【RAGFlow代码详解-11】知识库管理
系统概述
知识库管理系统通过多层运行,为管理文档集合及其相关元数据、嵌入和知识图谱提供了全面的解决方案。
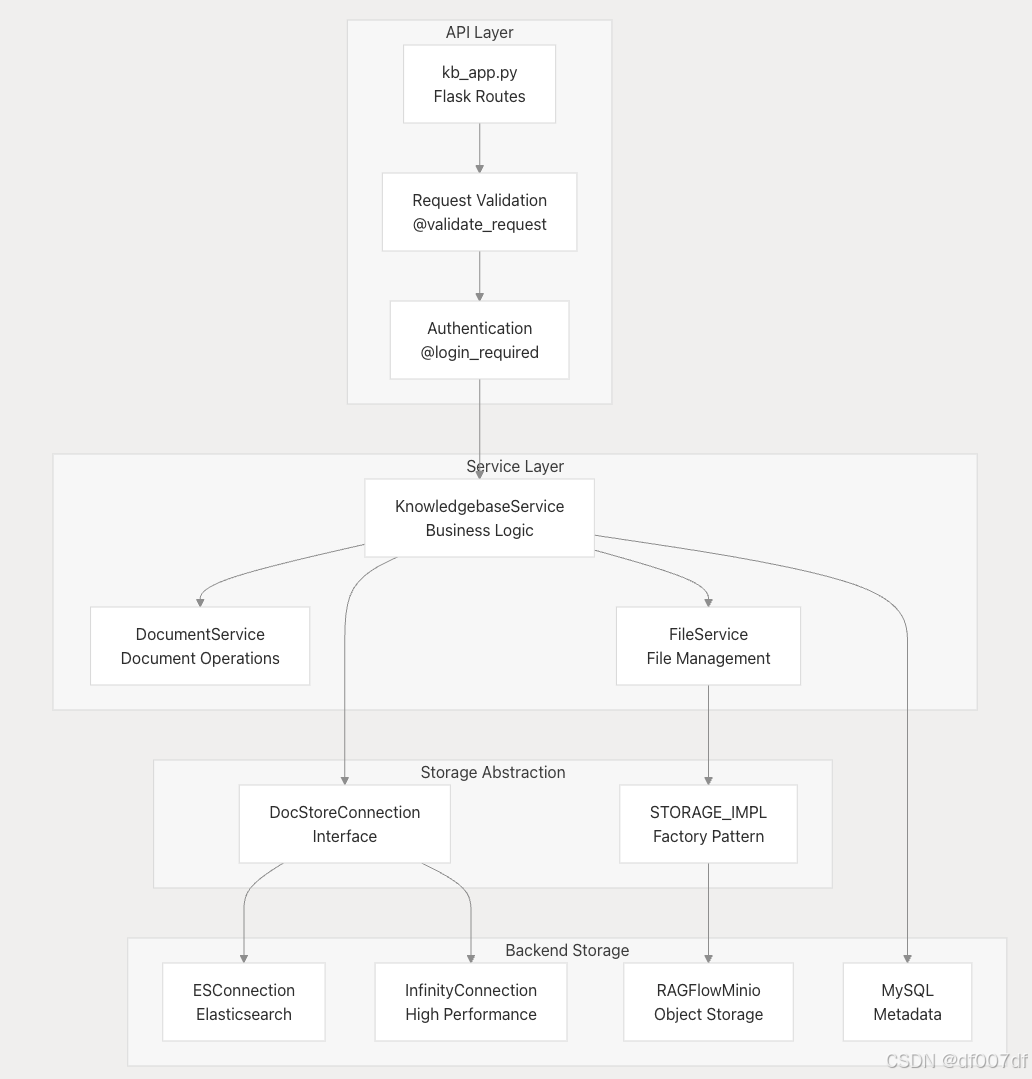
核心业务
知识库 CRUD 作
该系统通过 KnowledgebaseService 类和 HTTP API 端点提供全面的 CRUD 作。
创建过程
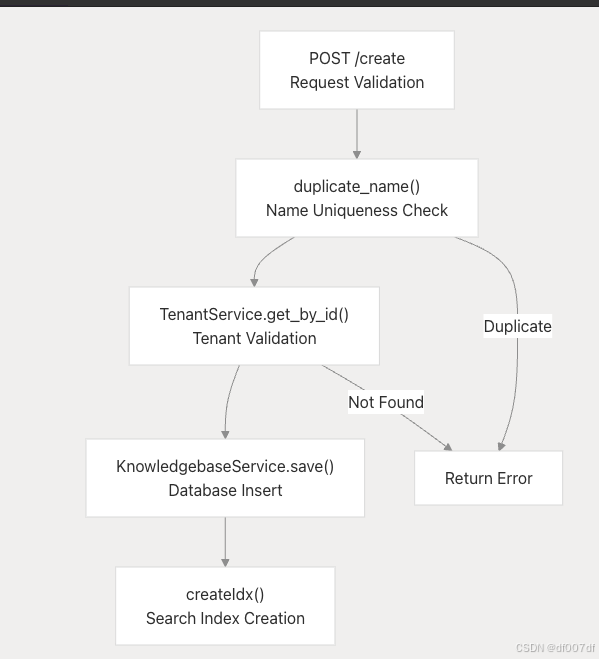
创建过程包括:
- 名称验证 :使用 duplicate_name() 函数确保租户范围内的唯一名称
- 租户验证 :验证租户是否存在并检索嵌入模型 ID
- 数据库持久性 :通过生成 UUID 保存知识库元数据
- 索引创建 :在配置的文档存储后端创建搜索索引
更新作
知识库更新支持修改元数据、解析器配置和排名参数:
# Key update validations from kb_app.py:79-136
@validate_request("kb_id", "name", "description", "parser_id")
@not_allowed_parameters("id", "tenant_id", "created_by", "create_time", "update_time")
def update():# PageRank field updates require special handlingif kb.pagerank != req.get("pagerank", 0):if req.get("pagerank", 0) > 