spark数据缓存机制
文章目录
- 1.哪种数据需要被缓存
- 2.缓存数据的执行计划
- 3.缓存级别
- 3.1 缓存级别分类
- 3.2 MEMORY_ONLY
- 3.3 MEMORY_AND_DISK/MEMORY_AND_DISK_SER
- 4.缓存数据的写入方法
- 4.1 persist的执行时机
- 4.2 缓存原理
- 5.缓存数据的读取方法
- 6.缓存数据的替换和回收
- 6.1 缓存回收和替换的应用场景
- 6.2 缓存替换
- 6.3 缓存回收
1.哪种数据需要被缓存
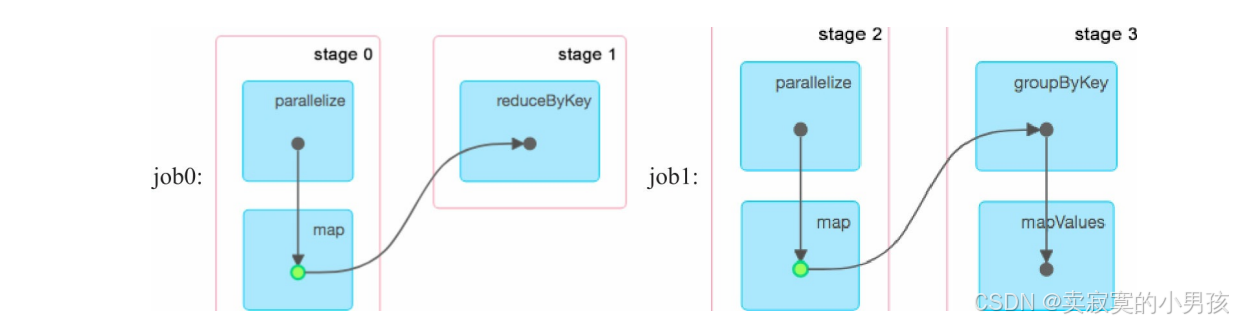
如下图:
对于上面这个任务而言,有两个job,并且这两个job都进行了相同的运算,将inputRDD转化成了MappedRDD,后续再对MappedRDD进行处理。这个相同的计算是可以避免的,只需要将job1计算出的MappedRDD缓存起来,job2可以直接使用。
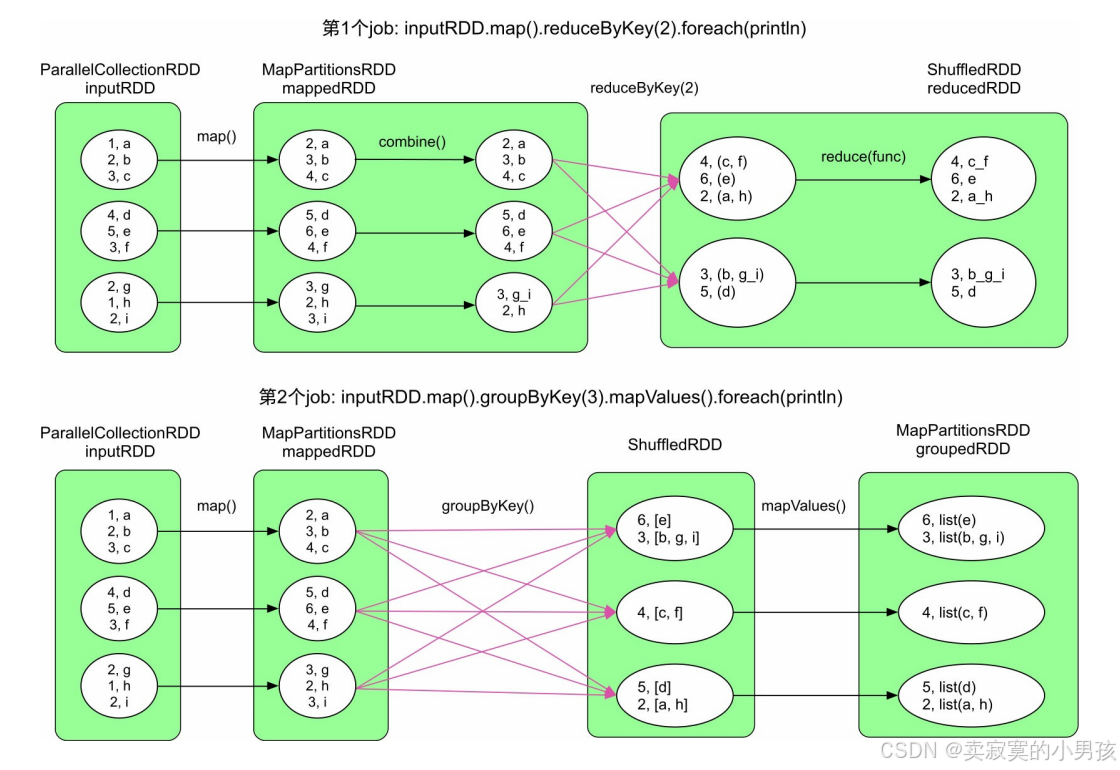
对于什么样的数据应该进行缓存,可以总结以下几点:
- 会被重复使用的数据。更确切地,会被多个job共享使用的数据。被共享使用的次数越多,那么缓存该数据的性价比越高。
