计算机图像处理:从像素到卷积与池化的深度解析
文章目录
- 前言
- 一、计算机眼中的图像
- 1.1 基础概念 - 像素
- 1.2 图片输入
- 1.3 代码示例
- 二、卷积
- 2.1 基础原理
- 2.1.1 卷积的概念
- 2.1.2 卷积核的概念
- 2.2 卷积的过程
- 2.2.1 步长
- 2.2.2 Padding
- 2.2.2.1 int/tuple
- 2.2.2.2 VALID
- 2.2.2.3 SAME
- 2.2.2.4 代码示例
- 2.3 卷积核为什么总是选择奇数大小
- 2.4 代码示例
- 三、池化
- 3.1 基础原理
- 3.2 下采样
- 3.3 池化输出尺寸计算公式
- 3.4 下采样原理
- 3.5 池化的作用
- 3.5.1 池化操作的优势
- 3.5.2 池化操作的缺点
- 3.6 代码示例
- 总结
前言
昨天我们已经介绍完了深度学习的基础知识,今天我们要开启深度学习的一个重要篇章——卷积神经网络。让我们由浅入深,开始今天的学习吧!
一、计算机眼中的图像
1.1 基础概念 - 像素
在了解计算机如何处理图像之前,需要先了解图像的构成元素。像素是图像的基本单元,每个像素存储着图像的颜色、亮度和其他特征。一系列像素组合在一起就形成了完整的图像。在计算机中,图像以像素的形式存在,并采用二进制格式进行存储。
根据图像的颜色不同,每个像素可以用不同的二进制数表示。日常生活中常见的图像是RGB三原色图,RGB图上的每个点都是由红(R)、绿(G)、蓝(B)三个颜色按照一定比例混合而成的,几乎所有颜色都可以通过这三种颜色按照不同比例调配而成。在计算机中,RGB三种颜色被称为RGB三通道,计算机根据这三个通道存储的像素值来对应不同的颜色。例如,在使用“画图”软件进行自定义调色时,其数值单位就是像素。

1.2 图片输入
这里可以看我之前的文章
在机器视觉的篇章中我很详细的介绍了图片的输入
基于Python OpenCV与Matplotlib的红色斜十字图像生成及色彩空间分离技术解析
1.3 代码示例
# 导入opencv包,OpenCV是一个广泛用于计算机视觉任务的库,提供了各种图像处理和计算机视觉算法
import cv2
# 导入numpy库,它是Python中用于科学计算的基础库,提供了高效的多维数组对象和处理这些数组的工具
import numpy as np
# 导入matplotlib.pyplot库,它是一个用于创建可视化图形的库,这里主要用于显示图像
import matplotlib.pyplot as plt# 创建空白的700x700彩色图像(三通道,类型是8位无符号整数取值范围为0~255)
# np.zeros函数用于创建一个全零的数组,(700, 700, 3)表示数组的形状,即高度为700,宽度为700,通道数为3
# dtype=np.uint8指定数组的数据类型为8位无符号整数,这是图像数据常用的数据类型
image = np.zeros((700, 700, 3), dtype=np.uint8)# 初始化为全黑,看一下效果
# cv2.cvtColor函数用于颜色空间转换,这里将OpenCV默认的BGR颜色空间转换为matplotlib使用的RGB颜色空间
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 设置图像的标题
plt.title('original image')
# 使用matplotlib显示图像
plt.imshow(image_rgb)
# 显示图像
plt.show()# 绘制黑色边框的蓝色边沿,每个100x100像素的块范围
# 绘制X型图案,将对角线方向的块填充为红色
# 定义每个小块的大小为100x100像素
block_size = 100
# 外层循环遍历y轴方向,步长为block_size
for i in range(0, 700, block_size):# 内层循环遍历x轴方向,步长为block_sizefor j in range(0, 700, block_size):# 计算当前小块的左上角坐标top_left = (j, i)# 计算当前小块的右下角坐标bottom_right = (j + block_size - 1, i + block_size - 1)# 绘制矩形型图案,将两个对角线方向的块填充为红色# image: 要绘制矩形的图像对象。# top_left: 矩形的一个顶点(左上角),以(x, y)形式表示。# bottom_right: 矩形的对角顶点(右下角),以(x, y)形式表示。# color: 矩形边框的颜色,以(B, G, R) (255,255,255)白色格式表示# thickness: 矩形边框的厚度。默认为 1。如果设置为负值(如 -1),则表示填充矩形。