERT OVERWRITE my_table SELECT ...-- Static overwrite (Overwrite whole table)
INSERT OVERWRITE my_table /*+ OPTIONS('dynamic-partition-overwrite' = 'false') */ SELECT ...截断表(Truncate tables)
-
Flink 1.17及以下: 你可以使用
INSERT OVERWRITE通过插入空值来清空表数据。
INSERT OVERWRITE my_table /*+ OPTIONS('dynamic-partition-overwrite'='false') */ SELECT * FROM my_table WHERE false;
-
Flink 1.18及以上:
TRUNCATE TABLE my_table;
清除分区(Purging Partitions)
目前,Paimon支持两种清除分区的方法。
- 与清除表类似,你可以使用
INSERT OVERWRITE通过向分区插入空值来清除分区数据。 - 方法1不支持删除多个分区。如果你需要删除多个分区,可以通过
flink run提交drop_partition作业。
-- Syntax
INSERT OVERWRITE my_table /*+ OPTIONS('dynamic-partition-overwrite'='false') */
PARTITION (key1 = value1, key2 = value2, ...) SELECT selectSpec FROM my_table WHERE false;-- The following SQL is an example:
-- table definition
CREATE TABLE my_table (k0 INT,k1 INT,v STRING
) PARTITIONED BY (k0, k1);-- you can use
INSERT OVERWRITE my_table /*+ OPTIONS('dynamic-partition-overwrite'='false') */
PARTITION (k0 = 0) SELECT k1, v FROM my_table WHERE false;-- or
INSERT OVERWRITE my_table /*+ OPTIONS('dynamic-partition-overwrite'='false') */
PARTITION (k0 = 0, k1 = 0) SELECT v FROM my_table WHERE false;更新表(Updating tables)
重要的表属性设置:
-
仅主键表支持此功能。
-
MergeEngine需要是deduplicate或partial-update才能支持此功能。 -
不支持更新主键。
目前,Paimon在Flink 1.17及更高版本中支持使用UPDATE更新记录。你可以在Flink的批处理模式下执行UPDATE。
-- Syntax
UPDATE table_identifier SET column1 = value1, column2 = value2, ... WHERE condition;-- The following SQL is an example:
-- table definition
CREATE TABLE my_table (a STRING,b INT,c INT,PRIMARY KEY (a) NOT ENFORCED
) WITH ( 'merge-engine' = 'deduplicate'
);-- you can use
UPDATE my_table SET b = 1, c = 2 WHERE a = 'myTable';从表中删除(Deleting from table)
-
Flink 1.17及以上: 重要的表属性设置:
-
仅主键表支持此功能。
-
如果表有主键,
MergeEngine需要是deduplicate才能支持此功能。 -
不支持在流处理模式下从表中删除数据。
-- Syntax
DELETE FROM table_identifier WHERE conditions;-- The following SQL is an example:
-- table definition
CREATE TABLE my_table (id BIGINT NOT NULL,currency STRING,rate BIGINT,dt String,PRIMARY KEY (id, dt) NOT ENFORCED
) PARTITIONED BY (dt) WITH ( 'merge-engine' = 'deduplicate'
);-- you can use
DELETE FROM my_table WHERE currency = 'UNKNOWN';分区标记完成(Partition Mark Done)
对于分区表,每个分区可能需要被调度以触发下游批处理计算。因此,有必要选择合适的时机表明该分区已准备好调度,并尽量减少调度期间的数据漂移量。我们将这个过程称为:“分区标记完成”。
标记完成的示例:
CREATE TABLE my_partitioned_table (f0 INT,f1 INT,f2 INT,...dt STRING
) PARTITIONED BY (dt) WITH ('partition.timestamp-formatter'='yyyyMMdd','partition.timestamp-pattern'='$dt','partition.time-interval'='1 d','partition.idle-time-to-done'='15 m'
);- 首先,你需要定义分区的时间解析器和分区之间的时间间隔,以便确定何时可以正确标记分区完成。
- 其次,你需要定义空闲时间,它决定了分区在没有新数据的情况下经过多长时间后将被标记为完成。
- 第三,默认情况下,分区标记完成会创建
_SUCCESS文件,_SUCCESS文件的内容是一个JSON,包含creationTime和modificationTime,它们可以帮助你了解是否有延迟数据。你也可以配置其他操作。
拓展:
SQL写入操作:在数据处理中,SQL写入操作是将数据持久化到表中的关键步骤。Paimon提供了丰富的写入方式,如
INSERT INTO用于常规写入,INSERT OVERWRITE用于覆盖写入,这些操作在批处理和流处理模式下的行为和适用场景不同,用户可根据需求灵活选择。聚类功能:聚类是Paimon针对追加表在批处理模式下的优化功能。通过对特定列进行聚类,数据在存储时会按照指定策略组织,这在大数据场景下能显著提升查询性能,减少数据检索时间。例如在一个包含大量用户行为数据的追加表中,按照用户ID和时间列进行聚类,可以快速定位和分析特定用户在某个时间段内的行为。
覆盖与清除操作:覆盖整个表、分区以及动态/静态覆盖模式,为数据更新和管理提供了多种选择。而截断表和清除分区功能则用于删除数据,不同版本的Flink在实现方式上略有差异,用户需根据实际情况选择合适的方法。这些操作对于数据的清理和维护十分重要,比如在数据过期或错误数据处理场景中。
更新与删除操作:更新和删除操作针对主键表,且对
MergeEngine有特定要求。这确保了数据的一致性和完整性,因为主键表中的数据更新和删除需要更严格的控制。例如在用户信息表中,当用户信息发生变化时,可以使用更新操作修改相应记录;当用户注销时,可以使用删除操作移除相关记录。分区标记完成:在分区表的场景下,分区标记完成机制用于协调下游批处理计算的调度。通过合理设置时间解析器、时间间隔和空闲时间等参数,可以确保分区在合适的时机被标记为完成,减少数据漂移,保证批处理计算的准确性和高效性。比如在按天分区的销售数据分区表中,通过设置这些参数,可以确保每天的数据在处理完成且无延迟数据后,被正确标记为完成,以便下游进行准确的统计分析。
SQL查询(SQL Query)
与所有其他表一样,Paimon表可以使用SELECT语句进行查询。
批处理查询(Batch Query)
Paimon的批处理读取会返回表某个快照中的所有数据。默认情况下,批处理读取返回最新的快照。
-- Flink SQL
SET 'execution.runtime-mode' = 'batch';批处理时间旅行(Batch Time Travel)
Paimon的批处理时间旅行读取可以指定一个快照或标签,并读取相应的数据。
- Flink(动态选项):
-- read the snapshot with id 1L
SELECT * FROM t /*+ OPTIONS('scan.snapshot-id' = '1') */;-- read the snapshot from specified timestamp in unix milliseconds
SELECT * FROM t /*+ OPTIONS('scan.timestamp-millis' = '1678883047356') */;-- read the snapshot from specified timestamp string ,it will be automatically converted to timestamp in unix milliseconds
-- Supported formats include:yyyy-MM-dd, yyyy-MM-dd HH:mm:ss, yyyy-MM-dd HH:mm:ss.SSS, use default local time zone
SELECT * FROM t /*+ OPTIONS('scan.timestamp' = '2023-12-09 23:09:12') */;-- read tag 'my-tag'
SELECT * FROM t /*+ OPTIONS('scan.tag-name' = 'my-tag') */;-- read the snapshot from watermark, will match the first snapshot after the watermark
SELECT * FROM t /*+ OPTIONS('scan.watermark' = '1678883047356') */; - Flink 1.18及以上:
-- read the snapshot from specified timestamp
SELECT * FROM t FOR SYSTEM_TIME AS OF TIMESTAMP '2023-01-01 00:00:00';-- you can also use some simple expressions (see flink document to get supported functions)
SELECT * FROM t FOR SYSTEM_TIME AS OF TIMESTAMP '2023-01-01 00:00:00' + INTERVAL '1' DAY批处理增量读取(Batch Incremental)
读取起始快照(不包含)和结束快照之间的增量更改。
例如:
‘5,10’表示快照5和快照10之间的更改。‘TAG1,TAG3’表示TAG1和TAG3之间的更改。
-- incremental between snapshot ids
SELECT * FROM t /*+ OPTIONS('incremental-between' = '12,20') */;-- incremental between snapshot time mills
SELECT * FROM t /*+ OPTIONS('incremental-between-timestamp' = '1692169000000,1692169900000') */;默认情况下,对于生成变更日志文件的表,将扫描变更日志文件。否则,扫描新更改的文件。你也可以强制指定'incremental-between-scan-mode'。
在批处理SQL中,不允许返回DELETE记录,因此带有 -D的记录将被丢弃。如果你想查看DELETE记录,可以使用audit_log表:
SELECT * FROM t$audit_log /*+ OPTIONS('incremental-between' = '12,20') */;
流处理查询(Streaming Query)
默认情况下,流处理读取在首次启动时生成表上的最新快照,然后继续读取最新的更改。
Paimon默认确保你的启动过程能够正确处理所有数据。
流处理模式下的Paimon源是无界的,就像一个永远不会结束的队列。
-- Flink SQL
SET 'execution.runtime-mode' = 'streaming';你也可以不读取快照数据进行流处理读取,你可以使用最新扫描模式:
-- Continuously reads latest changes without producing a snapshot at the beginning.
SELECT * FROM t /*+ OPTIONS('scan.mode' = 'latest') */;流处理时间旅行(Streaming Time Travel)
如果你只想处理从今天开始及以后的数据,你可以使用分区过滤器来实现:
SELECT * FROM t WHERE dt > '2023-06-26';
如果它不是一个分区表,或者你不能通过分区进行过滤,你可以使用时间旅行的流读取。
- Flink(动态选项):
-- read changes from snapshot id 1L
SELECT * FROM t /*+ OPTIONS('scan.snapshot-id' = '1') */;-- read changes from snapshot specified timestamp
SELECT * FROM t /*+ OPTIONS('scan.timestamp-millis' = '1678883047356') */;-- read snapshot id 1L upon first startup, and continue to read the changes
SELECT * FROM t /*+ OPTIONS('scan.mode'='from-snapshot-full','scan.snapshot-id' = '1') */;-
Flink 1.18及以上:
-- read the snapshot from specified timestamp
SELECT * FROM t FOR SYSTEM_TIME AS OF TIMESTAMP '2023-01-01 00:00:00';-- you can also use some simple expressions (see flink document to get supported functions)
SELECT * FROM t FOR SYSTEM_TIME AS OF TIMESTAMP '2023-01-01 00:00:00' + INTERVAL '1' DAY时间旅行的流读取依赖于快照,但默认情况下,快照仅保留1小时内的数据,这可能会阻止你读取更旧的增量数据。因此,Paimon还为流读取提供了另一种模式scan.file-creation-time-millis,它提供一种粗略的过滤方式,保留在timeMillis之后生成的文件。
SELECT * FROM t /*+ OPTIONS('scan.file-creation-time-millis' = '1678883047356') */;
消费者ID(Consumer ID)
你可以在对流读取表时指定consumer-id:
SELECT * FROM t /*+ OPTIONS('consumer-id' = 'myid', 'consumer.expiration-time' = '1 d', 'consumer.mode' = 'at-least-once') */;
对流读取Paimon表时,下一个快照ID会记录到文件系统中。这有几个优点:
- 当先前的作业停止时,新启动的作业可以从先前的进度继续消费,而无需从状态恢复。新的读取将从消费者文件中找到的下一个快照ID开始读取。如果你不想要这种行为,可以将
'consumer.ignore-progress'设置为true。 - 在决定某个快照是否过期时,Paimon会查看文件系统中该表的所有消费者,如果有消费者仍然依赖这个快照,那么这个快照将不会因过期而被删除。
注意1:消费者会阻止快照过期。你可以指定'consumer.expiration-time'来管理消费者的生命周期。
注意2:如果你不想影响检查点时间,你需要配置'consumer.mode' = 'at-least-once'。这种模式允许读取器以不同的速率消费快照,并将所有读取器中最慢的快照ID记录到消费者中。这种模式可以提供更多功能,如水印对齐。
注意3:关于'consumer.mode',由于exactly-once模式和at-least-once模式的实现完全不同,Flink的状态是不兼容的,并且在切换模式时无法从状态恢复。
你可以使用给定的消费者ID和下一个快照ID重置一个消费者,并使用给定的消费者ID删除一个消费者。首先,你需要停止使用这个消费者ID的流处理任务,然后执行重置消费者动作作业。
运行以下命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \reset-consumer \--warehouse <warehouse-path> \--database <database-name> \ --table <table-name> \--consumer_id <consumer-id> \[--next_snapshot <next-snapshot-id>] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]]如果你想删除消费者,请不要指定 -next_snapshot参数。
读取覆盖(Read Overwrite)
默认情况下,流处理读取将忽略由INSERT OVERWRITE生成的提交。如果你想读取OVERWRITE的提交,可以配置streaming-read-overwrite。
读取并行度(Read Parallelism)
默认情况下,批处理读取的并行度与分片数相同,而流处理读取的并行度与桶数相同,但不大于scan.infer-parallelism.max。
禁用scan.infer-parallelism后,将使用全局并行度进行读取。
你也可以通过scan.parallelism手动指定并行度。
| 键 | 默认值 | 类型 | 描述 |
|---|---|---|---|
| scan.infer-parallelism | true | 布尔值 | 如果为false,源的并行度由全局并行度设置。否则,源并行度从分片数(批处理模式)或桶数(流处理模式)推断得出。 |
| scan.infer-parallelism.max | 1024 | 整数 | 如果 |
| scan.parallelism | (none) | 整数 | 为扫描源定义自定义并行度。默认情况下,如果未定义此选项,规划器将通过考虑全局配置为每个语句单独推导并行度。如果用户启用 |
查询优化(Query Optimization)
强烈建议在查询时指定分区和主键过滤器,这将加速查询的数据跳过。
能够加速数据跳过的过滤函数有:
-
= -
< -
<= -
> -
>= -
IN (...) -
LIKE 'abc%' -
IS NULL
Paimon将按主键对数据进行排序,这会加速点查询和范围查询。当使用复合主键时,最好让查询过滤器形成主键的最左前缀,以实现良好的加速效果。
假设一个表有以下定义:
CREATE TABLE orders (catalog_id BIGINT,order_id BIGINT,.....,PRIMARY KEY (catalog_id, order_id) NOT ENFORCED -- composite primary key
);通过为主键的最左前缀指定范围过滤器,查询可以获得良好的加速效果。
SELECT * FROM orders WHERE catalog_id=1025;SELECT * FROM orders WHERE catalog_id=1025 AND order_id=29495;SELECT * FROM ordersWHERE catalog_id=1025AND order_id>2035 AND order_id<6000;然而,以下过滤器不能很好地加速查询。
SELECT * FROM orders WHERE order_id=29495;SELECT * FROM orders WHERE catalog_id=1025 OR order_id=29495;拓展:
Paimon的SQL查询功能:Paimon在SQL查询方面提供了丰富的特性,涵盖批处理和流处理两种模式。批处理查询能获取表快照的全部数据,并通过时间旅行功能指定特定快照或标签进行查询,还能实现增量读取,这对于分析数据变化和版本回溯非常有用。流处理查询则可以实时获取最新数据,通过不同的扫描模式和时间旅行选项,满足对实时数据处理的多样化需求。
消费者ID机制:消费者ID机制为流处理读取提供了断点续传和快照管理的功能。它允许作业在停止后从上次的进度继续读取,同时通过消费者对快照的依赖关系来控制快照的过期,有效避免了数据丢失。不同的消费者模式(如
at-least-once和exactly-once)在实现和功能上有所差异,用户需根据实际需求选择合适的模式。读取覆盖与并行度:读取覆盖配置决定了流处理读取是否包含
INSERT OVERWRITE的提交,这在数据一致性要求较高的场景中很关键。而读取并行度的设置则直接影响查询性能,通过不同的参数配置,用户可以根据系统资源和数据规模灵活调整批处理和流处理读取的并行度,以达到最优的查询效率。查询优化策略:通过合理使用分区和主键过滤器,利用Paimon按主键排序的特性,可以显著提升查询性能。特别是在处理复合主键时,遵循最左前缀原则能更有效地加速查询。了解哪些过滤函数能实现数据跳过,有助于用户编写高效的查询语句,减少数据扫描范围,提高大数据量下的查询响应速度。
SQL查找连接(SQL Lookup Joins)
查找连接是流查询中的一种连接类型。它用于使用从Paimon查询到的数据丰富一个表。这种连接要求一个表具有处理时间属性,另一个表由查找源连接器支持。
Paimon在Flink中支持对主键表和追加表进行查找连接。以下示例说明了此功能。
准备(Prepare)
首先,我们创建一个Paimon表并实时更新它。
-- Create a paimon catalog
CREATE CATALOG my_catalog WITH ('type'='paimon','warehouse'='hdfs://nn:8020/warehouse/path' -- or 'file://tmp/foo/bar'
);USE CATALOG my_catalog;-- Create a table in paimon catalog
CREATE TABLE customers (id INT PRIMARY KEY NOT ENFORCED,name STRING,country STRING,zip STRING
);-- Launch a streaming job to update customers table
INSERT INTO customers ...-- Create a temporary left table, like from kafka
CREATE TEMPORARY TABLE orders (order_id INT,total INT,customer_id INT,proc_time AS PROCTIME()
) WITH ('connector' = 'kafka','topic' = '...','properties.bootstrap.servers' = '...','format' = 'csv'...