- 数据不宜过大。过大会占用大量存储空间,导致内存不足,也会降低数据计算时可使用的空间。虽然缓存数据过大时也可以存放到磁盘中,但磁盘的I/O代价比较高,有时甚至不如重新计算快。
2.缓存数据的执行计划
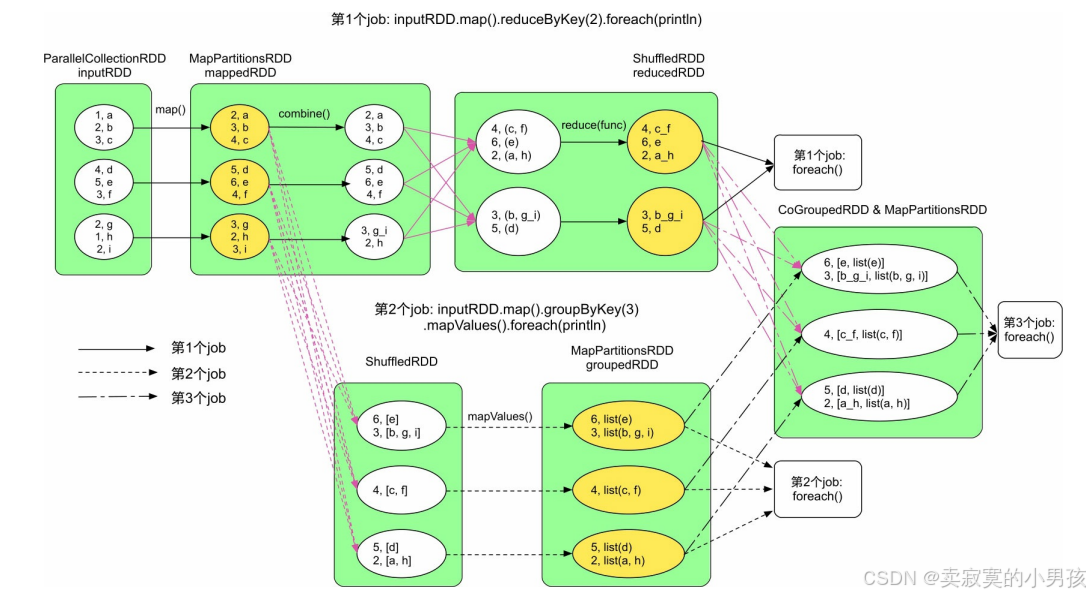
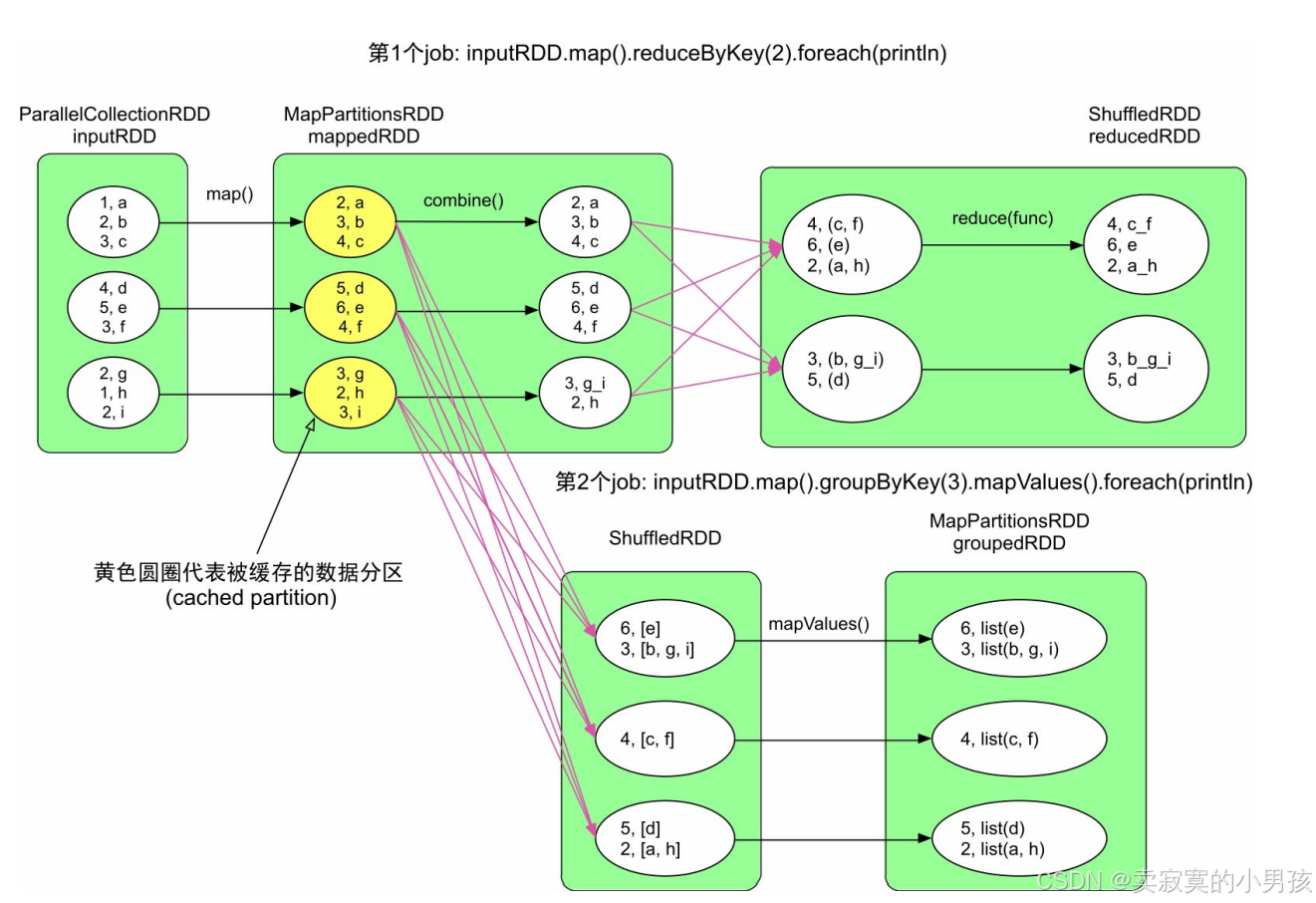
对于上图中的执行流程:一共有三个job,这三个job之间有一些重复计算的情况,其中黄色部分为进行缓存的rdd。如果我们查看job的Web UI界面,则也会发现生成了3个job,这3个job一共生成了8个stage,其中还有2个stage被忽略了。
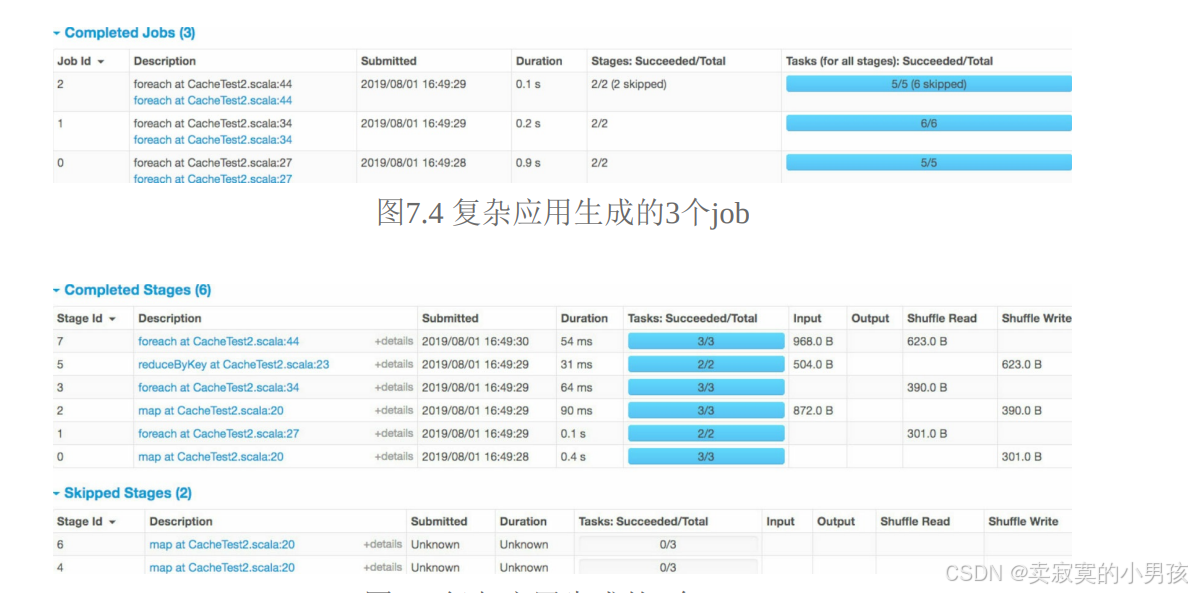
可以根据下表来进行分析,其中划掉的为缓存后避免重复计算的部分:

3.缓存级别
3.1 缓存级别分类
对于缓存函数persist,有很多参数可供选择,而这些参数就是缓存级别。
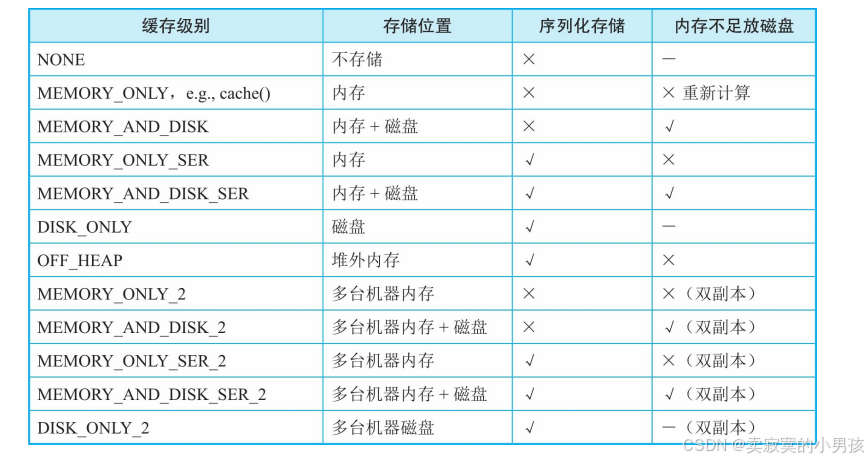
缓存级别主要从几个层面来考虑:
- 存储位置。可以将数据缓存到内存和磁盘中,内存空间小但读写速度快,磁盘空间大但读写速度慢。
- 是否序列化存储。如果对数据(record以Java objects形式)进行序列化,则可以减少存储空间,方便网络传输,但是在计算时需要对数据进行反序列化,会增加计算时延。
- 是否将缓存数据进行备份。将缓存数据复制多份并分配到多个节点,可以应对节点失效带来的缓存数据丢失问题,但需要更多的存储空间。
缓存级别针对的是RDD中的全部分区,即对RDD中每个分区中的数据(record)都进行缓存。
3.2 MEMORY_ONLY
对于MEMORY_ONLY级别来说,只使用内存进行缓存,如果某个分区在内存中存放不下,就不对该分区进行缓存。当后续job中的task计算需要这个分区中的数据时,需要重新计算得到该分区。
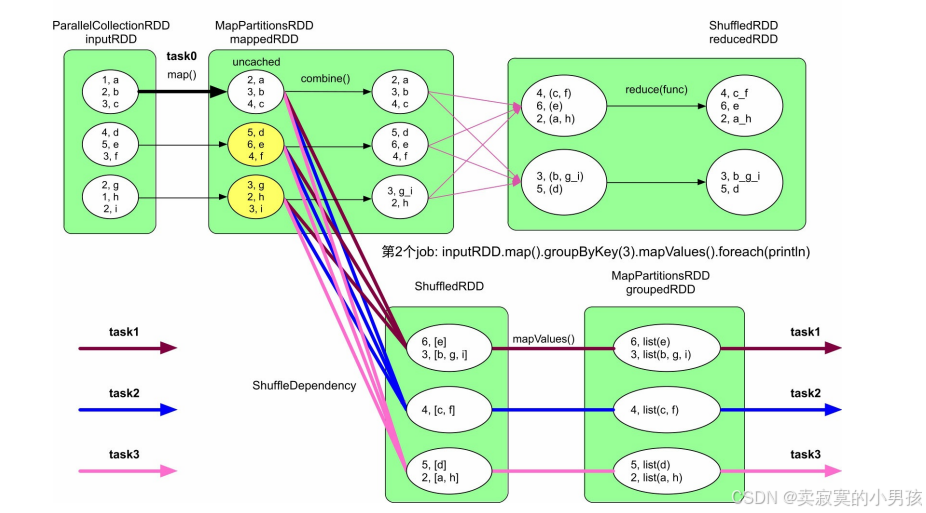
如果mappedRDD中的第1个分区没有被缓存,那么需要先执行task0,算出mappedRDD第1个分区中的数据,然后才能执行task1、task2、task3。
3.3 MEMORY_AND_DISK/MEMORY_AND_DISK_SER
