《汇编语言:基于X86处理器》第8章 高级过程(3)
8.6参数的高级用法(可选主题)
本节将讨论 32 位模式中,向运行时堆栈传递参数时一些不常遇见的情况。比如,在查看由C和C++编译器创建的代码时,就有可能发现其中用到了将在下面说明的技术。
8.6.1 受USES运算符影响的堆栈
第5章的USES运算符列出了在过程开始保存、结尾恢复的寄存器名。汇编器自动为每个列出的寄存器生成相应的 PUSH 和 POP 指令。但是必须注意的是:如果过程用常数偏移量访问其堆栈参数,比如 [ebp+8],那么声明该过程时不能使用 USES 运算符。现在举例说明其原因。下面的MySub1过程用USES运算符保存和恢复ECX和EDX:
MySub1 PROC USES ecx edx ret
MySub1 ENDP当 MASM 汇编 MySub1 时,生成代码如下:
push ecx
push edx
pop edx
pop ecx
ret假设在使用USES 的同时还使用了堆栈参数,如 MySub2 过程所示,该参数预期保存的堆栈地址为EBP+8:
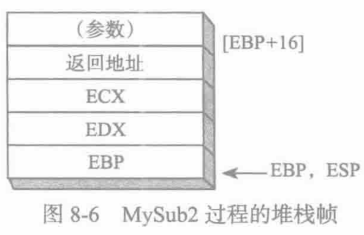
MySub2 PROC USES ecx edxpush ebp ;保存基址指针mov ebp, esp ;堆栈帧基址mov eax, [ebp+8] ;取堆栈参数pop ebp ;恢复基址指针ret 4 ;清除堆栈
MySub2 ENDP则MASM为MySub2生成的相应代码如下:
push ecx
push edx
push ebp
mov ebp, esp
mov eax, dword ptr [ebp+8] ;错误地址!
pop ebp
pop edx
pop ecx
ret 4生变化,从而导致结果错误。图8-6 说明了为什么堆栈参数现在必须以[EBP+16] 来引用。USES 在保存EBP之前修改了堆栈,破坏了子程序常用的标准开始代码。
提示 本章较早部分给出了PROC伪指令声明堆栈参数的高级语法。在那种情况下,USES 运算符不会带来问题。
完整代码测试笔记
;8.6.1.asm 8.6.1 受USES运算符影响的堆栈INCLUDE Irvine32.inc.code
MySub1 PROC USES ecx edxret
MySub1 ENDP
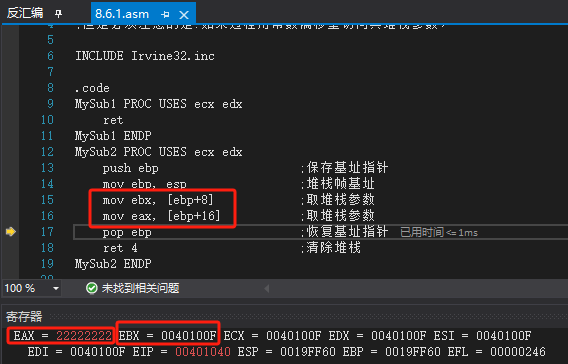
MySub2 PROC USES ecx edxpush ebp ;保存基址指针mov ebp, esp ;堆栈帧基址mov ebx, [ebp+8] ;取堆栈参数mov eax, [ebp+16] ;取堆栈参数pop ebp ;恢复基址指针ret 4 ;清除堆栈
MySub2 ENDPmain PROCINVOKE MySub1push 22222222hINVOKE MySub2mov ebx, eaxINVOKE ExitProcess,0
main ENDPEND main
运行调试:
8.6.2 向堆栈传递8位和16 位参数
32 位模式中,向过程传递堆栈参数时,最好是压入 32 位操作数。虽然也可以将 16 位操作数人栈,但是这样会使得EBP 不能对齐双字边界,从而可能导致出现页面失效、降低运行时性能。因此,在入栈之前,要把操作数扩展为32 位。下面的 Uppercase 过程接收一个字符参数,并用AL返回其大写字母:
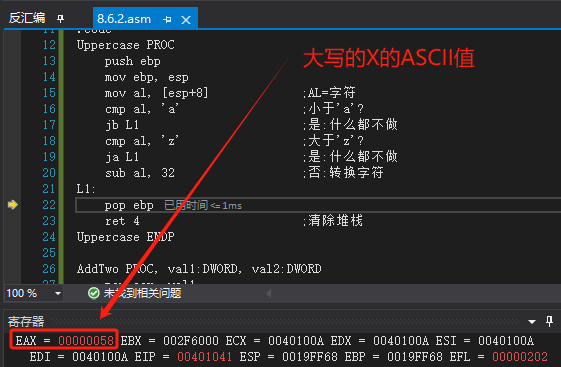
Uppercase PROC push ebp mov ebp, espmov al, [esp+8] ;AL=字符cmp al, 'a' ;小于'a'?jb L1 ;是:什么都不做cmp al, 'z' ;大于'z'?ja L1 ;是:什么都不做sub al, 32 ;否:转换字符
L1:pop ebpret 4 ;清除堆栈
Uppercase ENDP当向Uppercase传递一个字母字符时,PUSH 指令自动将其扩展为32位:
push 'x'
call Uppercase如果传递的是字符变量就需要更小心一些,因为PUSH指令不允许操作数为8位:
.data
charVal BYTE 'x'
.code
push charVal ;语法错误!error A2070: invalid instruction operands
call Uppercase相反,要用MOVZX把字符扩展到EAX:
movzx eax, charVal ;扩展并传送
push eax
call Uppercase16 位参数示例
假设现在想向之前给出的 AddTwo 过程传递两个16位整数。由于该过程期望的数值为32 位,所以下面的调用会发生错误:
.data
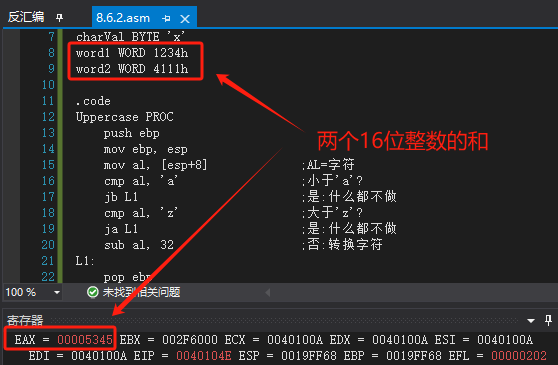
word1 WORD 1234h
word2 WORD 4111h
.code
push word1
push word2
call AddTwo ;错误!因此,可以在每个参数入栈之前进行全零扩展。下面的代码将会正确调用AddTwo:
movzx eax, word1
push eax
movzx eax, word2
push eax
call AddTwo ;EAX为和数一个过程的主调者必须保证它传递的参数与过程期望的参数是一致的。对堆栈参数而言,参数的顺序和大小都很重要!
完整代码测试笔记
;8.6.2.asm 8.6.2 向堆栈传递8位和16 位参数
;下面的 Uppercase 过程接收一个字符参数,并用AL返回其大写字母INCLUDE Irvine32.inc.data
charVal BYTE 'x'
word1 WORD 1234h
word2 WORD 4111h.code
Uppercase PROC push ebp mov ebp, espmov al, [esp+8] ;AL=字符cmp al, 'a' ;小于'a'?jb L1 ;是:什么都不做cmp al, 'z' ;大于'z'?ja L1 ;是:什么都不做sub al, 32 ;否:转换字符
L1:pop ebpret 4 ;清除堆栈
Uppercase ENDPAddTwo PROC, val1:DWORD, val2:DWORDmov eax, val1add eax, val2ret
AddTwo ENDPmain PROCpush 'y'call Uppercase;push charVal ;语法错误!error A2070: invalid instruction operands;call Uppercasemovzx eax, charVal ;扩展并传送push eaxcall Uppercase;16位参数示例push word1push word2call AddTwo ;错误!movzx eax, word1push eaxmovzx eax, word2push eaxcall AddTwo ;EAX为和INVOKE ExitProcess,0
main ENDPEND main
运行调试:
16位参数传递:
8.6.3 传递 64 位参数
32 位模式中,通过堆栈向子程序传递 64 位参数时,先将参数的高位双字入栈,再将其低位双字人栈。这样就使得整数在堆栈中是按照小端顺序(低字节在低地址)存放的,因而子程序容易检索到这些数值,如同下面的 WriteHex64过程操作一样。该过程用十六进制显示 64 位整数:
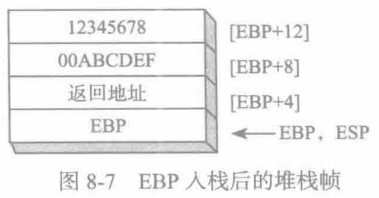
WriteHex64 PROCpush ebpmov ebp, espmov eax, [ebp+12] ;高位双字call WriteHexmov eax, [ebp+8] ;低位双字call WriteHexpop ebpret 8WriteHex64 ENDPWriteHex64 的调用示例如下,它先把 longVal 的高半部分入栈,再把 longVal 的低半部分入栈:
.data
longVal QWORD 123456789ABCDEFh
.code
push DWORD PTR longVal+4 ;高位双字
push DWORD PTR longVal ;低位双字
call WriteHex64图8-7显示的是在EBP 入栈,并把ESP复制给EBP 之后,WriteHex64的堆栈帧示意图。
完整代码测试笔记
;8.6.3.asm 8.6.3 传递 64 位参数
;WriteHex64 的调用示例如下,它先把 longVal 的高半部分入栈,
;再把 longVal 的低半部分入栈:INCLUDE Irvine32.inc.data
longVal QWORD 123456789ABCDEFh.code
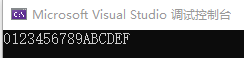
WriteHex64 PROCpush ebpmov ebp, espmov eax, [ebp+12] ;高位双字call WriteHexmov eax, [ebp+8] ;低位双字call WriteHexcall Crlfpop ebpret 8
WriteHex64 ENDPmain PROCpush DWORD PTR longVal+4 ;高位双字push DWORD PTR longVal ;低位双字call WriteHex64INVOKE ExitProcess,0
main ENDPEND main
运行结果:
8.6.4 非双字局部变量
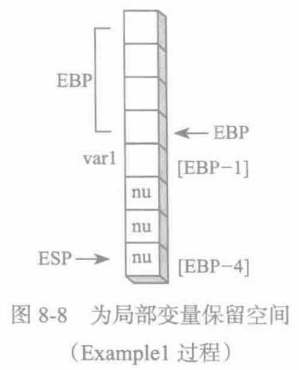
在声明不同大小的局部变量时,LOCAL 伪指令的操作会变得很有趣。每个变量都按照其大小来分配空间:8位的变量分配给下一个可用的字节,16 位的变量分配给下一个偶地址(字对齐),32 位变量分配给下一个双字对齐的地址。现在来看几个例子。首先,Example 过程含有一个局部变量varl类型为BYTE:
Example1 PROCLOCAL var1:bytemov al, var1 ;[EBP-1]ret
Example1 ENDP由于32位模式中,堆栈偏移量默认为32位,因此,var1可能被认为会存放于EBP-4的位置。实际上,如图8-8所示,MASM将EBP减去4,但是却把var1存放在EBP-1,其下面的三个字节并未使用(用nu标记,表示没有使用)。图中,每个方块表示一个字节。
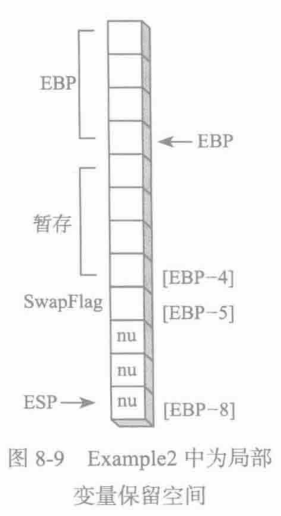
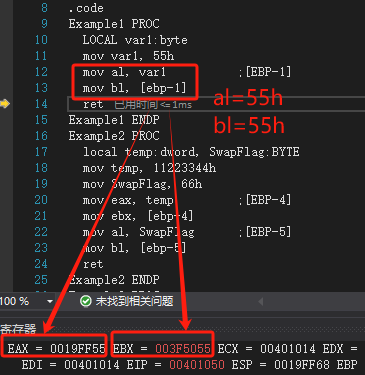
过程Example2含一个双字局部变量和一个字节局部变量:
Example2 PROClocal temp:dword, SwapFlag:BYTE..ret
Example2 ENDP汇编器为Example2生成的代码如下所示。ADD指令将ESP加-8,在ESP和EBP之间为这两个局部变量预留了空间:
push ebp
mov ebp, esp
add esp, 0FFFFFFF8h ;ESP+(-8)
mov eax, [ebp-4] ;temp
mov bl, [ebp-5] ;SwapFlag
leave ;mov esp, ebp; pop ebp
ret虽然SwapFlag只是一个字节变量,但是ESP还是会下移到堆栈中下一个双字的位置。图8-9以字节为单位详细展示了堆栈的情况:SwapFlag确切的位置以及位于其下方的三个没有使用的空间(用m标记)。图中,每个方块表示一个字节。
完整代码测试笔记
;8.6.4.asm 8.6.4非双字局部变量
;在声明不同大小的局部变量时,LOCAL 伪指令的操作会变得很有趣。
;每个变量都按照其大小来分配空间:8位的变量分配给下一个可用的字节,16 位的变量分配给下一个偶地址(字对齐),
;位变量分配给下一个双字对齐的地址。现在来看几个例子。首先,Example 过程含有一个局部变量varl类型为BYTE:INCLUDE Irvine32.inc.code
Example1 PROCLOCAL var1:bytemov var1, 55hmov al, var1 ;[EBP-1]mov bl, [ebp-1]ret
Example1 ENDP
Example2 PROClocal temp:dword, SwapFlag:BYTEmov temp, 11223344hmov SwapFlag, 66hmov eax, temp ;[EBP-4]mov ebx, [ebp-4]mov al, SwapFlag ;[EBP-5]mov bl, [ebp-5]ret
Example2 ENDP
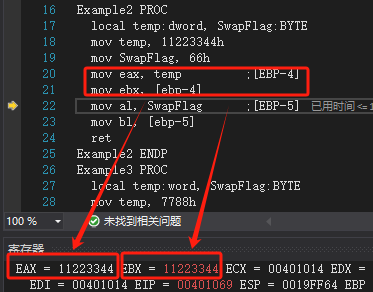
Example3 PROClocal temp:word, SwapFlag:BYTEmov temp, 7788hmov SwapFlag, 66hmov ax, temp ;[EBP-2]mov bx, [ebp-2]mov al, SwapFlag ;[EBP-3]mov bl, [ebp-3]ret
Example3 ENDP
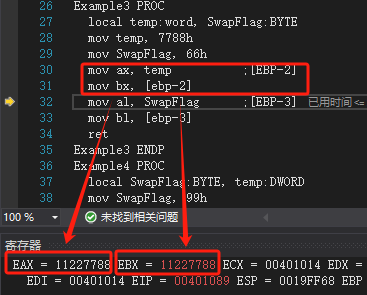
Example4 PROClocal SwapFlag:BYTE, temp:DWORD mov SwapFlag, 99hmov temp, 11223344hmov al, SwapFlag ;[EBP-1]mov bl, [ebp-1]mov eax, temp ;[EBP-8]mov ebx, [ebp-8]ret
Example4 ENDP
main PROCINVOKE Example1INVOKE Example2INVOKE Example3INVOKE Example4mov ebx, eaxINVOKE ExitProcess,0
main ENDPEND main
运行调试:
Example2调试
Example3调试
Example4调试
如果要创建超过几百字节的数组作为局部变量,那么一定要确保为运行时堆栈预留足够的空间。此时可以使用STACK伪指令。比如,在Irvine32链接库中,要预留4096个字节的堆空间:
.stack 4096
对嵌套调用来说,不论程序执行到哪一步,运行时堆栈都必须大到能够容纳下全部的活跃局部变量。比如在下面的代码中,Sub1调用Sub2,Sub2调用Sub3,每个过程都有一个局部数组变量:
Sub1 PROC
local array1[50]:dword ;200字节
call Sub2
.
.
ret
Sub1 ENDP
Sub2 PROC
local array2[80]:word ;160字节
call Sub3
.
.
ret
Sub2 ENDP
Sub3 PROC
local array3[300]:dword ;1200字节
.
.
ret
Sub3 ENDP当程序进入 Sub3 时,运行时堆栈中有来自 Sub1、Sub2 和 Sub3 的全部局部变量。那么堆栈总共需要:1560个字节保存局部变量,加上两个过程的返回地址(8 字节),还要加上在过程中入栈的所有寄存器占用的空间。若过程为递归调用,则堆栈空间大约为其局部变量与参数总的大小乘以预计的递归次数。
8.7 Java字节码(可选主题)
8.7.1 Java虚拟机
Java 虚拟机(JVM)是执行已编译Java 字节码的软件。它是 Java 平台的重要组成部分,包括程序、规范、库和数据结构,让它们协同工作。Java字节码是指编译好的Java程序中使用的机器语言的名字。
虽然本书的内容为x86处理器的原生汇编语言,但是了解其他机器架构如何工作也是有益的。JVM 是基于堆栈机器的首选示例。JVM 用堆栈实现数据传送、算术运算、比较和分支操作,而不是用寄存器来保存操作数(如同x86一样)。
JVM 执行的编译程序包含了 Java 字节码。每个 Java 源程序都必须编译为Java 字节码(形式为class文件)后才能执行。包含Java字节码的程序可以在任何安装了Java 运行时软件的计算机系统上执行。
例如,一个Java 源文件名为Account.java,编译为文件Account.class。这个类文件是该类中每个方法的字节码流。JVM可能选择实时编译(just-in-time compilation)技术把类字节码编译为计算机的本机机器语言。
正在执行的 Java 方法有自己的堆栈帧存放局部变量、操作数栈、输入参数、返回地址和返回值。操作数区实际位于堆栈顶端,因此,压入这个区域的数值可以作为算术和逻辑运算的操作数,以及传递给类方法的参数。
在局部变量被算术运算指令或比较指令使用之前,它们必须被压入堆栈帧的操作数区域。从现在开始,本书把这个区域称为操作数栈(operand stack)。
Java 字节码中,每条指令包含1字节的操作码、零个或多个操作数。操作码可以用Java 反汇编工具显示名字,如 iload、istore、imul 和goto。每个堆栈项为4字节(32位)。
查看反汇编字节码
Java 开发工具包(JDK)中的工具javap.exe 可以显示java.class 文件的字节码,这个操作被称为文件的反汇编。命令行语法如下所示:
javap -c classname
比如,若类文件名为Account.class,则相应的javap命令行为
javap -c Account
安装Java开发工具包后,可以在\bin文件夹下找到javap.exe工具。
完整代码测试笔记
//Account.java 8.7.1 Java虚拟机 Java 源文件名为Account.java,编译为文件Account.class。
//这个类文件是该类中每个方法的字节码流。public class Account {public static void main(String[]args) {String name = "Tom";int age = 27;System.out.println("name = " + name);System.out.println("age = " + age);}
}
编译运行:
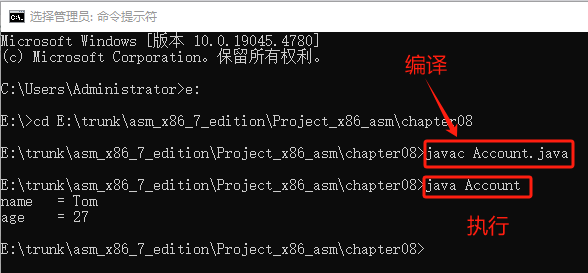
查看反汇编
E:\trunk\asm_x86_7_edition\Project_x86_asm\chapter08>javap -c Account
Compiled from "Account.java"
public class Account {public Account();Code:0: aload_01: invokespecial #1 // Method java/lang/Object."<init>":()V4: returnpublic static void main(java.lang.String[]);Code:0: ldc #2 // String Tom2: astore_13: bipush 275: istore_26: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;9: new #4 // class java/lang/StringBuilder12: dup13: invokespecial #5 // Method java/lang/StringBuilder."<init>":()V16: ldc #6 // String name =18: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;21: aload_122: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;25: invokevirtual #8 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;28: invokevirtual #9 // Method java/io/PrintStream.println:(Ljava/lang/String;)V31: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;34: new #4 // class java/lang/StringBuilder37: dup38: invokespecial #5 // Method java/lang/StringBuilder."<init>":()V41: ldc #10 // String age =43: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;46: iload_247: invokevirtual #11 // Method java/lang/StringBuilder.append:(I)Ljava/lang/StringBuilder;50: invokevirtual #8 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;53: invokevirtual #9 // Method java/io/PrintStream.println:(Ljava/lang/String;)V56: return
}E:\trunk\asm_x86_7_edition\Project_x86_asm\chapter08>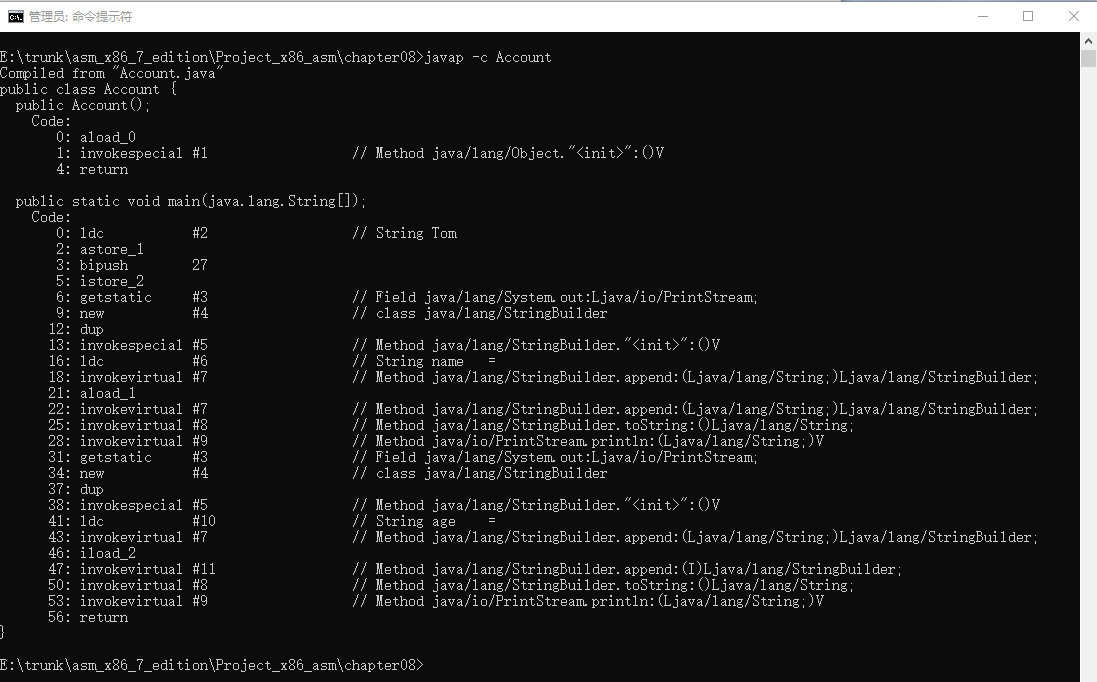
8.7.2 指令集
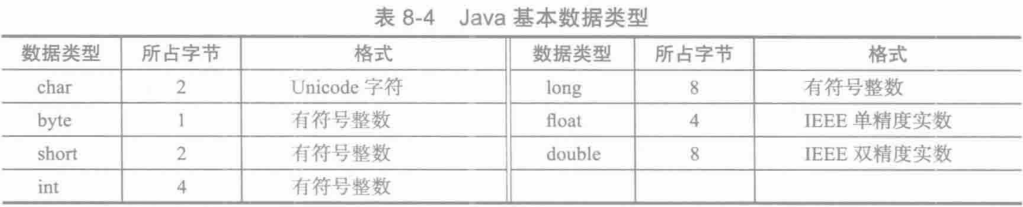
1.基本数据类型
JVM 可以识别 7 种基本数据类型,如表 8-4 所示。和 x86 整数一样,所有有符号整数都是二进制补码形式。但它们是按照大端顺序存放的,即高位字节位于每个整数的起始地址(x86 的整数按小端顺序存放)。IEEE 实数格式将在第 12 章说明。
2.比较指令
比较指令从操作数栈的顶端弹出两个操作数,对它们进行比较,再把比较结果压入堆栈。现在假设操作数入栈顺序如下所示:

下表给出了比较op1和op2之后压人堆栈的数值:

dcmp指令比较双字,fcmp指令比较浮点数
3.分支指令
分支指令可以分为有条件分支和无条件分支。Java 字节码中无条件分支的例子是 goto和jsr。
goto 指令无条件分支到一个标号:
goto label
jsr 指令调用用标号定义的子程序。其语法如下:
jsr label
条件分支指令通常检测从操作数栈顶弹出的数值。根据该值,指令决定是否分支到给定标号。比如,ifle指令就是当弹出数值小于等于0时跳转到标号。其语法如下:
ifle label
同样,ifgt 指令就是当弹出数值大于等于0时跳转到标号。其语法如下:
ifgt label
8.7.3 Java 反汇编示例
为了帮助理解Java 字节码是如何工作的,本节将给出用Java 编写的一些短代码例子。在这些例子中,请注意不同版本Java的字节码清单细节会存在些许差异。
1.示例:两个整数相加
下面的 Java 源代码行实现两个整数相加,并将和数保存在第三个变量中:
int A = 3;
int B=2
int sum = 0;
sum = A + B;该Java代码的反汇编如下:
0: iconst_3
1: istore_0
2: iconst_2
3: istore_1
4: iconst_0
5: istore_2
6: iload_0
7: iload_1
8: iadd
9: istore_2每个编号行表示一条Java字节码指令的字节偏移量。本例中,可以发现每条指令都只占一个字节,因为指令偏移量的编号是连续的。
尽管字节码反汇编一般不包括注释,这里还是会将注释添加上去。虽然局部变量在运行时堆栈中有专门的保留区域,但是指令在执行算术运算和数据传送时还会使用另一个堆栈,即操作数栈。为了避免在这两个堆栈间产生混淆,将用索引值来指代变量位置,如0、1、2 等。
现在来仔细分析刚才的字节码。开始的两条指令将一个常数值压人操作数栈,并把同一个值弹出到位置为0的局部变量:
0: iconst_3 //常数(3)压入操作数栈
1: istore_0 //弹出到局部变量0
接下来的四行将其他两个常数压人操作数栈,并把它们弹出到位置分别为1 和 2 的局部变量:
2: iconst_2 //常数(2)压入操作数栈
3: istore_1 //弹出到局部变量1
4: iconst_0 //常数(0)压入操作数栈
5: istore_2 //弹出到局部变量2
由于已经知道了该生成字节码的Java源代码,因此,很明显下表列出的是三个变量的位置索引:
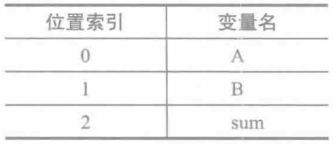
接下来,为了实现加法,必须将两个操作数压入操作数栈。指令iload0将变量A人栈,指令iload1对变量B进行相同的操作:
6: iload_0 //(A入栈)
7: iload_7 //(B入栈)
现在操作数栈包含两个数:
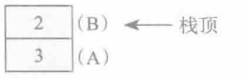
这里并不关心这些例子的实际机器表示,因此上图中的运行时堆栈是向上生长的。每个堆栈示意图中的最大值即为栈顶。
指令 iadd 将栈顶的两个数相加,并把和数压入堆栈:
8: iadd
操作数栈现在包含的是 A、B 的和数:
![]()
指令 istore_2 将栈顶内容弹出到位置为2的变量,其变量名为sum:
9: istore_2
操作数栈现在为空。
2.示例:两个Double类型数据相加
下面的 Java 代码片段实现两个 double 类型的变量相加,并将和数保存到 sum。它执行的操作与两个整数相加示例相同,因此这里主要关注的是整数处理与 double 处理的差异:
double A = 3.1;
double B = 2;
double sum = A + B;本例的反汇编字节码如下所示,用javap 实用程序可以在右边插入注释:
0: ldc2_w #2 // double 3.1d
3: dstore_1
4: ldc2_w #4 // double 2.0d
7: dstore_3
8: dload_1
9: dload_3
10: dadd
11: dstore 5下面对这个代码进行分步讨论。偏移量为0的指令ldc2_w把一个浮点常数(3.1)从常数池压人操作数栈。ldc2 指令总是用两个字节作为常数池区域的索引:
0: 1de2_w #20 // double 3.1d
偏移量为 3 的 dstore 指令从堆栈弹出一个 double 数,送入位置为0的局部变量。该指令起始偏移量(3)反映出第一条指令占用的字节数(操作码加上两字节索引);
3: dstore_0 // 保存到 A
同样,接下来偏移量为4和7的两条指令对变量B进行初始化:
4: 1dc2_w #22; // double 2.0d
7: dstore_2 // 保存到B
指令 dload_0 和 dload_2 把局部变量入栈,其索引指的是 64 位位置(两个变量栈项),因为双字数值要占用8个字节:
8: dload_0
9: dload_2
接下来的指令(dadd)将栈顶的两个 double 值相加,并把和数入栈:
10: dadd
最后,指令 dstore_4 把栈顶内容弹出到位置为4 的局部变量:
11: dstore_4
8.7.4 示例:条件分支
了解JVM 怎样处理条件分支是理解Java字节码的重要一环。比较操作总是从堆栈栈顶弹出两个数据,对它们进行比较后,再把结果数值人栈。条件分支指令常常跟在比较操作的后面,利用栈顶数值决定是否分支到目标标号。比如,下面的Java 代码包含一个简单的IF语句,它将两个数值中的一个分配给一个布尔变量:
double A = 3.0;
boolean result = false;
if(A > 2.0)result = false;
elseresult = true;该 Java 代码对应的反汇编如下所示:
0:ldc2_w #26; // double 3.0d
3:dstore_0 // 弹出到A
4: iconst_0 // false = 0
5: istore_2 // 保存到 result
6: dload_0
7:ldc2_w #22; // double 2.0d
10: dcmpl
11:ifle19 //如果A<0,转到19
14:iconst_0 //false
15:istore_2 //result = false
16:goto 21 //跳过后面的两条指令
19:iconst_1 //true
20:istore_2 //result = true开始的两条指令将 3.0 从常数池复制到运行时堆栈,再把它从堆栈弹出到变量 A:
0:ldc2_w #26; // double 3.0d
3:dstore_0 // 弹出到A
接下来的两条指令将布尔值false(等于0)从常量区复制到堆栈,再把它弹出到变量result:
4: iconst_0 // false = 0
5: istore_2 // 保存到 result
A 的值(位置0)压人操作数栈,数值 2.0 紧跟其后人栈;
6: dload_0 //(A入栈)
7:ldc2_w #22; // double 2.0d
操作数栈现在有两个数值:

指令 dcmpl 将两个double 数弹出堆栈进行比较。由于栈顶的数值(2.0)小于它下面的数值(3.0),因此整数1被压人堆栈。
10: dcmpl
如果从堆栈弹出的数值小于等于0,则指令ifle 就分支到给定的偏移量:
11:ifle19 //如果stackpop()<0,转到19
这里要回顾一下之前给出的Java源代码示例,若A>2.0,其分配的值为false:
if(A > 2.0)result = false
elseresult = true如果A≤2.0,Java 字节码就把 IF 语句转向偏移量为19 的语句,为result 分配数值true。与此同时,如果不发生到偏移量 19 的分支,则由下面几条指令把 false 赋给 result;
14:iconst_0 //false
15:istore_2 //result = false
16:goto 21 //跳过后面的两条指令偏移量16 的指令 goto 跳过后面两行代码,它们的作用是给result 分配true:
19:iconst_1 //true
20:istore_2 //result = true结论
Java 虚拟机的指令集与x86处理器系列的指令集有很大的不同。它采用面向堆栈的方法实现计算、比较和分支,与x86 指令经常使用寄存器和内存操作数形成了鲜明的对比。虽然字节码的符号反汇编不如x86 汇编语言简单,但是,编译器生成字节码也是相当容易的。每个操作都是原子的,这就意味着它只执行一个操作。若 JVM 使用的是实时编译器,则 Java字节码只要在执行前转换为本地机器语言即可。就这方面来说,Java 字节码与基于精简指令集(RISC)模型的机器语言有很多共同点。
8.8 本章小结
过程参数有两种基本类型:寄存器参数和堆栈参数。Irvine32 和 Irvine64链接库使用寄存器参数,为程序执行速度进行了优化。但是,寄存器参数往往在调用程序时使代码变得混乱。堆栈参数是另一种选择,其过程的实际参数必须由主调程序压入堆栈。
堆栈帧(或活动记录)是为过程返回地址、传递参数、局部变量和被保存寄存器预留的堆栈区域。运行中的程序在开始执行过程的时候就会创建堆栈帧。
当过程参数的副本人栈时,该参数是通过值来传递的。如果是参数地址入栈,那么它是通过引用来传递的;过程可以利用地址来修改变量。数组应该通过引用传递,以避免将所有的数组元素人栈。
EBP寄存器间接寻址可以访问过程参数,形如ebp+81的表达式能对堆栈参数进行高级控制。指令 LEA 返回任何类型间接操作数的偏移量,它非常适合与堆参数一起使用。
ENTER指令完成堆栈帧,方法是将EBP人栈并为局部变量预留空间。LEAVE指令结束过程的堆栈帧,方法是执行其之前 ENTER指令的逆操作,
直接或间接调用自身的子程序即为递归子程序。递归过程,调用递归子程序的实践,在处理具有重复模式的数据结构时,是一种强有力的工具。
LOCAL伪指令在过程内部声明一个或多个局部变量,它必须紧跟在 PROC 伪指令的后面。与全局变量相比,局部变量有独特优势:
●对局部变量名和内容的访问可以被限制在包含它的过程之内。局部变量对程序调试也有帮助,因为只有少数几条程序语句才能修改它们。
●局部变量的生命周期受限于包含它的过程的执行范围。局部变量能有效利用内存,因为同样的存储空间还可以被其他变量使用。
●同一个变量名可以被多个过程使用,而不会发生命名冲突。
●递归过程可以用局部变量在堆栈中保存数值。如果使用的是全局变量,那么每次过程调用自身时,这些数值就会被覆盖。
INVOKE 伪指令(仅限32 位模式)能代替 CALL 指令,它的功能更加强大,可以传递多个参数。用INVOKE伪指令定义过程时,ADDR 运算符可以传递指针。
PROC伪指令在声明过程名的同时可以带上已命名参数列表。PROTO 伪指令为现有过程创建原型,原型声明过程的名称和参数列表。
当应用程序全部的源代码都在一个文件中时,不论该程序有多大都是难以管理的。更实用的方法是,将程序分割为多个源代码文件(称为模块),使每个文件都易于查看和编辑。
Java字节码 Java字节码是指编译好的Java程序中使用的机器语言。Java虚拟机(JVM)是执行已编译 Java 字节码的软件。在 Java 字节码中,每条指令都有一个字节的操作码,其后跟零个或多个操作数。JVM使用面向堆栈的模式来执行算术运算、数据传送、比较和分支。Java 开发工具包(JDK)包含的工具javap.exe 可以显示javaclass 文件中字节码的反汇编。
8.9 关键术语
8.9.1 术语


8.9.2指令、运算符和伪指令
ADDR LOCAL
ENTER PROC
INVOKE PROTO
LEA RET
LEAVE USES