);普通查找(Normal Lookup)
现在你可以在查找连接查询中使用customers表。
-- enrich each order with customer information
SELECT o.order_id, o.total, c.country, c.zip
FROM orders AS o
JOIN customers
FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id;重试查找(Retry Lookup)
如果由于customers(查找表)的相应数据尚未准备好,导致orders(主表)的记录连接失败。你可以考虑使用Flink的查找延迟重试策略。仅适用于Flink 1.16及以上版本。
-- enrich each order with customer information
SELECT /*+ LOOKUP('table'='c', 'retry-predicate'='lookup_miss', 'retry-strategy'='fixed_delay', 'fixed-delay'='1s', 'max-attempts'='600') */
o.order_id, o.total, c.country, c.zip
FROM orders AS o
JOIN customers
FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id;异步重试查找(Async Retry Lookup)
同步重试的问题在于一条记录会阻塞后续记录,导致整个作业被阻塞。你可以考虑使用异步 + allow_unordered来避免阻塞,连接失败的记录将不再阻塞其他记录。
-- enrich each order with customer information
SELECT /*+ LOOKUP('table'='c', 'retry-predicate'='lookup_miss', 'output-mode'='allow_unordered', 'retry-strategy'='fixed_delay', 'fixed-delay'='1s', 'max-attempts'='600') */
o.order_id, o.total, c.country, c.zip
FROM orders AS o
JOIN customers /*+ OPTIONS('lookup.async'='true', 'lookup.async-thread-number'='16') */
FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id;如果主表(orders)是CDC流,Flink SQL将忽略allow_unordered(仅支持追加流),你的流作业可能会被阻塞。你可以尝试使用Paimon的audit_log系统表功能来解决(将CDC流转换为追加流)。
动态分区(Dynamic Partition)
在传统数据仓库中,每个分区通常维护最新的完整数据,因此这个分区表只需要连接最新的分区。Paimon针对这种场景专门开发了max_pt特性。
-
创建Paimon分区表:
CREATE TABLE customers (id INT,name STRING,country STRING,zip STRING,dt STRING,PRIMARY KEY (id, dt) NOT ENFORCED
) PARTITIONED BY (dt);-
查找连接:
SELECT o.order_id, o.total, c.country, c.zip
FROM orders AS o
JOIN customers /*+ OPTIONS('lookup.dynamic-partition'='max_pt()', 'lookup.dynamic-partition.refresh-interval'='1 h') */
FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id;查找节点将自动刷新最新的分区并查询最新分区的数据。
查询服务(Query Service)
你可以运行一个Flink流作业来启动表的查询服务。当查询服务存在时,Flink查找连接将优先从它获取数据,这将有效地提高查询性能。
Flink SQL
CALL sys.query_service('database_name.table_name', parallelism);
Flink Action
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \query_service \--warehouse <warehouse-path> \--database <database-name> \--table <table-name> \[--parallelism <parallelism>] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]]拓展:
查找连接在流处理中的应用:查找连接在流处理场景中非常实用,它允许在实时流数据处理过程中,通过从另一个表(如Paimon表)中查询相关数据来丰富主表数据。例如,在一个电商订单处理系统中,订单流数据(orders表)可以通过查找连接从客户信息表(customers表)中获取客户的详细信息,从而实现对订单数据的补充和增强,为后续的分析和处理提供更完整的数据。
不同查找连接策略:普通查找连接按照常规方式使用处理时间属性进行连接操作。重试查找策略则针对查找表数据可能延迟到达的情况,通过设置重试条件(如
retry-predicate)、重试策略(如retry-strategy)、重试延迟(如fixed-delay)和最大重试次数(如max-attempts)等参数,确保在数据准备好后能够成功连接。异步重试查找进一步优化了同步重试可能导致的阻塞问题,通过异步处理和allow_unordered设置,避免了单个连接失败记录对整个作业的阻塞,提高了流处理的效率和响应性。动态分区的优化:在处理分区表时,动态分区的
max_pt特性能够自动识别并连接最新分区,这对于需要获取最新数据的场景非常有用。例如,在每日更新的销售数据分区表中,通过动态分区查找连接,可以确保每次查询都能获取到最新一天的销售数据,无需手动指定分区,简化了查询逻辑并提高了数据的实时性。查询服务的作用:启动查询服务为Flink查找连接提供了一种优化机制。通过优先从查询服务获取数据,可以减少查询延迟,提高查询性能。特别是在大规模数据和高并发查询的场景下,查询服务可以缓存和预处理数据,使得查找连接能够更快速地获取所需信息,从而提升整个流处理系统的效率和响应能力。
SQL修改表结构(Altering Tables)
修改/添加表属性(Changing/Adding Table Properties)
以下SQL将write-buffer-size表属性设置为256MB。
ALTER TABLE my_table SET ('write-buffer-size' = '256 MB'
);删除表属性(Removing Table Properties)
以下SQL删除write-buffer-size表属性。
ALTER TABLE my_table RESET ('write-buffer-size');
修改/添加表注释(Changing/Adding Table Comment)
以下SQL将表my_table的注释修改为“table comment”。
ALTER TABLE my_table SET ('comment' = 'table comment');删除表注释(Removing Table Comment)
以下SQL删除表注释。
ALTER TABLE my_table RESET ('comment');
重命名表名(Rename Table Name)
以下SQL将表名重命名为my_table_new。
ALTER TABLE my_table RENAME TO my_table_new;
如果你使用对象存储,如S3或OSS,请谨慎使用此语法,因为对象存储的重命名操作不是原子性的,操作失败时可能仅部分文件被移动。
添加新列(Adding New Columns)
以下SQL向表my_table添加两列c1和c2。
ALTER TABLE my_table ADD (c1 INT, c2 STRING);
重命名列名(Renaming Column Name)
以下SQL将表my_table中的列c0重命名为c1。
ALTER TABLE my_table RENAME c0 TO c1;
删除列(Dropping Columns)
以下SQL从表my_table中删除两列c1和c2。在Hive目录中,你需要确保在Hive服务器中禁用hive.metastore.disallow.incompatible.col.type.changes,否则此操作可能失败,并抛出类似“以下列的类型与各自位置上的现有列不兼容”的异常。
ALTER TABLE my_table DROP (c1, c2);
删除分区(Dropping Partitions)
以下SQL删除Paimon表的分区。
对于Flink SQL,你可以指定分区列的部分列,也可以同时指定多个分区值。
ALTER TABLE my_table DROP PARTITION (`id` = 1);ALTER TABLE my_table DROP PARTITION (`id` = 1, `name` = 'paimon');ALTER TABLE my_table DROP PARTITION (`id` = 1), PARTITION (`id` = 2);修改列的可空性(Changing Column Nullability)
以下SQL修改列coupon_info的可空性。
CREATE TABLE my_table (id INT PRIMARY KEY NOT ENFORCED, coupon_info FLOAT NOT NULL);-- Change column `coupon_info` from NOT NULL to nullable
ALTER TABLE my_table MODIFY coupon_info FLOAT;-- Change column `coupon_info` from nullable to NOT NULL
-- If there are NULL values already, set table option as below to drop those records silently before altering table.
SET 'table.exec.sink.not-null-enforcer' = 'DROP';
ALTER TABLE my_table MODIFY coupon_info FLOAT NOT NULL;目前将可空列修改为NOT NULL仅在Flink中支持。
修改列注释(Changing Column Comment)
以下SQL将列buy_count的注释修改为“buy count”。
ALTER TABLE my_table MODIFY buy_count BIGINT COMMENT 'buy count';
添加列位置(Adding Column Position)
要添加具有指定位置的新列,使用FIRST或AFTER col_name。
ALTER TABLE my_table ADD c INT FIRST;ALTER TABLE my_table ADD c INT AFTER b;修改列位置(Changing Column Position)
要将现有列修改到新位置,使用FIRST或AFTER col_name。
ALTER TABLE my_table MODIFY col_a DOUBLE FIRST;ALTER TABLE my_table MODIFY col_a DOUBLE AFTER col_b;修改列类型(Changing Column Type)
以下SQL将列col_a的类型修改为DOUBLE。
ALTER TABLE my_table MODIFY col_a DOUBLE;
添加水印(Adding watermark)
以下SQL从现有列log_ts添加一个计算列ts,并在列ts上添加一个水印策略为ts-INTERVAL '1' HOUR,该列ts被标记为表my_table的事件时间属性。
ALTER TABLE my_table ADD (ts AS TO_TIMESTAMP(log_ts) AFTER log_ts,WATERMARK FOR ts AS ts - INTERVAL '1' HOUR
);删除水印(Dropping watermark)
以下SQL删除表my_table的水印。
ALTER TABLE my_table DROP WATERMARK;
修改水印(Changing watermark)
以下SQL将水印策略修改为ts-INTERVAL '2' HOUR。
ALTER TABLE my_table MODIFY WATERMARK FOR ts AS ts - INTERVAL '2' HOUR
拓展:
表结构修改操作的重要性:在数据库管理和数据处理中,修改表结构是一项常见且重要的操作。它允许用户根据业务需求的变化,灵活地调整表的属性、列结构、分区等,以优化数据存储和查询性能。例如,通过修改表属性可以调整数据写入的缓冲区大小,从而影响数据写入的效率;添加或删除列能够适应业务数据的增减需求。
不同修改操作的细节与注意事项:
表属性与注释:修改表属性和注释操作相对直接,但在实际应用中需要准确理解每个属性的含义和作用。比如
write-buffer-size属性直接影响数据写入的性能和资源使用情况。而表注释则有助于文档化表的用途和特点,方便团队成员理解和维护。重命名操作:表名重命名在对象存储环境下需谨慎,因为非原子性操作可能导致数据不一致。这提醒用户在进行此类操作时,要考虑到存储环境的特性,并做好相应的备份或恢复策略。
列操作:添加、重命名、删除列以及修改列的可空性、注释、位置和类型等操作,为表结构的精细调整提供了丰富手段。但在执行这些操作时,尤其是涉及到类型修改或删除列操作时,需要特别注意数据兼容性和潜在的数据丢失风险。例如,在Hive目录中删除列时,需关注Hive元存储的相关配置,避免因类型不兼容而导致操作失败。
分区与水印操作:删除分区操作可以清理不再需要的数据分区,优化存储和查询性能。而水印的添加、删除和修改操作则与流处理中的事件时间处理紧密相关,正确设置水印策略能够有效地处理乱序数据,确保流处理结果的准确性和一致性。
变更数据捕获摄入(CDC Ingestion)
概述
Paimon支持多种方式将数据摄入到具有模式演变功能的Paimon表中。这意味着新增的列会实时同步到Paimon表,并且同步作业无需为此重启。
我们目前支持以下同步方式:
-
MySQL 表同步:将一个或多个 MySQL 表同步到一个 Paimon 表中。
-
MySQL 数据库同步:将整个 MySQL 数据库同步到一个 Paimon 数据库中。
-
程序 API 同步:将自定义的 DataStream 输入同步到一个 Paimon 表中。
-
Kafka 表同步:将一个 Kafka 主题中的表同步到一个 Paimon 表中。
-
Kafka 数据库同步:将包含多个表的一个 Kafka 主题或每个主题包含一个表的多个 Kafka 主题同步到一个 Paimon 数据库中。
-
MongoDB 集合同步:将 MongoDB 中的一个集合同步到一个 Paimon 表中。
-
MongoDB 数据库同步:将整个 MongoDB 数据库同步到一个 Paimon 数据库中。
-
Pulsar 表同步:将一个 Pulsar 主题中的表同步到一个 Paimon 表中。
-
Pulsar 数据库同步:将包含多个表的一个 Pulsar 主题或每个主题包含一个表的多个 Pulsar 主题同步到一个 Paimon 数据库中。
什么是模式演进
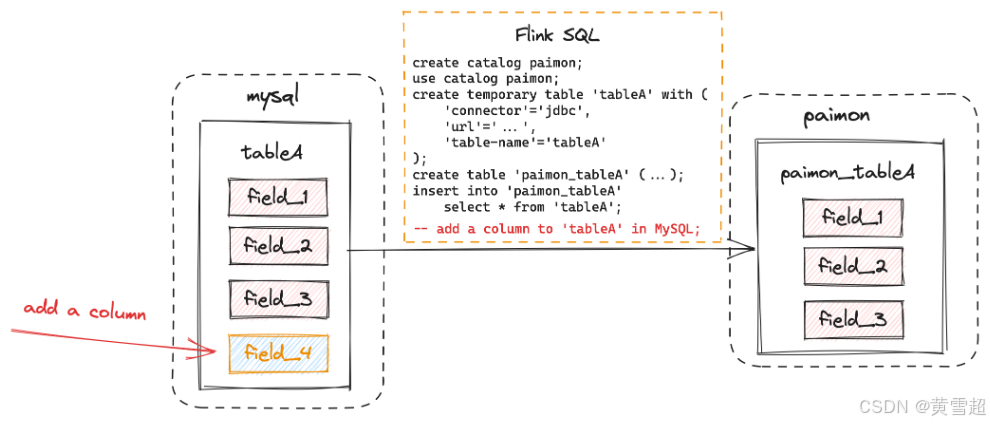
假设我们有一个名为 tableA 的 MySQL 表,它有三个字段:field_1、field_2、field_3。当我们想将这个 MySQL 表加载到 Paimon 时,可以在 Flink SQL 中操作,也可以使用 MySqlSyncTableAction。
Flink SQL:
在 Flink SQL 中,如果在数据摄入后更改 MySQL 表的表模式,表模式的更改不会同步到 Paimon。
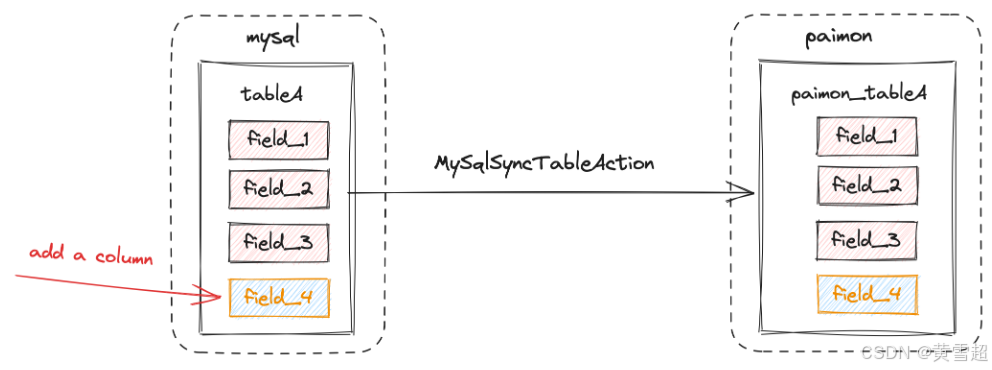
MySqlSyncTableAction:
在 MySqlSyncTableAction中,如果在数据摄入后更改 MySQL 表的表模式,表模式的更改会同步到 Paimon,新添加的 field_4 字段的数据也会同步到 Paimon。
模式变更演进
CDC 摄取支持有限数量的模式变更。目前,该框架无法重命名表、删除列,因此 RENAME TABLE(重命名表)和 DROP COLUMN(删除列)操作将被忽略,RENAME COLUMN(重命名列)操作将添加一个新列。目前支持的模式变更包括:
-
添加列。
-
修改列类型。更具体地说,支持以下变更:
-
从一种字符串类型(char、varchar、text)变更为长度更长的另一种字符串类型;
-
从一种二进制类型(binary、varbinary、blob)变更为长度更长的另一种二进制类型;
-
从一种整数类型(tinyint、smallint、int、bigint)变更为范围更广的另一种整数类型;
-
从一种浮点类型(float、double)变更为范围更广的另一种浮点类型。
-
计算函数
--computed_column 是计算列的定义。参数字段来自源表字段名。
时间函数
时间函数可以将日期和纪元时间转换为另一种形式。一个常见的用例是生成分区值。
| 函数 | 描述 |
|---|---|
| year(temporal-column [, precision]) | 从输入中提取年份。输出是一个表示年份的 INT 值。 |
| month(temporal-column [, precision]) | 从输入中提取一年中的月份。输出是一个表示月份的 INT 值。 |
| day(temporal-column [, precision]) | 从输入中提取月份中的日期。输出是一个表示日期的 INT 值。 |
| hour(temporal-column [, precision]) | 从输入中提取小时。输出是一个表示小时的 INT 值。 |
| minute(temporal-column [, precision]) | 从输入中提取分钟。输出是一个表示分钟的 INT 值。 |
| second(temporal-column [, precision]) | 从输入中提取秒。输出是一个表示秒的 INT 值。 |
| date_format(temporal-column, format-string [, precision]) | 将输入转换为所需格式的字符串。输出类型为 STRING。 |
时间列的数据类型可以是以下几种情况之一:
-
日期、日期时间或时间戳。(DATE, DATETIME or TIMESTAMP)
-
任何整数类型(例如 INT 和 BIGINT)。在这种情况下,数据将被视为 1970-01-01 00:00:00 的纪元时间。你应该设置值的精度(默认精度为 0)。
-
字符串。在这种情况下,如果你未设置时间单位,数据将被视为日期、日期时间或时间戳值的格式化字符串。否则,数据将被视为纪元时间的字符串值。所以在后一种情况下,你必须设置时间单位。
精度表示纪元时间的单位。目前,有四种有效的精度:0(表示纪元秒)、3(表示纪元毫秒)、6(表示纪元微秒)和9(表示纪元纳秒)。以时间点1970-01-01 00:00:00.123456789为例,纪元秒为0,纪元毫秒为123,纪元微秒为123456,纪元纳秒为123456789。精度应与输入值匹配。你可以通过以下方式设置精度:date_format(epoch_col, yyyy-MM-dd, 0) 。
date_format是一个灵活的函数,它能够使用不同的格式字符串将时间值转换为各种格式。最常见的格式字符串是yyyy-MM-dd HH:mm:ss.SSS。另一个例子是yyyy-ww,它可以从输入中提取年份和当年的周数。请注意,输出受区域设置的影响。例如,在某些地区,一周的第一天是星期一,而在其他地区是星期日,所以如果你使用date_format(date_col, yyyy-ww) ,并且date_col的输入是2024-01-07(星期日),输出可能是2024-01(如果一周的第一天是星期一)或2024-02(如果一周的第一天是星期日)。
其他函数
| 函数 | 描述 |
|---|---|
| substring(column, beginInclusive) | 获取column.substring(beginInclusive) 。输出是一个字符串。 |
| substring(column, beginInclusive, endExclusive) | 获取column.substring(beginInclusive, endExclusive) 。输出是一个字符串。 |
| truncate(column, width) | 按宽度截断column 。输出类型与column相同。如果column是一个字符串,truncate(column, width)会将字符串截断为width个字符,即 |
| cast(value, dataType) | 获取一个常量值。输出是一种原子类型,如字符串、整数、布尔值等。 |
特殊数据类型映射
-
MySQL的TINYINT(1)类型默认将映射为布尔值。如果你想像MySQL一样在其中存储数字(- 128 ~ 127),可以指定类型映射选项tinyint1-not-bool(使用--type_mapping),然后该列将在Paimon表中映射为TINYINT。
-
你可以使用类型映射选项to-nullable(使用--type_mapping)来忽略所有非空约束(主键除外)。
-
你可以使用类型映射选项to-string(使用--type_mapping)将所有MySQL数据类型映射为字符串。
