OpenCV 官翻7 - 对象检测
文章目录
- ArUco 标记检测
- 标记与字典
- 标记物创建
- 标记检测
- 姿态估计
- 选择字典
- 预定义字典
- 自动生成字典
- 手动定义字典
- 检测器参数
- 阈值处理
- adaptiveThreshConstant
- 轮廓过滤
- minMarkerPerimeterRate 与 maxMarkerPerimeterRate
- polygonalApproxAccuracyRate
- minCornerDistanceRate
- minMarkerDistanceRate
- minDistanceToBorder
- 比特提取
- markerBorderBits
- minOtsuStdDev
- perspectiveRemovePixelPerCell
- perspectiveRemoveIgnoredMarginPerCell
- 标记识别
- maxErroneousBitsInBorderRate
- errorCorrectionRate
- 角点优化
- cornerRefinementMethod
- cornerRefinementWinSize
- relativeCornerRefinmentWinSize
- cornerRefinementMaxIterations 和 cornerRefinementMinAccuracy
- ArUco 标定板检测
- 棋盘检测
- 网格标定板
- 优化标记检测
- ChArUco 板的检测
- 目标
- 源代码
- ChArUco 标定板创建
- ChArUco 棋盘检测
- ChArUco 姿态估计
- 菱形标记检测
- ChArUco 菱形标记生成
- ChArUco 菱形标记检测
- ChArUco 菱形姿态估计
- 使用ArUco和ChArUco进行标定
- 使用 ChArUco 标定板进行校准
- 使用ArUco标定板进行校准
- ArUco 模块常见问题解答
ArUco 标记检测
https://docs.opencv.org/4.x/d5/dae/tutorial_aruco_detection.html
下一篇教程: ArUco 标定板检测
| 原作者 | Sergio Garrido, Alexander Panov |
| 兼容性 | OpenCV >= 4.7.0 |
姿态估计在许多计算机视觉应用中至关重要:机器人导航、增强现实等等。该过程基于寻找真实环境中的点与其二维图像投影之间的对应关系。这通常是一个困难的步骤,因此通常会使用合成标记或基准标记来简化这一过程。
最流行的方法之一是使用二进制方形基准标记。这些标记的主要优点是单个标记就能提供足够的对应点(其四个角点)来获取相机姿态。此外,内部的二进制编码使其特别鲁棒,可以应用错误检测和纠正技术。
aruco 模块基于 ArUco 库,这是一个由 Rafael Muñoz 和 Sergio Garrido 开发的用于检测方形基准标记的流行库 [98]`。
aruco 功能包含在:
#include <opencv2/objdetect/aruco_detector.hpp>
标记与字典
ArUco标记是一种由宽黑色边框和内部二进制矩阵组成的合成方形标记,矩阵决定了其标识符(id)。黑色边框便于在图像中快速检测,二进制编码则支持标识识别及错误检测与纠正技术的应用。标记尺寸决定了内部矩阵的大小,例如4x4的标记由16位组成。
ArUco标记示例:

标记图像示例
需注意标记在环境中可能以旋转状态出现,但检测过程需能确定其原始旋转方向,从而明确识别每个角点。这一过程同样基于二进制编码实现。
标记字典是指特定应用中考虑使用的标记集合,本质上是所有标记二进制编码的列表。字典的主要属性包括字典大小和标记尺寸:
- 字典大小:组成字典的标记数量
- 标记尺寸:标记的位/模块数量
aruco模块预置了多种字典,涵盖不同字典大小和标记尺寸的组合。
可能有人会认为标记id是二进制编码转换为十进制数所得,但实际上对于大尺寸标记,位数过多会导致处理超大数字不切实际。因此,标记id仅表示该标记在其所属字典中的索引位置。例如字典中前5个标记的id分别为:0、1、2、3和4。
更多关于字典的详细信息请参阅"选择字典"章节。
标记物创建
在检测之前,需要先打印标记物以便放置在环境中。可以使用generateImageMarker()函数生成标记物图像。
例如,我们分析以下调用:
cv::Mat markerImage;
cv::aruco::Dictionary dictionary = cv::aruco::getPredefinedDictionary(cv::aruco::DICT_6X6_250);
cv::aruco::generateImageMarker(dictionary, 23, 200, markerImage, 1);
cv::imwrite("marker23.png", markerImage);
首先,通过选择 aruco 模块中的预定义字典之一创建 cv::aruco::Dictionary 对象。具体来说,该字典由 250 个标记组成,每个标记大小为 6x6 位(cv::aruco::DICT_6X6_250)。
cv::aruco::generateImageMarker() 的参数如下:
-
第一个参数是之前创建的
cv::aruco::Dictionary对象。 -
第二个参数是标记 ID,此处为字典
cv::aruco::DICT_6X6_250中的第 23 号标记。注意,每个字典包含的标记数量不同。本例中,有效 ID 范围为 0 至 249,超出此范围的 ID 将引发异常。 -
第三个参数 200 表示输出标记图像的尺寸。此处输出图像大小为 200x200 像素。注意,该参数需足够大以容纳特定字典的位数。例如,无法为 6x6 位的标记生成 5x5 像素的图像(且未考虑标记边框)。此外,为避免变形,该参数应与位数加边框大小成比例,或至少远大于标记尺寸(如示例中的 200),使变形可忽略不计。
-
第四个参数为输出图像。
-
最后一个可选参数用于指定标记黑色边框的宽度,其值相对于位数比例设定。例如,值 2 表示边框宽度等于两个内部位的尺寸,默认值为 1。
生成的图像如下:
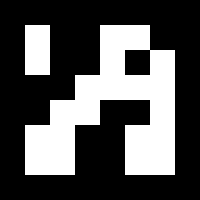
生成的标记
完整示例代码位于 samples/cpp/tutorial_code/objectDetection/ 目录下的 create_marker.cpp 文件中。
示例现使用 cv::CommandLineParser 从命令行获取输入。对于此文件,示例参数如下:
"marker23.png" -d=10 -id=23
create_marker.cpp 的参数:
const char* keys ="{@outfile |res.png| Output image }""{d | 0 | dictionary: DICT_4X4_50=0, DICT_4X4_100=1, DICT_4X4_250=2,""DICT_4X4_1000=3, DICT_5X5_50=4, DICT_5X5_100=5, DICT_5X5_250=6, DICT_5X5_1000=7, ""DICT_6X6_50=8, DICT_6X6_100=9, DICT_6X6_250=10, DICT_6X6_1000=11, DICT_7X7_50=12,""DICT_7X7_100=13, DICT_7X7_250=14, DICT_7X7_1000=15, DICT_ARUCO_ORIGINAL = 16}""{cd | | Input file with custom dictionary }""{id | 0 | Marker id in the dictionary }""{ms | 200 | Marker size in pixels }""{bb | 1 | Number of bits in marker borders }""{si | false | show generated image }";
}
标记检测
给定一张包含ArUco标记的图像,检测过程需要返回检测到的标记列表。每个检测到的标记包含以下信息:
- 标记四个角点在图像中的位置(保持原始顺序)
- 标记的ID
标记检测过程主要分为两个步骤:
-
候选标记检测:分析图像以寻找可能成为标记的方形区域。首先通过自适应阈值分割标记,然后从阈值图像中提取轮廓,丢弃非凸轮廓或不符合方形近似的轮廓。还会进行额外过滤(移除过小或过大的轮廓,消除彼此过于接近的轮廓等)。
-
标记识别:通过分析内部编码确认候选标记的有效性。首先对每个候选标记应用透视变换获取标准形式,然后使用Otsu算法对标准图像进行阈值处理以分离黑白位。根据标记尺寸和边框大小将图像划分为不同单元格,统计每个单元格的黑白像素数量来确定位值。最后分析这些位值,判断标记是否属于特定字典。必要时会采用纠错技术。
参考以下示例图像:

包含多种标记的图像
该图像的打印照片效果:

带有标记的原始图像
绿色区域表示检测到的标记(注意部分标记存在旋转),红色小方块指示标记左上角:

标记检测结果图像
粉色区域表示识别阶段被拒绝的候选标记:

被拒绝的候选标记图像
在aruco模块中,检测功能通过cv::aruco::ArucoDetector::detectMarkers()函数实现。这是该模块的核心功能,其他所有功能都基于此函数返回的检测结果。
标记检测示例:
cv::Mat inputImage;
// ... read inputImage ...
std::vector<int> markerIds;
std::vector<std::vector<cv::Point2f>> markerCorners, rejectedCandidates;
cv::aruco::DetectorParameters detectorParams = cv::aruco::DetectorParameters();
cv::aruco::Dictionary dictionary = cv::aruco::getPredefinedDictionary(cv::aruco::DICT_6X6_250);
cv::aruco::ArucoDetector detector(dictionary, detectorParams);
detector.detectMarkers(inputImage, markerCorners, markerIds, rejectedCandidates);
创建 cv::aruco::ArucoDetector 对象时,需要向构造函数传递以下参数:
-
字典对象,此处使用预定义的字典之一 (
cv::aruco::DICT_6X6_250)。 -
cv::aruco::DetectorParameters类型对象。该对象包含检测过程中可自定义的所有参数,这些参数将在下一节详细说明。
cv::aruco::ArucoDetector::detectMarkers() 的参数包括:
-
第一个参数是包含待检测标记的图像。
-
检测到的标记存储在
markerCorners和markerIds结构中:
-
markerCorners是检测到的标记角点列表。每个标记的四个角点按原始顺序返回(从左上角开始顺时针方向)。因此,第一个角点是左上角,依次是右上角、右下角和左下角。 -
markerIds是markerCorners中每个检测到标记的ID列表。注意返回的markerCorners和markerIds向量大小相同。
- 最后一个可选参数
rejectedCandidates是返回的候选标记列表,即被找到但未通过有效性检测的形状。每个候选标记同样由其四个角点定义,格式与markerCorners参数相同。该参数可省略,仅用于调试和“重检测”策略(参见cv::aruco::ArucoDetector::refineDetectedMarkers()`)。
完成 cv::aruco::ArucoDetector::detectMarkers() 检测后,通常需要验证标记是否正确识别。aruco模块提供了 drawDetectedMarkers() 函数,可在输入图像上绘制检测到的标记。例如:
cv::Mat outputImage = inputImage.clone();
cv::aruco::drawDetectedMarkers(outputImage, markerCorners, markerIds);
-
outputImage是用于绘制标记的输入/输出图像(通常与检测到标记的图像相同)。 -
markerCorners和markerIds是由cv::aruco::ArucoDetector::detectMarkers()函数返回的检测到的标记结构。

