Django母婴商城项目实践(九)- 商品列表页模块
9、商品列表页模块
1、业务逻辑
-
商品模块分为:商品列表页 和 商品详情页
-
商品列表页将所有商品按照一定的规则排序展示,用于可以从销量、价格、上架时间和收藏数量设置商品的排序方式,并且在商品左侧设置分类列表,选择某一个分类可以筛选出对应的商品信息。

-
商品列表页设有商品搜索功能和导航栏,网页顶部下方划分为3个部分:分类列表、排序设置和商品列表,当在搜索栏搜索每个商品时,商品列表会展示符合搜索条件的数据,这些数据还可以分类显示、排序设置和分页查询,所以商品列表页需实现商品关键字查询、商品分类筛选、商品排序设置和分页显示,同时这四种方式可以任意组合并且互不干扰。
-
数据查询适合使用GET、POST请求实现,则针对4种查询方式分别设置请求参数n、t、s 和 p,其中n 表示商品搜索功能的关键字、t 表示用于查询某一个分页的商品、s 用设置商品的排序方式、p 用于设置商品信息的页数。
2、功能实现
- 项目应用 commodity 下的 urls.py:
from django.urls import path
from .views import *urlpatterns = [path('', commodityView, name='commodity'), # 商品列表页path('detail/<int:id>.html', detailView, name='detail'), # 商品详情页
]
- 项目应用 commodity 下的 views.py:
from django.shortcuts import render
from .models import CommodityInfos, Types
from django.core.paginator import Paginator, PageNotAnInteger, EmptyPage # 分页def commodityView(request):'''商品列表页的业务逻辑:param request: 请求对象:return: 渲染页面内容'''title = '商品列表' # 页面的标题# 查询分类的数据typeLists = Types.objects.all() # 获取所有的商品分类firsts_lists = Types.objects.values('firsts').distinct() # 获取不重复的一级分类# 查询所有商品的数据commodityInfos = CommodityInfos.objects.all()# 获取搜索关键字search = request.GET.get('q', '').strip()if search: # 搜索关键字不为空,则查询商品名字中包含关键字的数据commodityInfos = commodityInfos.filter(name__contains=search)# 获取选择的二级分类名称utype = request.GET.get('t', '')if utype: # 选择了二级分类名称不为空,则查询商品分类等于该名称的数据commodityInfos = commodityInfos.filter(types=utype)# 获取选择的排序字段操作choice = request.GET.get('s', '')# 获取排序字段映射(传递的排序操作:排序字段条件)sort_map = {'sold0': 'sold', # 销量升序'sold1': '-sold', # 销量降序'discount0': 'discount', # 价格升序'discount1': '-discount', # 价格降序'created0': 'created', # 最新升序'created1': '-created', # 最新降序'likes0': 'likes', # 收藏升序'likes1': '-likes', # 收藏降序}if choice and choice in sort_map: # 判断排序字段是否存在,且在排序字段映射的字典中,在根据排序字段进行排序commodityInfos = commodityInfos.order_by(sort_map[choice])'''方式1:搜索 + 分类 + 按字段排序:参数 q + t + shttp://127.0.0.1:8003/commodity.html?q=%E5%AE%9D%E5%AE%9D&t=%E5%AE%9D%E5%AE%9D%E8%BE%85%E9%A3%9F&s=likes1方式2:分类 + 按字段排序:q='' + t + shttp://127.0.0.1:8003/commodity.html?q=&t=%E5%AE%9D%E5%AE%9D%E8%BE%85%E9%A3%9F&s=likes1'''# p 分页功能:获取当前页码数pages = request.GET.get('p', 1)# 1 创建分页对象paginator = Paginator(commodityInfos, 6)# 2 向模板传递分页对象try:pageObj = paginator.page(pages) # 对数据进行切片处理except PageNotAnInteger: # 页面数不为整数(用户随机修改p的值,不是整数)pageObj = paginator.page(1)except EmptyPage: # 页面数超过最大值pageObj = paginator.page(paginator.num_pages) # 获取最大页数return render(request, 'commodity.html', locals())