-
你可以使用类型映射选项char-to-string(使用--type_mapping)将MySQL的CHAR(length)/VARCHAR(length)类型映射为字符串。
-
你可以使用类型映射选项longtext-to-bytes(使用--type_mapping)将MySQL的LONGTEXT类型映射为BYTES。
-
MySQL的BIGINT UNSIGNED、BIGINT UNSIGNED ZEROFILL、SERIAL默认将映射为DECIMAL(20, 0) 。你可以使用类型映射选项bigint-unsigned-to-bigint(使用--type_mapping)将这些类型映射为Paimon的BIGINT,但存在潜在的数据溢出风险,因为BIGINT UNSIGNED最多可以存储20位整数值,而Paimon的BIGINT最多只能存储19位整数值。所以在使用此选项时,你应确保不会发生溢出。
-
MySQL的BIT(1)类型将映射为布尔值。
-
当使用Hive目录时,MySQL的TIME类型将映射为字符串。
-
MySQL的BINARY将映射为Paimon的VARBINARY。这是因为二进制值在binlog中是以字节形式传递的,所以它应该映射为字节类型(BYTES或VARBINARY)。我们选择VARBINARY是因为它可以保留长度信息。
自定义作业设置
检查点:使用-Dexecution.checkpointing.interval = <interval> 来启用检查点并设置间隔。对于0.7及更高版本,如果你没有启用检查点,Paimon将默认启用检查点并将检查点间隔设置为180秒。
作业名称:使用-Dpipeline.name = <job-name> 来设置自定义同步作业名称。
表配置:你可以使用--table_conf来设置表属性和一些Flink作业属性(如sink.parallelism)。如果表是由CDC作业创建的,表的属性将与给定的属性相同。否则,作业将使用给定的属性来更改表的属性。但请注意,不可变选项(如merge-engine)和桶数不会被更改。
拓展:
DataStream:在流计算领域,DataStream代表一个连续的数据流。在Apache Flink等流计算框架中,DataStream是处理无界数据的基本抽象。它可以从各种数据源(如Kafka、文件等)获取数据,然后通过一系列的转换操作(如过滤、映射、聚合等)进行处理,最终输出到各种数据接收器(如文件系统、数据库等)。DataStream处理模型允许开发者对实时数据流进行低延迟、高吞吐的处理,适用于许多实时应用场景,如实时监控、实时分析等。
Kafka:是一个分布式流平台,由Apache软件基金会开发。它主要用于处理和存储大量的实时数据流。Kafka具有高吞吐量、可扩展性、容错性等特点。它以主题(topic)为单位来组织数据,生产者(producer)将消息发送到特定的主题,消费者(consumer)从主题中拉取消息进行处理。Kafka常用于日志收集、消息队列、流处理等场景,许多大数据和实时应用都依赖Kafka来处理和传输数据。
MySQL:是最流行的开源关系型数据库管理系统之一。它基于SQL(结构化查询语言),广泛应用于各种Web应用程序和企业级应用中。MySQL具有高性能、可靠性和易用性等优点,支持事务处理、数据备份与恢复等功能。在数据同步场景中,常作为数据源,将其中的数据同步到其他数据存储或处理系统,如Paimon。
MongoDB:是一个基于分布式文件存储的开源文档数据库。与传统的关系型数据库不同,MongoDB以BSON(一种类似JSON的二进制格式)文档的形式存储数据,这种数据模型更灵活,适合处理半结构化和非结构化数据。它具有高可扩展性、高可用性等特点,常用于大数据存储、内容管理、实时分析等场景,同样在数据同步场景中可作为数据源。
Pulsar:是一个云原生分布式消息流平台,由Apache软件基金会开发。它提供了统一的消息和流处理原语,支持多租户、持久化消息、高吞吐量等特性。Pulsar的架构设计使其能够在大规模集群环境下高效运行,在消息队列、流处理等领域有广泛应用,在数据同步中可作为数据源,将其主题中的数据同步到Paimon。
Schema(模式):在数据库和数据处理领域,模式定义了数据的结构和组织方式。例如在关系型数据库中,表模式包括表名、列名、列的数据类型等信息。在大数据领域,像 Avro、JSON Schema 等定义了数据记录的结构规范。模式演进则指随着业务发展,模式需要动态更新,比如添加新列、修改数据类型等,而不影响已有数据处理逻辑或尽可能少影响。
DataStream(数据流):是 Apache Flink 等流处理框架中的核心概念,表示连续不断的数据流。数据以事件序列的形式在 DataStream 中流动,框架可以对这些数据流进行实时的转换、聚合等操作。常见的 DataStream 来源有 Kafka、Pulsar 等消息队列,以及文件流等。
CDC(Change Data Capture,变更数据捕获):是一种用于捕获数据库中数据更改的技术。它可以实时或近实时地检测到数据库表中的插入、更新和删除操作,并将这些变更数据提取出来用于其他目的,如数据同步、数据集成、实时数据分析等。例如,在微服务架构中,不同服务的数据库之间可能需要通过 CDC 技术来保持数据的一致性。
Ingestion(摄取):在这里指将数据引入到特定的系统或流程中。在数据处理场景下,数据摄取通常涉及从各种数据源(如数据库、文件系统、消息队列等)获取数据,并将其转换和加载到目标存储或处理系统中,比如数据仓库或大数据处理平台。
Computed Column(计算列):在数据库中,计算列的值是通过表达式基于同一表中其他列的值计算得出的。例如,在一个 “订单” 表中有 “单价” 和 “数量” 列,你可以创建一个计算列 “总价”,其值通过 “单价 * 数量” 计算得到。计算列并不实际存储数据,而是在查询时实时计算。这有助于减少数据冗余,并在需要时快速获取派生数据。
Temporal Functions(时间函数):主要用于处理日期和时间相关的数据。在数据库和数据处理场景中,经常需要对时间数据进行格式化、提取特定部分(如年、月、日等)的操作。例如在数据分析中,按年、月对销售数据进行分组统计时,就会用到这些时间函数。
Epoch Time(纪元时间):也称为 Unix 时间,是一种表示时间的方式,定义为从 1970 年 1 月 1 日 00:00:00 UTC 到特定时间点所经过的秒数。在编程和数据库中广泛用于时间戳的存储和计算,因为它是一种简单且标准化的时间表示方法,便于在不同系统和编程语言之间进行数据交换和处理。
MySQL变更数据捕获(CDC)
Paimon支持使用变更数据捕获(CDC)从不同数据库同步数据变更。此功能需要Flink及其CDC连接器。
准备CDC捆绑包JAR
下载CDC捆绑包JAR并将其放置在<FLINK_HOME>/lib/目录下。
| 版本 | 捆绑包JAR |
|---|---|
| 2.3.x | 仅0.8.2以下版本支持 flink-sql-connector-mysql-cdc-2.3.x.jar |
| 2.4.x | 仅0.8.2以下版本支持 flink-sql-connector-mysql-cdc-2.4.x.jar |
| 3.0.x | 仅0.8.2以下版本支持 flink-sql-connector-mysql-cdc-3.0.x.jar flink-cdc-common-3.0.x.jar |
| 3.1.x | flink-sql-connector-mysql-cdc-3.1.x.jar mysql-connector-java-8.0.27.jar |
同步表
通过在Flink DataStream作业中使用MySqlSyncTableAction,或直接通过flink run,用户可以将一个或多个MySQL表同步到一个Paimon表中。
要通过flink run使用此功能,运行以下Shell命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mysql_sync_table--warehouse <warehouse-path> \--database <database-name> \--table <table-name> \[--partition_keys <partition_keys>] \[--primary_keys <primary-keys>] \[--type_mapping <option1,option2...>] \[--computed_column <'column-name=expr-name(args[, ...])'> [--computed_column ...]] \[--metadata_column <metadata-column>] \[--mysql_conf <mysql-cdc-source-conf> [--mysql_conf <mysql-cdc-source-conf> ...]] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]]| 配置 | 描述 |
|---|---|
| --warehouse | Paimon仓库的路径。 |
| --database | Paimon目录中的数据库名称。 |
| --table | Paimon表名。 |
| --partition_keys | Paimon表的分区键。如果有多个分区键,用逗号连接,例如“dt,hh,mm”。 |
| --primary_keys | Paimon表的主键。如果有多个主键,用逗号连接,例如“buyer_id,seller_id”。 |
| --type_mapping | 用于指定如何将MySQL数据类型映射到Paimon类型。 支持的选项: “tinyint1-not-bool”:将MySQL的TINYINT(1)映射为TINYINT而不是BOOLEAN。 “to-nullable”:忽略所有非空约束(主键除外)。这用于解决Flink无法接受MySQL的“ALTER TABLE ADD COLUMN column type NOT NULL DEFAULT x”操作的问题。 “to-string”:将所有MySQL类型映射为STRING。 “char-to-string”:将MySQL的CHAR(length)/VARCHAR(length)类型映射为STRING。 “longtext-to-bytes”:将MySQL的LONGTEXT类型映射为BYTES。 “bigint-unsigned-to-bigint”:将MySQL的BIGINT UNSIGNED、BIGINT UNSIGNED ZEROFILL、SERIAL映射为BIGINT。使用此选项时应确保不会发生溢出。 |
| --computed_column | 计算列的定义。参数字段来自MySQL表字段名。有关完整的配置列表,请参阅此处。 |
| --metadata_column | --metadata_column用于指定在连接器的输出模式中包含哪些元数据列。元数据列提供与源数据相关的附加信息,例如:--metadata_column table_name,database_name,op_ts。有关可用元数据的完整列表,请参阅其文档。 |
| --mysql_conf | Flink CDC MySQL源的配置。每个配置应采用“key = value”的格式指定。hostname、username、password、database-name和table-name是必需的配置,其他是可选的。有关完整的配置列表,请参阅其文档。 |
| --catalog_conf | Paimon目录的配置。每个配置应采用“key = value”的格式指定。有关目录配置的完整列表,请参阅此处。 |
| --table_conf | Paimon表接收器的配置。每个配置应采用“key = value”的格式指定。有关表配置的完整列表,请参阅此处。 |
如果指定的Paimon表不存在,此操作将自动创建该表。其模式将从所有指定的MySQL表派生而来。如果Paimon表已存在,将把它的模式与所有指定MySQL表的模式进行比较。
示例1:将表同步到一个Paimon表
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mysql_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--primary_keys pt,uid \--computed_column '_year=year(age)' \--mysql_conf hostname=127.0.0.1 \--mysql_conf username=root \--mysql_conf password=123456 \--mysql_conf database-name='source_db' \--mysql_conf table-name='source_table1|source_table2' \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4如示例所示,mysql_conf的table-name支持正则表达式,以监控满足正则表达式的多个表。所有表的模式将合并为一个Paimon表模式。
示例2:将分片同步到一个Paimon表 你还可以使用正则表达式设置database-name以捕获多个数据库。一个典型的场景是,表“source_table”被拆分到数据库“source_db1”、“source_db2”等中,然后你可以将所有“source_table”的数据同步到一个Paimon表中。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mysql_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--primary_keys pt,uid \--computed_column '_year=year(age)' \--mysql_conf hostname=127.0.0.1 \--mysql_conf username=root \--mysql_conf password=123456 \--mysql_conf database-name='source_db.+' \--mysql_conf table-name='source_table' \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4同步数据库
通过在Flink DataStream作业中使用MySqlSyncDatabaseAction,或直接通过flink run,用户可以将整个MySQL数据库同步到一个Paimon数据库中。
要通过flink run使用此功能,运行以下Shell命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mysql_sync_database--warehouse <warehouse-path> \--database <database-name> \[--ignore_incompatible <true/false>] \[--merge_shards <true/false>] \[--table_prefix <paimon-table-prefix>] \[--table_suffix <paimon-table-suffix>] \[--including_tables <mysql-table-name|name-regular-expr>] \[--excluding_tables <mysql-table-name|name-regular-expr>] \[--mode <sync-mode>] \[--metadata_column <metadata-column>] \[--type_mapping <option1,option2...>] \[--partition_keys <partition_keys>] \[--primary_keys <primary-keys>] \[--mysql_conf <mysql-cdc-source-conf> [--mysql_conf <mysql-cdc-source-conf> ...]] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]]| 配置 | 描述 |
|---|---|
| --warehouse | Paimon仓库的路径。 |
| --database | Paimon目录中的数据库名称。 |
| --ignore_incompatible | 默认值为false,在这种情况下,如果MySQL表名在Paimon中存在且它们的模式不兼容,将抛出异常。你可以显式地将其指定为true以忽略不兼容的表和异常。 |
| --merge_shards | 默认值为true,在这种情况下,如果不同数据库中的某些表具有相同的名称,它们的模式将被合并,并且它们的记录将被同步到一个Paimon表中。否则,每个表的记录将被同步到相应的Paimon表中,并且Paimon表将被命名为'databaseName_tableName'以避免潜在的名称冲突。 |
| --table_prefix | 要同步的所有Paimon表的前缀。例如,如果你希望所有同步的表都有“ods_”作为前缀,你可以指定“--table_prefix ods_”。 |
| --table_suffix | 要同步的所有Paimon表的后缀。用法与“--table_prefix”相同。 |
| --including_tables | 用于指定要同步哪些源表。必须使用' |
| --excluding_tables | 用于指定不同步哪些源表。用法与“--including_tables”相同。如果同时指定了“--excluding_tables”和“--including_tables”,“--excluding_tables”具有更高的优先级。 |
| --mode | 用于指定同步模式。 可能的值: “divided”(如果你未指定,则为默认模式):为每个表启动一个接收器,新表的同步需要重新启动作业。 “combined”:为所有表启动一个单一的组合接收器,新表将自动同步。 |
| --metadata_column | --metadata_column用于指定在连接器的输出模式中包含哪些元数据列。元数据列提供与源数据相关的附加信息,例如:--metadata_column table_name,database_name,op_ts。有关可用元数据的完整列表,请参阅其文档。 |
| --type_mapping | 用于指定如何将MySQL数据类型映射到Paimon类型。 支持的选项: “tinyint1-not-bool”:将MySQL的TINYINT(1)映射为TINYINT而不是BOOLEAN。 “to-nullable”:忽略所有非空约束(主键除外)。这用于解决Flink无法接受MySQL的“ALTER TABLE ADD COLUMN column type NOT NULL DEFAULT x”操作的问题。 “to-string”:将所有MySQL类型映射为STRING。 “char-to-string”:将MySQL的CHAR(length)/VARCHAR(length)类型映射为STRING。 “longtext-to-bytes”:将MySQL的LONGTEXT类型映射为BYTES。 “bigint-unsigned-to-bigint”:将MySQL的BIGINT UNSIGNED、BIGINT UNSIGNED ZEROFILL、SERIAL映射为BIGINT。使用此选项时应确保不会发生溢出。 |
| --partition_keys | Paimon表的分区键。如果有多个分区键,用逗号连接,例如“dt,hh,mm”。如果这些键不在源表中,接收器表将不设置分区键。 |
| --primary_keys | Paimon表的主键。如果有多个主键,用逗号连接,例如“buyer_id,seller_id”。如果这些键不在源表中,但源表有主键,接收器表将使用源表的主键。否则,接收器表将不设置主键。 |
| --mysql_conf | Flink CDC MySQL源的配置。每个配置应采用“key = value”的格式指定。hostname、username、password、database-name和table-name是必需的配置,其他是可选的。有关完整的配置列表,请参阅其文档。 |
| --catalog_conf | Paimon目录的配置。每个配置应采用“key = value”的格式指定。有关目录配置的完整列表,请参阅此处。 |
| --table_conf | Paimon表接收器的配置。每个配置应采用“key = value”的格式指定。有关表配置的完整列表,请参阅此处。 |
只有具有主键的表才会被同步。
对于每个要同步的MySQL表,如果相应的Paimon表不存在,此操作将自动创建该表。其模式将从所有指定的MySQL表派生而来。如果Paimon表已存在,将把它的模式与所有指定MySQL表的模式进行比较。
示例1:同步整个数据库
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mysql_sync_database \--warehouse hdfs:///path/to/warehouse \--database test_db \--mysql_conf hostname=127.0.0.1 \--mysql_conf username=root \--mysql_conf password=123456 \--mysql_conf database-name=source_db \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4示例2:同步数据库下新添加的表 假设一开始一个Flink作业正在同步source_db数据库下的[product, user, address]表。提交作业的命令如下:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mysql_sync_database \--warehouse hdfs:///path/to/warehouse \--database test_db \--mysql_conf hostname=127.0.0.1 \--mysql_conf username=root \--mysql_conf password=123456 \--mysql_conf database-name=source_db \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4 \--including_tables 'product|user|address'之后,我们希望作业也同步包含历史数据的[order, custom]表。我们可以通过从作业的先前快照恢复来实现这一点,从而重用作业的现有状态。恢复的作业将首先对新添加的表进行快照,然后自动从先前的位置继续读取变更日志。