# 绘制其他块的白色边框cv2.rectangle(image, top_left, bottom_right, (255, 255, 255), 1)# 绘制X型图案,将两个对角线方向的块填充为红色# 主对角线填充为红色# i // block_size和j // block_size分别计算当前小块在y轴和x轴方向上的索引# i != 0和i != 600用于排除第一行和最后一行的小块if (i // block_size == j // block_size) and (i != 0) and i != 600:# 填充矩形为红色cv2.rectangle(image, top_left, bottom_right, (0, 0, 255), -1)# 副对角线也填充为红色# i // block_size + j // block_size == 6判断当前小块是否在副对角线上# i != 0和i != 600用于排除第一行和最后一行的小块if (i // block_size + j // block_size == 6) and (i != 0) and i != 600:# 填充矩形为红色cv2.rectangle(image, top_left, bottom_right, (0, 0, 255), -1)# 将BRG通道顺序转换为RGB顺序,用于matplotlib画图
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 使用matplotlib显示图像
plt.imshow(image_rgb)
# 设置图像的标题
plt.title('Add X Shape Image')
# 不显示坐标轴
plt.axis('off')
# 显示图像
plt.show()# 拆分彩色通道
# img 图像数据,为多维数组(numpy )
# b,g,r分割成三个通道图像,分别代表蓝色,绿色,红色通道,并将他们分别赋值为b,g,r
# cv2.split函数用于将彩色图像拆分为三个单通道图像
b, g, r = cv2.split(image)# 创建空白图像,用于每个通道
# 创建一个全零的700x700x3的数组,用于存储蓝色通道图像
blue_channel = np.zeros((700, 700, 3), dtype=np.uint8)
# 创建一个全零的700x700x3的数组,用于存储绿色通道图像
green_channel = np.zeros((700, 700, 3), dtype=np.uint8)
# 创建一个全零的700x700x3的数组,用于存储红色通道图像
red_channel = np.zeros((700, 700, 3), dtype=np.uint8)# 分配颜色通道数据
# 将蓝色通道的数据赋值给blue_channel的第一个通道
blue_channel[:, :, 0] = b
# 将绿色通道的数据赋值给green_channel的第二个通道
green_channel[:, :, 1] = g
# 将红色通道的数据赋值给red_channel的第三个通道
red_channel[:, :, 2] = r# 将BRG通道顺序转换为RGB顺序,用于Matplotlib 显示
blue_channel_rgb = cv2.cvtColor(blue_channel, cv2.COLOR_BGR2RGB)
green_channel_rgb = cv2.cvtColor(green_channel, cv2.COLOR_BGR2RGB)
red_channel_rgb = cv2.cvtColor(red_channel, cv2.COLOR_BGR2RGB)# 显示拆分分颜色通道
# 创建一个1行3列的子图布局,并选择第一个子图
plt.subplot(131)
# 显示蓝色通道图像
plt.imshow(blue_channel_rgb)
# 设置子图的标题
plt.title('Blue Channel')
# 不显示坐标轴
plt.axis('off')# 选择第二个子图
plt.subplot(132)
# 显示绿色通道图像
plt.imshow(green_channel_rgb)
# 设置子图的标题
plt.title('Green Channel')
# 不显示坐标轴
plt.axis('off')# 选择第三个子图
plt.subplot(133)
# 显示红色通道图像
plt.imshow(red_channel_rgb)
# 设置子图的标题
plt.title('Red Channel')
# 不显示坐标轴
plt.axis('off')
# 显示所有子图
plt.show()
二、卷积
2.1 基础原理
2.1.1 卷积的概念
在数学中,卷积是一种较为复杂的运算。而在计算机领域,卷积指的是用一个小的卷积核与目标图像进行相乘相加计算,以此提取目标图像中的某些特征,例如边缘、角点等。
2.1.2 卷积核的概念
卷积核是卷积运算中不可或缺的“工具”,在卷积神经网络里尤为重要,其作用是提取图像中的特征。
卷积核本质上是一个小矩阵,定义卷积核时需考虑以下几个方面:
- 卷积核的个数:该数量决定了输出特征矩阵的通道数。
- 卷积核的值:其值为自定义,根据想要提取的特征进行设置,后续还会更新。
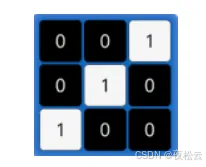
