Null-text Inversion for Editing Real Images using Guided Diffusion Models

1. 已有工作的思路以及不足之处(existing work)有哪些?
已有工作主要包括以下几类:
-
GAN反转方法:通过优化潜在向量或训练编码器将图像映射到GAN的潜在空间,但这些方法不适用于扩散模型。
-
DDIM反转:适用于无条件扩散模型,但在文本引导扩散模型中,分类器自由引导会放大累积误差,导致重建质量下降。
-
文本反转和模型调优:如Textual Inversion和Dreambooth,通过优化文本嵌入或模型权重来适应特定图像,但前者编辑能力有限,后者需要为每张图像复制整个模型,效率低下。
-
基于掩码的编辑方法:如Blended Diffusion和Stable Diffusion Inpaint,需要用户提供精确掩码,限制了编辑的灵活性和自然性。
不足之处:
-
现有方法无法同时实现高保真重建和灵活的文本编辑。
-
需要用户干预(如提供掩码)或复杂的模型调优,效率低且难以推广。
2. 作者的洞见(insight)是什么?
作者的洞见主要有两点:
-
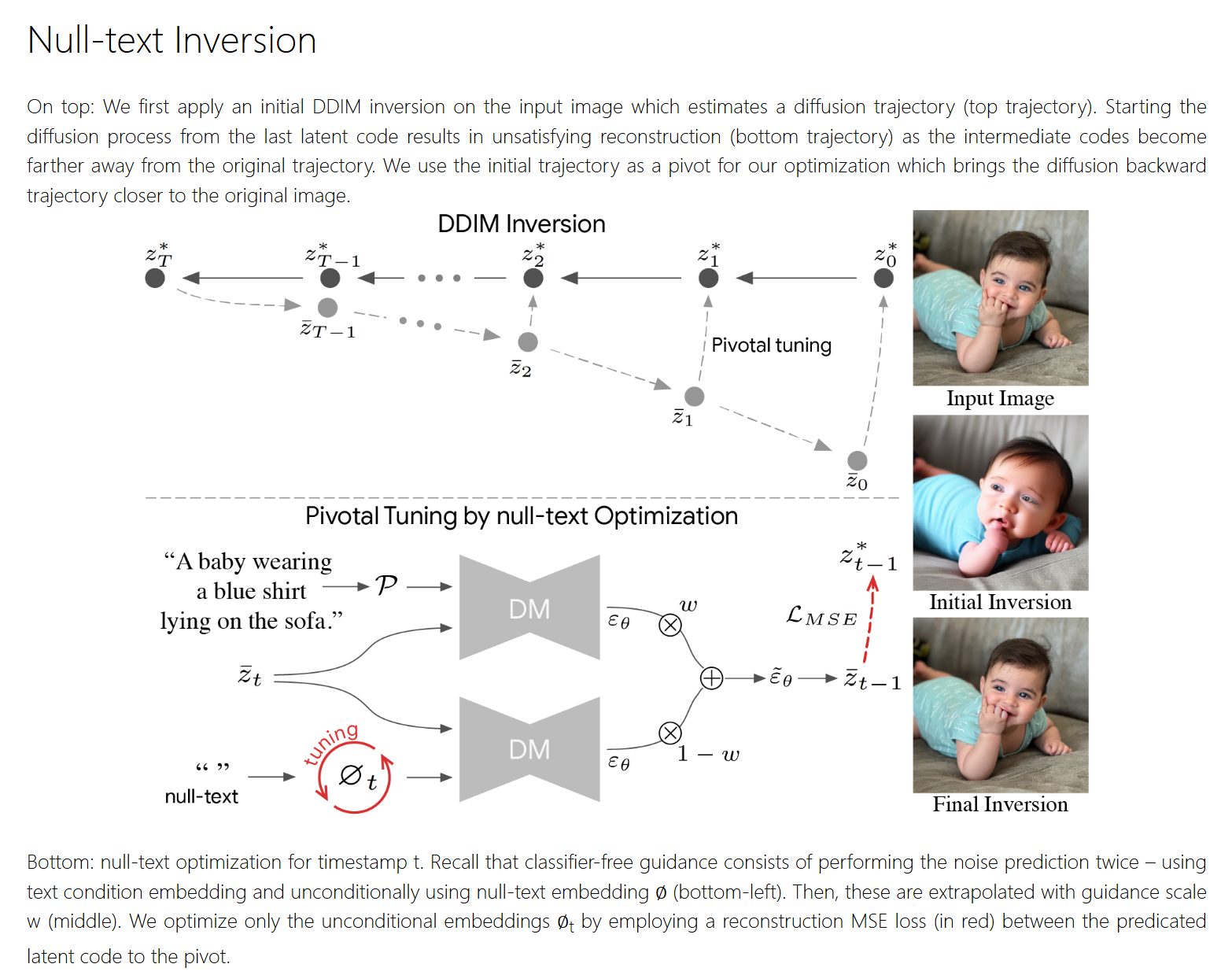
关键反转(Pivotal Inversion):DDIM反转在分类器自由引导下效果不佳,但可以作为优化的起点(即“关键点”),通过围绕这一关键点进行局部优化,能够高效实现高保真重建。
-
空文本优化(Null-text Optimization):分类器自由引导的结果受无条件预测的影响很大,因此优化用于无条件预测的空文本嵌入(而非条件文本嵌入或模型权重),可以在保留模型编辑能力的同时实现高质量重建。
3. 解决方法的基本思想(basic idea)是什么?