从先前快照恢复并添加新表进行同步的命令如下:
<FLINK_HOME>/bin/flink run \--fromSavepoint savepointPath \/path/to/paimon-flink-action-0.9.0.jar \mysql_sync_database \--warehouse hdfs:///path/to/warehouse \--database test_db \--mysql_conf hostname=127.0.0.1 \--mysql_conf username=root \--mysql_conf password=123456 \--mysql_conf database-name=source_db \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--including_tables 'product|user|address|order|custom'你可以设置--mode combined以启用在不重启作业的情况下同步新添加的表。
示例3:同步并合并多个分片 假设你有多个数据库分片db1、db2等,并且每个数据库都有表tbl1、tbl2等。你可以通过以下命令将所有db.+.tbl.+同步到test_db.tbl1、test_db.tbl2等表中:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mysql_sync_database \--warehouse hdfs:///path/to/warehouse \--database test_db \--mysql_conf hostname=127.0.0.1 \--mysql_conf username=root \--mysql_conf password=123456 \--mysql_conf database-name='db.+' \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4 \--including_tables 'tbl.+'通过将database-name设置为正则表达式,同步作业将捕获匹配数据库下的所有表,并将同名表合并为一个表。
你可以设置--merge_shards false以防止合并分片。同步后的表将命名为‘databaseName_tableName’以避免潜在的名称冲突。
常见问题解答
从MySQL摄入的记录中的中文字符出现乱码。 尝试在flink-conf.yaml中设置env.java.opts: -Dfile.encoding=UTF-8(自Flink-1.17起,该选项已更改为env.java.opts.all)。
拓展:
CDC(Change Data Capture,变更数据捕获):这是一种用于捕获数据库中数据更改的技术。在数据集成、数据同步和实时数据分析等场景中广泛应用。通过CDC,系统可以实时感知数据库表的插入、更新和删除操作,并将这些变化传播到其他系统或存储中。例如,在微服务架构中,不同服务之间的数据同步就可以借助CDC技术,使得数据在多个服务间保持一致。
Flink:Apache Flink是一个分布式流批一体化的开源平台,专为高吞吐、低延迟的流处理应用而设计。它提供了丰富的API,支持多种编程语言,能够在不同的集群环境(如YARN、Kubernetes等)上运行。Flink具备强大的状态管理和容错机制,适合处理实时数据和复杂的事件处理。例如,在电商实时数据分析场景中,Flink可以实时处理用户的点击流数据、订单数据等,实现实时的销售统计、用户行为分析等功能。
正则表达式:在文本处理中,正则表达式是一种描述字符模式的工具。在上述场景中,用于指定要同步的数据库名或表名,能够方便地匹配一组符合特定规则的数据库或表。例如
source_db. +表示匹配以source_db开头的所有数据库名;tbl. +表示匹配以tbl开头的所有表名。不同编程语言和工具对正则表达式的支持略有差异,但基本的语法和功能相似。在Python中,通过re模块可以使用正则表达式进行字符串匹配、搜索、替换等操作。Flink CDC连接器:是Flink用于连接各种数据源并捕获其数据变更的组件。针对不同的数据库(如MySQL、PostgreSQL等),有相应的CDC连接器。这些连接器负责与数据库进行交互,监听数据的变化,并将变更数据传递给Flink进行后续处理。例如
flink-sql-connector-mysql-cdc就是用于连接MySQL数据库并捕获其数据变更的连接器。元数据列(Metadata Column):在数据同步过程中,元数据列提供了与源数据相关的额外信息。比如
table_name表示数据来自哪个源表,database_name表示来自哪个源数据库,op_ts可能表示数据操作的时间戳等。这些元数据对于数据的追踪、审计和进一步处理非常有帮助。例如,在数据质量监控中,可以根据操作时间戳来分析数据变更的频率和趋势,以发现潜在的数据问题。
PostgreSQL变更数据捕获(CDC)
Paimon支持使用变更数据捕获(CDC)从不同数据库同步数据变更。此功能需要Flink及其CDC连接器。
准备CDC捆绑包JAR
flink-connector-postgres-cdc-*.jar
同步表
通过在Flink DataStream作业中使用PostgresSyncTableAction,或直接通过flink run,用户可以将一个或多个PostgreSQL表同步到一个Paimon表中。
要通过flink run使用此功能,运行以下Shell命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \postgres_sync_table--warehouse <warehouse_path> \--database <database_name> \--table <table_name> \[--partition_keys <partition_keys>] \[--primary_keys <primary_keys>] \[--type_mapping <option1,option2...>] \[--computed_column <'column-name=expr-name(args[, ...])'> [--computed_column ...]] \[--metadata_column <metadata_column>] \[--postgres_conf <postgres_cdc_source_conf> [--postgres_conf <postgres_cdc_source_conf> ...]] \[--catalog_conf <paimon_catalog_conf> [--catalog_conf <paimon_catalog_conf> ...]] \[--table_conf <paimon_table_sink_conf> [--table_conf <paimon_table_sink_conf> ...]]| 配置 | 描述 |
|---|---|
| --warehouse | Paimon仓库的路径。 |
| --database | Paimon目录中的数据库名称。 |
| --table | Paimon表名。 |
| --partition_keys | Paimon表的分区键。如果有多个分区键,用逗号连接,例如“dt,hh,mm”。 |
| --primary_keys | Paimon表的主键。如果有多个主键,用逗号连接,例如“buyer_id,seller_id”。 |
| --type_mapping | 用于指定如何将PostgreSQL数据类型映射到Paimon类型。 支持的选项: “to-string”:将所有PostgreSQL类型映射为STRING。 |
| --computed_column | 计算列的定义。参数字段来自PostgreSQL表字段名。有关完整的配置列表,请参阅此处。 |
| --metadata_column | --metadata_column用于指定在连接器的输出模式中包含哪些元数据列。元数据列提供与源数据相关的附加信息,例如:--metadata_column table_name,database_name,schema_name,op_ts。有关可用元数据的完整列表,请参阅其文档。 |
| --postgres_conf | Flink CDC Postgres源的配置。每个配置应采用“key = value”的格式指定。hostname、username、password、database-name、schema-name、table-name和slot.name是必需的配置,其他是可选的。有关完整的配置列表,请参阅其文档。 |
| --catalog_conf | Paimon目录的配置。每个配置应采用“key = value”的格式指定。有关目录配置的完整列表,请参阅此处。 |
| --table_conf | Paimon表接收器的配置。每个配置应采用“key = value”的格式指定。有关表配置的完整列表,请参阅此处。 |
如果指定的Paimon表不存在,此操作将自动创建该表。其模式将从所有指定的PostgreSQL表派生而来。如果Paimon表已存在,将把它的模式与所有指定PostgreSQL表的模式进行比较。
示例1:将表同步到一个Paimon表
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \postgres_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--primary_keys pt,uid \--computed_column '_year=year(age)' \--postgres_conf hostname=127.0.0.1 \--postgres_conf username=root \--postgres_conf password=123456 \--postgres_conf database-name='source_db' \--postgres_conf schema-name='public' \--postgres_conf table-name='source_table1|source_table2' \--postgres_conf slot.name='paimon_cdc' \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4如示例所示,postgres_conf的table-name支持正则表达式,以监控满足正则表达式的多个表。所有表的模式将合并为一个Paimon表模式。
示例2:将分片同步到一个Paimon表 你还可以使用正则表达式设置‘schema-name’以捕获多个模式。一个典型的场景是,表“source_table”被拆分到模式“source_schema1”、“source_schema2”等中,然后你可以将所有“source_table”的数据同步到一个Paimon表中。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \postgres_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--primary_keys pt,uid \--computed_column '_year=year(age)' \--postgres_conf hostname=127.0.0.1 \--postgres_conf username=root \--postgres_conf password=123456 \--postgres_conf database-name='source_db' \--postgres_conf schema-name='source_schema.+' \--postgres_conf table-name='source_table' \--postgres_conf slot.name='paimon_cdc' \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4拓展:
PostgreSQL:一种强大的开源关系型数据库管理系统,以其对SQL标准的广泛支持、丰富的数据类型和强大的扩展性而闻名。在数据处理场景中,常用于存储和管理复杂的数据结构与业务逻辑相关的数据。例如,在一些对数据完整性和事务处理要求较高的企业级应用中,PostgreSQL可以作为后端数据库存储关键业务数据。
flink-connector-postgres-cdc-*.jar:这是Flink用于连接PostgreSQL数据库并进行变更数据捕获的连接器JAR包。它负责与PostgreSQL数据库建立连接,监听数据库中的数据变化,并将这些变更数据传递给Flink进行后续处理。在使用时,需要将该JAR包放置在Flink的相关目录下,以便Flink能够加载并使用其中的功能。
PostgreSQL模式(Schema):在PostgreSQL中,模式是数据库对象(如表、视图、函数等)的逻辑分组。类似于命名空间,它可以帮助用户更好地组织和管理数据库中的对象。不同模式中的对象可以有相同的名称而不会冲突。在数据同步场景中,通过设置
schema-name并结合正则表达式,可以灵活地选择需要同步的模式及其下的表,这在处理大型、复杂的数据库结构时非常有用。Slot.name:在PostgreSQL的逻辑复制中,Slot(槽)用于标识一个复制流。slot.name是在配置Flink CDC Postgres源时必须指定的参数之一,它定义了用于捕获变更数据的逻辑复制槽的名称。每个逻辑复制槽会跟踪数据库的更改,并将这些更改提供给订阅者(如Flink作业)。例如,在上述配置中使用
paimon_cdc作为槽名,该槽将负责捕获相关表的变更数据并传递给Flink进行同步到Paimon表的操作。
Kafka变更数据捕获(CDC)
准备Kafka捆绑包JAR
flink-sql-connector-kafka-*.jar
支持的格式
Flink提供了几种Kafka CDC格式:Canal Json、Debezium Json、Debezium Avro、Ogg Json、Maxwell Json和普通Json。如果Kafka主题中的消息是使用变更数据捕获(CDC)工具从其他数据库捕获的变更事件,那么你可以使用Paimon Kafka CDC,将解析后的INSERT、UPDATE、DELETE消息写入Paimon表。
| 格式 | 是否支持 |
|---|---|
| Canal CDC | True |
| Debezium CDC | True |
| Maxwell CDC | True |
| OGG CDC | True |
| JSON | True |
JSON源可能缺少一些信息。例如,Ogg和Maxwell格式标准不包含字段类型;当你将JSON源写入Flink Kafka接收器时,它将只保留数据和行类型,而丢弃其他信息。同步作业将尽力按如下方式处理该问题:
-
通常,debezium-json包含“schema”字段,Paimon将从中检索数据类型。请确保你的debezium json有此字段,否则Paimon将使用“STRING”类型。
-
如果缺少字段类型,Paimon将默认使用“STRING”类型。
-
如果缺少数据库名或表名,你无法进行数据库同步,但仍可以进行表同步。
-
如果缺少主键,作业可能会创建无主键表。你可以在提交表同步作业时设置主键。
同步表
通过在Flink DataStream作业中使用KafkaSyncTableAction,或直接通过flink run,用户可以将Kafka一个主题中的一个或多个表同步到一个Paimon表中。
要通过flink run使用此功能,运行以下Shell命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \kafka_sync_table--warehouse <warehouse-path> \--database <database-name> \--table <table-name> \[--partition_keys <partition_keys>] \[--primary_keys <primary-keys>] \[--type_mapping to-string] \[--computed_column <'column-name=expr-name(args[, ...])'> [--computed_column ...]] \[--kafka_conf <kafka-source-conf> [--kafka_conf <kafka-source-conf> ...]] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]]| 配置 | 描述 |
|---|---|
| --warehouse | Paimon仓库的路径。 |
| --database | Paimon目录中的数据库名称。 |
| --table | Paimon表名。 |
| --partition_keys | Paimon表的分区键。如果有多个分区键,用逗号连接,例如“dt,hh,mm”。 |
| --primary_keys | Paimon表的主键。如果有多个主键,用逗号连接,例如“buyer_id,seller_id”。 |
| --type_mapping | 用于指定如何将MySQL数据类型映射到Paimon类型。 支持的选项: “tinyint1-not-bool”:将MySQL的TINYINT(1)映射为TINYINT而不是BOOLEAN。 “to-nullable”:忽略所有非空约束(主键除外)。这用于解决Flink无法接受MySQL的“ALTER TABLE ADD COLUMN column type NOT NULL DEFAULT x”操作的问题。 “to-string”:将所有MySQL类型映射为STRING。 “char-to-string”:将MySQL的CHAR(length)/VARCHAR(length)类型映射为STRING。 “longtext-to-bytes”:将MySQL的LONGTEXT类型映射为BYTES。 “bigint-unsigned-to-bigint”:将MySQL的BIGINT UNSIGNED、BIGINT UNSIGNED ZEROFILL、SERIAL映射为BIGINT。使用此选项时应确保不会发生溢出。 |
| --computed_column | 计算列的定义。参数字段来自Kafka主题的表字段名。有关完整的配置列表,请参阅此处。 |
| --kafka_conf | Flink Kafka源的配置。每个配置应采用 |
| --catalog_conf | Paimon目录的配置。每个配置应采用“key = value”的格式指定。有关目录配置的完整列表,请参阅此处。 |
| --table_conf | Paimon表接收器的配置。每个配置应采用“key = value”的格式指定。有关表配置的完整列表,请参阅此处。 |
如果指定的Paimon表不存在,此操作将自动创建该表。其模式将从所有指定的Kafka主题的表派生而来,它从主题中获取最早的非DDL数据解析模式。如果Paimon表已存在,将把它的模式与所有指定的Kafka主题的表的模式进行比较。
示例1:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \kafka_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--primary_keys pt,uid \--computed_column '_year=year(age)' \--kafka_conf properties.bootstrap.servers=127.0.0.1:9020 \--kafka_conf topic=order \--kafka_conf properties.group.id=123456 \--kafka_conf value.format=canal-json \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4如果在启动同步作业时Kafka主题不包含消息,则必须在提交作业前手动创建表。你可以仅定义分区键和主键,其余列将由同步作业添加。
注意:在这种情况下,你不应使用–partition_keys或–primary_keys,因为这些键在创建表时已定义且无法修改。此外,如果你指定了计算列,还应定义计算列使用的所有参数字段。
示例2:如果你想同步一个主键为id INT的表,并且想计算一个分区键part = date_format(create_time,yyyy-MM-dd),你可以先创建这样一个表(其他列可以省略):
CREATE TABLE test_db.test_table (id INT, -- primary keycreate_time TIMESTAMP, -- the argument of computed column partpart STRING, -- partition keyPRIMARY KEY (id, part) NOT ENFORCED