注意:此函数仅用于可视化,可以省略使用。
通过这两个函数,我们可以创建一个基本的标记检测循环来从摄像头检测标记:
cv::aruco::ArucoDetector detector(dictionary, detectorParams);cv::VideoCapture inputVideo;int waitTime;if(!video.empty()) {inputVideo.open(video);waitTime = 0;} else {inputVideo.open(camId);waitTime = 10;}double totalTime = 0;int totalIterations = 0;// set coordinate systemcv::Mat objPoints(4, 1, CV_32FC3);objPoints.ptr<Vec3f>(0)[0] = Vec3f(-markerLength/2.f, markerLength/2.f, 0);objPoints.ptr<Vec3f>(0)[1] = Vec3f(markerLength/2.f, markerLength/2.f, 0);objPoints.ptr<Vec3f>(0)[2] = Vec3f(markerLength/2.f, -markerLength/2.f, 0);objPoints.ptr<Vec3f>(0)[3] = Vec3f(-markerLength/2.f, -markerLength/2.f, 0);while(inputVideo.grab()) {cv::Mat image, imageCopy;inputVideo.retrieve(image);double tick = (double)getTickCount();vector<int> ids;vector<vector<Point2f> > corners, rejected;// detect markers and estimate posedetector.detectMarkers(image, corners, ids, rejected);size_t nMarkers = corners.size();vector<Vec3d> rvecs(nMarkers), tvecs(nMarkers);if(estimatePose && !ids.empty()) {// Calculate pose for each markerfor (size_t i = 0; i < nMarkers; i++) {solvePnP(objPoints, corners.at(i), camMatrix, distCoeffs, rvecs.at(i), tvecs.at(i));}}double currentTime = ((double)getTickCount() - tick) / getTickFrequency();totalTime += currentTime;totalIterations++;if(totalIterations % 30 == 0) {cout << "Detection Time = " << currentTime * 1000 << " ms "<< "(Mean = " << 1000 * totalTime / double(totalIterations) << " ms)" << endl;}// draw resultsimage.copyTo(imageCopy);if(!ids.empty()) {cv::aruco::drawDetectedMarkers(imageCopy, corners, ids);if(estimatePose) {for(unsigned int i = 0; i < ids.size(); i++)cv::drawFrameAxes(imageCopy, camMatrix, distCoeffs, rvecs[i], tvecs[i], markerLength * 1.5f, 2);}}if(showRejected && !rejected.empty())cv::aruco::drawDetectedMarkers(imageCopy, rejected, noArray(), Scalar(100, 0, 255));imshow("out", imageCopy);char key = (char)waitKey(waitTime);if(key == 27) break;}
注意:部分可选参数已被省略,例如检测参数对象和被拒绝候选者的输出向量。
完整可运行示例位于samples/cpp/tutorial_code/objectDetection/目录下的detect_markers.cpp文件中。
现在这些示例使用cv::CommandLineParser从命令行获取输入。对于该文件,示例参数如下所示:
-v=/path_to_opencv/opencv/doc/tutorials/objdetect/aruco_detection/images/singlemarkersoriginal.jpg -d=10
detect_markers.cpp 的参数:
const char* keys ="{d | 0 | dictionary: DICT_4X4_50=0, DICT_4X4_100=1, DICT_4X4_250=2,""DICT_4X4_1000=3, DICT_5X5_50=4, DICT_5X5_100=5, DICT_5X5_250=6, DICT_5X5_1000=7, ""DICT_6X6_50=8, DICT_6X6_100=9, DICT_6X6_250=10, DICT_6X6_1000=11, DICT_7X7_50=12,""DICT_7X7_100=13, DICT_7X7_250=14, DICT_7X7_1000=15, DICT_ARUCO_ORIGINAL = 16,""DICT_APRILTAG_16h5=17, DICT_APRILTAG_25h9=18, DICT_APRILTAG_36h10=19, DICT_APRILTAG_36h11=20}""{cd | | Input file with custom dictionary }""{v | | Input from video or image file, if ommited, input comes from camera }""{ci | 0 | Camera id if input doesnt come from video (-v) }""{c | | Camera intrinsic parameters. Needed for camera pose }""{l | 0.1 | Marker side length (in meters). Needed for correct scale in camera pose }""{dp | | File of marker detector parameters }""{r | | show rejected candidates too }""{refine | | Corner refinement: CORNER_REFINE_NONE=0, CORNER_REFINE_SUBPIX=1,""CORNER_REFINE_CONTOUR=2, CORNER_REFINE_APRILTAG=3}";
姿态估计
在检测到标记后,接下来你可能想利用它们来获取相机姿态。
要进行相机姿态估计,你需要知道相机的标定参数。这些参数包括相机矩阵和畸变系数。如果你不清楚如何标定相机,可以参考OpenCV的calibrateCamera()函数和相机标定教程。你也可以按照使用ArUco和ChArUco进行标定教程中的说明,使用aruco模块来标定相机。注意,除非相机光学组件发生改变(例如调整焦距),否则只需进行一次标定即可。
标定完成后,你将获得一个相机矩阵:这是一个3x3的矩阵,包含焦距和相机中心坐标(即内参),以及畸变系数:这是一个由5个或更多元素组成的向量,用于模拟相机产生的畸变。
使用ArUco标记进行姿态估计时,可以单独计算每个标记的姿态。如果你想基于一组标记来估计一个统一姿态,请使用ArUco标定板(参见ArUco标定板检测教程)。与单标记相比,使用ArUco标定板的优势在于允许部分标记被遮挡。
相机相对于标记的姿态是一个从标记坐标系到相机坐标系的3D变换,由旋转向量和平移向量表示。OpenCV提供了cv::solvePnP()函数来实现这一功能。
Mat camMatrix, distCoeffs;if(estimatePose) {// You can read camera parameters from tutorial_camera_params.ymlreadCameraParamsFromCommandLine(parser, camMatrix, distCoeffs);}
// set coordinate systemcv::Mat objPoints(4, 1, CV_32FC3);objPoints.ptr<Vec3f>(0)[0] = Vec3f(-markerLength/2.f, markerLength/2.f, 0);objPoints.ptr<Vec3f>(0)[1] = Vec3f(markerLength/2.f, markerLength/2.f, 0);objPoints.ptr<Vec3f>(0)[2] = Vec3f(markerLength/2.f, -markerLength/2.f, 0);objPoints.ptr<Vec3f>(0)[3] = Vec3f(-markerLength/2.f, -markerLength/2.f, 0);
vector<int> ids;vector<vector<Point2f> > corners, rejected;// detect markers and estimate posedetector.detectMarkers(image, corners, ids, rejected);size_t nMarkers = corners.size();vector<Vec3d> rvecs(nMarkers), tvecs(nMarkers);if(estimatePose && !ids.empty()) {// Calculate pose for each markerfor (size_t i = 0; i < nMarkers; i++) {solvePnP(objPoints, corners.at(i), camMatrix, distCoeffs, rvecs.at(i), tvecs.at(i));}}
-
corners参数是由cv::aruco::ArucoDetector::detectMarkers()函数返回的标记角点向量。 -
第二个参数是标记边长的实际尺寸(以米或其他单位表示)。注意估计位姿的平移向量将使用相同单位。
-
camMatrix和distCoeffs是相机校准过程中生成的相机标定参数。 -
输出参数
rvecs和tvecs分别表示corners中每个检测到标记的旋转向量和平移向量。
该函数假设的标记坐标系默认位于标记中心(或左上角),Z轴向外延伸,如下图所示。坐标轴颜色对应关系为:X轴红色,Y轴绿色,Z轴蓝色。注意图中旋转标记的轴向。