0:settings.docStoreConn.update({"kb_id": kb.id}, {PAGERANK_FLD: req["pagerank"]})else:settings.docStoreConn.update({"exists": PAGERANK_FLD}, {"remove": PAGERANK_FLD})
文档存储集成
系统通过 DocStoreConnection 接口抽象存储作,支持多个后端。
存储后端架构
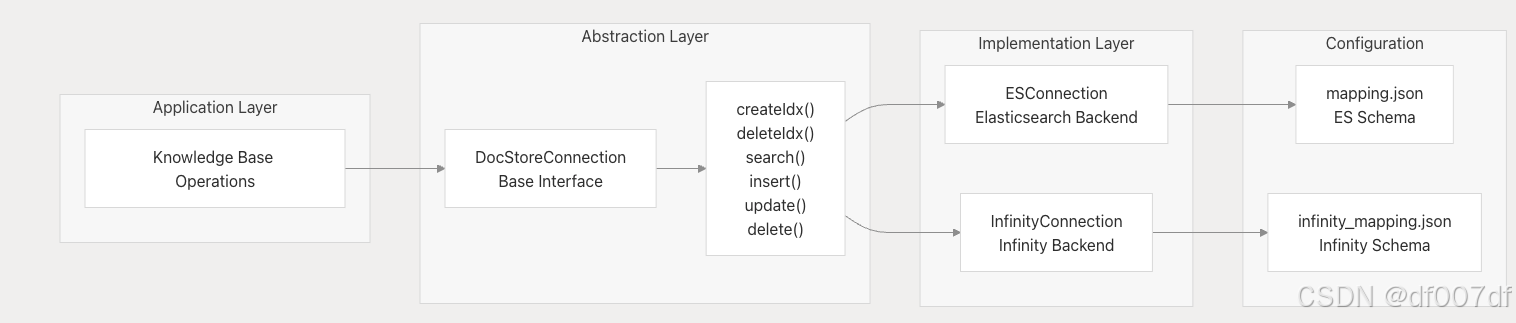
后端差异
| 操作 | 弹性搜索 | 无限 |
|---|---|---|
| 索引创建 | IndicesClient.create() 和映射 | create_table() 与模式 |
| 数据存储 | 使用 JSON 文档进行批量作 | 基于 DataFrame 的作 |
| 矢量搜索 | 具有余弦相似度的 KNN | 具有可配置指标的 HNSW 索引 |
| 全文搜索 | 使用分析器查询 DSL | 带有分析器的全文筛选器 |
| Schema管理 | 动态模板 | Column-based schema with migration |
访问控制和权限
系统实现权限继承的多租户访问控制。
权限模型
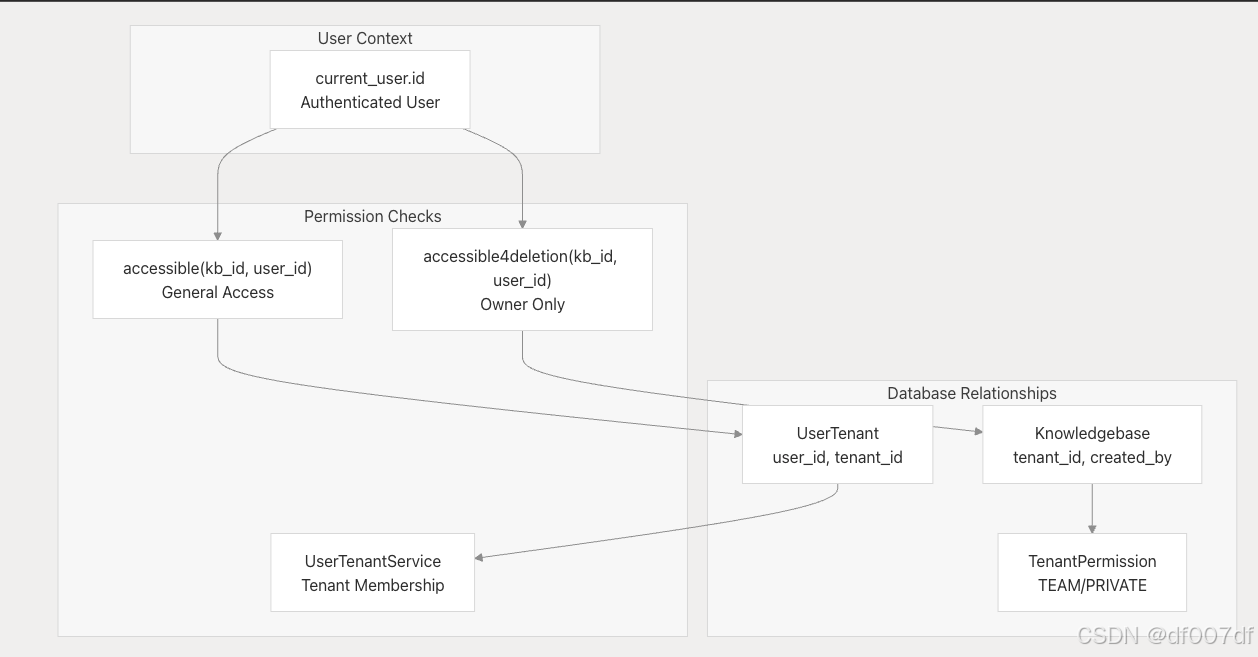
访问控制实施
系统使用两种主要的访问控制方法:
- accessible(kb_id, user_id):检查用户是否可以通过租户成员身份读取/修改知识库
- accessible4deletion(kb_id, user_id) :将删除限制为仅知识库创建者
知识图谱集成
知识库通过 GraphRAG 系统支持知识图谱功能,以增强语义搜索。