对于MEMORY_AND_DISK缓存级别,如果内存不足时,则会将部分数据存放到磁盘上。而DISK_ONLY级别只使用磁盘进行缓存。MEMORY_ONLY_SER和MEMORY_AND_DISK_SER将数据按照序列化方式存储,以减少存储空间,但需要序列化/反序列化,会增加计算延时。因为存储到磁盘前需要对数据进行序列化,所以DISK_ONLY级别也需要序列化存储。
4.缓存数据的写入方法
4.1 persist的执行时机
缓存操作是lazy操作,只有等到action()操作触发job运行时才实际执行缓存操作。更进一步,当需要进行数据缓存时,Spark既要将数据写入内存或磁盘,也需要执行下一步数据操作。
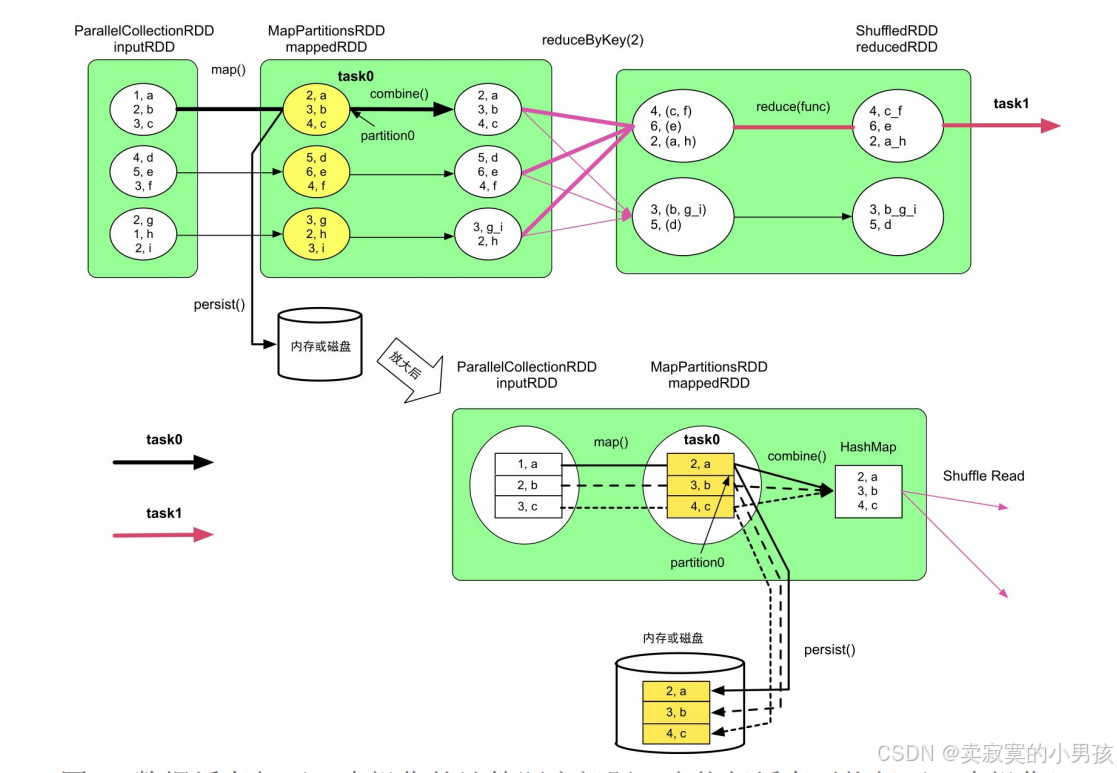
对于persist和combine的顺序,每当map计算出一个值后,就将其进行combine操作,然后删除计算出的值。因此正确的顺序是,每计算出一个值后,先persist该值,然后再进行combine操作。
4.2 缓存原理
在实现中,Spark在每个Executor进程中分配一个区域,以进行数据缓存,该区域由BlockManager来管理。