解决方法的基本思想包括两个核心组件:
-
关键反转:
-
首先使用DDIM反转(无分类器自由引导)生成初始噪声轨迹(关键点)。
-
围绕这一轨迹进行优化,确保重建图像接近原始图像,同时保留编辑能力。
-
-
空文本优化:
-
优化用于无条件预测的空文本嵌入(替换默认的空文本嵌入),保持模型权重和条件文本嵌入不变。
-
通过逐时间步优化空文本嵌入,进一步提升重建质量。
-
Abstrct:
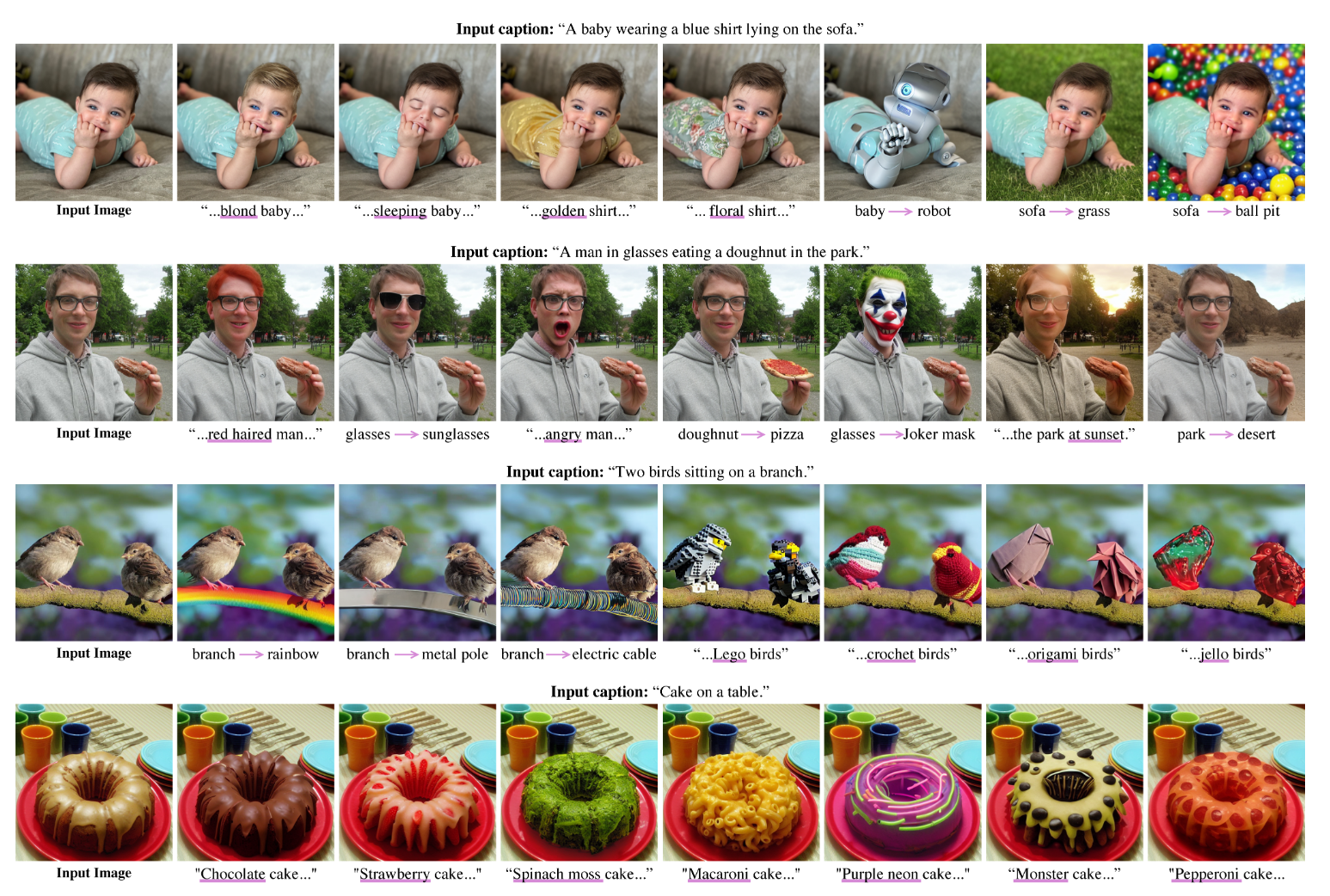
Recent large-scale text-guided diffusion models provide powerful image generation capabilities. Currently, a massive effort is given to enable the modification of these images using text only as means to offer intuitive and versatile editing tools. To edit a real image using these state-of-the-art tools, one must first invert the image with a meaningful text prompt into the pretrained model's domain. In this paper, we introduce an accurate inversion technique and thus facilitate an intuitive text-based modification of the image. Our proposed inversion consists of two key novel components: (i) Pivotal inversion for diffusion models. While current methods aim at mapping random noise samples to a single input image, we use a single pivotal noise vector for each timestamp and optimize around it. We demonstrate that a direct DDIM inversion is inadequate on its own, but does provide a rather good anchor for our optimization. (ii) Null-text optimization, where we only modify the unconditional textual embedding that is used for classifier-free guidance, rather than the input text embedding. This allows for keeping both the model weights and the conditional embedding intact and hence enables applying prompt-based editing while avoiding the cumbersome tuning of the model's weights. Our null-text inversion, based on the publicly available Stable Diffusion model, is extensively evaluated on a variety of images and various prompt editing, showing high-fidelity editing of real images.
原文链接:Null-text Inversion for Editing Real Images using Guided Diffusion Models
架构图:
class NullInversion:def prev_step(self, model_output: Union[torch.FloatTensor, np.ndarray], timestep: int, sample: Union[torch.FloatTensor, np.ndarray]):prev_timestep = timestep - self.scheduler.config.num_train_timesteps // self.scheduler.num_inference_stepsalpha_prod_t = self.scheduler.alphas_cumprod[timestep]alpha_prod_t_prev = self.scheduler.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.scheduler.final_alpha_cumprodbeta_prod_t = 1 - alpha_prod_tpred_original_sample = (sample - beta_prod_t ** 0.5 * model_output) / alpha_prod_t ** 0.5pred_sample_direction = (1 - alpha_prod_t_prev) ** 0.5 * model_outputprev_sample = alpha_prod_t_prev ** 0.5 * pred_original_sample + pred_sample_directionreturn prev_sampledef next_step(self, model_output: Union[torch.FloatTensor, np.ndarray], timestep: int, sample: Union[torch.FloatTensor, np.ndarray]):timestep, next_timestep = min(timestep - self.scheduler.config.num_train_timesteps // self.scheduler.num_inference_steps, 999), timestepalpha_prod_t = self.scheduler.alphas_cumprod[timestep] if timestep >= 0 else self.scheduler.final_alpha_cumprodalpha_prod_t_next = self.scheduler.alphas_cumprod[next_timestep]beta_prod_t = 1 - alpha_prod_tnext_original_sample = (sample - beta_prod_t ** 0.5 * model_output) / alpha_prod_t ** 0.5next_sample_direction = (1 - alpha_prod_t_next) ** 0.5 * model_outputnext_sample = alpha_prod_t_next ** 0.5 * next_original_sample + next_sample_directionreturn next_sampledef get_noise_pred_single(self, latents, t, context):noise_pred = self.model.unet(latents, t, encoder_hidden_states=context)["sample"]return noise_preddef get_noise_pred(self, latents, t, is_forward=True, context=None):latents_input = torch.cat([latents] * 2)if context is None:context = self.contextguidance_scale = 1 if is_forward else GUIDANCE_SCALEnoise_pred = self.model.unet(latents_input, t, encoder_hidden_states=context)["sample"]noise_pred_uncond, noise_prediction_text = noise_pred.chunk(2)noise_pred = noise_pred_uncond + guidance_scale * (noise_prediction_text - noise_pred_uncond)if is_forward:latents = self.next_step(noise_pred, t, latents)else:latents = self.prev_step(noise_pred, t, latents)return latents@torch.no_grad()def latent2image(self, latents, return_type='np'):latents = 1 / 0.18215 * latents.detach()image = self.model.vae.decode(latents)['sample']if return_type == 'np':image = (image / 2 + 0.5).clamp(0, 1)image = image.cpu().permute(0, 2, 3, 1).numpy()[0]image = (image * 255).astype(np.uint8)return image@torch.no_grad()def image2latent(self, image):with torch.no_grad():if type(image) is Image:image = np.array(image)if type(image) is torch.Tensor and image.dim() == 4:latents = imageelse:image = torch.from_numpy(image).float() / 127.5 - 1image = image.permute(2, 0, 1).unsqueeze(0).to(device)latents = self.model.vae.encode(image)['latent_dist'].meanlatents = latents * 0.18215return latents@torch.no_grad()def init_prompt(self, prompt: str):uncond_input = self.model.tokenizer([""], padding="max_length", max_length=self.model.tokenizer.model_max_length,return_tensors="pt")uncond_embeddings = self.model.text_encoder(uncond_input.input_ids.to(self.model.device))[0]text_input = self.model.tokenizer([prompt],padding="max_length",max_length=self.model.tokenizer.model_max_length,truncation=True,return_tensors="pt",)text_embeddings = self.model.text_encoder(text_input.input_ids.to(self.model.device))[0]self.context = torch.cat([uncond_embeddings, text_embeddings])self.prompt = prompt@torch.no_grad()def ddim_loop(self, latent):uncond_embeddings, cond_embeddings = self.context.chunk(2)all_latent = [latent]latent = latent.clone().detach()for i in range(NUM_DDIM_STEPS):t = self.model.scheduler.timesteps[len(self.model.scheduler.timesteps) - i - 1]noise_pred = self.get_noise_pred_single(latent, t, cond_embeddings)latent = self.next_step(noise_pred, t, latent)all_latent.append(latent)return all_latent@propertydef scheduler(self):return self.model.scheduler@torch.no_grad()def ddim_inversion(self, image):latent = self.image2latent(image)image_rec = self.latent2image(latent)ddim_latents = self.ddim_loop(latent)return image_rec, ddim_latentsdef null_optimization(self, latents, num_inner_steps, epsilon):uncond_embeddings, cond_embeddings = self.context.chunk(2)uncond_embeddings_list = []latent_cur = latents[-1]bar = tqdm(total=num_inner_steps * NUM_DDIM_STEPS)for i in range(NUM_DDIM_STEPS):uncond_embeddings = uncond_embeddings.clone().detach()uncond_embeddings.requires_grad = Trueoptimizer = Adam([uncond_embeddings], lr=1e-2 * (1. - i / 100.))latent_prev = latents[len(latents) - i - 2]t = self.model.scheduler.timesteps[i]with torch.no_grad():noise_pred_cond = self.get_noise_pred_single(latent_cur, t, cond_embeddings)for j in range(num_inner_steps):noise_pred_uncond = self.get_noise_pred_single(latent_cur, t, uncond_embeddings)noise_pred = noise_pred_uncond + GUIDANCE_SCALE * (noise_pred_cond - noise_pred_uncond)latents_prev_rec = self.prev_step(noise_pred, t, latent_cur)loss = nnf.mse_loss(latents_prev_rec, latent_prev)optimizer.zero_grad()loss.backward()optimizer.step()loss_item = loss.item()bar.update()if loss_item < epsilon + i * 2e-5:breakfor j in range(j + 1, num_inner_steps):bar.update()uncond_embeddings_list.append(uncond_embeddings[:1].detach())with torch.no_grad():context = torch.cat([uncond_embeddings, cond_embeddings])latent_cur = self.get_noise_pred(latent_cur, t, False, context)bar.close()return uncond_embeddings_listdef invert(self, image_path: str, prompt: str, offsets=(0,0,0,0), num_inner_steps=10, early_stop_epsilon=1e-5, verbose=False):self.init_prompt(prompt)ptp_utils.register_attention_control(self.model, None)image_gt = load_512(image_path, *offsets)if verbose:print("DDIM inversion...")image_rec, ddim_latents = self.ddim_inversion(image_gt)if verbose:print("Null-text optimization...")uncond_embeddings = self.null_optimization(ddim_latents, num_inner_steps, early_stop_epsilon)return (image_gt, image_rec), ddim_latents[-1], uncond_embeddingsdef __init__(self, model):scheduler = DDIMScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", clip_sample=False,set_alpha_to_one=False)self.model = modelself.tokenizer = self.model.tokenizerself.model.scheduler.set_timesteps(NUM_DDIM_STEPS)self.prompt = Noneself.context = Nonenull_inversion = NullInversion(ldm_stable)代码:
结果: