Elastic Search 8.x 分片和常见性能优化
目录
- 索引分片写入原理
- 概念
- 索引写入流程
- 常见性能优化
- 背景
- 常见性能优化
- 硬件资源优化
- 分片和副本优化
索引分片写入原理
概念
-
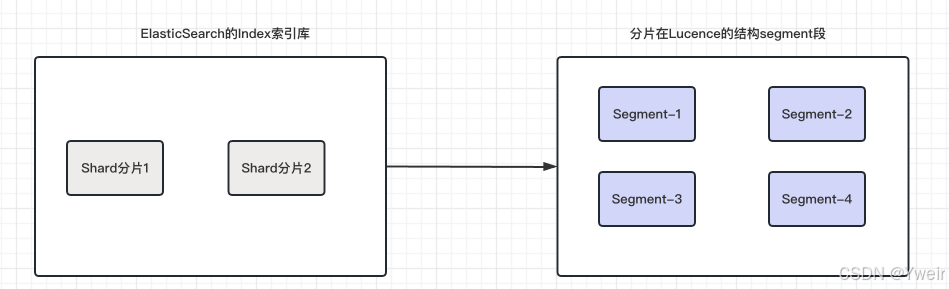
分片(shard)
- 分片是将索引数据分割成更小的、可分布式存储和处理的单元
- 每个索引都由一个或多个分片组成,每个分片都是一个独立的Lucene索引
-
段(segment)
- 段是Lucene索引的基本单元,每个分片都包含一个或多个段
- 段是不可变的,表示一定范围内的文档数据和相关的倒排索引,每一个Segment本质上就是一个倒排索引
- 总结
- 每个shard分片是一个lucene实例
- 每个分片由多个segment组成
- 每个segment占用内存,文件句柄
-
事务日志(Translog)
- 防止缓存中的
Segment还没有来得及被commit到磁盘当中,就发生了一些意外,比如断电等情况,导致数据丢失 - 引入
translog文件来保存这些记录,新文档先写入内存 buffer 和 translog 文件,每个 shard 都对应一个 translog 文件 - 当
translog大到一定程度,将会发生一个commit操作也就是全量提交 translog也是先写入 os cache 的,默认每隔 5 秒刷一次到磁盘中去- 所以默认情况下,可能有 5 秒的数据会仅仅停留在 buffer 或者 translog 文件的 os cache 中
- 如果此时机器挂了,会丢失 5 秒钟的数据。但是这样性能比较好,最多丢 5 秒的数据
- 也可以将 translog 设置成每次写操作必须是直接 fsync 到磁盘,但是性能会差很多
- 防止缓存中的
-
刷新(Refresh)
- 将缓存中的文档写入Segment,并打开Segment,让他可以被搜索的过程
- Refresh操作默认每秒执行一次, 将内存 buffer 的数据写入到一个新 的 Segment 中
- 因此新加了一条数据,在下一秒就可以被搜索,也因此ES被称为可以实时的搜索NRT
- 这个时候索引变成可被检索的,写入新Segment后 会清空内存buffer
- 经过了refresh间隔,将该时间段写入的全部数据refresh成一个segment
- refresh过程是很消耗性能的,如果你的系统对实时性要求不高,可以通过API控制refresh的时间间隔
PUT /dp_shop
{"settings": {"refresh_interval": "30s" }
}
- 合并(merge)
- 每秒都会有新的segment生成,用不了多久segment的数量暴涨,每个段都将十分消耗文件句柄、内存、和cpu资源
- 系统无法忍受的,所以将零散的segment进行合并,ES通过后台合并段解决这个问题
- ES因为会定期的把一些小的Segment或者没用的Segment进行合并,减少存储占用空间
- 小段被合并成大段,再合并成更大的段,然后将新的segment打开供搜索,旧的segment删除
- 影响
- 每个segment的占据内存是随着gc不会释放掉的,导致系统内存不够,进一步导致查询超时等问题
- 查询时会遍历每个segment,过多的segment会导致查询速度下降
- 刷盘(Flush)
- 实现文档数据从文件系统缓存刷到磁盘的过程
- 会定期触发,也可以当translog的数据达到某个上限的时候会进行一次flush操作
- 默认条件是,每 30 分钟主动进行一次 flush,或者当 translog 文件大小大于 512MB主动进行一次 flush
- 配置
index.translog.flush_threshold_period和index.translog.flush_threshold_size
- 配置
- 在ES中, 要保证被索引的文档能够立即被搜索到, 有两种方法:_refresh 或者 _ flush
索引写入流程
- 当一个写请求发送到ES后,ES会将数据写入内存缓冲区(memory buffer)并添加事务日志
- 为了避免频繁地将每条数据直接写入硬盘文件,导致硬盘进行随机写入,而随机写入的效率较低,会对性能造成严重影响
- 在设计时,ES引入了Linux的高速缓存(File system cache)来提高写入效率
- 当写入请求发送到ES后,数据会被暂时写入内存缓冲区,此时写入的数据还不能立即被查询到
- 默认,ES会每秒将内存缓冲区中的数据刷新到Linux的文件系统缓存中,并清空内存缓冲区,写入的数据就可以被查询到
- 这样的设计可以避免频繁进行随机硬盘写入,通过利用Linux的文件系统缓存,提高了Elasticsearch的写入效率
- 关于translog和flush的一些配置项
//当发生多少次操作时进行一次flush。默认是 unlimited
index.translog.flush_threshold_ops
//当translog的大小达到此值时会进行一次flush操作。默认是512mb
index.translog.flush_threshold_size
//指定的时间间隔内如果没有进行flush操作,进行一次强制flush操作 默认是30m
index.translog.flush_threshold_period
//多少时间间隔内会检查一次translog,来进行一次flush操作,默认是5s
index.translog.interval
常见性能优化
背景
- 官方数据Elastic Search最高的性能可以达到,PB级别数据秒内相应
- 1PB=1024TB = 1024GB * 1024GB
- 但是很多小伙伴公司的Elastic Search集群,里面存储了几百万或者几千万数据,但是ES查询就很慢了
- 记住,ES数量常规是亿级别为起点,之所以达不到官方的数据,多数是团队现有技术水平不够和业务场景不一样
- 海量数据检索领域榜单:https://db-engines.com/en/ranking/search+engine
常见性能优化
硬件资源优化
- 内存分配
- 将足够的堆内存分配给Elasticsearch进程,以减少垃圾回收的频率
- ElasticSearch推荐的最大JVM堆空间是30~32G, 所以分片最大容量推荐限制为30GB
- 30G heap 大概能处理的数据量 10 T,如果内存很大如128G,可在一台机器上运行多个ES节点
- 比如业务的数据能达到200GB, 推荐最多分配7到8个分片
- 存储器选择
- 使用高性能的存储器,如SSD,以提高索引和检索速度
- SSD的读写速度更快,适合高吞吐量的应用场景
- CPU和网络资源
- 根据预期的负载需求,配置合适的CPU和网络资源,以确保能够处理高并发和大数据量的请求
分片和副本优化
-
合理设置分片数量
- 过多的分片会增加CPU和内存的开销,因此要根据数据量、节点数量和性能需求来确定分片的数量
- 一般建议每个节点上不超过20个分片
-
考虑副本数量
- 根据可用资源、数据可靠性和负载均衡等因素,设置合适的副本数量
- 至少应设置一个副本,以提高数据的冗余和可用性
- 不是副本越多,检索性能越高,增加副本数量会消耗额外的存储空间和计算资源
-
索引和搜索优化
- 映射和数据类型
- 根据实际需求,选择合适的数据类型和映射设置
- 避免不必要的字段索引,尽可能减少数据在硬盘上的存储空间
- 分词和分析器
- 根据实际需求,选择合适的分词器和分析器,以优化搜索结果
- 了解不同分析器的性能特点,根据业务需求进行选择
- 查询和过滤器
- 使用合适的查询类型和过滤器,以减少不必要的计算和数据传输
- 尽量避免全文搜索和正则表达式等开销较大的查询操作
- 映射和数据类型
-
缓存和缓冲区优化
- 缓存大小
- 在Elasticsearch的JVM堆内存中配置合适的缓存大小,以加速热数据的访问
- 可以根据节点的角色和负载需求来调整缓存设置
- 索引排序字段
- 选择合适的索引排序字段,以提高排序操作的性能
- 对于经常需要排序的字段,可以为其创建索引,或者选择合适的字段数据类型
- 缓存大小
-
监控和日志优化
- 监控集群性能
- 使用Elasticsearch提供的监控工具如Elastic Stack的Elasticsearch监控、X-Pack或其他第三方监控工具
- 实时监控集群的健康状态、吞吐量、查询延迟和磁盘使用情况等关键指标
- 配置日志级别和轮转策略
- 根据需求配置Elasticsearch的日志级别和轮转策略,以避免日志文件过大影响磁盘空间
- 并能方便故障排查和性能分析
- 监控集群性能
-
集群规划和部署
- 多节点集群
- 使用多个节点组成集群,以提高数据的冗余和可用性。多节点集群还可以分布负载和增加横向扩展的能力
- 节点类型和角色
- 根据节点的硬件配置和功能需求,将节点设置为合适的类型和角色
- 如数据节点、主节点、协调节点等,以实现负载均衡和高可用性
- 多节点集群
-
数据备份和恢复
- 定期备份数据
- 根据数据重要性和业务需求,定期备份Elasticsearch数据
- 可以使用snapshot和restore功能、在线备份工具或者文件系统级别的备份工具
- 定期备份数据
-
性能测试和优化
- 压力测试
- 使用性能测试工具模拟真实的负载,评估集群的性能极限和瓶颈
- 根据测试结果,优化硬件资源、配置参数和查询操作等
- 日常性能调优
- 通过监控指标和日志分析,定期评估集群的性能表现,及时调整和优化配置,以满足不断变化的需求
- 压力测试
-
安全性和权限
- 启用安全功能
- 在生产环境中,为了确保数据的安全性,启用适当的安全功能,如访问控制、身份验证和传输加密等
- 权限控制
- 根据用户角色和权限需求,设置合适的访问控制策略。限制敏感数据的访问权限,并定期审计用户权限
- 启用安全功能
-
升级和版本管理
- 计划升级
- 定期考虑升级Elasticsearch版本,以获取新功能、性能改进和安全修复
- 在升级过程中,确保备份数据并进行合理的测试
- 版本管理
- 跟踪Elasticsearch的发行说明和文档,了解新版本的特性和已知问题,并根据实际需求选择合适的版本
- 计划升级