) PARTITIONED BY (part);然后你可以提交同步作业:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \kafka_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--computed_column 'part=date_format(create_time,yyyy-MM-dd)' \... (other conf)示例3:对于一些追加数据(如日志数据),它可以被视为仅包含INSERT操作类型的特殊CDC数据,因此你可以使用format = json将此类数据同步到Paimon表。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \kafka_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--computed_column 'pt=date_format(event_tm, yyyyMMdd)' \--kafka_conf properties.bootstrap.servers=127.0.0.1:9020 \--kafka_conf topic=test_log \--kafka_conf properties.group.id=123456 \--kafka_conf value.format=json \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf sink.parallelism=4同步数据库
通过在Flink DataStream作业中使用KafkaSyncDatabaseAction,或直接通过flink run,用户可以将多个主题或一个主题同步到一个Paimon数据库。
要通过flink run使用此功能,运行以下Shell命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \kafka_sync_database--warehouse <warehouse-path> \--database <database-name> \[--table_prefix <paimon-table-prefix>] \[--table_suffix <paimon-table-suffix>] \[--including_tables <table-name|name-regular-expr>] \[--excluding_tables <table-name|name-regular-expr>] \[--type_mapping to-string] \[--partition_keys <partition_keys>] \[--primary_keys <primary-keys>] \[--kafka_conf <kafka-source-conf> [--kafka_conf <kafka-source-conf> ...]] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]]| 配置 | 描述 |
|---|---|
| --warehouse | Paimon仓库的路径。 |
| --database | Paimon目录中的数据库名称。 |
| --ignore_incompatible | 默认值为false,在这种情况下,如果MySQL表名在Paimon中存在且它们的模式不兼容,将抛出异常。你可以显式地将其指定为true以忽略不兼容的表和异常。 |
| --table_prefix | 要同步的所有Paimon表的前缀。例如,如果你希望所有同步的表都有“ods_”作为前缀,你可以指定“--table_prefix ods_”。 |
| --table_suffix | 要同步的所有Paimon表的后缀。用法与“--table_prefix”相同。 |
| --including_tables | 用于指定要同步哪些源表。必须使用' |
| --excluding_tables | 用于指定不同步哪些源表。用法与“--including_tables”相同。如果同时指定了“--excluding_tables”和“--including_tables”,“--excluding_tables”具有更高的优先级。 |
| --type_mapping | 用于指定如何将MySQL数据类型映射到Paimon类型。 支持的选项: “tinyint1-not-bool”:将MySQL的TINYINT(1)映射为TINYINT而不是BOOLEAN。 “to-nullable”:忽略所有非空约束(主键除外)。这用于解决Flink无法接受MySQL的“ALTER TABLE ADD COLUMN column type NOT NULL DEFAULT x”操作的问题。 “to-string”:将所有MySQL类型映射为STRING。 “char-to-string”:将MySQL的CHAR(length)/VARCHAR(length)类型映射为STRING。 “longtext-to-bytes”:将MySQL的LONGTEXT类型映射为BYTES。 “bigint-unsigned-to-bigint”:将MySQL的BIGINT UNSIGNED、BIGINT UNSIGNED ZEROFILL、SERIAL映射为BIGINT。使用此选项时应确保不会发生溢出。 |
| --partition_keys | Paimon表的分区键。如果有多个分区键,用逗号连接,例如“dt,hh,mm”。如果这些键不在源表中,接收器表将不设置分区键。 |
| --multiple_table_partition_keys | 每个不同Paimon表的分区键。如果有多个分区键,用逗号连接,例如: --multiple_table_partition_keys tableName1 = col1,col2.col3 --multiple_table_partition_keys tableName2 = col4,col5.col6 --multiple_table_partition_keys tableName3 = col7,col8.col9 如果这些键不在源表中,接收器表将不设置分区键。 |
| --primary_keys | Paimon表的主键。如果有多个主键,用逗号连接,例如“buyer_id,seller_id”。如果这些键不在源表中,但源表有主键,接收器表将使用源表的主键。否则,接收器表将不设置主键。 |
| --kafka_conf | Flink Kafka源的配置。每个配置应采用 |
| --catalog_conf | Paimon目录的配置。每个配置应采用“key = value”的格式指定。有关目录配置的完整列表,请参阅此处。 |
| --table_conf | Paimon表接收器的配置。每个配置应采用“key = value”的格式指定。有关表配置的完整列表,请参阅此处。 |
此操作将为所有表构建一个单一的组合接收器。对于每个要同步的Kafka主题的表,如果相应的Paimon表不存在,此操作将自动创建该表,并且其模式将从所有指定的Kafka主题的表派生而来。如果Paimon表已存在且其模式与从Kafka记录解析的模式不同,此操作将尝试进行模式演进。
示例:
-
从一个Kafka主题同步到Paimon数据库:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \kafka_sync_database \--warehouse hdfs:///path/to/warehouse \--database test_db \--kafka_conf properties.bootstrap.servers=127.0.0.1:9020 \--kafka_conf topic=order \--kafka_conf properties.group.id=123456 \--kafka_conf value.format=canal-json \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4-
从多个Kafka主题同步到Paimon数据库:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \kafka_sync_database \--warehouse hdfs:///path/to/warehouse \--database test_db \--kafka_conf properties.bootstrap.servers=127.0.0.1:9020 \--kafka_conf topic=order\;logistic_order\;user \--kafka_conf properties.group.id=123456 \--kafka_conf value.format=canal-json \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4额外的Kafka配置
有一些用于构建Flink Kafka源的有用选项,但它们未在flink-kafka-connector文档中提供。它们是:
| 键 | 默认值 | 类型 | 描述 |
|---|---|---|---|
| schema.registry.url | (none) | 字符串 | 当配置“value.format = debezium-avro”时,这需要使用Confluence模式注册表模型进行Apache Avro序列化,你需要提供模式注册表URL。 |
拓展:
Kafka:是一个分布式流平台,常用于处理实时数据。它具有高吞吐量、可扩展性和容错性等特点,在大数据生态系统中被广泛应用于数据的收集、传输和分发。例如,在电商系统中,Kafka可以收集用户的各种行为数据(如点击、购买等),然后将这些数据分发给不同的分析系统进行实时处理。
Flink Kafka连接器:
flink-sql-connector-kafka-*.jar是Flink与Kafka集成的关键组件。它允许Flink从Kafka主题中读取数据,并将处理后的数据写回到Kafka主题。在CDC场景下,该连接器负责从Kafka获取包含变更数据的消息,并将其传递给Flink进行进一步处理,如解析消息并同步到Paimon表。这涉及到对Kafka消息格式的理解和处理,以及与Flink的流处理逻辑相结合。Canal:是阿里巴巴开发的一款基于MySQL数据库增量日志解析,提供增量数据订阅和消费的开源工具。Canal模拟MySQL主从复制架构中的slave节点,通过解析MySQL的二进制日志(binlog)来获取数据变更,然后将这些变更以特定格式(如Canal Json)发送到Kafka等消息队列中。在数据同步场景中,Canal为捕获MySQL数据变化提供了一种高效可靠的方式。
Debezium:是一个开源的分布式平台,用于捕获数据库的变更数据。它支持多种数据库,如MySQL、PostgreSQL等。Debezium将数据库的更改记录转换为事件流,并以特定格式(如Debezium Json、Debezium Avro)输出到消息代理(如Kafka)。Debezium提供了丰富的元数据信息,如数据库名、表名、字段类型等,这对于数据同步和处理非常有帮助。例如,在异构数据库之间的数据同步场景中,Debezium可以将源数据库的变更准确地传递到目标系统。
Maxwell:是一个用于从MySQL数据库捕获数据变更并将其作为JSON格式消息发送到Kafka等消息队列的工具。它通过解析MySQL的binlog来实现数据捕获。Maxwell的JSON格式消息相对简洁,但可能缺少一些像字段类型这样的详细元数据信息,在使用时需要额外处理。
OGG(Oracle GoldenGate):是甲骨文公司的一款数据集成和复制软件,能够在异构数据库之间实现数据的实时复制和同步。OGG可以捕获源数据库的变更,并将其传输到目标数据库或其他消息系统。当使用OGG与Kafka结合时,OGG会将捕获到的数据变更以OGG Json格式发送到Kafka,后续Flink可以从Kafka获取这些数据进行进一步处理。
Avro:是一种数据序列化系统,它提供了丰富的数据结构类型,并且支持数据的压缩和模式演变。在Kafka CDC中,当使用Debezium Avro格式时,数据会以Avro格式进行序列化,并通过Kafka传输。Avro的模式信息可以存储在Schema Registry中,这有助于确保数据的一致性和可解析性。例如,在处理大规模数据传输和存储时,Avro的压缩功能可以有效减少数据传输量和存储空间。
Schema Registry:是一个存储和管理Avro、Protobuf等序列化格式的模式(Schema)的服务。在使用Debezium Avro格式时,Flink Kafka源需要从Schema Registry获取相应的模式信息,以便正确解析Kafka消息中的数据。Schema Registry提供了版本管理、兼容性检查等功能,确保数据生产者和消费者之间的模式一致性。例如,当数据结构发生变化时,Schema Registry可以帮助管理新模式的注册和版本控制,使得消费者能够正确处理新的数据格式。
MongoDB变更数据捕获(CDC)
准备MongoDB捆绑包JAR
flink-sql-connector-mongodb-cdc-*.jar
仅支持3.1+版本的CDC
同步表
通过在Flink DataStream作业中使用MongoDBSyncTableAction,或直接通过flink run,用户可以将MongoDB中的一个集合同步到一个Paimon表中。
要通过flink run使用此功能,运行以下Shell命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mongodb_sync_table--warehouse <warehouse-path> \--database <database-name> \--table <table-name> \[--partition_keys <partition_keys>] \[--computed_column <'column-name=expr-name(args[, ...])'> [--computed_column ...]] \[--mongodb_conf <mongodb-cdc-source-conf> [--mongodb_conf <mongodb-cdc-source-conf> ...]] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]]| 配置 | 描述 |
|---|---|
| --warehouse | Paimon仓库的路径。 |
| --database | Paimon目录中的数据库名称。 |
| --table | Paimon表名。 |
| --partition_keys | Paimon表的分区键。如果有多个分区键,用逗号连接,例如“dt,hh,mm”。 |
| --computed_column | 计算列的定义。参数字段来自MongoDB集合字段名。有关完整的配置列表,请参阅此处。 |
| --mongodb_conf | Flink CDC MongoDB源的配置。每个配置应采用“key = value”的格式指定。hosts、username、password、database和collection是必需的配置,其他是可选的。有关完整的配置列表,请参阅其文档。 |
| --catalog_conf | Paimon目录的配置。每个配置应采用“key = value”的格式指定。有关目录配置的完整列表,请参阅此处。 |
| --table_conf | Paimon表接收器的配置。每个配置应采用“key = value”的格式指定。有关表配置的完整列表,请参阅此处。 |
这里有几点需要注意:
-
mongodb_conf在MongoDB CDC源配置的基础上引入了schema.start.mode参数。schema.start.mode提供两种模式:dynamic(默认)和specified。在dynamic模式下,MongoDB模式信息在一个层级上进行解析,这构成了模式变更演进的基础。在specified模式下,同步根据指定的标准进行。这可以通过配置field.name来指定同步字段,并通过parser.path指定这些字段的JSON解析路径来实现。两者的区别在于,specified模式要求用户明确标识要使用的字段,并基于这些字段创建映射表。而dynamic模式则确保Paimon和MongoDB始终保持顶级字段一致,无需关注特定字段。在使用嵌套字段的值时,需要对数据表进行进一步处理。 -
mongodb_conf在MongoDB CDC源配置的基础上引入了default.id.generation参数。default.id.generation设置提供两种不同的行为:设置为true和设置为false时。当default.id.generation设置为true时,MongoDB CDC源遵循默认的_id生成策略,即去除外部的$oid嵌套,以提供更简洁的标识符。这种模式简化了_id的表示,使其更直接且用户友好。相反,当default.id.generation设置为false时,MongoDB CDC源保留原始的_id结构,不进行任何额外处理。这种模式为用户提供了使用MongoDB提供的原始_id格式的灵活性,保留了任何嵌套元素,如$oid。两者之间的选择取决于用户的偏好:前者用于更简洁、简化的_id,后者用于直接表示MongoDB的_id结构。
| 操作符 | 描述 |
|---|---|
|
| 查询的根元素。所有路径表达式由此开始。 |
|
| 由过滤谓词处理的当前节点。 |
|
| 通配符。可用于任何需要名称或数字的地方。 |
|
| 深度扫描。可用于任何需要名称的地方。 |
|
| 点表示法的子节点。 |
|
| 方括号表示法的一个或多个子节点。 |
|
| 方括号表示法的一个或多个子节点。 |
|
| 数组索引或索引范围。 |
|
| 过滤表达式。表达式必须计算为布尔值。 |
函数可以在路径末尾调用-函数的输入是路径表达式的输出。函数输出由函数本身决定。
| 函数 | 描述 | 输出类型 |
|---|---|---|
|
| 提供数字数组的最小值。 | Double |
|
| 提供数字数组的最大值。 | Double |
|
| 提供数字数组的平均值。 | Double |
|
| 提供数字数组的标准偏差值 | Double |
|
| 提供数组的长度 | Integer |
|
| 提供数字数组的总和值。 | Double |
|
| 提供属性键(终端波浪号 | Set |
|
| 提供路径输出与新项的连接版本。 | like input |
|
| 向json路径输出数组添加一个项 | like input |
|
| 向json路径输出数组添加一个项 | like input |
|
| 提供数组的第一项 | Depends on the array |
|
| 提供数组的最后一项 | Depends on the array |
|
| 提供数组中索引为 | Depends on the array |
路径示例
{"store": {"book": [{"category": "reference","author": "Nigel Rees","title": "Sayings of the Century","price": 8.95},{"category": "fiction","author": "Evelyn Waugh","title": "Sword of Honour","price": 12.99},{"category": "fiction","author": "Herman Melville","title": "Moby Dick","isbn": "0-553-21311-3","price": 8.99},{"category": "fiction","author": "J. R. R. Tolkien","title": "The Lord of the Rings","isbn": "0-395-19395-8","price": 22.99}],"bicycle": {"color": "red","price": 19.95}},"expensive": 10
}| JsonPath | 结果 |
|---|---|
|
| 提供数字数组的最小值。(此处描述疑似有误,应为获取 |
|
| 所有作者。 |
|
| 所有事物,包括书籍和自行车。 |
|
| 提供数字数组的标准偏差值。(此处描述疑似有误,应为获取 |
|
| 第三本书。 |
|
| 倒数第二本书。 |
|
| 前两本书。 |
|
| 从索引0(包含)到索引2(不包含)的所有书籍。 |
|
| 从索引1(包含)到索引2(不包含)的所有书籍 |
|
| 最后两本书 |
|
| 从索引2(包含)到最后的所有书籍 |
|
| 所有有ISBN编号的书籍 |
|
| 商店中所有价格低于10的书籍 |
|
| 商店中所有价格不“昂贵”的书籍 |
|
| 所有匹配正则表达式(忽略大小写)的书籍 |
|
| 获取所有内容 |
|
| 书籍的数量 |
- 同步表需要将其主键设置为
_id。这是因为MongoDB的变更事件在消息中是在更新之前记录的。因此,我们只能将它们转换为Flink的UPSERT变更日志流。而UPSERT流需要一个唯一键,这就是为什么我们必须将_id声明为主键。将其他列声明为主键是不可行的,因为删除操作仅包含_id和分片键,不包括其他键值对。 - MongoDB变更流旨在返回简单的JSON文档,不包含任何数据类型定义。这是因为MongoDB是一个面向文档的数据库,其核心特性之一是动态模式,文档可以包含不同的字段,并且字段的数据类型可以是灵活的。因此,变更流中不存在数据类型定义是为了保持这种灵活性和可扩展性。出于这个原因,我们将从MongoDB同步到Paimon的所有字段数据类型都设置为字符串,以解决无法获取数据类型的问题。
如果指定的Paimon表不存在,此操作将自动创建该表。其模式将从MongoDB集合派生而来。
示例1:将集合同步到一个Paimon表