- 卷积核的大小:常见的卷积核大小有 1x1、3x3、5x5 等,通常采用奇数 x 奇数的形式。例如,下图就是一个 3x3 的卷积核:
2.2 卷积的过程
卷积是将卷积核在图像上滑动计算。每次滑动到新位置时,将卷积核与对应位置的图像区域元素相乘后求和,得到一个新值,将该新值添加到特征图中,最终得到新的特征图。此过程涉及padding方式和步长(strides)。

2.2.1 步长
-
定义:步长指卷积核完成一次卷积操作后移动的长度。
-
示例:在常规卷积过程中,步长为1,即每次卷积操作后,卷积核向右(或向下)移动一个单位。当步长为2时,对输入图像进行卷积,结果会是一个尺寸更小的矩阵,如对5×5的输入图像进行卷积,输出会是2×2的矩阵。

-
总结:步长会影响输出特征图的大小(长和高或宽和高)。例如,输入为5×5的图像,步长S = 1时,输出为3×3的图像;步长S = 2时,输出为2×2的图像。虽然提取的特征仍然正确,但步长增大会使输出特征矩阵变小。
代码示例:
# 导入 PyTorch 库,它是一个用于深度学习的开源库
import torch
# 导入 PyTorch 的神经网络模块,提供了构建神经网络所需的各种类和函数
import torch.nn as nn"""
nn.Conv2d 参数介绍
in_channels: 输入通道数,例如彩色图像通常有 3 个通道(RGB)
out_channels: 输出通道数,它也代表卷积核的个数,每个卷积核会生成一个输出通道
kernel_size: 卷积核的大小,可以是整数(表示正方形卷积核)或元组(表示矩形卷积核)
stride: 步长,即每次卷积操作时卷积核在输入特征图上移动的距离,默认值为 1
bias: 偏置,若为 True 则在卷积输出中添加一个可学习的偏置参数 b,若为 False 则不添加,默认值为 True
"""# 模型建立
# 创建一个包含单个 2D 卷积层的顺序容器
# 输入通道数为 3,输出通道数为 3,卷积核大小为 3x3,步长为 1,包含偏置参数
conv1_layer = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3, stride=1, bias=True))# 创建另一个包含单个 2D 卷积层的顺序容器
# 输入通道数为 3,输出通道数为 3,卷积核大小为 5x5,步长为 2,包含偏置参数
conv2_layer = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=3, kernel_size=5, stride=2, bias=True))# 生成一个随机的图像张量
# 张量的形状为 (1, 3, 30, 20),表示批量大小为 1,通道数为 3,高度为 30,宽度为 20
image = torch.rand(1, 3, 30, 20)# 将随机图像输入到第一个卷积层进行卷积操作
result1 = conv1_layer(image)
# 打印第一个卷积层的输出结果的形状
# 可以观察到卷积操作对输入图像的形状产生的影响
print(result1.shape)# 将随机图像输入到第二个卷积层进行卷积操作
result2 = conv2_layer(image)
# 打印第二个卷积层的输出结果的形状
# 由于第二个卷积层的步长和卷积核大小不同,输出形状会与第一个卷积层的输出形状不同
print(result2.shape)
2.2.2 Padding
Padding 即填充,是卷积过程中的一种操作,用于对原始输入特征进行处理,在图像边缘添加额外像素,使图像尺寸达到指定大小。通常使用填充操作来增加图像大小,以便在应用卷积操作时,让输出特征图的大小与输入特征图相同或更接近。以下是几种 Padding 填充方式的介绍:
2.2.2.1 int/tuple
-
形式:
padding = int/tuple -
示例:
padding等于 1 表示补一圈零,等于 2 表示补两圈零。

-
含义:
- int:表示在 2 个维度补齐相同数量的 0。
- tuple:按照 tuple 里的顺序分别给不同方向补齐对应的 0。其中,第一个维度用于 height 信息,第二个维度用于 width 信息。
2.2.2.2 VALID
- 操作特点:在“VALID”模式下,输入特征图不进行补 0 操作,即不改变输入特征图的大小和尺寸。
- 卷积示例:对于 5x5 的输入特征图和 3x3 的卷积核,按以下步骤进行卷积:
- 不补 0:不对输入特征图进行补 0 操作。
- 计算输出特征图大小:
- 计算方式 1(常用,在VALID中P为0,所以是是通用公式):
(输入特征图大小 - 卷积核尺寸 + 2 * P) / 步长 + 1,其中 P 是填充 0 的数量。若分子除以分母不是整数,则向下取整。例如,5x5 的输入,3x3 的卷积核,步长为 3,输出结果是 1x1,计算过程为(5 - 3) / 3 + 1 = 1。- 计算方式 2:
(输入特征图大小 - 卷积核尺寸 + 1) / 步长。若分子除以分母不是整数,则向上取整。例如,5x5 的输入,3x3 的卷积核,步长为 2,输出结果是 2x2,计算过程为(5 - 3 + 1) / 2 = 2。 - 等价性:两种计算方式是等价的。
2.2.2.3 SAME
-
操作特点:在卷积操作中进行填充(补 0)操作,补 0 的目的是使输出特征图大小等于输入特征图大小。但该前提是步长等于 1(
Strides = 1),当步长为 2 时不满足此条件。 -
卷积示例:对于 5x5 的输入特征图和 3x3 的卷积核,补 0 方式如下:

- 输出特征图大小计算公式:
输出特征图的大小 = (输入特征图大小 - 卷积核尺寸 + 2 * P) / 步长 + 1向下取整,其中 P 是填充 0 的数量(即填充多少层 0)。- 补零规则:先补右和下(一层),然后补左和上(一层)。补零的数量无需手动计算,因为 PyTorch 或 TensorFlow 等框架已实现该功能。图中深灰色部分即为补 0 的部分。
2.2.2.4 代码示例
# 卷积的填充
# 导入torch库,它是一个开源的深度学习框架,提供了张量操作、自动求导等功能
import torch
# 导入torch.nn模块,该模块包含了构建神经网络所需的各种层和损失函数等
import torch.nn as nn"""
nn.Conv2d 参数介绍
in_channels: 输入通道数,例如彩色图像通常有3个通道(RGB)
out_channels: 输出通道数(卷积核的个数),每个卷积核会生成一个特征图,因此输出通道数决定了特征图的数量
kernel_size: 卷积核的大小,可以是整数(表示正方形卷积核)或元组(表示矩形卷积核)
stride: 步长(每次卷积位移的距离) 默认值:1,步长越大,卷积操作的滑动间隔越大
bias: 偏置(True 有b参数,False 没有b参数) 默认值:True,偏置用于在卷积结果上添加一个常数项
padding: 填充,默认值:0 格式:1、字符串('same'或者'valid') 2、数值'same': 输出输入图像大小保持不变 'valid':不加边距(padding=0)
"""# conv1_layer属于same方式填充
# 使用nn.Sequential将卷积层封装起来,方便后续操作
# 输入通道数为3(模拟彩色图像),输出通道数为6,卷积核大小为5x5,步长为1,采用'same'填充方式
# 'same'填充会自动计算所需的填充量,使得输出图像的大小与输入图像大小相同
conv1_layer = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=6, kernel_size=5, stride=1, padding='same'))# conv2_layer属于默认不填充方式
# 输入通道数为3,输出通道数为6,卷积核大小为3x3,步长默认为1,填充默认为0
# 当不指定填充时,默认不进行填充,即padding=0
conv2_layer = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3))# conv3_layer 使用valid方式填充
# 输入通道数为3,输出通道数为6,卷积核大小为3x3,步长默认为1,采用'valid'填充方式
# 'valid'填充表示不添加任何边距,即padding=0
conv3_layer = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, padding='valid'))# conv4_layer 使用int填充
# 输入通道数为3,输出通道数为6,卷积核大小为3x3,步长默认为1,填充为2
# 填充值为2表示在图像的上下左右各添加2个像素的填充
conv4_layer = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, padding=2))# 生成一个随机图像张量
# 张量的形状为(1, 3, 20, 20),表示批量大小为1,通道数为3,图像高度为20,图像宽度为20
image = torch.rand(1, 3, 20, 20)# 将图像输入到conv1_layer进行卷积操作
result1 = conv1_layer(image)
# 打印conv1_layer的输出结果的形状
# 由于采用'same'填充,输出图像大小应与输入图像大小相同
print(result1.shape)# 将图像输入到conv2_layer进行卷积操作
result2 = conv2_layer(image)
# 打印conv2_layer的输出结果的形状
# 由于默认不填充,输出图像大小会比输入图像大小小
print(result2.shape)# 将图像输入到conv3_layer进行卷积操作
result3 = conv3_layer(image)
# 打印conv3_layer的输出结果的形状
# 由于采用'valid'填充,即不填充,输出图像大小会比输入图像大小小
print(result3.shape)# 将图像输入到conv4_layer进行卷积操作