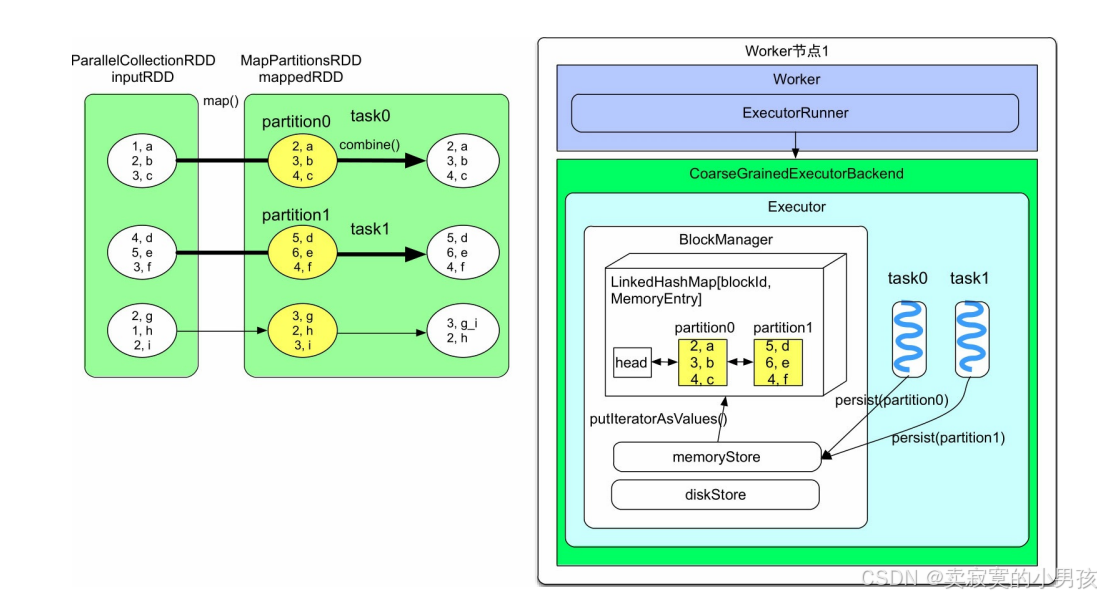
task0和task1运行在同一个Executor进程中。对于task0,当计算出mappedRDD中的partition0后,将partition0存放到BlockManager中的memoryStore内。memoryStore包含了一个LinkedHashMap,用来存储RDD的分区。该LinkedHashMap中的Key是blockId,即rddId+partitionId,如rdd_1_1,Value是分区中的数据,LinkedHashMap基于双向链表实现。在图中,task0和task1都将各自需要缓存的分区存放到了LinkedHashMap中。
5.缓存数据的读取方法
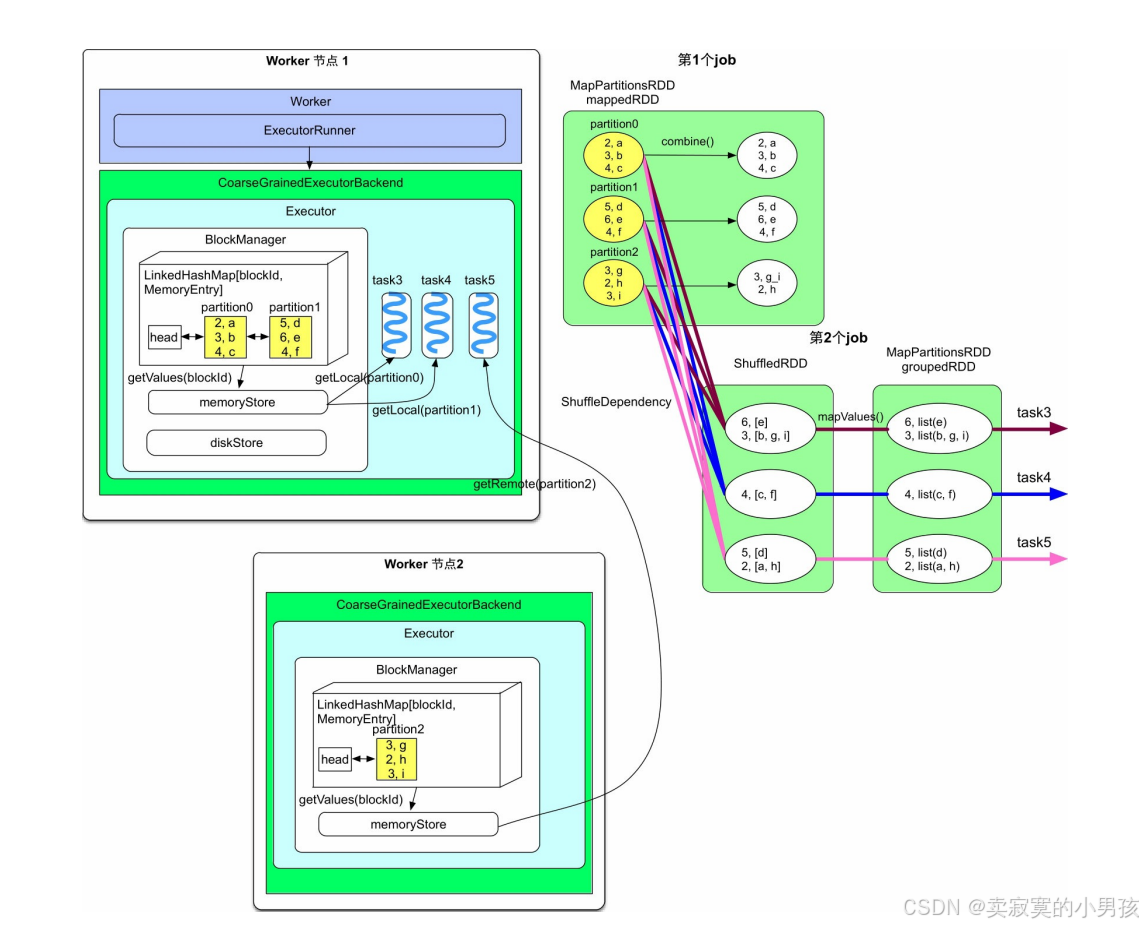
- 假设mappedRDD的partition0和partition1被Worker节点1中的BlockManager缓存,而partition2被Worker节点2中的BlockManager缓存,那么当第2个job需要读取mappedRDD中的分区时,首先去本地的BlockManager中查找该分区是否被缓存。