3、分页功能的机制和原理
-
Django 为开发者提供了内置的分页功能,开发者无须自己实现数据分页功能,只需调用 Django 内置分页功能的函数即可实现,实现数据的分页功能需要考虑多方面的因素,分别说明如下:
- 当前用户访问的页数是否存在上(下)一页。
- 访问的页数是否超出页数上限。
- 数据如何接页截取,如何设置每页的数据量。
-
对于上述考虑因素,Django 内置的分页功能已提供解决方法,而且代码的实现方式相对固定,便于开发者理解和使用。分页功能由Paginator 类实现,我们在 PyCharm 中查看该类的定义过程
-
Paginator类一共定义了4个初始化参数和8个类方法,每个初始化参数和类方法说明如下:
- object_list:必选参数,代表需要进行分页处理的数据,参数值可以为列表、元组或 ORM查询的数据对象等。
- per_page:必选参数,设置每一页的数据量,参数值必须为整型。
- orphans:可选参数,如果最后一页的数据量小于或等于参数 orphans 的值,就将最后一页的数据合并到前一页的数据。比如有 23 行数据,若参数 pet_page=10、orphans=5,则数据分页后的总页数为 2,第一页显示 10 行数据,第二页显示 13 行数据。
- allow_empty_first_page:可选参数,是否允许第一页为空。如果参数值为 False 并且参数
object_list为空列表,就会引发 EmptyPage 错误。 - validate_number():验证当前页数是否大于或等于 1。
- get_page():调用 validate_number() 验证当前页数是否有效,函数返回值调用 page()。
- page():根据当前页数对参数 object_list 进行切片处理,获取页数所对应的数据信息,画数道回值调用 _get_page()。
- _get_page():调用 Page 类,并将当前页数和页数所对应的数据信息传递给 Page类,创建当前页数的数据对象。
- count():获取参数 object_list的数据长度。
- num_pages():获取分页后的总页数。
- page.range():将分页后的总页数生成可循环对象。
- _check_object_list_is_ordered():如果参数 object_list 是 ORM 查询的数据对象,并且该数据对象的数据是无序排列的,就提示警告信息。
-
从 Paginator 类定义的 get_page()、page() 和 _get_page() 得知,三者之间存在调用关系,我
们将它们的调用关系以流程图的形式表示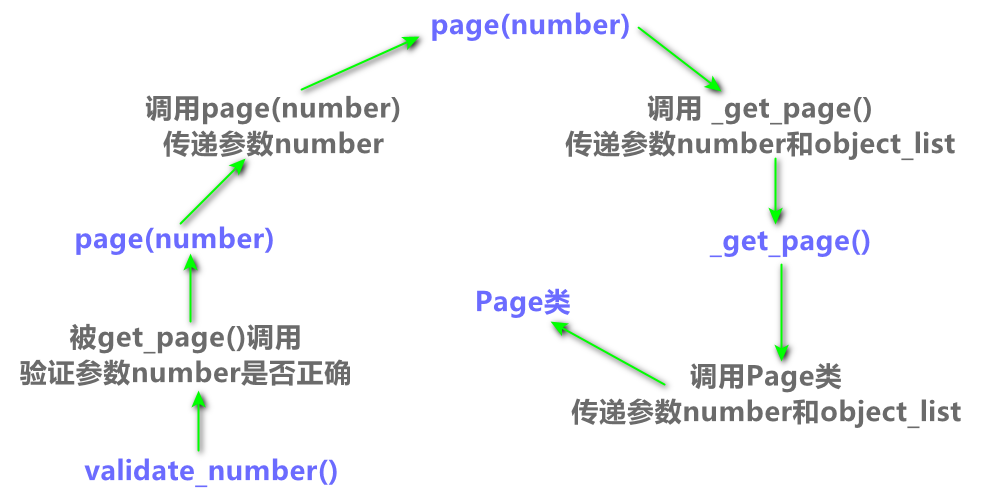
-
-
我们将 Paginator 类实例化之后,再由实例化对象调用 get_page() 即可得到Page 类的实例化对象。在源码文件 paginator.py 中可以找到 Page 类的定义过程,它一共定义了3 个初始化参数和 7 个类方法,每个初始化参数和类方法说明如下。
- object_list:必选参数,代表已切片处理的数据对象。
- number:必选参数,代表用户传递的页数。
- paginator:必选参数,代表 Paginator 类的实例化对象。
- has_next():判断当前页是否存在下一页。
- has_previous():判断当前页是否存在上一页。
- has_other_pages():判断当前页是否存在上一页或者下一页。
- next_page_number():如果当前页存在下一页,就输出下一页的页数,否则抛出 EmptyPage异常。
- previous_page_number():如果当前页存在上一页,就输出上一页的页数,否则抛出
EmptyPage 异常。 - start_index():输出当前页的第一行数据在整个数据列表的位置,数据位置从1开始计算。
- end_index():输出当前页的最后一行数据在整个数据列表的位置,数据位置从1开始计算。
-
上述是从源码的角度剖析分页功能的参数和方法,下一步在 PyCharm 的 Terminal中开启
Django的 Shell 模式,简单地讲述如何使用分页功能,代码如下:In [1]: from django.core.paginator import PaginatorIn [2]: # 生成数据列表In [3]: objects = [chr(x) for x in range(97, 107)]In [4]: objectsOut[4]: ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']In [5]: # 将数据列表以每3个元素分为1页In [6]: p = Paginator(objects, 3)In [7]: p.object_listOut[7]: ['a', 'b', 'c', 'd', 'e', 'f',