result4 = conv4_layer(image)
# 打印conv4_layer的输出结果的形状
# 由于填充为2,输出图像大小会比输入图像大小大
print(result4.shape)
2.3 卷积核为什么总是选择奇数大小
- 唯一中心像素作锚点:奇数大小的卷积核有唯一的中心像素,可作为滑动的默认参考点(锚点)。进行卷积操作时,能在输入图像每个像素周围均匀取样,对称处理图像各位置,避免引入额外偏差与不对称性。而偶数大小的卷积核,中心像素会落在两个相邻像素之间,可能引发对称性问题。
- 利于处理边缘和边界像素:奇数大小的卷积核有明确的中心像素,有助于处理图像边缘和边界像素,避免模糊和信息损失。
不过,并非所有情况都必须选奇数大小的卷积核。在某些特定情况和任务中,偶数大小的卷积核也可使用,甚至可能表现更好。但多数情况下,奇数大小的卷积核是常见且推荐的选择,能简化卷积操作,保持图像处理的对称性和一致性。
2.4 代码示例
import tensorflow as tf# 输入特征张量
# 输入张量的形状为 [batch_size, input_height, input_width, in_channels]
# batch_size 表示一批数据中样本的数量
# input_height 表示输入图像的高度
# input_width 表示输入图像的宽度
# in_channels 表示输入图像的通道数
input = tf.constant([[[[1], [0], [0], [0], [1]],[[0], [1], [0], [1], [0]],[[0], [0], [1], [0], [0]],[[0], [1], [0], [1], [0]],[[1], [0], [0], [0], [1]]]], dtype=tf.float32)
# 打印输入张量的形状,以确认输入的格式
print(input.shape)# 卷积核张量
# 卷积核张量的形状为 [kernel_height, kernel_width, in_channels, out_channels]
# kernel_height 表示卷积核的高度
# kernel_width 表示卷积核的宽度
# in_channels 表示输入图像的通道数,必须与输入张量的通道数一致
# out_channels 表示卷积核的个数,即卷积层输出的通道数
wc1 = tf.constant([[[[0]], [[0]], [[1]]],[[[0]], [[1]], [[0]]],[[[1]], [[0]], [[0]]]], dtype=tf.float32)
# 打印第一个卷积核的形状
print("wc1", wc1.shape)# 定义第二个卷积核
wc2 = tf.constant([[[[1]], [[0]], [[0]]], [[[0]], [[1]], [[0]]], [[[0]], [[0]], [[1]]]], dtype=tf.float32)
# 打印第二个卷积核的形状
print("wc2", wc2.shape)# 创建一个卷积层
# tf.nn.conv2d 是 TensorFlow 中用于执行二维卷积操作的函数
# 第一个参数 input:指需要做卷积的输入图像,它要求是一个 Tensor,
# 具有 [batch, in_height, in_width, in_channels] 这样的 shape,
# 具体含义是 [训练时一个 batch 的图片数量, 图片高度, 图片宽度, 图像通道数],
# 要求类型为 float32 和 float64 其中之一
# 第二个参数 filter:相当于 CNN 中的卷积核,它要求是一个 Tensor,
# 具有 [filter_height, filter_width, in_channels, out_channels] 这样的 shape,
# 具体含义是 [卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],
# 要求类型与参数 input 相同。
# 第三个参数 strides:卷积时在图像每一维的步长,这是一个一维的向量,长度 4
# 第四个参数 padding 只能是 'VALID' 或 'SAME'
# 'VALID' 表示不进行填充,卷积核只在输入数据范围内进行卷积操作
# 'SAME' 表示进行填充,使得输出的高度和宽度与输入的高度和宽度相同(在步长为 1 的情况下)
conv_layer1 = tf.nn.conv2d(input, wc1, strides=[1, 1, 1, 1], padding='SAME')
# 将输出结果转化为 numpy 数组,方便后续处理和打印
output1 = conv_layer1.numpy()
# 打印第一个卷积层输出的形状
print(output1.shape)# 创建第二个卷积层
conv_layer2 = tf.nn.conv2d(input, wc2, strides=[1, 1, 1, 1], padding='SAME')