- 第2个job的3个task都被分到了Worker节点1上,其中task3和task4对应的CachedPartition在本地,因此直接通过Worker节点1memoryStore读取即可。而task5对应的CachedPartition在Worker节点2上,需要通过远程访问,也就是通过getRemote()读取。远程访问需要对数据行序列化和反序列化,远程读取时是一条条record读取,并得到及时处理的。
6.缓存数据的替换和回收
6.1 缓存回收和替换的应用场景
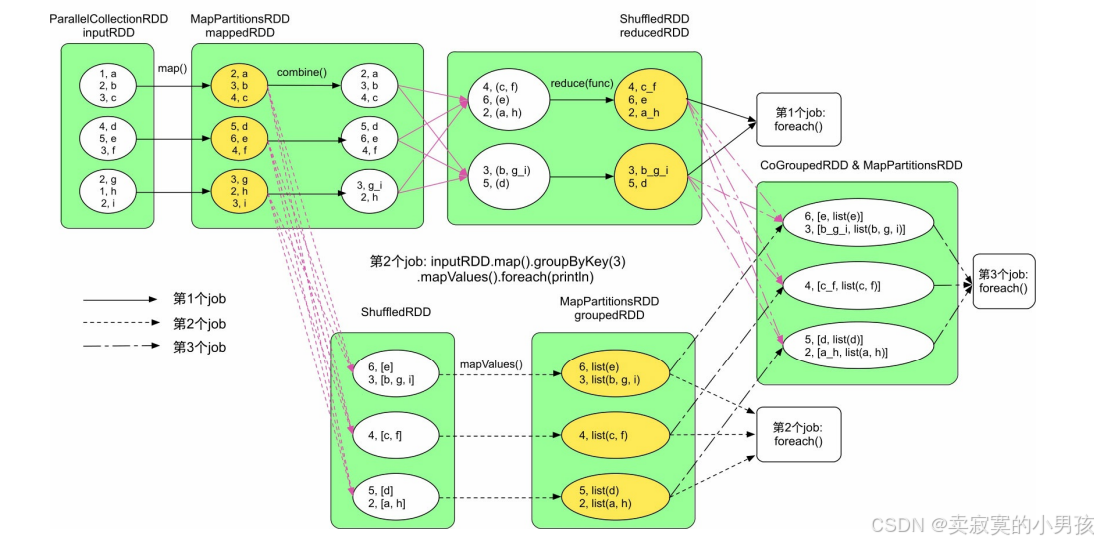
在本图中,一共缓存了三个rdd,mappedRDD、reducedRDD和groupedRDD。
缓存回收:当对reducedRDD和groupedRDD完成缓存后,可以回收mappedRDD,因为第3个job只需要使用reducedRDD和groupedRDD。缓存替换:当需要缓存reducedRDD而内存空间不足时,可以及时将mappedRDD进行替换,以腾出空间存储reducedRDD。
6.2 缓存替换
目前Spark采用LRU替换算法,即优先替换掉当前最长时间没有被使用过的RDD。在当前可用内存空间不足时,每次通过LRU替换一个或多个RDD(具体数目与一个动态的阈值相关),然后开始存储新的RDD,如果中途存放不下,就暂停,继续使用LRU替换一个或多个RDD,依此类推,直到存放完新的RDD。
LinkedHashMap双向链表自带的LRU功能实现了缓存替换。在进行缓存替换时,RDD的分区数据不能被该RDD的其他分区数据替换。例如,Spark在缓存中存放了newRDD的partition0和partition1后,就没有空间再放入newRDD的partition2了。此时,Spark不能删除newRDD的partition0和partition1来缓存partition2,因为被替换的RDD和要缓存的RDD是同一个RDD。
6.3 缓存回收
使用unpersist方法进行缓存回收:
- 不同于persist()的延时生效,unpersist()操作是立即生效的。
- 还可以设定unpersist()是同步阻塞的还是异步执行的,如unpersist(blocking=true)表示同步阻塞,即程序需要等待unpersist()结束后再进行下一步操作,这也是Spark的默认设定。而unpersist(blocking=false)表示异步执行,即边执行unpersist()边进行下一步操作。
- 如果unpersist()语句设置的位置不当,则会造成与用户预期效果不一致的结果。

第一个位置释放:如果再第一个位置释放缓存,此时由于在action()之前既执行了cache()又执行了unpersist(),所以删除了Spark刚设置的mappedRDD缓存,意味着不对mappedRDD进行缓存。实际上并没有对数据缓存,当缓存或使用缓存数据时,dag图中会出现绿色的点。
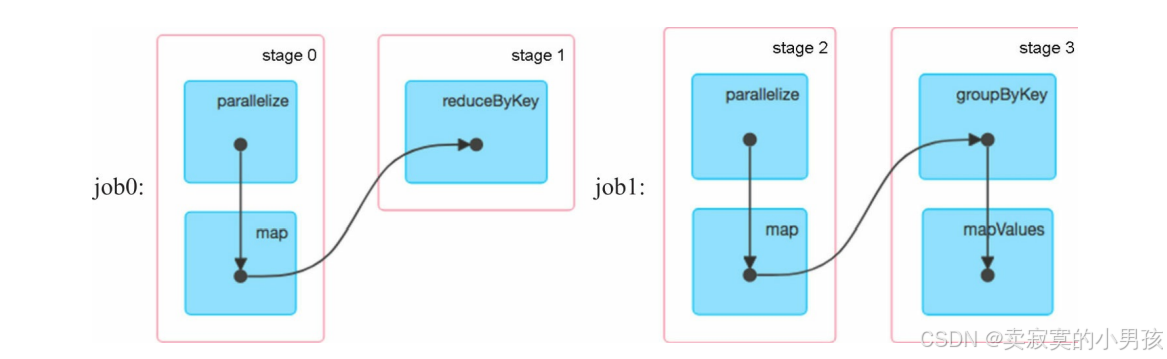
第二个位置释放:第一个job执行了action操作,因此mappedRDD被成功缓存了下来,但是第二个job还并没有执行action,也就是说
val groupedRDD = mappedRDD.groupByKey().mapValues(V=>V.tolist)
还并没有执行就已经执行到了释放逻辑,而persist是立即执行的,因此并没有使用到缓存数据。缓存了数据,只不过用之前把它给释放掉了。
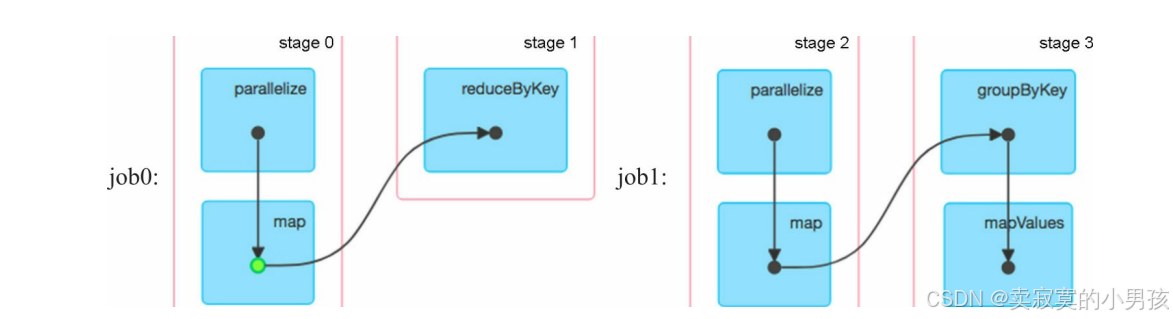
第三个位置释放:这种情况可以正常缓存数据。