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mongodb_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--computed_column '_year=year(age)' \--mongodb_conf hosts=127.0.0.1:27017 \--mongodb_conf username=root \--mongodb_conf password=123456 \--mongodb_conf database=source_db \--mongodb_conf collection=source_table1 \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4示例2:根据指定的字段映射将集合同步到Paimon表
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mongodb_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--mongodb_conf hosts=127.0.0.1:27017 \--mongodb_conf username=root \--mongodb_conf password=123456 \--mongodb_conf database=source_db \--mongodb_conf collection=source_table1 \--mongodb_conf schema.start.mode=specified \--mongodb_conf field.name=_id,name,description \--mongodb_conf parser.path=$._id,$.name,$.description \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4同步数据库
通过在Flink DataStream作业中使用MongoDBSyncDatabaseAction,或直接通过flink run,用户可以将整个MongoDB数据库同步到一个Paimon数据库。
要通过flink run使用此功能,运行以下Shell命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mongodb_sync_database--warehouse <warehouse-path> \--database <database-name> \[--table_prefix <paimon-table-prefix>] \[--table_suffix <paimon-table-suffix>] \[--including_tables <mongodb-table-name|name-regular-expr>] \[--excluding_tables <mongodb-table-name|name-regular-expr>] \[--partition_keys <partition_keys>] \[--primary_keys <primary-keys>] \[--mongodb_conf <mongodb-cdc-source-conf> [--mongodb_conf <mongodb-cdc-source-conf> ...]] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]]| 配置 | 描述 |
|---|---|
| --warehouse | Paimon仓库的路径。 |
| --database | Paimon目录中的数据库名称。 |
| --table_prefix | 要同步的所有Paimon表的前缀。例如,如果你希望所有同步的表都有“ods_”作为前缀,你可以指定“--table_prefix ods_”。 |
| --table_suffix | 要同步的所有Paimon表的后缀。用法与“--table_prefix”相同。 |
| --including_tables | 用于指定要同步哪些源表。必须使用' |
| --excluding_tables | 用于指定不同步哪些源表。用法与“--including_tables”相同。如果同时指定了“--excluding_tables”和“--including_tables”,“--excluding_tables”具有更高的优先级。 |
| --partition_keys | Paimon表的分区键。如果有多个分区键,用逗号连接,例如“dt,hh,mm”。如果这些键不在源表中,接收器表将不设置分区键。 |
| --primary_keys | Paimon表的主键。如果有多个主键,用逗号连接,例如“buyer_id,seller_id”。如果这些键不在源表中,但源表有主键,接收器表将使用源表的主键。否则,接收器表将不设置主键。 |
| --mongodb_conf | Flink CDC MongoDB源的配置。每个配置应采用“key = value”的格式指定。hosts、username、password、database是必需的配置,其他是可选的。有关完整的配置列表,请参阅其文档。 |
| --catalog_conf | Paimon目录的配置。每个配置应采用“key = value”的格式指定。有关目录配置的完整列表,请参阅此处。 |
| --table_conf | Paimon表接收器的配置。每个配置应采用“key = value”的格式指定。有关表配置的完整列表,请参阅此处。 |
所有要同步的集合都需要将_id设置为主键。对于每个要同步的MongoDB集合,如果相应的Paimon表不存在,此操作将自动创建该表。其模式将从所有指定的MongoDB集合派生而来。如果Paimon表已存在,将把它的模式与所有指定的MongoDB集合的模式进行比较。任务开始后创建的任何MongoDB表将自动包含在内。
示例1:同步整个数据库
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mongodb_sync_database \--warehouse hdfs:///path/to/warehouse \--database test_db \--mongodb_conf hosts=127.0.0.1:27017 \--mongodb_conf username=root \--mongodb_conf password=123456 \--mongodb_conf database=source_db \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4示例2:同步指定的表
<FLINK_HOME>/bin/flink run \
--fromSavepoint savepointPath \
/path/to/paimon-flink-action-0.9.0.jar \
mongodb_sync_database \
--warehouse hdfs:///path/to/warehouse \
--database test_db \
--mongodb_conf hosts=127.0.0.1:27017 \
--mongodb_conf username=root \
--mongodb_conf password=123456 \
--mongodb_conf database=source_db \
--catalog_conf metastore=hive \
--catalog_conf uri=thrift://hive-metastore:9083 \
--table_conf bucket=4 \
--including_tables 'product|user|address|order|custom'拓展:
MongoDB:是一款流行的开源文档型数据库,以其高可扩展性、灵活的数据模型和出色的性能在大数据和Web应用开发中广泛应用。与传统的关系型数据库不同,MongoDB使用BSON(Binary JSON)格式来存储数据,这使得它非常适合存储半结构化或非结构化数据。例如,在内容管理系统中,MongoDB可以轻松存储和管理各种格式的文章、图片和多媒体文件的相关信息。
Flink SQL连接器 for MongoDB CDC:
flink-sql-connector-mongodb-cdc-*.jar是Flink用于连接MongoDB并捕获变更数据的组件。它基于MongoDB的变更流功能,能够实时监听数据库的变化,并将这些变更数据传递给Flink进行处理,实现数据从MongoDB到Paimon等存储系统的同步。MongoDB变更流(Change Streams):这是MongoDB提供的一项功能,允许应用程序实时响应数据库中的数据更改。变更流会返回描述数据库操作(如插入、更新、删除)的文档,应用程序可以订阅这些变更并进行相应处理。在数据集成场景中,变更流为捕获MongoDB数据的实时变化提供了高效的途径。
JSON路径(JsonPath):是一种用于在JSON文档中定位特定元素的表达式语言。在处理MongoDB数据时,JsonPath非常有用,因为MongoDB以文档形式存储数据,结构类似于JSON。通过JsonPath,可以方便地从复杂的文档结构中提取所需的数据字段,例如在配置
parser.path时使用JsonPath来指定字段的解析路径。UPSERT变更日志流:在Flink中,UPSERT流结合了插入(INSERT)和更新(UPDATE)操作,用于处理数据的变化。对于MongoDB的变更数据,由于其记录方式,转换为Flink的UPSERT变更日志流可以有效地处理数据的更新和插入操作,确保数据的一致性。而设置唯一的主键(如
_id)对于UPSERT流的正确处理至关重要。
Pulsar变更数据捕获(CDC)
准备Pulsar捆绑包JAR
flink-connector-pulsar-*.jar
支持的格式
Flink提供了几种PulsarCDC格式:Canal Json、Debezium Json、Debezium Avro、Ogg Json、Maxwell Json和普通Json。如果Pulsar主题中的消息是使用变更数据捕获(CDC)工具从其他数据库捕获的变更事件,那么你可以使用PaimonPulsarCDC,将解析后的INSERT、UPDATE、DELETE消息写入Paimon表。
| 格式 | 是否支持 |
|---|---|
| Canal CDC | True |
| Debezium CDC | True |
| Maxwell CDC | True |
| OGG CDC | True |
| JSON | True |
JSON源可能缺少一些信息。例如,Ogg和Maxwell格式标准不包含字段类型;当你将JSON源写入FlinkPulsar接收器时,它将只保留数据和行类型,而丢弃其他信息。同步作业将尽力按如下方式处理该问题:
- 如果缺少字段类型,Paimon将默认使用“STRING”类型。
- 如果缺少数据库名或表名,你无法进行数据库同步,但仍可以进行表同步。
- 如果缺少主键,作业可能会创建无主键表。你可以在提交表同步作业时设置主键。
同步表
通过在Flink DataStream作业中使用PulsarSyncTableAction,或直接通过flink run,用户可以将Pulsar一个主题中的一个或多个表同步到一个Paimon表中。
要通过flink run使用此功能,运行以下Shell命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \pulsar_sync_table--warehouse <warehouse-path> \--database <database-name> \--table <table-name> \[--partition_keys <partition_keys>] \[--primary_keys <primary-keys>] \[--type_mapping to-string] \[--computed_column <'column-name=expr-name(args[, ...])'> [--computed_column ...]] \[--pulsar_conf <pulsar-source-conf> [--pulsar_conf <pulsar-source-conf> ...]] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]]| 配置 | 描述 |
|---|---|
| --warehouse | Paimon仓库的路径。 |
| --database | Paimon目录中的数据库名称。 |
| --table | Paimon表名。 |
| --partition_keys | Paimon表的分区键。如果有多个分区键,用逗号连接,例如“dt,hh,mm”。 |
| --primary_keys | Paimon表的主键。如果有多个主键,用逗号连接,例如“buyer_id,seller_id”。 |
| --type_mapping | 用于指定如何将MySQL数据类型映射到Paimon类型。 支持的选项: “tinyint1-not-bool”:将MySQL的TINYINT(1)映射为TINYINT而不是BOOLEAN。 “to-nullable”:忽略所有非空约束(主键除外)。这用于解决Flink无法接受MySQL的“ALTER TABLE ADD COLUMN column type NOT NULL DEFAULT x”操作的问题。 “to-string”:将所有MySQL类型映射为STRING。 “char-to-string”:将MySQL的CHAR(length)/VARCHAR(length)类型映射为STRING。 “longtext-to-bytes”:将MySQL的LONGTEXT类型映射为BYTES。 “bigint-unsigned-to-bigint”:将MySQL的BIGINT UNSIGNED、BIGINT UNSIGNED ZEROFILL、SERIAL映射为BIGINT。使用此选项时应确保不会发生溢出。 |
| --computed_column | 计算列的定义。参数字段来自Pulsar主题的表字段名。有关完整的配置列表,请参阅此处。 |
| --pulsar_conf | FlinkPulsar源的配置。每个配置应采用 |
| --catalog_conf | Paimon目录的配置。每个配置应采用“key = value”的格式指定。有关目录配置的完整列表,请参阅此处。 |
| --table_conf | Paimon表接收器的配置。每个配置应采用“key = value”的格式指定。有关表配置的完整列表,请参阅此处。 |
如果指定的Paimon表不存在,此操作将自动创建该表。其模式将从所有指定的Pulsar主题的表派生而来,它从主题中获取最早的非DDL数据解析模式。如果Paimon表已存在,将把它的模式与所有指定的Pulsar主题的表的模式进行比较。
示例1:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \pulsar_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--primary_keys pt,uid \--computed_column '_year=year(age)' \--pulsar_conf topic=order \--pulsar_conf value.format=canal-json \--pulsar_conf pulsar.client.serviceUrl=pulsar://127.0.0.1:6650 \--pulsar_conf pulsar.admin.adminUrl=http://127.0.0.1:8080 \--pulsar_conf pulsar.consumer.subscriptionName=paimon-tests \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4如果在启动同步作业时Pulsar主题不包含消息,则必须在提交作业前手动创建表。你可以仅定义分区键和主键,其余列将由同步作业添加。
注意:在这种情况下,你不应使用–partition_keys或–primary_keys,因为这些键在创建表时已定义且无法修改。此外,如果你指定了计算列,还应定义计算列使用的所有参数字段。
示例2:如果你想同步一个主键为id INT的表,并且想计算一个分区键part = date_format(create_time,yyyy-MM-dd),你可以先创建这样一个表(其他列可以省略):
CREATE TABLE test_db.test_table (id INT, -- primary keycreate_time TIMESTAMP, -- the argument of computed column partpart STRING, -- partition keyPRIMARY KEY (id, part) NOT ENFORCED
) PARTITIONED BY (part);然后你可以提交同步作业:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \pulsar_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--computed_column 'part=date_format(create_time,yyyy-MM-dd)' \... (other conf)示例3:对于一些追加数据(如日志数据),它可以被视为仅包含INSERT操作类型的特殊CDC数据,因此你可以使用format = json将此类数据同步到Paimon表。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \kafka_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--computed_column 'pt=date_format(event_tm, yyyyMMdd)' \--kafka_conf properties.bootstrap.servers=127.0.0.1:9020 \--kafka_conf topic=test_log \--kafka_conf properties.group.id=123456 \--kafka_conf value.format=json \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf sink.parallelism=4(此处示例3开头kafka_sync_table疑似错误,应为pulsar_sync_table)
同步数据库
通过在Flink DataStream作业中使用PulsarSyncDatabaseAction,或直接通过flink run,用户可以将多个主题或一个主题同步到一个Paimon数据库。
要通过flink run使用此功能,运行以下Shell命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \pulsar_sync_database--warehouse <warehouse-path> \--database <database-name> \[--table_prefix <paimon-table-prefix>] \[--table_suffix <paimon-table-suffix>] \[--including_tables <table-name|name-regular-expr>] \[--excluding_tables <table-name|name-regular-expr>] \[--type_mapping to-string] \[--partition_keys <partition_keys>] \[--primary_keys <primary-keys>] \[--pulsar_conf <pulsar-source-conf> [--pulsar_conf <pulsar-source-conf> ...]] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]]| 配置 | 描述 |
|---|---|
| --warehouse | Paimon仓库的路径。 |
| --database | Paimon目录中的数据库名称。 |
| --ignore_incompatible | 默认值为false,在这种情况下,如果MySQL表名在Paimon中存在且它们的模式不兼容,将抛出异常。你可以显式地将其指定为true以忽略不兼容的表和异常。 |
| --table_prefix | 要同步的所有Paimon表的前缀。例如,如果你希望所有同步的表都有“ods_”作为前缀,你可以指定“--table_prefix ods_”。 |
| --table_suffix | 要同步的所有Paimon表的后缀。用法与“--table_prefix”相同。 |
| --including_tables | 用于指定要同步哪些源表。必须使用' |
| --excluding_tables | 用于指定不同步哪些源表。用法与“--including_tables”相同。如果同时指定了“--excluding_tables”和“--including_tables”,“--excluding_tables”具有更高的优先级。 |
| --type_mapping | 用于指定如何将MySQL数据类型映射到Paimon类型。 支持的选项: “tinyint1-not-bool”:将MySQL的TINYINT(1)映射为TINYINT而不是BOOLEAN。 “to-nullable”:忽略所有非空约束(主键除外)。这用于解决Flink无法接受MySQL的“ALTER TABLE ADD COLUMN column type NOT NULL DEFAULT x”操作的问题。 “to-string”:将所有MySQL类型映射为STRING。 “char-to-string”:将MySQL的CHAR(length)/VARCHAR(length)类型映射为STRING。 “longtext-to-bytes”:将MySQL的LONGTEXT类型映射为BYTES。 “bigint-unsigned-to-bigint”:将MySQL的BIGINT UNSIGNED、BIGINT UNSIGNED ZEROFILL、SERIAL映射为BIGINT。使用此选项时应确保不会发生溢出。 |
| --partition_keys | Paimon表的分区键。如果有多个分区键,用逗号连接,例如“dt,hh,mm”。如果这些键不在源表中,接收器表将不设置分区键。 |
| --primary_keys | Paimon表的主键。如果有多个主键,用逗号连接,例如“buyer_id,seller_id”。如果这些键不在源表中,但源表有主键,接收器表将使用源表的主键。否则,接收器表将不设置主键。 |
| --pulsar_conf | FlinkPulsar源的配置。每个配置应采用 |
| --catalog_conf | Paimon目录的配置。每个配置应采用“key = value”的格式指定。有关目录配置的完整列表,请参阅此处。 |
| --table_conf | Paimon表接收器的配置。每个配置应采用“key = value”的格式指定。有关表配置的完整列表,请参阅此处。 |
只有具有主键的表才会被同步。
此操作将为所有表构建一个单一的组合接收器。对于每个要同步的Pulsar主题的表,如果相应的Paimon表不存在,此操作将自动创建该表,并且其模式将从所有指定的Pulsar主题的表派生而来。如果Paimon表已存在且其模式与从Pulsar记录解析的模式不同,此操作将尝试进行模式演进。
示例:
-
从一个Pulsar主题同步到Paimon数据库:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \pulsar_sync_database \--warehouse hdfs:///path/to/warehouse \--database test_db \--pulsar_conf topic=order \--pulsar_conf value.format=canal-json \--pulsar_conf pulsar.client.serviceUrl=pulsar://127.0.0.1:6650 \--pulsar_conf pulsar.admin.adminUrl=http://127.0.0.1:8080 \--pulsar_conf pulsar.consumer.subscriptionName=paimon-tests \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4-
从多个Pulsar主题同步到Paimon数据库:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \pulsar_sync_database \--warehouse hdfs:///path/to/warehouse \--database test_db \--pulsar_conf topic=order,logistic_order,user \--pulsar_conf value.format=canal-json \--pulsar_conf pulsar.client.serviceUrl=pulsar://127.0.0.1:6650 \--pulsar_conf pulsar.admin.adminUrl=http://127.0.0.1:8080 \--pulsar_conf pulsar.consumer.subscriptionName=paimon-tests \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4额外的Pulsar配置
有一些用于构建FlinkPulsar源的有用选项,但它们未在flink-pulsar-connector文档中提供。它们是:
| 键 | 默认值 | 类型 | 描述 |
|---|---|---|---|
| value.format | (none) | String | 定义用于编码值数据的格式标识符。 |
| topic | (none) | String | 从中读取数据的主题名称。它也支持通过分号分隔主题列表,如'topic-1;topic-2'。注意,“topic-pattern”和“topic”只能指定一个。 |
| topic-pattern | (none) | String | 要读取的主题名称模式的正则表达式。当作业开始运行时,所有名称与指定正则表达式匹配的主题都将被消费者订阅。注意,“topic-pattern”和“topic”只能指定一个。 |
| pulsar.startCursor.fromMessageId | EARLIEST | String | 使用单个消息的唯一标识符来定位起始位置。常见格式是三元组 'ledgerId,entryId,partitionIndex'。特别地,你可以将其设置为 EARLIEST (-1, -1, -1) 或 LATEST (Long.MAX_VALUE, Long.MAX_VALUE, -1)。 |
| pulsar.startCursor.fromPublishTime | (none) | Long | 使用消息发布时间来定位起始位置。 |
| pulsar.startCursor.fromMessageIdInclusive | true | Boolean | 是否包含给定的消息ID。此选项仅在消息ID不是EARLIEST或LATEST时有效。 |
| pulsar.stopCursor.atMessageId | (none) | String | 当消息ID等于或大于指定的消息ID时停止消费。等于指定消息ID的消息将不会被消费。常见格式是三元组 'ledgerId,entryId,partitionIndex'。特别地,你可以将其设置为LATEST (Long.MAX_VALUE, Long.MAX_VALUE, -1)。 |
| pulsar.stopCursor.afterMessageId | (none) | String | 当消息ID大于指定的消息ID时停止消费。等于指定消息ID的消息将被消费。常见格式是三元组 'ledgerId,entryId,partitionIndex'。特别地,你可以将其设置为LATEST (Long.MAX_VALUE, Long.MAX_VALUE, -1)。 |
| pulsar.stopCursor.atEventTime | (none) | Long | 当消息事件时间大于或等于指定的时间戳时停止消费。事件时间等于指定时间戳的消息将不会被消费。 |
| pulsar.stopCursor.afterEventTime | (none) | Long | 当消息事件时间大于指定的时间戳时停止消费。事件时间等于指定时间戳的消息将被消费。 |
| pulsar.source.unbounded | true | Boolean | 指定流的有界性。 |
| schema.registry.url | (none) | String | 当配置“value.format=debezium-avro”时,这需要使用Confluence模式注册表模型进行Apache Avro序列化,你需要提供模式注册表URL。 |
拓展:
Apache Pulsar:是一个开源的分布式消息流平台,旨在为现代云原生应用程序提供高性能、低延迟和可扩展性的消息传递解决方案。与Kafka类似,Pulsar 也支持发布-订阅模型,但它在架构设计上有一些独特之处,例如采用分层存储架构,将消息存储和元数据管理分离,这使得 Pulsar 在处理大规模数据和高并发场景时表现出色。常用于构建实时数据管道、微服务之间的异步通信以及事件驱动的应用程序等。
Flink-Pulsar 连接器:
flink-connector-pulsar-*.jar是 Apache Flink 与 Apache Pulsar 集成的关键组件。它允许 Flink 作业从 Pulsar 主题中读取数据,并将处理后的数据写回到 Pulsar 主题,从而实现数据在 Flink 和 Pulsar 之间的高效交互。在 CDC 场景下,该连接器负责从 Pulsar 获取包含变更数据的消息,并将其传递给 Flink 进行处理,例如解析消息并同步到 Paimon 表。CDC 格式在 Pulsar 中的应用:Canal Json、Debezium Json 等格式在 Pulsar 的 CDC 场景中用于编码和传输数据库的变更数据。这些格式各自有其特点和适用场景,例如 Debezium Json 通常会包含丰富的元数据信息,方便在数据处理过程中理解数据的结构和变化,而 Canal Json 则在与基于 Canal 的数据捕获系统集成时具有良好的兼容性。
Pulsar 配置参数的作用: -
pulsar.client.serviceUrl和pulsar.admin.adminUrl分别指定了 Pulsar 客户端连接服务的 URL 和管理接口的 URL,它们是 Flink 与 Pulsar 建立连接的重要配置。 -pulsar.consumer.subscriptionName定义了消费者订阅的名称,通过设置不同的订阅名称,可以实现不同的消费策略,例如独占消费、共享消费等。 -与消息起始和停止位置相关的配置参数,如pulsar.startCursor.fromMessageId、pulsar.stopCursor.atMessageId等,为用户提供了精确控制消息消费范围的能力。这在数据恢复、数据重放以及处理特定时间段内的数据等场景中非常有用。
过期分区(Expiring Partitions)
在创建分区表时,你可以设置partition.expiration-time。Paimon 流接收器会定期检查分区状态,并根据时间删除过期分区。
如何确定一个分区是否过期:在创建分区表时,你可以设置partition.expiration-strategy,该策略决定了如何提取分区时间,并将其与当前时间进行比较,以查看存活时间是否超过partition.expiration-time。支持的过期策略值有:
-
values-time:该策略将从分区值中提取的时间与当前时间进行比较,此为默认策略。 -
update-time:该策略将分区的最后更新时间与当前时间进行比较。此策略适用于以下场景: -你的分区值不是日期格式。 -你只想保留最近 n 天/月/年更新过的数据。 -数据初始化时导入了大量历史数据。
注意:分区过期后,会被逻辑删除,最新的快照无法查询其数据。但文件系统中的文件不会立即被物理删除,这取决于相应快照何时过期。请参阅“过期快照”。
单分区字段示例:
-
values-time策略:
CREATE TABLE t (...) PARTITIONED BY (dt) WITH ('partition.expiration-time' = '7 d','partition.expiration-check-interval' = '1 d','partition.timestamp-formatter' = 'yyyyMMdd' -- this is required in `values-time` strategy.
);
-- Let's say now the date is 2024-07-09,so before the date of 2024-07-02 will expire.
insert into t values('pk', '2024-07-01');-- An example for multiple partition fields
CREATE TABLE t (...) PARTITIONED BY (other_key, dt) WITH ('partition.expiration-time' = '7 d','partition.expiration-check-interval' = '1 d','partition.timestamp-formatter' = 'yyyyMMdd','partition.timestamp-pattern' = '$dt'
);-
update-time策略:
CREATE TABLE t (...) PARTITIONED BY (dt) WITH ('partition.expiration-time' = '7 d','partition.expiration-check-interval' = '1 d','partition.expiration-strategy' = 'update-time'
);-- The last update time of the partition is now, so it will not expire.
insert into t values('pk', '2024-01-01');
-- Support non-date formatted partition.
insert into t values('pk', 'par-1');
更多选项:
| 选项 | 默认值 | 类型 | 描述 |
|---|---|---|---|
|
|
| String | 指定分区过期的过期策略。可能的值有: |
|
|
| Duration | 分区过期的检查间隔。 |
|
| (none) | Duration | 分区的过期间隔。如果分区的存在时间超过此值,该分区将过期。分区时间从分区值中提取。 |
|
| (none) | String | 用于将字符串格式化为时间戳的格式化器。它可以与 |
|
| (none) | String | 你可以指定一个模式从分区中获取时间戳。格式化模式由 |
|
|
| Boolean | 在批处理模式或有界流作业完成后,是否检查分区过期。 |
拓展:
分区过期机制在大数据存储中的意义:在大数据处理场景中,数据量通常会随着时间不断增长。通过设置分区过期机制,可以自动清理不再需要的历史数据分区,从而有效控制存储成本,同时提升查询性能。例如,在日志数据存储中,老的日志分区可能不再被频繁查询,将其过期删除可以减少存储资源占用。
values-time策略实现原理:values-time策略依赖于从分区值中提取时间信息。这要求分区值必须以某种可解析的时间格式存储,通过partition.timestamp-formatter和partition.timestamp-pattern配合,将分区值解析为时间戳,再与当前时间比较以判断分区是否过期。这种策略适用于分区值天然带有时间属性且以时间为维度进行过期管理的场景,如按日期分区的销售数据。
update-time策略应用场景拓展:除了上述提到的场景,update-time策略在数据仓库环境中也很有用。例如,某些维度表的数据更新频率较低,但数据量较大。通过update-time策略,只保留最近更新的分区,可以确保数据仓库中的维度数据是最新且有效的,避免查询到陈旧数据。同时,在数据导入大量历史数据后,使用该策略可以逐步清理未更新的旧数据分区,优化存储结构。
partition.expiration-check-interval对系统性能的影响:该参数决定了检查分区过期的频率。如果设置过短,系统会频繁进行过期检查,增加系统开销;若设置过长,可能导致过期分区不能及时被清理,占用过多存储资源。因此,需要根据数据的更新频率和存储资源情况,合理调整该参数,以平衡系统性能和存储成本。
存储过程(Procedures)
Flink 1.18及更高版本支持调用语句(Call Statements),这使得通过编写SQL而不是提交Flink作业来操作Paimon表的数据和元数据变得更加容易。
在1.18版本中,存储过程仅支持按位置传递参数。你必须按顺序传递所有参数,如果你不想传递某些参数,必须使用空字符串 '' 作为占位符。例如,如果你想以并行度4压缩表default.t,但不想指定分区和排序策略,调用语句应该是: CALL sys.compact('default.t', '', '', '', 'sink.parallelism=4')
在更高版本中,存储过程支持按名称传递参数。你可以按任意顺序传递参数,并且可以省略任何可选参数。对于上述示例,调用语句为: CALL sys.compact(table => 'default.t', options => 'sink.parallelism=4')
指定分区:我们使用字符串来表示分区过滤器。“,” 表示 “AND”,“;” 表示 “OR”。例如,如果你想指定两个分区date = 01和date = 02,你需要写'date = 01;date = 02';如果你想指定一个分区date = 01且day = 01,你需要写'date = 01,day = 01'。
表选项语法:我们使用字符串来表示表选项。格式为 'key1 = value1,key2 = value2…'。
以下是所有可用的存储过程列表:
| 存储过程名称 | 用法 | 解释 | 示例 |
|---|---|---|---|
| compact |
| 用于压缩表。参数: | -- 使用分区过滤器 |
| compact_database |
| 用于压缩数据库。参数: | `CALL sys.compact_database('db1 |
| create_tag | -- 基于指定的快照 | 基于给定的快照创建一个标签。参数: |
|
| create_tag_from_timestamp | -- 从提交时间大于指定时间戳的第一个快照创建一个标签。 | 基于给定的时间戳创建一个标签。参数: | -- 对于Flink 1.18 |
| create_tag_from_watermark | -- 从水印大于指定时间戳的第一个快照创建一个标签。 | 基于给定的水印时间戳创建一个标签。参数: | -- 对于Flink 1.18 |
| delete_tag |
| 删除一个标签。参数: |
|
| merge_into |
| 执行 “MERGE INTO” 语法。有关参数的详细信息,请参阅merge_into操作。 | -- 对于匹配的订单行, -- 增加价格, -- 如果没有匹配项, -- 从源表插入订单 |
| remove_orphan_files |
| 删除孤立的数据文件和元数据文件。参数: |
|
| reset_consumer | -- 在消费者中重置新的下一个快照ID | 重置或删除消费者。参数: |
|
| rollback_to | -- 回滚到一个快照 | 回滚到目标表的特定版本。参数: |
|
| expire_snapshots | -- 对于Flink 1.18 | 过期快照。参数: | -- 对于Flink 1.18 |
| expire_partitions |
| 过期分区。参数: | -- 对于Flink 1.18 |
| repair | -- 修复目录中的所有数据库和表 | 将文件系统中的信息同步到元存储。参数: 空:目录中的所有数据库和表。 |
|
| rewrite_file_index |
| 重写表的文件索引。参数: | -- 重写整个表的文件索引 |
| create_branch | -- 基于指定的标签 | 基于给定的标签创建一个分支,或者仅创建空分支。参数: |
|
| delete_branch |
| 删除一个分支。参数: |
|
| fast_forward |
| 将一个分支快速合并到主分支。参数: |
|
拓展:
Flink Call Statements:Flink从1.18版本引入对Call Statements的支持,这极大地增强了Flink SQL的功能。通过存储过程,用户可以直接在SQL层面完成复杂的数据和元数据操作,无需编写复杂的Java或Scala代码来提交Flink作业。这使得数据工程师和分析师能够更便捷地与Paimon表进行交互,提升了工作效率。例如,在数据仓库场景中,定期压缩表(compact操作)以优化存储和查询性能,可以通过简单的SQL调用实现,而无需重新部署Flink作业。
表压缩(compact):表压缩是提升Paimon表性能的重要操作。通过
compact存储过程,可以对表数据进行整理和优化。不同的排序策略(order_strategy)如zorder、hilbert等,能够以特定方式对数据进行排序,从而在查询时提高数据扫描效率。例如,在分析按时间序列存储的数据时,使用zorder策略对时间列进行排序,可以使查询特定时间范围的数据更加高效。此外,通过指定分区进行压缩,能够针对性地处理特定分区的数据,减少不必要的计算资源消耗。标签(tag)和分支(branch)管理:标签和分支是Paimon中版本控制和数据管理的重要手段。标签允许用户为特定的快照(snapshot)命名,方便快速定位和回滚到某个特定版本的数据状态。而分支则提供了一种并行的数据演进路径,例如在进行数据实验或开发新功能时,可以基于某个标签创建分支,在分支上进行操作而不影响主数据分支。通过
create_tag、delete_tag、create_branch和delete_branch等存储过程,用户能够灵活地管理标签和分支,确保数据的可追溯性和开发过程的灵活性。MERGE INTO操作:
merge_into存储过程实现了SQL中强大的MERGE INTO语法。这在数据集成和ETL(Extract,Transform,Load)过程中非常有用,例如将源表数据根据特定条件合并到目标表中。它可以同时处理匹配行的更新(matchedUpsertCondition)和不匹配行的插入(notMatchedInsertCondition),避免了传统方式中需要分别编写插入和更新语句的繁琐过程,提高了数据处理的原子性和效率。孤儿文件清理(remove_orphan_files):在数据处理过程中,由于各种原因(如任务失败、数据迁移等)可能会产生孤儿文件,即不再被表元数据引用的数据文件或元数据文件。这些文件不仅占用存储资源,还可能导致数据不一致。
remove_orphan_files存储过程提供了一种清理这些孤儿文件的机制。通过设置olderThan参数,可以控制只删除特定时间之前产生的孤儿文件,避免误删新生成的文件。而dryRun参数则提供了一种预览模式,方便用户在实际删除文件之前查看哪些文件将被删除。分区和快照管理:
expire_partitions和expire_snapshots存储过程分别用于管理分区和快照的过期。在大数据存储中,随着时间推移,旧的分区和快照可能不再需要,通过设置合适的过期策略,可以自动清理这些不再使用的数据,释放存储资源。例如,对于按时间分区的表,通过expire_partitions设置过期时间,可以定期删除旧的时间分区。而expire_snapshots则可以根据保留的最大或最小快照数量,以及时间条件,删除不再需要的快照版本。
动作JAR(Action Jars)
在启动Flink本地集群后,你可以使用以下命令执行动作JAR。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \<action><args>以下命令用于压缩表。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \compact \--path <TABLE_PATH>合并到表
Paimon支持通过flink run提交merge_into作业来实现“MERGE INTO”。
重要的表属性设置:
- 只有主键表支持此功能。
- 此动作不会生成UPDATE_BEFORE,因此不建议设置
'changelog-producer' = 'input'。
该设计参考了如下语法:
MERGE INTO target-tableUSING source_table | source-expr AS source-aliasON merge-conditionWHEN MATCHED [AND matched-condition]THEN UPDATE SET xxxWHEN MATCHED [AND matched-condition]THEN DELETEWHEN NOT MATCHED [AND not_matched_condition]THEN INSERT VALUES (xxx)WHEN NOT MATCHED BY SOURCE [AND not-matched-by-source-condition]THEN UPDATE SET xxxWHEN NOT MATCHED BY SOURCE [AND not-matched-by-source-condition]THEN DELETEmerge_into动作使用“upsert”语义而非“update”,这意味着如果行存在,则执行更新;否则执行插入。例如,对于非主键表,你可以更新每一列,但对于主键表,如果你想更新主键,则必须插入一个主键与表中现有行不同的新行。在这种情况下,“upsert”很有用。
运行以下命令为表提交一个merge_into作业。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \merge_into \--warehouse <warehouse-path> \--database <database-name> \--table <target-table> \[--target_as <target-table-alias>] \--source_table <source_table-name> \[--source_sql <sql> ...]\--on <merge-condition> \--merge_actions <matched-upsert,matched-delete,not-matched-insert,not-matched-by-source-upsert,not-matched-by-source-delete> \--matched_upsert_condition <matched-condition> \--matched_upsert_set <upsert-changes> \--matched_delete_condition <matched-condition> \--not_matched_insert_condition <not-matched-condition> \--not_matched_insert_values <insert-values> \--not_matched_by_source_upsert_condition <not-matched-by-source-condition> \--not_matched_by_source_upsert_set <not-matched-upsert-changes> \--not_matched_by_source_delete_condition <not-matched-by-source-condition> \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]]You can pass sqls by '--source_sql <sql> [, --source_sql <sql> ...]' to config environment and create source table at runtime.-- Examples:
-- Find all orders mentioned in the source table, then mark as important if the price is above 100
-- or delete if the price is under 10.
./flink run \/path/to/paimon-flink-action-0.9.0.jar \merge_into \--warehouse <warehouse-path> \--database <database-name> \--table T \--source_table S \--on "T.id = S.order_id" \--merge_actions \matched-upsert,matched-delete \--matched_upsert_condition "T.price > 100" \--matched_upsert_set "mark = 'important'" \--matched_delete_condition "T.price < 10" -- For matched order rows, increase the price, and if there is no match, insert the order from the
-- source table:
./flink run \/path/to/paimon-flink-action-0.9.0.jar \merge_into \--warehouse <warehouse-path> \--database <database-name> \--table T \--source_table S \--on "T.id = S.order_id" \--merge_actions \matched-upsert,not-matched-insert \--matched_upsert_set "price = T.price + 20" \--not_matched_insert_values * -- For not matched by source order rows (which are in the target table and does not match any row in the
-- source table based on the merge-condition), decrease the price or if the mark is 'trivial', delete them:
./flink run \/path/to/paimon-flink-action-0.9.0.jar \merge_into \--warehouse <warehouse-path> \--database <database-name> \--table T \--source_table S \--on "T.id = S.order_id" \--merge_actions \not-matched-by-source-upsert,not-matched-by-source-delete \--not_matched_by_source_upsert_condition "T.mark <> 'trivial'" \--not_matched_by_source_upsert_set "price = T.price - 20" \--not_matched_by_source_delete_condition "T.mark = 'trivial'"-- A --source_sql example:
-- Create a temporary view S in new catalog and use it as source table
./flink run \/path/to/paimon-flink-action-0.9.0.jar \merge_into \--warehouse <warehouse-path> \--database <database-name> \--table T \--source_sql "CREATE CATALOG test_cat WITH (...)" \--source_sql "CREATE TEMPORARY VIEW test_cat.`default`.S AS SELECT order_id, price, 'important' FROM important_order" \--source_table test_cat.default.S \--on "T.id = S.order_id" \--merge_actions not-matched-insert\--not_matched_insert_values *“matched”术语解释:
- matched:更改的行来自目标表,并且每行都可以基于合并条件和可选的匹配条件与源表行匹配(源 ∩ 目标)。
- not matched:更改的行来自源表,并且基于合并条件和可选的不匹配条件,所有行都无法与目标表中的任何行匹配(源-目标)。
- not matched by source:更改的行来自目标表,并且基于合并条件和可选的源不匹配条件,所有行都无法与源表中的任何行匹配(目标-源)。
参数格式:
- matched_upsert_changes:
col = <source_table>.col | expression [, …](表示用给定值设置<target_table>.col。不要在col前添加<target_table>.)。特别地,你可以使用'*'用所有源列设置列(要求目标表的模式与源表相同)。 - not_matched_upsert_changes与
matched_upsert_changes类似,但你不能引用源表的列或使用'*'。 - insert_values:
col1, col2, …, col_end。必须指定所有列的值。对于每一列,你可以引用<source_table>.col或使用表达式。特别地,你可以使用'*'用所有源列插入(要求目标表的模式与源表相同)。 - not_matched_condition不能使用目标表的列来构造条件表达式。
- not_matched_by_source_condition不能使用源表的列来构造条件表达式。
1.目标别名不能与已存在的表名重复。
2.如果源表不在当前目录和当前数据库中,则源表名必须是限定的(如果创建了新目录,则为 database.table 或 catalog.database.table)。例如:
(1) 如果源表 “my_source” 在 “my_db” 中,对其进行限定:
--source_table “my_db.my_source”
(2) SQL 示例:
当 SQL 语句更改了当前目录和数据库时,源表名无需限定:
--source_sql “CREATE CATALOG my_cat WITH (…)"
--source_sql “USE CATALOG my_cat”
--source_sql “CREATE DATABASE my_db”
--source_sql “USE my_db”
--source_sql “CREATE TABLE S …"
--source_table S
但在以下情况下必须对其进行限定:
--source_sql “CREATE CATALOG my_cat WITH (…)"
--source_sql “CREATE TABLE my_cat.default.S …"
--source_table my_cat.default.S
在以下参数中,你可以仅使用 “S” 作为源表名。
3.必须至少指定一个合并操作。
4.如果同时存在匹配时插入(matched-upsert)和匹配时删除(matched-delete)操作,它们的条件也都必须存在(对于不匹配源时插入(not-matched-by-source-upsert)和不匹配源时删除(not-matched-by-source-delete)也是如此)。否则,所有条件都是可选的。
5.所有条件、设置更改和值都应使用 Flink SQL 语法。为确保整个命令在 Shell 中正常运行,请用双引号将它们引起来以转义空格,并使用反斜杠 “\” 转义语句中的特殊字符。例如:
--source_sql “CREATE TABLE T (k INT) WITH (‘special-key’ = ‘123!')”
有关merge_into的更多信息,请查看:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \merge_into --help从表中删除
在Flink 1.16及更早版本中,Paimon仅支持通过flink run提交delete作业来删除记录。
运行以下命令为表提交一个delete作业。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \delete \--warehouse <warehouse-path> \--database <database-name> \--table <table-name> \--where <filter_spec> \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]]filter_spec is equal to the 'WHERE' clause in SQL DELETE statement. Examples:age >= 18 AND age <= 60animal <> 'cat'id > (SELECT count(*) FROM employee)有关delete的更多信息,请查看:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \delete --help删除分区
运行以下命令为表提交一个drop_partition作业。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \drop_partition \--warehouse <warehouse-path> \--database <database-name> \--table <table-name> \[--partition <partition_spec> [--partition <partition_spec> ...]] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]]partition_spec:
key1=value1,key2=value2...有关drop_partition的更多信息,请查看:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \drop_partition --help重写文件索引
运行以下命令为表提交一个rewrite_file_index作业。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \rewrite_file_index \--warehouse <warehouse-path> \--identifier <database.table> \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]]有关rewrite_file_index的更多信息,请查看:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \rewrite_file_index --help拓展:
MERGE INTO操作在数据处理中的应用:MERGE INTO操作在数据集成场景中极为常见,例如将来自不同数据源的数据合并到数据仓库的目标表中。通过Paimon的
merge_into作业,能够实现复杂的业务逻辑,如根据业务规则对匹配和不匹配的数据进行不同处理。在电商数据处理中,将实时订单数据与历史订单表进行合并时,可对已存在的订单更新其状态或金额等信息,对新订单则插入到表中,确保数据的完整性和实时性。DELETE操作的优化考量:在大数据环境下,从表中删除数据需要谨慎操作。通过
delete作业,用户可以基于复杂的条件过滤来删除数据。然而,在执行删除操作时,需要考虑对系统性能和存储的影响。例如,如果删除的数据量较大,可能会导致存储碎片,影响后续的查询性能。因此,在实际应用中,可能需要结合数据的使用频率、存储策略等因素,合理安排删除操作的时机和条件。DROP PARTITION操作与存储管理:
drop_partition操作对于管理分区表的存储非常重要。在数据按时间分区存储的场景下,随着时间推移,旧的分区数据可能不再需要,通过删除这些分区,可以释放大量的存储资源。但在执行此操作时,要确保不会影响到依赖这些分区数据的业务流程,如某些历史数据分析任务可能仍需要访问旧分区数据。REWRITE FILE INDEX操作与查询性能:
rewrite_file_index作业主要用于优化表的文件索引结构。文件索引对于查询性能至关重要,当表数据发生大量的插入、删除或更新操作后,文件索引可能变得碎片化或不准确,从而影响查询效率。通过重写文件索引,可以重新组织索引结构,提高查询时的数据定位速度,进而提升整体查询性能。
保存点(Savepoint)
Paimon有自己的快照管理机制,这可能会与Flink的检查点管理产生冲突,导致从保存点恢复时出现异常(不过不用担心,这不会造成存储损坏)。
建议你使用以下方法进行保存点操作:
-
使用Flink的带保存点停止(Stop with savepoint)功能。
-
将Paimon标签与Flink保存点结合使用,并在从保存点恢复之前回滚到指定标签。
带保存点停止(Stop with savepoint)
Flink的此功能可确保最后一个检查点得到完全处理,这意味着不会再有未提交的元数据残留。这种方式非常安全,因此我们推荐使用此功能来停止和启动作业。
保存点与标签结合(Tag with Savepoint)
在Flink中,我们可能从Kafka消费数据,然后写入Paimon。由于Flink的检查点仅保留有限数量,我们会在特定时间(如代码升级、数据更新等)触发保存点,以确保状态能够保留更长时间,从而使作业可以增量恢复。
Paimon的快照与Flink的检查点类似,两者都会自动过期,但Paimon的标签功能允许快照长时间保留。因此,我们可以结合Paimon的标签和Flink的保存点这两个功能,实现作业从指定保存点的增量恢复。
从Flink 1.15开始,中间保存点(除使用stop-with-savepoint创建的保存点之外的其他保存点)不用于恢复,并且不会提交任何副作用。
对于使用stop-with-savepoint创建的保存点,会自动创建标签。对于其他保存点,将在下一个检查点成功后创建标签。
步骤1:启用为保存点自动创建标签功能
你可以将sink.savepoint.auto-tag设置为true,以启用为保存点自动创建标签的功能。
步骤2:触发保存点
你可以参考flink savepoint 文档,了解如何配置和触发保存点。
步骤3:选择与保存点对应的标签
与保存点对应的标签将以savepoint-${savepointID}的形式命名。你可以参考标签表进行查询。
步骤4:回滚Paimon表
将Paimon表回滚到指定标签。
步骤5:从保存点重启
你可以参考此处,了解如何从指定保存点重启。
拓展:
Flink保存点与检查点的区别:Flink的检查点是一种定期进行的轻量级状态备份,主要用于故障恢复,确保作业在发生故障时能够从最近的检查点恢复执行,减少数据丢失。而保存点是用户手动触发的一种特殊的检查点,通常用于计划内的作业暂停、迁移或升级等场景。保存点可以长时间保留,并且包含作业的完整状态,包括所有算子的状态和数据流的位置等信息。在大数据处理中,例如在进行集群升级时,使用保存点可以安全地停止作业,升级完成后从保存点恢复作业,保证数据处理的连续性。
Paimon快照与Flink检查点冲突的原因:Paimon的快照管理和Flink的检查点管理在数据一致性和状态管理的实现机制上存在差异。Paimon的快照主要关注表数据的版本管理和元数据一致性,而Flink的检查点更侧重于作业执行状态的恢复。当从保存点恢复时,Flink期望作业的状态与保存点创建时完全一致,但Paimon的快照管理可能导致表的元数据状态与Flink预期的不一致,从而引发异常。例如,Paimon可能在Flink保存点创建后对表结构或数据进行了一些内部调整,而Flink在恢复时未正确处理这些变化。
结合Paimon标签与Flink保存点的优势:通过结合Paimon的标签和Flink的保存点,能够实现更灵活和可靠的作业恢复策略。Paimon的标签可以长期保留特定的快照版本,方便用户在需要时准确回滚到某个特定的数据状态。而Flink的保存点则提供了作业执行状态的完整备份。在实际应用中,比如在进行数据处理逻辑更新时,先触发Flink保存点并结合Paimon标签记录当前数据状态,更新完成后,如果出现问题,可以通过回滚Paimon表到指定标签,再从保存点重启作业,确保作业恢复到更新前的准确状态,同时避免了Paimon快照与Flink检查点冲突带来的问题。