# 将第二个卷积层的输出结果转化为 numpy 数组
output2 = conv_layer2.numpy()# 合并两个卷积层的输出特征图
# tf.concat() 是用于将多个 Tensor 沿着指定维度拼接在一起的函数
# 它和 Python 里的 numpy.concatenate() 函数作用类似
# axis=-1 表示沿着最后一个维度进行拼接,即通道维度
merged_features = tf.concat([output1, output2], axis=-1)# 获取合并后特征图的各个维度大小
batch_size = merged_features.shape[0]
height = merged_features.shape[1]
width = merged_features.shape[2]
channels = merged_features.shape[3]# 打印卷积后结果的形状和值
print(f"卷积后的特征大小:[batch_size={batch_size}, "f"height={height}, width={width}, channels={channels}]")# 使用 tensorflow 中的 keras.layers.Conv2D 方法
# filters 表示卷积核的个数,即输出的通道数
# kernel_size 表示卷积核的大小
# padding='same' 表示进行填充,使得输出的高度和宽度与输入的高度和宽度相同(在步长为 1 的情况下)
# 将输入张量传入 Conv2D 层进行卷积操作
conv = tf.keras.layers.Conv2D(filters=2, kernel_size=3, padding='same')(input)
# 打印使用 keras.layers.Conv2D 进行卷积后的输出形状
print(conv.shape)
三、池化
3.1 基础原理
- 什么是池化:池化(Pooling)用于减少卷积神经网络(CNN)中特征图大小,通过聚合特征图上的局部区域得到更小的特征图。
- 池化操作:
- 池化操作类似卷积操作,使用的池化核是一个小矩阵,但本身无参数,仅对输入特征矩阵运算。其大小常见为 2x2、3x3、4x4 等,在卷积得到的输出特征图中进行池化操作。池化过程也有 Padding 方式和步长的概念,不同的是,池化步长往往等于池化核大小。
- 常见池化类型:
-
最大值池化(Max Pooling):从每个局部区域中选择最大值作为池化后的值,可保留局部区域中最显著的特征,在提取图像纹理、形状等方面效果良好。

-
平均值池化(Average Pooling):将局部区域中的值取平均作为池化后的值,能得到整体特征的平均值,在提取图像整体特征、减少噪声等方面效果较好。

-
3.2 下采样
池化也被称为下采样,它在图像处理和深度学习中有着重要作用。下面将分别介绍池化输出尺寸的计算公式以及下采样的原理。
3.3 池化输出尺寸计算公式
池化的输出尺寸计算方式与卷积类似,其计算公式为:
输出尺寸 = ⌊ 图像尺寸 − 池化核尺寸 + 2 × 填充值 步长 + 1 ⌋ \text{输出尺寸} = \lfloor \frac{\text{图像尺寸}-\text{池化核尺寸} + 2\times\text{填充值}}{\text{步长}}+1 \rfloor 输出尺寸=⌊步长图像尺寸−池化核尺寸+2×填充值+1⌋
其中, ⌊ x ⌋ \lfloor x \rfloor ⌊x⌋表示向下取整操作。该公式用于计算经过池化操作后输出特征图的尺寸。
3.4 下采样原理
下采样是一种对图像进行降分辨率处理的方法。对于一幅尺寸为 M × N M \times N M×N 的图像 I I I,若要对其进行 s s s 倍下采样,那么最终会得到尺寸为 ( M s ) × ( N s ) (\frac{M}{s})\times(\frac{N}{s}) (sM)×(sN) 的低分辨率图像。需要注意的是,这里的 s s s 应当是 M M M 和 N N N 的公约数,在一定程度上, s s s 类似于池化核在下采样过程中所起到的控制尺寸缩小比例的作用。
3.5 池化的作用
3.5.1 池化操作的优势
- 提升运行效率:通过降低特征图尺寸,减少计算量,进而提升模型运行效率。不过需注意,参数量通常不会因池化操作而改变,如 5×5 池化后再进行 3×3 的操作,卷积核参数量依旧是 3×3。
- 增强鲁棒性:能带来特征的平移、旋转等不变性,有助于提高模型对输入数据的鲁棒性,即让模型在面对输入数据、环境或参数的摄动(扰动)时,仍能保持性能的稳定性和可靠性。
- 增强表达能力:池化层多为非线性操作,例如最大值池化,可增强网络的表达能力,进一步提升模型性能。
3.5.2 池化操作的缺点
会丢失一些信息,这是池化操作的最大弊端。
3.6 代码示例
# 手搓 最大池化,平均池化
import torch
import matplotlib.pyplot as plt# 生成一个随机的图像数据
