模型轻量化全指南:从剪枝量化到低配置设备部署实战

在AI模型向边缘设备(如手机、IoT设备、嵌入式终端)渗透的过程中,“模型太大、算力不足、内存不够”成为核心障碍。模型轻量化技术通过减少参数量、压缩计算量、优化资源占用,让大模型在低配置设备上流畅运行。
本文整合2025年最新实践,系统解析剪枝、量化、知识蒸馏等核心技术,提供从模型优化到硬件部署的全流程指南,附带关键代码与可视化图表,助力开发者实现“小模型、高性能、低消耗”的落地目标。
一、模型轻量化的核心目标与挑战
模型轻量化并非简单“缩小模型”,而是在精度、速度、资源三者间找到平衡。其核心目标与面临的挑战如下:
1.1 轻量化的三大核心目标
| 目标 | 具体指标(以移动端为例) | 业务价值 |
|---|---|---|
| 减小模型体积 | 从1GB压缩至100MB以内(存储占用降低90%) | 减少下载流量,适配低存储设备 |
| 降低计算消耗 | 推理延迟从500ms降至100ms以内,FPS提升5倍以上 | 满足实时性需求(如人脸识别打卡) |
| 减少资源占用 | 内存占用从2GB降至512MB以内,功耗降低60% | 避免设备卡顿、发热,延长续航 |
1.2 低配置设备的典型限制
轻量化的核心挑战源于设备硬件约束,以常见低配置设备为例:
| 设备类型 | CPU/GPU配置 | 内存限制 | 存储限制 | 典型算力(TOPS) |
|---|---|---|---|---|
| 低端智能手机 | 4核ARM Cortex-A53,Mali-G52 | ≤4GB | ≤64GB | 0.5-2 |
| 嵌入式终端 | 2核ARM Cortex-A7,无独立GPU | ≤1GB | ≤16GB | 0.1-0.5 |
| 物联网传感器 | 单核ARM Cortex-M4 | ≤256MB | ≤8GB | 0.01-0.1 |
(图表说明:该表格清晰展示了三类低配置设备的硬件瓶颈,解释了为何需要针对性轻量化——例如物联网传感器的算力仅为高端GPU的万分之一,必须通过极致压缩才能运行AI模型。)
二、核心轻量化技术:剪枝、量化与知识蒸馏
模型轻量化的“三板斧”——参数剪枝、精度量化、知识蒸馏,分别从“移除冗余”“压缩精度”“迁移能力”三个维度实现优化,三者组合可使模型性能提升10倍以上。
2.1 参数剪枝:移除冗余参数
剪枝通过删除对模型输出影响极小的参数(如接近0的权重),在几乎不损失精度的前提下减少参数量。
2.1.1 剪枝的两种核心类型
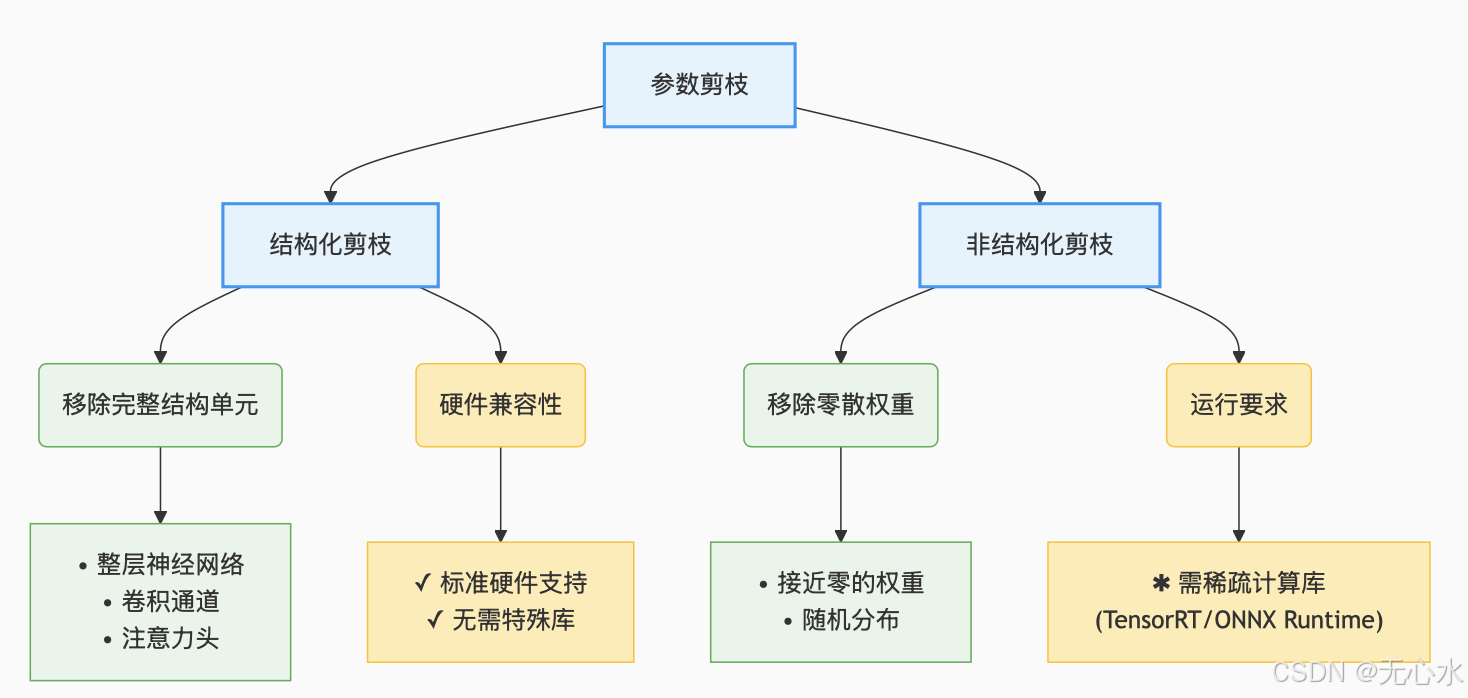
(图表说明:该图展示了剪枝的分类及特点,结构化剪枝更易部署在普通硬件,非结构化剪枝压缩率更高但依赖特殊支持,帮助读者快速选择适合场景的剪枝方式。)
- 结构化剪枝(推荐低配置设备):
移除整个神经元、通道或网络层(如卷积核、注意力头),剪枝后模型结构规则,无需特殊硬件支持。
示例:MobileNetV3的通道剪枝——删除激活值方差小于阈值的通道,参数量减少40%,精度损失<1%。 - 非结构化剪枝(适合高端边缘设备):
随机移除零散权重(如将50%接近0的权重置为0),压缩率更高(可达70%),但需稀疏计算引擎(如TensorRT、ONNX Runtime)加速,否则可能更慢。
2.1.2 剪枝实战代码(PyTorch)
import torch
import torch.nn.utils.prune as prune
from torchvision.models import mobilenet_v3_small# 1. 加载预训练模型(MobileNetV3-small,轻量级基线)
model = mobilenet_v3_small(pretrained=True)
print(f"剪枝前总参数量:{sum(p.numel() for p in model.parameters())/1e6:.2f}M")# 2. 对卷积层执行结构化剪枝(移除30%通道)
for name, module in model.named_modules():if isinstance(module, torch.nn.Conv2d):# 对卷积层的权重按通道剪枝(L1范数作为重要性指标)prune.ln_structured(module, name="weight", amount=0.3, # 剪枝比例30%n=1, # L1范数dim=0 # 按输出通道剪枝(dim=0))# 3. 永久化剪枝(删除被剪枝的参数,而非仅屏蔽)
for name, module in model.named_modules():if isinstance(module, torch.nn.Conv2d) and hasattr(module, 'weight_mask'):prune.remove(module, 'weight')# 4. 剪枝后评估
print(f"剪枝后总参数量:{sum(p.numel() for p in model.parameters())/1e6:.2f}M")# 5. 微调恢复精度(关键步骤!剪枝后需微调3-5个epoch)
# (此处省略数据加载和微调代码,核心是用小学习率训练)
2.1.3 剪枝的关键技巧
- 剪枝比例递增:从10%开始,逐步提高至30%-50%,避免一次性剪枝过多导致精度暴跌。
- 重要性指标选择:优先用“权重×梯度”(参数对损失的影响)而非单纯权重绝对值,更准确衡量重要性。
- 结合任务特性:分类任务对剪枝更敏感,检测/分割任务可适当提高剪枝比例(如目标检测模型可剪枝50%通道)。
2.2 精度量化:压缩数值表示
量化通过降低参数和计算的数值精度(如从32位浮点数FP32转为8位整数INT8),实现存储和计算量的指数级降低。
2.2.1 量化的三种主流方式
| 量化类型 | 原理 | 精度损失 | 适用场景 | 部署难度 |
|---|---|---|---|---|
| 训练后量化 | 用校准数据计算量化参数(如缩放因子) | 中(3%-5%) | 快速部署,对精度要求不高的场景 | 低 |
| 动态量化 | 推理时实时量化激活值,权重提前量化 | 中低(2%-4%) | 全连接层为主的模型(如BERT) | 中 |
| 量化感知训练 | 训练中加入伪量化节点,模拟量化误差 | 低(<2%) | 高精度要求场景(如医疗影像识别) | 高 |
(图表说明:该表格对比了三种量化方式的核心差异,帮助读者根据精度需求和开发成本选择——例如快速原型验证用训练后量化,生产环境用量化感知训练。)
2.2.2 量化实战代码(PyTorch与Hugging Face)
- PyTorch静态量化(图像模型):
import torch
from torchvision.models import resnet18# 1. 准备模型和校准数据(需10-100个样本)
model = resnet18(pretrained=True).eval()
calibration_data = [torch.randn(1, 3, 224, 224) for _ in range(32)] # 校准数据# 2. 准备量化
model.qconfig = torch.quantization.get_default_qconfig('fbgemm') # x86平台配置
model_prepared = torch.quantization.prepare(model)# 3. 校准(计算量化参数)
with torch.no_grad():for data in calibration_data:model_prepared(data)# 4. 转换为量化模型
model_quantized = torch.quantization.convert(model_prepared)# 5. 验证效果(存储减少75%,速度提升2-4倍)
torch.save(model_quantized.state_dict(), 'resnet18_int8.pth')
- 大语言模型4-bit量化(Hugging Face):
from transformers import AutoModelForCausalLM, AutoTokenizer# 加载6B参数模型,用4-bit量化(显存仅需6GB,适合低端GPU)
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen1.5-6B",device_map="auto",load_in_4bit=True, # 启用4-bit量化quantization_config=BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_use_double_quant=True, # 双重量化,进一步压缩bnb_4bit_quant_type="nf4", # 针对大模型优化的量化类型bnb_4bit_compute_dtype=torch.float16 # 计算用半精度,平衡速度与精度)
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-6B")# 测试推理
inputs = tokenizer("低配置设备如何运行大模型?", return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
2.2.3 量化的进阶优化
- 混合精度量化:对敏感层(如输出层)用FP16,非敏感层用INT8,平衡精度与速度。
- 动态缩放因子:对激活值范围差异大的层(如ReLU6后的输出),使用层内动态缩放而非全局缩放,减少量化误差。
- 量化友好模型设计:避免使用过大激活值的激活函数(如ReLU替换为ReLU6),降低量化溢出风险。
2.3 知识蒸馏:小模型学大模型
知识蒸馏通过“教师模型(大模型)指导学生模型(小模型)”,让小模型学到大模型的泛化能力,精度接近大模型但体积仅为1/10。
2.3.1 蒸馏原理与流程
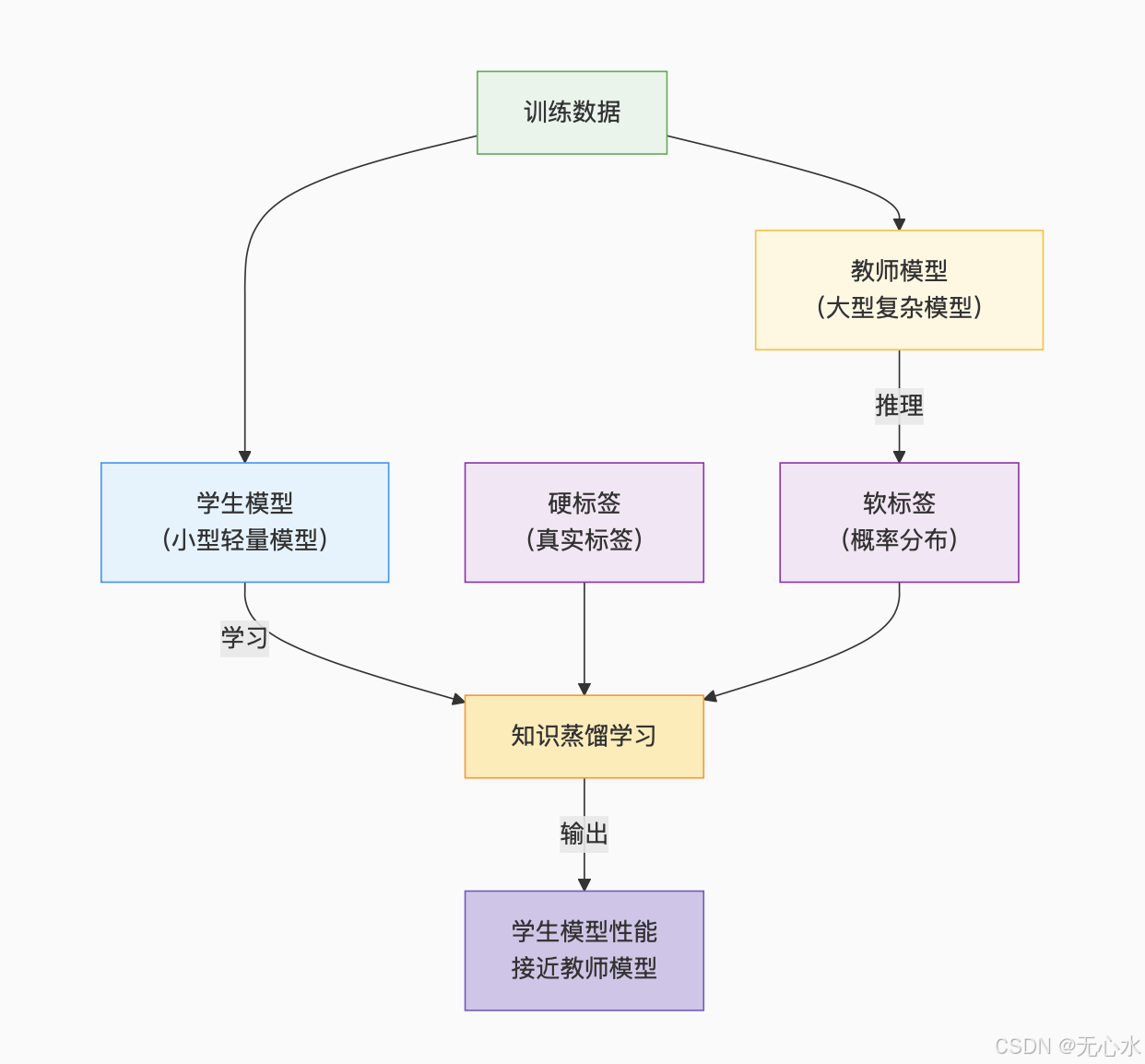
(图表说明:该图展示了知识蒸馏的核心逻辑——学生模型同时学习真实标签(硬标签)和教师模型的输出分布(软标签),相比仅学硬标签能获得更多类别间关系信息,从而在小体积下保持高精度。)
2.3.2 蒸馏实战代码(图像分类)
import torch
import torch.nn as nn
from torchvision.models import resnet50, mobilenet_v3_small# 1. 定义教师模型(大模型)和学生模型(小模型)
teacher_model = resnet50(pretrained=True).eval() # 教师:ResNet50(25M参数)
student_model = mobilenet_v3_small(pretrained=False) # 学生:MobileNetV3(2.5M参数)# 2. 定义蒸馏损失(硬标签损失+软标签损失)
def distillation_loss(student_output, teacher_output, true_labels, temperature=3.0):# 软标签损失(KL散度,衡量学生与教师输出分布差异)soft_loss = nn.KLDivLoss(reduction="batchmean")(torch.log_softmax(student_output / temperature, dim=1),torch.softmax(teacher_output / temperature, dim=1)) * (temperature ** 2) # 温度系数放大差异# 硬标签损失(交叉熵,保证学生学到真实标签)hard_loss = nn.CrossEntropyLoss()(student_output, true_labels)# 混合损失(软标签权重0.7,硬标签0.3)return 0.7 * soft_loss + 0.3 * hard_loss# 3. 蒸馏训练
optimizer = torch.optim.Adam(student_model.parameters(), lr=1e-4)
for epoch in range(10):student_model.train()total_loss = 0.0for images, labels in train_loader:# 教师模型生成软标签(不更新参数)with torch.no_grad():teacher_output = teacher_model(images)# 学生模型前向传播student_output = student_model(images)# 计算蒸馏损失loss = distillation_loss(student_output, teacher_output, labels)# 反向传播与优化optimizer.zero_grad()loss.backward()optimizer.step()total_loss += loss.item()print(f"Epoch {epoch}, Loss: {total_loss/len(train_loader):.4f}")
2.3.3 蒸馏的关键技巧
- 温度系数调优:温度越高(如5-10),软标签分布越平缓,适合类别多的任务(如1000类分类);温度越低(如2-3),适合类别少的任务(如10类分类)。
- 教师模型选择:优先用“略大于需求”的教师模型(如学生是MobileNetV3,教师用ResNet50而非ResNet152),避免蒸馏难度过高。
- 中间层蒸馏:除输出层外,让学生模型的中间特征图模仿教师模型(如用MSE损失约束卷积层输出),进一步提升精度。
三、高效模型架构设计:从源头减少冗余
轻量化不仅依赖“压缩已有模型”,更需从设计源头优化——轻量级基础模块和专用架构可在相同精度下减少80%的计算量。
3.1 轻量级基础模块
| 模块名称 | 原理 | 计算量减少 | 代表模型 |
|---|---|---|---|
| 深度可分离卷积 | 将标准卷积拆分为“深度卷积(单通道)+逐点卷积(1x1)” | 8-9倍 | MobileNetV1/V2/V3 |
| 倒残差结构 | 先升维(1x1卷积)→ 深度卷积 → 降维(1x1卷积) | 3-5倍 | MobileNetV2/V3, EfficientNet |
| 通道混洗 | 组卷积后打乱通道顺序,促进组间信息交流 | 2-3倍 | ShuffleNetV1/V2 |
| 注意力压缩 | 用全局平均池化替代全连接层计算注意力 | 10-20倍 | MobileNetV3的SE模块简化版 |
(图表说明:该表格解析了四类核心轻量级模块的优化逻辑,例如深度可分离卷积通过“拆分卷积操作”将计算量从Dk×Dk×Cin×Cout×H×W降至Dk×Dk×Cin×H×W + Cin×Cout×H×W,适合移动端算力有限的场景。)
3.2 经典轻量级模型推荐
根据任务类型和设备性能,选择开箱即用的轻量级模型可大幅降低开发成本:
- 图像分类:
- 极致轻量化:MobileNetV3-Small(2.5M参数)、EfficientNet-Lite0(4.7M参数)
- 平衡精度与速度:GhostNet(5.2M参数)、ShuffleNetV2(1.4M参数)
- 目标检测:
- 移动端首选:YOLOv5n(1.9M参数)、YOLOv8n(3.2M参数)
- 嵌入式终端:YOLOv7-Tiny(6.0M参数)、NanoDet(0.9M参数)
- 自然语言处理:
- 文本分类:DistilBERT(66M参数,BERT的60%精度,33%参数)
- 轻量对话:Phi-2(2.7B参数,INT4量化后仅1.3GB)、ChatGLM3-6B(INT4量化后6GB)
3.3 模型定制化设计原则
当现有模型无法满足需求时,可按以下原则设计专用轻量级模型:
- 分辨率优先缩减:输入图像分辨率从224×224降至112×112,计算量减少75%(平方级降低),适合对细节不敏感的任务(如人脸检测)。
- 平衡深度与宽度:增加层数(深度)比增加通道数(宽度)更高效(如MobileNetV3通过“窄而深”设计提升性能)。
- 动态架构适配:在不同设备上自动调整模型深度(如高端手机用20层,低端手机用10层),通过代码实现:
# 动态调整模型深度示例 class DynamicMobileNet(nn.Module):def __init__(self, device_level): # device_level: 0(低端)-2(高端)super().__init__()self.stages = nn.ModuleList()# 根据设备等级调整阶段数(深度)stage_counts = [3, 5, 7] # 低端3层,中端5层,高端7层for i in range(stage_counts[device_level]):self.stages.append(MBConvBlock(kernel_size=3 if i%2==0 else 5))
四、推理引擎与硬件加速:释放轻量化模型性能
优化后的模型需配合高效推理引擎和硬件加速,才能在低配置设备上发挥最大性能——相同模型在不同引擎上的速度可相差5-10倍。
4.1 主流推理引擎对比与选择
| 推理引擎 | 支持平台 | 核心优势 | 量化支持 | 硬件加速能力 | 适合场景 |
|---|---|---|---|---|---|
| TensorFlow Lite | 移动端、嵌入式 | 体积小(<1MB),NNAPIDelegate支持 | INT8/FP16 | 支持ARM NEON、Mali GPU、高通DSP | 手机APP、IoT设备 |
| ONNX Runtime | 跨平台 | 兼容性强(支持ONNX模型) | INT4/INT8/FP16 | 支持CUDA、DirectML、CPU优化 | 多平台部署、需要灵活适配的场景 |
| PyTorch Mobile | 移动端 | 与PyTorch无缝衔接 | INT8 | 支持ARM NEON、Metal(iOS) | 用PyTorch训练的模型部署 |
| OpenVINO | 英特尔设备 | 针对x86/Atom优化 | INT8/FP16 | 支持英特尔集成GPU、VPU | 工业嵌入式(如英特尔凌动平台) |
| TensorRT | NVIDIA设备 | 算子融合与INT8优化极强 | INT8/FP16 | 支持NVIDIA GPU(含Jetson系列) | 高端边缘设备(如Jetson Nano) |
(图表说明:该表格帮助读者根据硬件平台选择推理引擎——例如开发安卓APP优先用TensorFlow Lite,NVIDIA Jetson设备必选TensorRT,跨平台部署则用ONNX Runtime。)
4.2 硬件加速Delegate配置
推理引擎通过“Delegate”机制将计算卸载到设备的硬件加速器(如NPU、GPU),性能提升3-10倍:
- TensorFlow Lite启用GPU Delegate(安卓):
// Java代码:在安卓中启用GPU加速
TensorFlowLite.Interpreter.Options options = new TensorFlowLite.Interpreter.Options();
GpuDelegate.Options gpuOptions = new GpuDelegate.Options();
options.addDelegate(new GpuDelegate(gpuOptions)); // 启用GPU加速
Interpreter interpreter = new Interpreter(loadModelFile(), options);
- ONNX Runtime启用NPU加速(华为设备):
# Python代码:华为设备启用NPU加速
import onnxruntime as ort# 配置NPU执行 providers
sess_options = ort.SessionOptions()
sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
session = ort.InferenceSession("model.onnx",sess_options,providers=["HuaweiAscendExecutionProvider"] # 启用华为NPU
)
4.3 图优化与算子融合
推理引擎的“图优化”可自动优化模型计算流程,无需修改模型即可提升性能:
- 核心优化手段:
- 常量折叠:预计算模型中的常量操作(如固定权重的卷积),减少 runtime 计算。
- 算子融合:将连续操作(如Conv2D + BatchNorm + ReLU)融合为单个算子,减少内存读写。
- 死代码消除:移除模型中未被使用的层或分支。
- 效果示例:MobileNetV3经TensorRT优化后,Conv2D+BN+ReLU的融合使推理速度提升40%,内存访问减少60%。
五、工程实践:从优化到部署的全流程
模型轻量化是“技术组合+迭代调优”的过程,需结合设备特性制定针对性方案,以下是标准化流程:
5.1 轻量化全流程步骤
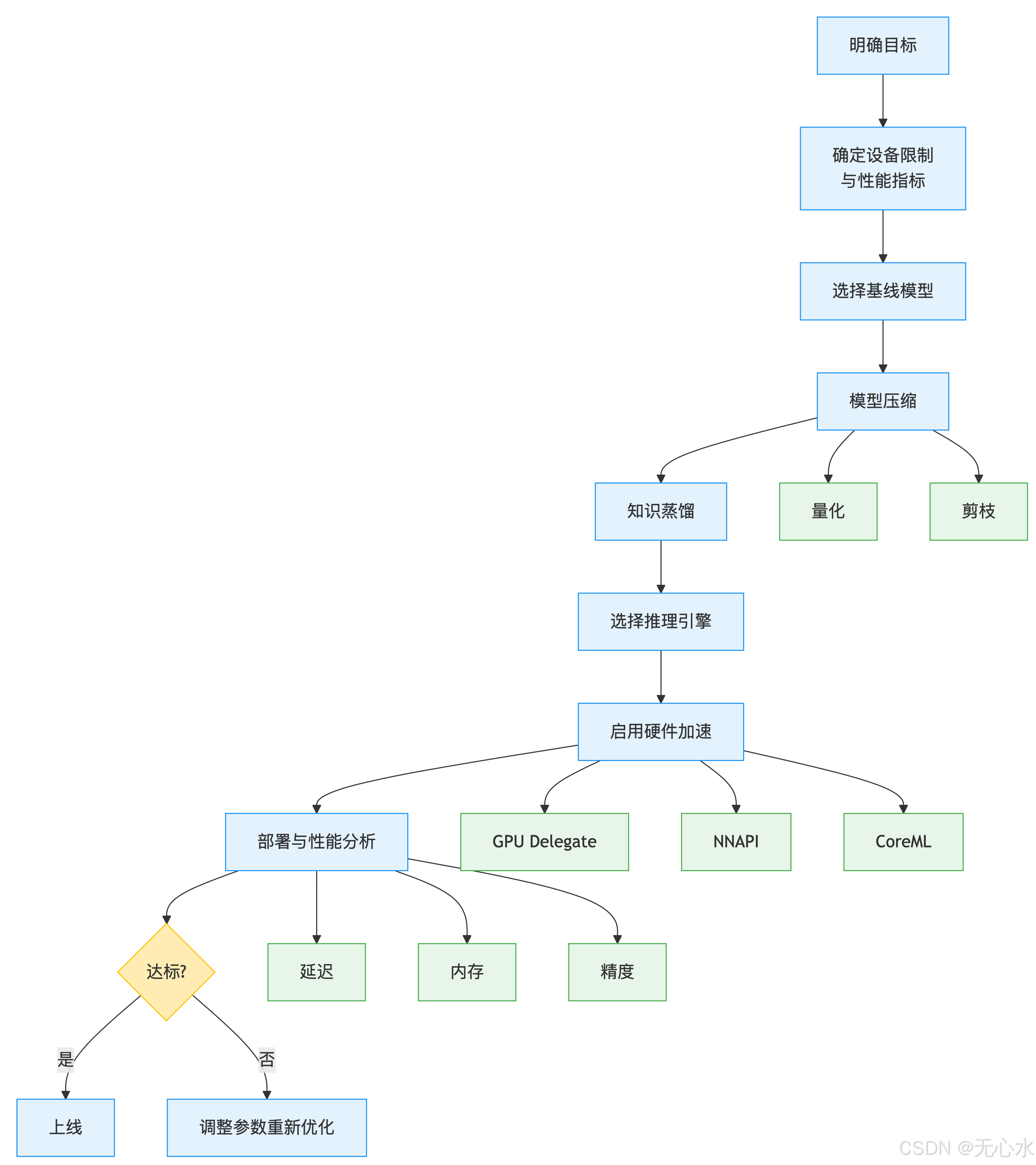
(图表说明:该流程图展示了从目标设定到上线的完整流程,强调“性能分析→迭代优化”的闭环——例如首次部署后若延迟不达标,需重新调整剪枝比例或更换推理引擎。)
全流程步骤说明:
- 明确目标:确定应用场景需求
- 设备限制:明确硬件约束(算力/内存)
- 基线模型:选择适合的基础模型架构
- 模型压缩:
- 量化:FP32→INT8降低计算精度
- 剪枝:移除冗余参数
- 知识蒸馏:大模型指导小模型(可选)
- 推理引擎:选择TensorRT/ONNX等
- 硬件加速:
- GPU Delegate(移动端)
- NNAPI(Android)
- CoreML(iOS)
- 部署分析:评估延迟/内存/精度
- 达标判断:满足要求则上线,否则调整参数重新优化
5.2 关键工程技巧
- 内存优化:
- 内存复用:通过推理引擎配置(如TFLite的
allow_fp16_relax_to_fp32)复用中间张量内存,峰值内存减少50%。 - 模型分片:对超大模型(如1B参数),按层拆分并按需加载(如先加载特征提取层,再加载分类层),降低峰值内存。
- 内存复用:通过推理引擎配置(如TFLite的
- 精度-速度平衡策略:
- 分场景适配:例如手机解锁场景优先保证速度(可接受5%精度损失),而医疗诊断场景必须保证精度(仅用轻度量化)。
- 动态切换:根据设备负载自动调整精度(如设备空闲时用FP16,高负载时切换为INT8)。
- 性能分析工具:
- 移动端:Android Profiler(分析CPU/GPU占用)、TFLite Benchmark Tool(测量延迟与吞吐量)。
- 嵌入式:TensorRT Profiler(算子耗时分析)、ONNX Runtime Profiler(瓶颈定位)。
5.3 实战案例:低端手机部署目标检测模型
场景:在内存2GB、4核ARM处理器的低端安卓手机上,部署实时目标检测模型(延迟<300ms)。
步骤:
- 选择基线模型:YOLOv5n(1.9M参数,原始延迟500ms)。
- 量化优化:用量化感知训练将模型转为INT8,延迟降至350ms,精度损失1.2%。
- 剪枝优化:移除20%冗余通道,参数量降至1.5M,延迟降至280ms。
- 推理引擎配置:使用TensorFlow Lite,启用NNAPI Delegate(利用ARM NEON指令),延迟进一步降至220ms。
- 输入分辨率调整:将输入从640×640降至480×480,延迟最终降至180ms,满足需求。
六、常见问题与避坑指南
模型轻量化实践中,常因对技术细节的忽视导致效果不佳,以下是高频问题的解决方案:
| 问题现象 | 根源分析 | 解决方案 |
|---|---|---|
| 量化后精度暴跌(>10%) | 激活值范围过大或存在异常值 | 1. 用量化感知训练替代训练后量化;2. 对激活值进行Clipping(截断极端值);3. 改用混合精度量化 |
| 剪枝后模型速度未提升 | 非结构化剪枝未用稀疏引擎 | 1. 改用结构化剪枝;2. 部署时启用稀疏计算库(如TensorRT的稀疏模式) |
| 推理引擎启动时间过长 | 模型加载未优化 | 1. 预加载模型到内存;2. 使用模型序列化(如TFLite的FlatBuffer格式);3. 启用引擎预热 |
| 硬件加速Delegate不生效 | 模型算子不支持或配置错误 | 1. 检查Delegate支持的算子列表(如TFLite GPU不支持动态形状);2. 简化模型算子(如用ReLU替代Swish) |
| 蒸馏后学生模型精度低于预期 | 教师模型与学生模型差距过大 | 1. 选择更接近学生规模的教师模型;2. 增加蒸馏轮次;3. 加入中间层蒸馏损失 |
七、总结
模型轻量化是AI技术落地低配置设备的“最后一公里”,其核心并非单一技术,而是剪枝、量化、蒸馏、架构设计、引擎优化的系统组合。通过本文的技术指南,开发者可根据设备特性(如内存、算力)和业务需求(如精度、延迟),制定针对性方案——从选择MobileNet等轻量级基线,到用INT8量化+结构化剪枝压缩模型,再到通过TensorFlow Lite+NNAPI释放硬件性能,最终实现“小而强”的AI部署。
随着边缘计算与嵌入式AI的发展,轻量化技术将向“更智能、更自动化”演进(如自动搜索最优量化参数、动态适配不同设备的架构),但当前阶段,“理解技术原理+结合实践调优”仍是开发者的核心竞争力。
附录:轻量化技术速查表
| 设备类型 | 推荐技术组合 | 预期效果 |
|---|---|---|
| 低端手机 | INT8量化 + MobileNetV3 + TFLite GPU | 延迟<300ms,精度损失<3% |
| 嵌入式终端 | INT4量化 + 结构化剪枝 + ONNX Runtime | 内存<512MB,功耗降低60% |
| 物联网传感器 | 知识蒸馏 + 极致剪枝 + 固定点计算 | 模型体积<10MB,推理电流<100mA |