知识图谱作
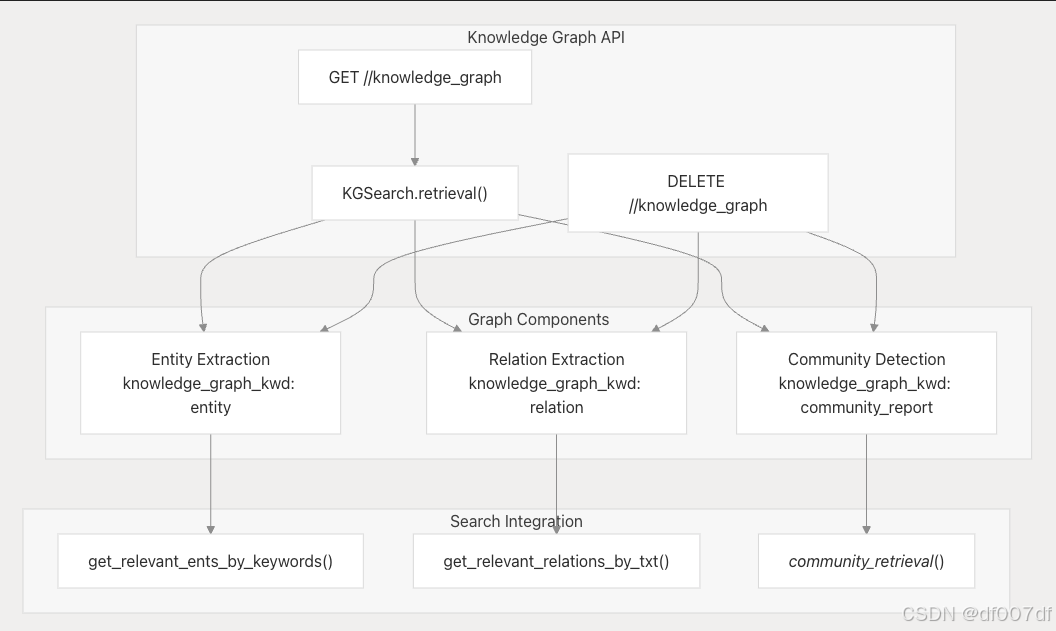
图数据结构
知识图谱数据使用特定字段映射存储:
| 田 | 目的 | 存储格式 |
|---|---|---|
| knowledge_graph_kwd | 组件类型标识符 | “实体”、“ 关系”、“community_report” |
| entity_kwd | 实体标识符 | 带有空格分析器的关键字数组 |
| from_entity_kwd/to_entity_kwd | 关系端点 | 关系映射的关键字对 |
| content_with_weight | 结构化内容 | 带有描述和权重的 JSON |
| rank_flt | PageRank 分数 | 实体重要性的浮点值 |
标签管理系统
知识库支持用于文档组织和筛选的分层标记管理。
标签作
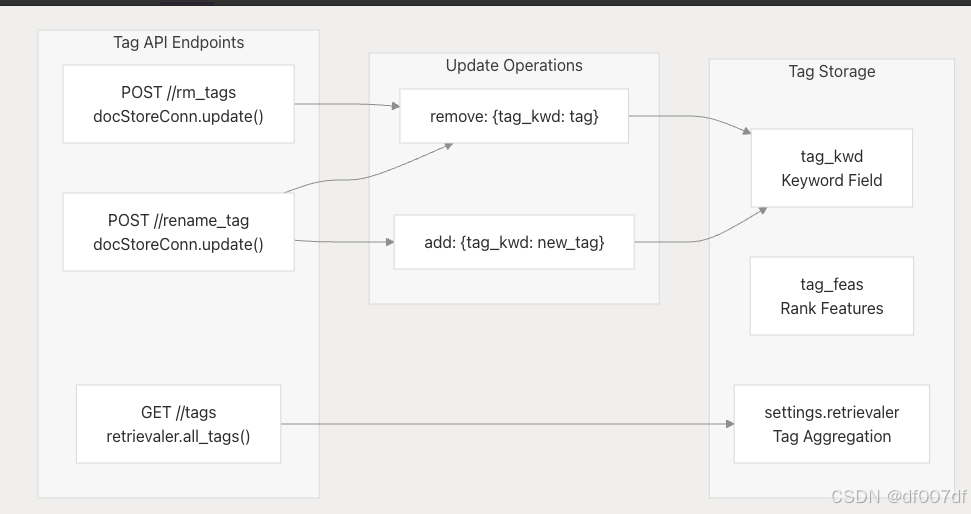
解析器配置管理
知识库通过 parser_config 字段维护解析器配置,支持动态文档处理参数。
配置结构
# Parser configuration update mechanism from knowledgebase_service.py:244-270
def update_parser_config(cls, id, config):def dfs_update(old, new):# Deep merge of nested configurationfor k, v in new.items():if isinstance(v, dict):assert isinstance(old[k], dict)dfs_update(old[k], v)elif isinstance(v, list):old[k] = list(set(old[k] + v)) # Merge unique valueselse:old[k] = v现场映射管理
系统支持文档元数据的自定义字段映射:
- get_field_map(ids): 检索跨多个知识库的字段映射
- delete_field_map(id): 删除字段映射配置
- 字段映射继承 :可以跨知识库层次结构合并配置
存储后端配置
系统通过定义模式映射的配置文件支持多个存储后端。
架构映射结构
Elasticsearch 映射
Elasticsearch 后端使用动态模板进行字段类型推断:
{"mappings": {"dynamic_templates": [{"int": {"match": "*_int", "mapping": {"type": "integer"}},"kwd": {"match": "*_kwd", "mapping": {"type": "keyword"}},"dense_vector": {"match": "*_1024_vec", "mapping": {"type": "dense_vector", "dims": 1024}}}]}
}
无限模式
Infinity 后端使用显式列定义:
{"id": {"type": "varchar", "default": ""},"content_with_weight": {"type": "varchar", "default": ""},"q_1024_vec": {"type": "vector,1024,float"}
}