# torch.normal(mean, std, size) 用于生成服从正态分布的随机张量
# 这里 mean 为 0,std 为 0.5,size 为 (1, 3, 6, 6),表示生成一个批次大小为 1,通道数为 3,高度和宽度均为 6 的图像张量
image = torch.normal(0, 0.5, (1, 3, 6, 6))# 定义最大池化函数
# image 是输入的图像张量,pool_kernel 是池化核的大小,stride 是步长
def max_pool_2d(image, pool_kernel=2, stride=3):# 获取输入图像的批次大小、通道数、高度和宽度batch_size, channels, h, w = image.shape# 计算池化后特征图的高度# 公式为 (h - pool_kernel) // stride + 1,其中 // 表示整除conv_h = (h - pool_kernel) // stride + 1# 计算池化后特征图的宽度conv_w = (w - pool_kernel) // stride + 1# 初始化一个全零的张量,用于存储池化后的结果# 形状为 (batch_size, channels, conv_h, conv_w)conv_result = torch.zeros((batch_size, channels, conv_h, conv_w))# 遍历池化后特征图的每一行for i in range(conv_h):# 遍历池化后特征图的每一列for j in range(conv_w):# 从输入图像中提取当前池化区域# i * stride:i * stride + pool_kernel 表示在高度方向上的切片范围# j * stride:j * stride + pool_kernel 表示在宽度方向上的切片范围val = image[:, :, i * stride:i * stride + pool_kernel, j * stride:j * stride + pool_kernel]# torch.max 不可以向高纬度内容求解# torch.amax 根据切片维度求解最大值(降维)# 先在最后一个维度上求最大值,再在新的最后一个维度上求最大值max_val = val.amax(dim=-1).amax(dim=-1)# 将求得的最大值赋值给池化结果张量的对应位置conv_result[:, :, i, j] = max_val# 返回池化后的结果return conv_result# 调用最大池化函数,并打印池化结果的形状
print(max_pool_2d(image, 2, 2).shape)# 定义平均池化函数
# image 是输入的图像张量,pool_kernel 是池化核的大小,stride 是步长
def average_pool_2d(image, pool_kernel=2, stride=2):# 获取输入图像的批次大小、通道数、高度和宽度batch_size, channels, h, w = image.shape# 计算池化后特征图的高度conv_h = (h - pool_kernel) // stride + 1# 计算池化后特征图的宽度conv_w = (w - pool_kernel) // stride + 1# 初始化一个全零的张量,用于存储池化后的结果conv_result = torch.zeros((batch_size, channels, conv_h, conv_w))# 遍历池化后特征图的每一行for i in range(conv_h):# 遍历池化后特征图的每一列for j in range(conv_w):# 从输入图像中提取当前池化区域val = image[:, :, i * stride:i * stride + pool_kernel, j * stride:j * stride + pool_kernel]# 计算当前池化区域的平均值# detach().cpu() 是为了将张量从计算图中分离出来,并转移到 CPU 上# dim=[2, 3] 表示在高度和宽度维度上求平均值mean_val = torch.mean(val.detach().cpu(), dim=[2, 3])# 将求得的平均值赋值给池化结果张量的对应位置conv_result[:, :, i, j] = mean_val# 返回池化后的结果return conv_result# 调用平均池化函数,并打印池化结果的形状
print(f"平均池化", average_pool_2d(image, 2, 2).shape)
总结
文章围绕计算机图像处理展开,首先介绍计算机眼中图像的基础概念,阐述像素是图像基本单元,RGB图通过三通道存储像素值对应颜色,还给出创建特定图案图像及拆分颜色通道的代码示例;接着讲解卷积相关知识,包括卷积和卷积核概念、卷积过程(涉及步长和Padding方式),分析卷积核常选奇数大小的原因并给出代码示例;最后介绍池化,说明其用于减少特征图大小,有最大值和平均值池化类型,给出池化输出尺寸计算公式和下采样原理,分析池化操作优缺点并提供手动实现最大和平均池化的代码示例。