带坐标轴显示的图像
OpenCV 提供了绘制上图所示坐标轴的功能,可用于验证位姿估计结果:
// draw resultsimage.copyTo(imageCopy);if(!ids.empty()) {cv::aruco::drawDetectedMarkers(imageCopy, corners, ids);if(estimatePose) {for(unsigned int i = 0; i < ids.size(); i++)cv::drawFrameAxes(imageCopy, camMatrix, distCoeffs, rvecs[i], tvecs[i], markerLength * 1.5f, 2);}}
-
imageCopy是输入/输出图像,检测到的标记将在此显示。 -
camMatrix和distCoeffs是相机标定参数。 -
对于每个检测到的标记,
rvecs[i]和tvecs[i]分别表示旋转向量和平移向量。 -
最后一个参数是轴的长度,单位与 tvec 相同(通常为米)。
示例视频:
完整示例代码位于 samples/cpp/tutorial_code/objectDetection/ 目录下的 detect_markers.cpp 文件中。
现在这些示例使用 cv::CommandLineParser 从命令行获取输入。对于此文件,示例参数如下:
-v=/path_to_opencv/opencv/doc/tutorials/objdetect/aruco_detection/images/singlemarkersoriginal.jpg -d=10
-c=/path_to_opencv/opencv/samples/cpp/tutorial_code/objectDetection/tutorial_camera_params.yml
detect_markers.cpp 的参数:
const char* keys ="{d | 0 | dictionary: DICT_4X4_50=0, DICT_4X4_100=1, DICT_4X4_250=2,""DICT_4X4_1000=3, DICT_5X5_50=4, DICT_5X5_100=5, DICT_5X5_250=6, DICT_5X5_1000=7, ""DICT_6X6_50=8, DICT_6X6_100=9, DICT_6X6_250=10, DICT_6X6_1000=11, DICT_7X7_50=12,""DICT_7X7_100=13, DICT_7X7_250=14, DICT_7X7_1000=15, DICT_ARUCO_ORIGINAL = 16,""DICT_APRILTAG_16h5=17, DICT_APRILTAG_25h9=18, DICT_APRILTAG_36h10=19, DICT_APRILTAG_36h11=20}""{cd | | Input file with custom dictionary }""{v | | Input from video or image file, if ommited, input comes from camera }""{ci | 0 | Camera id if input doesnt come from video (-v) }""{c | | Camera intrinsic parameters. Needed for camera pose }""{l | 0.1 | Marker side length (in meters). Needed for correct scale in camera pose }""{dp | | File of marker detector parameters }""{r | | show rejected candidates too }""{refine | | Corner refinement: CORNER_REFINE_NONE=0, CORNER_REFINE_SUBPIX=1,""CORNER_REFINE_CONTOUR=2, CORNER_REFINE_APRILTAG=3}";
选择字典
aruco模块提供了Dictionary类来表示标记字典。
除了字典中标记的大小和数量外,字典还有另一个重要参数——标记间距离。标记间距离是字典标记之间的最小汉明距离,它决定了字典检测和纠正错误的能力。
一般来说,较小的字典尺寸和较大的标记尺寸会增加标记间距离,反之亦然。然而,由于需要从图像中提取更多比特位,较大尺寸标记的检测会更加困难。
例如,如果你的应用只需要10个标记,那么使用仅包含这10个标记的字典比使用包含1000个标记的字典更好。原因是包含10个标记的字典将具有更高的标记间距离,因此对错误的鲁棒性更强。
因此,aruco模块提供了多种选择标记字典的方法,以提高系统的鲁棒性:
预定义字典
这是选择字典最简单的方式。aruco模块包含了一系列预定义的字典,涵盖不同标记尺寸和标记数量。例如:
cv::aruco::Dictionary dictionary = cv::aruco::getPredefinedDictionary(cv::aruco::DICT_6X6_250);
cv::aruco::DICT_6X6_250 是一个预定义的标记字典示例,采用6x6位编码,共包含250个标记。
在提供的所有字典中,建议选择能满足应用需求的最小字典。例如,若需要200个6x6位标记,使用cv::aruco::DICT_6X6_250比cv::aruco::DICT_6X6_1000更合适。字典越小,标记间的区分距离越大。
预定义字典的完整列表可查阅PredefinedDictionaryType枚举类型的文档。
自动生成字典
可以自动生成字典来调整所需的标记数量和位数,以优化标记间的距离:
cv::aruco::Dictionary dictionary = cv::aruco::extendDictionary(36, 5);
这将生成一个由36个5x5位标记组成的自定义字典。生成过程可能需要几秒钟,具体时间取决于参数设置(字典越大、位数越多,速度越慢)。
此外,您可以使用opencv/samples/cpp目录中的aruco_dict_utils.cpp示例程序。该示例会计算生成字典的最小汉明距离,并允许您创建具有反射抗性的标记。
手动定义字典
最后,字典可以手动配置,以便使用任何编码方式。为此,需要手动设置 cv::aruco::Dictionary 对象的参数。需要注意的是,除非有特殊理由需要手动操作,否则建议优先使用之前提到的其他方法。
cv::aruco::Dictionary 的参数包括:
class Dictionary {
public:cv::Mat bytesList; // marker code informationint markerSize; // number of bits per dimensionint maxCorrectionBits; // maximum number of bits that can be corrected...}
bytesList 是包含所有标记码信息的数组。markerSize 表示每个标记的尺寸(例如,5 代表 5x5 位的标记)。最后,maxCorrectionBits 是在标记检测过程中可纠正的最大错误位数。如果该值设置过高,可能导致大量误报。
bytesList 中的每一行代表字典中的一个标记。不过,这些标记并非以二进制形式存储,而是采用特殊格式存储以简化检测过程。
幸运的是,通过静态方法 Dictionary::getByteListFromBits() 可以轻松将标记转换为此格式。
例如:
cv::aruco::Dictionary dictionary;// Markers of 6x6 bits
dictionary.markerSize = 6;// Maximum number of bit corrections
dictionary.maxCorrectionBits = 3;// Let's create a dictionary of 100 markers
for(int i = 0; i < 100; i++)
{// Assume generateMarkerBits() generates a new marker in binary format, so that// markerBits is a 6x6 matrix of CV_8UC1 type, only containing 0s and 1scv::Mat markerBits = generateMarkerBits();cv::Mat markerCompressed = cv::aruco::Dictionary::getByteListFromBits(markerBits);// Add the marker as a new rowdictionary.bytesList.push_back(markerCompressed);
}
检测器参数
cv::aruco::ArucoDetector的一个参数是cv::aruco::DetectorParameters对象。该对象包含了标记检测过程中可自定义的所有选项。
本节将详细说明每个检测器参数。这些参数可根据其涉及的处理流程进行分类:
阈值处理
标记检测流程的第一步是对输入图像进行自适应阈值处理。
例如,前文示例图像经过阈值处理后的效果如下:

可通过以下参数自定义阈值处理过程:
adaptiveThreshWinSizeMin、adaptiveThreshWinSizeMax 和 adaptiveThreshWinSizeStep
参数 adaptiveThreshWinSizeMin 和 adaptiveThreshWinSizeMax 表示自适应阈值处理中窗口尺寸(以像素为单位)的选择范围(详见 OpenCV 的 threshold() 和 adaptiveThreshold() 函数说明)。
参数 adaptiveThreshWinSizeStep 表示窗口尺寸从 adaptiveThreshWinSizeMin 到 adaptiveThreshWinSizeMax 的递增步长。
例如,当设置 adaptiveThreshWinSizeMin = 5、adaptiveThreshWinSizeMax = 21 且 adaptiveThreshWinSizeStep = 4 时,系统会以 5、9、13、17 和 21 像素的窗口尺寸分 5 步进行阈值处理。每步处理后都会提取候选标记。
若标记尺寸过大而窗口尺寸过小,可能导致标记边框断裂而无法检测,如下图所示:

反之,若标记过小而窗口尺寸过大,同样会导致检测失败,还会降低处理性能。此外,过大的窗口会使处理过程趋近于全局阈值化,丧失自适应优势。
最简单的情况是将 adaptiveThreshWinSizeMin 和 adaptiveThreshWinSizeMax 设为相同值,此时仅执行单次阈值处理。但通常建议设置窗口尺寸范围,不过过多的阈值处理步骤也会显著影响性能。
另请参阅:
cv::aruco::DetectorParameters::adaptiveThreshWinSizeMincv::aruco::DetectorParameters::adaptiveThreshWinSizeMaxcv::aruco::DetectorParameters::adaptiveThreshWinSizeStep
adaptiveThreshConstant
adaptiveThreshConstant 参数表示在阈值化操作中添加的常数值(更多细节请参考 OpenCV 的 threshold() 和 adaptiveThreshold() 函数)。在大多数情况下,其默认值是一个不错的选择。
另请参阅 cv::aruco::DetectorParameters::adaptiveThreshConstant
轮廓过滤
经过阈值处理后,系统会检测出轮廓。但并非所有轮廓都被视为标记候选对象。它们会通过多个步骤进行过滤,以剔除极不可能是标记的轮廓。本节参数用于自定义这一过滤过程。
需要注意的是,在大多数情况下,这实际上是检测能力与性能之间的平衡问题。所有被保留的轮廓都会进入后续处理阶段,而这些阶段通常具有更高的计算成本。因此,相比后期阶段,更建议在当前阶段就剔除无效候选对象。
另一方面,如果过滤条件过于严格,真实的标记轮廓可能会被错误剔除,从而导致检测失败。
minMarkerPerimeterRate 与 maxMarkerPerimeterRate
这两个参数用于确定标记的最小和最大尺寸,具体指标记轮廓的最小和最大周长。它们不以绝对像素值指定,而是相对于输入图像的最大维度进行设置。
例如,对于640x480尺寸的图像,若最小相对标记周长为0.05,则最小标记周长计算为640×0.05=32像素(因为640是图像的最大维度)。maxMarkerPerimeterRate参数同理适用。
若minMarkerPerimeterRate设置过低,检测性能会显著下降,因为后续处理阶段需要评估的轮廓数量将大幅增加。这种负面影响在maxMarkerPerimeterRate参数上不太明显,因为图像中通常存在更多小轮廓而非大轮廓。当minMarkerPerimeterRate设为0且maxMarkerPerimeterRate设为4(或更大)时,相当于处理图像中的所有轮廓,但出于性能考虑不建议这样做。
另请参阅:cv::aruco::DetectorParameters::minMarkerPerimeterRate、cv::aruco::DetectorParameters::maxMarkerPerimeterRate
polygonalApproxAccuracyRate
对每个候选区域进行多边形近似处理,仅接受近似为正方形形状的候选。该参数决定了多边形近似所能产生的最大误差(更多信息请参阅 approxPolyDP() 函数)。
此参数相对于候选区域的长度(以像素为单位)。例如,若候选区域的周长为100像素且 polygonalApproxAccuracyRate 值为0.04,则最大误差为100×0.04=4像素。
在大多数情况下,默认值效果良好,但对于高度畸变的图像可能需要更大的误差值。
另请参阅 cv::aruco::DetectorParameters::polygonalApproxAccuracyRate
minCornerDistanceRate
同一标记内任意两个角点之间的最小距离。该值相对于标记周长表示,实际最小像素距离为周长乘以 minCornerDistanceRate。
另请参阅 cv::aruco::DetectorParameters::minCornerDistanceRate
minMarkerDistanceRate
两个不同标记中任意角点对之间的最小距离。该值以两个标记中最小周长的相对比例表示。如果两个候选标记距离过近,较小的那个将被忽略。
另请参阅 cv::aruco::DetectorParameters::minMarkerDistanceRate
minDistanceToBorder
标记任意角点到图像边框的最小距离(以像素为单位)。即使标记部分被图像边框遮挡,只要遮挡范围较小,仍能正确检测。然而,若某个角点被遮挡,返回的角点坐标通常会错误地定位在图像边框附近。
如果标记角点位置至关重要(例如进行姿态估计时),建议直接舍弃那些角点过于接近图像边框的标记。其他应用场景下则无需此操作。
另请参阅 cv::aruco::DetectorParameters::minDistanceToBorder
比特提取
在完成候选检测后,系统会分析每个候选对象的比特位以判断它们是否为有效标记。
在分析二进制代码本身之前,需要先提取比特位。这一过程包括校正透视畸变,并使用大津阈值法对处理后的图像进行二值化,以区分黑白像素。
下图展示了一个标记在消除透视畸变后获得的图像示例:

透视校正
接着,将图像划分为与标记比特数相同的网格单元。每个单元中统计黑白像素的数量,根据多数原则确定该单元对应的比特值:

标记单元
该过程支持通过以下参数进行自定义调整:
markerBorderBits
该参数表示标记边框的宽度,其数值相对于每个比特的大小。例如,值为2表示边框宽度等于两个内部比特的宽度。
使用时,此参数需与所采用标记的实际边框尺寸保持一致。边框尺寸可通过标记绘制函数(如generateImageMarker())进行配置。
另请参阅 cv::aruco::DetectorParameters::markerBorderBits
minOtsuStdDev
该值决定了执行Otsu阈值分割时像素值的最小标准差。如果标准差较低,很可能意味着整个区域都是黑色(或白色),此时应用Otsu算法没有意义。在这种情况下,所有比特位将根据平均值是否高于或低于128被设为0(或1)。
另请参阅 cv::aruco::DetectorParameters::minOtsuStdDev
perspectiveRemovePixelPerCell
该参数决定了在矫正透视畸变后(包括边框),所获得图像中每个单元格对应的像素数量。这对应于上图中红色方块的大小。
举例来说,假设我们处理的是5x5比特的标记,且边框大小为1比特(参见markerBorderBits)。那么,每个维度上的总单元格/比特数为5 + 2*1 = 7(边框需要计算两次)。总单元格数为7x7。
如果perspectiveRemovePixelPerCell的值设为10,那么最终获得的图像大小将是10*7 = 70,即70x70像素。
提高此参数的值可以在一定程度上改善比特提取过程,但也可能影响性能表现。
另请参阅cv::aruco::DetectorParameters::perspectiveRemovePixelPerCell
perspectiveRemoveIgnoredMarginPerCell
在提取每个单元格的比特位时,会统计黑色和白色像素的数量。通常不建议考虑所有单元格像素,更好的做法是忽略单元格边缘的部分像素。
这样做的原因是,在消除透视畸变后,单元格的颜色通常无法完美分离,白色单元格可能会侵入黑色单元格的部分像素(反之亦然)。因此,忽略部分像素可以避免统计错误的像素。
例如,在下图中:

标记单元格边缘
只有绿色方框内的像素会被计入。从右图可以看出,处理后的像素减少了相邻单元格带来的噪声。perspectiveRemoveIgnoredMarginPerCell参数表示红色方框与绿色方框之间的差异范围。
该参数相对于单元格的总大小。例如,如果单元格大小为40像素且此参数值为0.1,则每个单元格会忽略40*0.1=4像素的边缘。这意味着实际分析的每个单元格像素总数将是32x32,而非40x40。
另请参阅 cv::aruco::DetectorParameters::perspectiveRemoveIgnoredMarginPerCell
标记识别
在提取比特位后,下一步是检查提取的代码是否属于标记字典。如有必要,可执行纠错操作。
maxErroneousBitsInBorderRate
标记边框的比特位应为黑色。此参数指定了边框允许的错误比特数上限,即边框内白色比特的最大数量。该数值以相对于标记总比特数的比率形式表示。
另请参阅 cv::aruco::DetectorParameters::maxErroneousBitsInBorderRate
errorCorrectionRate
每个标记字典都有一个理论上的最大可纠正比特数(Dictionary.maxCorrectionBits)。但该值可通过 errorCorrectionRate 参数进行调整。
例如,若所用字典允许的最大可纠正比特数为6,且 errorCorrectionRate 值为0.5,则实际最大可纠正比特数为6*0.5=3比特。
此参数可用于降低纠错能力,从而避免误判。
另请参阅 cv::aruco::DetectorParameters::errorCorrectionRate
角点优化
在检测并识别出标记后,最后一步是对角点位置进行亚像素级优化(参见OpenCV的cornerSubPix()函数和cv::aruco::CornerRefineMethod)。
注意:此步骤是可选的,仅当需要精确获取标记角点位置(例如用于姿态估计)时才适用。该步骤通常较为耗时,因此默认处于禁用状态。
cornerRefinementMethod
该参数决定是否执行角点亚像素优化处理,以及执行时采用的具体方法。如果不需要精确的角点检测,可以禁用此功能。可选值包括 CORNER_REFINE_NONE、CORNER_REFINE_SUBPIX、CORNER_REFINE_CONTOUR 和 CORNER_REFINE_APRILTAG。
另请参阅 cv::aruco::DetectorParameters::cornerRefinementMethod
cornerRefinementWinSize
该参数用于确定角点细化处理过程中的最大窗口尺寸。
设置过高的值可能导致图像中相邻的角点被包含在同一窗口区域内,从而使得标记的角点在此过程中移动到错误的位置。此外,这还可能影响处理性能。若ArUco标记尺寸过小,窗口尺寸会自动减小,具体可参考cv::aruco::DetectorParameters::relativeCornerRefinmentWinSize。最终窗口尺寸按以下公式计算:min(cornerRefinementWinSize, averageArucoModuleSize*relativeCornerRefinmentWinSize),其中averageArucoModuleSize表示ArUco标记模块的平均像素尺寸。
另请参阅cv::aruco::DetectorParameters::cornerRefinementWinSize
relativeCornerRefinmentWinSize
用于角点优化的动态窗口大小,相对于ArUco模块尺寸(默认值为0.3)。
最终窗口大小的计算公式为:min(cornerRefinementWinSize, averageArucoModuleSize*relativeCornerRefinmentWinSize),其中averageArucoModuleSize表示ArUco标记的平均模块尺寸(以像素为单位)。当标记之间距离较远时,建议将该参数值增大至0.4-0.5;当标记密集分布时,建议减小至0.1-0.2。
另请参阅 cv::aruco::DetectorParameters::relativeCornerRefinmentWinSize
cornerRefinementMaxIterations 和 cornerRefinementMinAccuracy
这两个参数决定了亚像素细化过程的停止条件。cornerRefinementMaxIterations 表示最大迭代次数,cornerRefinementMinAccuracy 表示停止过程前的最小误差值。
如果迭代次数过高,可能会影响性能。反之,如果过低,则可能导致亚像素细化效果不佳。
另请参阅 cv::aruco::DetectorParameters::cornerRefinementMaxIterations 和 cv::aruco::DetectorParameters::cornerRefinementMinAccuracy
生成于 2025 年 4 月 30 日星期三 23:08:42,由 doxygen 1.12.0 为 OpenCV 生成
ArUco 标定板检测
https://docs.opencv.org/4.x/db/da9/tutorial_aruco_board_detection.html
上一教程: ArUco 标记检测
下一教程: ChArUco 标定板检测
| 原作者 | Sergio Garrido, Alexander Panov |
| 兼容性 | OpenCV >= 4.7.0 |
ArUco 标定板是由多个标记组成的集合,其功能类似于单个标记,能够为相机提供单一的位姿信息。
最常见的标定板类型是所有标记都位于同一平面的布局,这种设计便于直接打印:

但标定板的排列方式并不局限于此,它可以呈现任何二维或三维的布局结构。
标定板与独立标记组的本质区别在于:标定板中标记之间的相对位置是预先已知的。这一特性使得所有标记的角点都能用于计算相机相对于整个标定板的位姿。
当使用独立标记组时,由于无法获知标记在环境中的相对位置,只能单独计算每个标记的位姿。
使用标定板的主要优势包括:
- 位姿估计更具灵活性。只需检测到部分标记即可完成位姿计算,因此在存在遮挡或局部视野的情况下仍能工作
- 通常能获得更高精度的位姿结果,因为采用了更多点对应关系(标记角点)进行计算
棋盘检测
棋盘检测与标准标记检测类似,唯一区别在于姿态估计步骤。实际上,使用标记棋盘时,需要先完成标准标记检测,才能估计棋盘姿态。
执行棋盘姿态估计时,应使用solvePnP()函数,如下方samples/cpp/tutorial_code/objectDetection/detect_board.cpp所示。
int markersX = parser.get<int>("w");int markersY = parser.get<int>("h");float markerLength = parser.get<float>("l");float markerSeparation = parser.get<float>("s");bool showRejected = parser.has("r");bool refindStrategy = parser.has("rs");int camId = parser.get<int>("ci");Mat camMatrix, distCoeffs;readCameraParamsFromCommandLine(parser, camMatrix, distCoeffs);aruco::Dictionary dictionary = readDictionatyFromCommandLine(parser);aruco::DetectorParameters detectorParams = readDetectorParamsFromCommandLine(parser);String video;if(parser.has("v")) {video = parser.get<String>("v");}if(!parser.check()) {parser.printErrors();return 0;}aruco::ArucoDetector detector(dictionary, detectorParams);VideoCapture inputVideo;int waitTime;if(!video.empty()) {inputVideo.open(video);waitTime = 0;} else {inputVideo.open(camId);waitTime = 10;}float axisLength = 0.5f * ((float)min(markersX, markersY) * (markerLength + markerSeparation) +markerSeparation);// Create GridBoard objectaruco::GridBoard board(Size(markersX, markersY), markerLength, markerSeparation, dictionary);// Also you could create Board object//vector<vector<Point3f> > objPoints; // array of object points of all the marker corners in the board//vector<int> ids; // vector of the identifiers of the markers in the board//aruco::Board board(objPoints, dictionary, ids);double totalTime = 0;int totalIterations = 0;while(inputVideo.grab()) {Mat image, imageCopy;inputVideo.retrieve(image);double tick = (double)getTickCount();vector<int> ids;vector<vector<Point2f>> corners, rejected;Vec3d rvec, tvec;// Detect markersdetector.detectMarkers(image, corners, ids, rejected);// Refind strategy to detect more markersif(refindStrategy)detector.refineDetectedMarkers(image, board, corners, ids, rejected, camMatrix,distCoeffs);// Estimate board poseint markersOfBoardDetected = 0;if(!ids.empty()) {// Get object and image points for the solvePnP functioncv::Mat objPoints, imgPoints;board.matchImagePoints(corners, ids, objPoints, imgPoints);// Find posecv::solvePnP(objPoints, imgPoints, camMatrix, distCoeffs, rvec, tvec);markersOfBoardDetected = (int)objPoints.total() / 4;}double currentTime = ((double)getTickCount() - tick) / getTickFrequency();totalTime += currentTime;totalIterations++;if(totalIterations % 30 == 0) {cout << "Detection Time = " << currentTime * 1000 << " ms "<< "(Mean = " << 1000 * totalTime / double(totalIterations) << " ms)" << endl;}// Draw resultsimage.copyTo(imageCopy);if(!ids.empty())aruco::drawDetectedMarkers(imageCopy, corners, ids);if(showRejected && !rejected.empty())aruco::drawDetectedMarkers(imageCopy, rejected, noArray(), Scalar(100, 0, 255));if(markersOfBoardDetected > 0)cv::drawFrameAxes(imageCopy, camMatrix, distCoeffs, rvec, tvec, axisLength);imshow("out", imageCopy);char key = (char)waitKey(waitTime);if(key == 27) break;
参数说明:
-
objPoints和imgPoints:对象点和图像点,需与cv::aruco::GridBoard::matchImagePoints()匹配。该函数需要输入从cv::aruco::ArucoDetector::detectMarkers()函数检测到的标记角点markerCorners和标记IDmarkerIds结构。 -
board:定义标定板布局及其ID的cv::aruco::Board对象 -
cameraMatrix和distCoeffs:姿态估计所需的相机标定参数 -
rvec和tvec:标定板的估计姿态。若非空则作为初始猜测值 -
函数返回值:用于估计标定板姿态的标记总数
可通过 drawFrameAxes() 函数验证获得的姿态,例如:

带坐标轴的标定板
另一个部分遮挡的标定板示例:

存在遮挡的标定板
如图所示,即使部分标记未被检测到,仍可通过其余标记估计标定板姿态。
示例视频:
完整示例代码位于 samples/cpp/tutorial_code/objectDetection/detect_board.cpp 中。
示例程序现通过 cv::CommandLineParser 接收命令行参数,该文件的示例参数如下:
-w=5 -h=7 -l=100 -s=10
-v=/path_to_opencv/opencv/doc/tutorials/objdetect/aruco_board_detection/gboriginal.jpg
-c=/path_to_opencv/opencv/samples/cpp/tutorial_code/objectDetection/tutorial_camera_params.yml
-cd=/path_to_opencv/opencv/samples/cpp/tutorial_code/objectDetection/tutorial_dict.ymlParameters for `detect_board.cpp`: const char* keys ="{w | | Number of squares in X direction }""{h | | Number of squares in Y direction }""{l | | Marker side length (in pixels) }""{s | | Separation between two consecutive markers in the grid (in pixels)}""{d | | dictionary: DICT_4X4_50=0, DICT_4X4_100=1, DICT_4X4_250=2,""DICT_4X4_1000=3, DICT_5X5_50=4, DICT_5X5_100=5, DICT_5X5_250=6, DICT_5X5_1000=7, ""DICT_6X6_50=8, DICT_6X6_100=9, DICT_6X6_250=10, DICT_6X6_1000=11, DICT_7X7_50=12,""DICT_7X7_100=13, DICT_7X7_250=14, DICT_7X7_1000=15, DICT_ARUCO_ORIGINAL = 16}""{cd | | Input file with custom dictionary }""{c | | Output file with calibrated camera parameters }""{v | | Input from video or image file, if omitted, input comes from camera }""{ci | 0 | Camera id if input doesnt come from video (-v) }""{dp | | File of marker detector parameters }""{rs | | Apply refind strategy }""{r | | show rejected candidates too }";
}
网格标定板
创建 cv::aruco::Board 对象需要为环境中的每个标记指定角点位置。但在许多情况下,标定板只是同一平面上按网格布局排列的一组标记,因此可以轻松打印和使用。
幸运的是,aruco模块提供了便捷创建和打印这类标记的基础功能。
cv::aruco::GridBoard 是一个继承自 cv::aruco::Board 的特化类,它表示所有标记位于同一平面且呈网格布局的标定板,如下图所示:

ArUco标定板图像
具体而言,网格标定板的坐标系位于标定板平面内,以板面左下角为中心,Z轴向外延伸,如下图所示(X轴:红色,Y轴:绿色,Z轴:蓝色):

带坐标轴的标定板
可以通过以下参数定义 cv::aruco::GridBoard 对象:
- X方向的标记数量
- Y方向的标记数量
- 标记边长
- 标记间隔距离
- 标记使用的字典
- 所有标记的ID(共X*Y个标记)
使用 cv::aruco::GridBoard 构造函数可以轻松根据这些参数创建对象:
aruco::GridBoard board(Size(markersX, markersY), markerLength, markerSeparation, dictionary);
- 前两个参数分别表示X和Y方向的标记数量
- 第三和第四个参数分别表示标记长度和间隔距离。可使用任意单位,但需注意该标定板的估计位姿将使用相同单位(通常以米为单位)
- 最后提供标记使用的字典
因此,该标定板将包含5x7=35个标记。默认情况下,每个标记的ID按升序从0开始分配,即0, 1, 2, …, 34。
创建网格标定板后,通常需要打印并使用。有两种实现方式:
- 使用脚本
doc/patter_tools/gen_pattern.py,参见创建校准图案 - 使用函数
cv::aruco::GridBoard::generateImage()
cv::aruco::GridBoard 类提供的生成函数可通过以下代码调用:
Mat boardImage;
board.generateImage(imageSize, boardImage, margins, borderBits);
- 第一个参数是输出图像的像素尺寸(本例为600x500像素)。如果尺寸与标定板长宽比不符,图像将居中显示
boardImage:输出带标定板的图像- 第三个参数是(可选)边距像素值,确保标记不接触图像边界(本例边距为10)
- 最后是标记边框大小,与
generateImageMarker()函数类似,默认值为1
完整的工作示例见 samples/cpp/tutorial_code/objectDetection/create_board.cpp
输出图像效果如下:

示例现在通过 cv::CommandLineParser 接收命令行参数。该文件的示例参数如下:
"_output_path_/aboard.png" -w=5 -h=7 -l=100 -s=10 -d=10
优化标记检测
ArUco标定板还可用于提升标记检测效果。当我们已检测到属于标定板的部分标记时,可以利用这些标记和标定板的布局信息,尝试找出之前未被检测到的标记。
这一功能可通过调用cv::aruco::refineDetectedMarkers()函数实现,该函数应在cv::aruco::ArucoDetector::detectMarkers()之后调用。
该函数的主要参数包括:检测到标记的原始图像、标定板对象、已检测到的标记角点、已检测到的标记ID,以及被拒绝的标记角点。
被拒绝的角点可从cv::aruco::ArucoDetector::detectMarkers()函数获取,这些角点也被称为候选标记。这些候选标记是在原始图像中找到的方形区域,但由于未能通过识别步骤(例如其内部编码存在过多错误)而未被确认为有效标记。
然而,这些候选标记有时可能是实际存在的标记,只是由于图像噪声过大、分辨率过低或其他影响二进制编码提取的问题而未被正确识别。cv::aruco::ArucoDetector::refineDetectedMarkers()函数会在这些候选标记与标定板缺失的标记之间建立对应关系。这一搜索过程基于两个参数:
-
候选标记与缺失标记投影之间的距离。要获取这些投影,必须至少检测到标定板上的一个标记。如果提供了相机参数(相机矩阵和畸变系数),则使用这些参数计算投影。否则,将通过局部单应性变换计算投影,此时仅允许使用平面标定板(即所有标记角点的Z坐标应相同)。
refineDetectedMarkers()中的minRepDistance参数决定了候选角点与投影标记角点之间的最小欧氏距离(默认值为10)。 -
二进制编码。如果候选标记满足最小距离条件,将再次分析其内部比特以确定是否为实际投影标记。不过在这种情况下,条件相对宽松,允许的错误比特数可以更多。这由
errorCorrectionRate参数控制(默认值为3.0)。如果该参数为负值,则完全不分析内部比特,仅评估角点距离。
以下是使用cv::aruco::ArucoDetector::refineDetectedMarkers()函数的示例:
// Detect markersdetector.detectMarkers(image, corners, ids, rejected);// Refind strategy to detect more markersif(refindStrategy)detector.refineDetectedMarkers(image, board, corners, ids, rejected, camMatrix, distCoeffs);
还需注意的是,在某些情况下,如果初始检测到的标记点数量过少(例如仅1或2个标记点),缺失标记点的投影质量可能较差,从而导致错误的对应关系。
具体实现细节请参考模块示例。
生成于 2025年4月30日 星期三 23:08:42,由 doxygen 1.12.0 为 OpenCV 生成
ChArUco 板的检测
https://docs.opencv.org/4.x/df/d4a/tutorial_charuco_detection.html
上一篇教程: ArUco板的检测
下一篇教程: 菱形标记的检测
ArUco标记和板因其快速检测和多功能性而非常实用。然而,ArUco标记的一个问题是,即使在应用亚像素细化后,其角点位置的精度也不够高。
相反,棋盘图案的角点可以更精确地细化,因为每个角点都被两个黑色方块包围。但寻找棋盘图案不如寻找ArUco板灵活:它必须完全可见且不允许遮挡。
ChArUco板试图结合这两种方法的优点:
ChArUco定义
ArUco部分用于插值棋盘角点的位置,因此它具有标记板的灵活性,允许遮挡或部分可见。此外,由于插值的角点属于棋盘,它们在亚像素精度方面非常准确。
当需要高精度时(例如相机校准),ChArUco板比标准ArUco板是更好的选择。
目标
在本教程中,你将学习:
- 如何创建一个 charuco 棋盘?
- 如何在不进行相机校准的情况下检测 charuco 角点?
- 如何通过相机校准和姿态估计来检测 charuco 角点?
源代码
你可以在 samples/cpp/tutorial_code/objectDetection/detect_board_charuco.cpp 中找到这段代码。
以下是一个示例代码,展示了如何实现目标列表中列出的所有功能。
int squaresX = parser.get<int>("w");int squaresY = parser.get<int>("h");float squareLength = parser.get<float>("sl");float markerLength = parser.get<float>("ml");bool refine = parser.has("rs");int camId = parser.get<int>("ci");string video;if(parser.has("v")) {video = parser.get<string>("v");}Mat camMatrix, distCoeffs;readCameraParamsFromCommandLine(parser, camMatrix, distCoeffs);aruco::DetectorParameters detectorParams = readDetectorParamsFromCommandLine(parser);aruco::Dictionary dictionary = readDictionatyFromCommandLine(parser);if(!parser.check()) {parser.printErrors();return 0;}VideoCapture inputVideo;int waitTime = 0;if(!video.empty()) {inputVideo.open(video);} else {inputVideo.open(camId);waitTime = 10;}float axisLength = 0.5f * ((float)min(squaresX, squaresY) * (squareLength));// create charuco board objectaruco::CharucoBoard charucoBoard(Size(squaresX, squaresY), squareLength, markerLength, dictionary);// create charuco detectoraruco::CharucoParameters charucoParams;charucoParams.tryRefineMarkers = refine; // if tryRefineMarkers, refineDetectedMarkers() will be used in detectBoard()charucoParams.cameraMatrix = camMatrix; // cameraMatrix can be used in detectBoard()charucoParams.distCoeffs = distCoeffs; // distCoeffs can be used in detectBoard()aruco::CharucoDetector charucoDetector(charucoBoard, charucoParams, detectorParams);double totalTime = 0;int totalIterations = 0;while(inputVideo.grab()) {Mat image, imageCopy;inputVideo.retrieve(image);double tick = (double)getTickCount();vector<int> markerIds, charucoIds;vector<vector<Point2f> > markerCorners;vector<Point2f> charucoCorners;Vec3d rvec, tvec;// detect markers and charuco cornerscharucoDetector.detectBoard(image, charucoCorners, charucoIds, markerCorners, markerIds);// estimate charuco board posebool validPose = false;if(camMatrix.total() != 0 && distCoeffs.total() != 0 && charucoIds.size() >= 4) {Mat objPoints, imgPoints;charucoBoard.matchImagePoints(charucoCorners, charucoIds, objPoints, imgPoints);validPose = solvePnP(objPoints, imgPoints, camMatrix, distCoeffs, rvec, tvec);}double currentTime = ((double)getTickCount() - tick) / getTickFrequency();totalTime += currentTime;totalIterations++;if(totalIterations % 30 == 0) {cout << "Detection Time = " << currentTime * 1000 << " ms "<< "(Mean = " << 1000 * totalTime / double(totalIterations) << " ms)" << endl;}// draw resultsimage.copyTo(imageCopy);if(markerIds.size() > 0) {aruco::drawDetectedMarkers(imageCopy, markerCorners);}if(charucoIds.size() > 0) {aruco::drawDetectedCornersCharuco(imageCopy, charucoCorners, charucoIds, cv::Scalar(255, 0, 0));}if(validPose)cv::drawFrameAxes(imageCopy, camMatrix, distCoeffs, rvec, tvec, axisLength);imshow("out", imageCopy);if(waitKey(waitTime) == 27) break;}
ChArUco 标定板创建
aruco 模块提供了 cv::aruco::CharucoBoard 类来表示 ChArUco 标定板,该类继承自 cv::aruco::Board 类。
与 ChArUco 的其他功能一样,这个类定义在:
#include <opencv2/objdetect/charuco_detector.hpp>
定义 cv::aruco::CharucoBoard 需要以下参数:
- 棋盘在 X 和 Y 方向上的方格数量
- 方格的边长
- 标记的边长
- 标记的字典
- 所有标记的 ID
与 cv::aruco::GridBoard 类似,aruco 模块提供了便捷的方式来创建 cv::aruco::CharucoBoard。通过 cv::aruco::CharucoBoard 构造函数可以轻松根据这些参数创建对象:
aruco::Dictionary dictionary = readDictionatyFromCommandLine(parser);
cv::aruco::CharucoBoard board(Size(squaresX, squaresY), (float)squareLength, (float)markerLength, dictionary);
- 第一个参数分别表示 X 和 Y 方向上的方格数量
- 第二和第三个参数分别是方格和标记的边长。可以使用任何单位,但需注意该棋盘的估计位姿将使用相同单位(通常使用米)
- 最后提供标记的字典
默认情况下,每个标记的 ID 按升序从 0 开始分配,与 cv::aruco::GridBoard 构造函数相同。可以通过 board.ids 访问 ID 向量来自定义,如父类 cv::aruco::Board 所示。
创建 cv::aruco::CharucoBoard 对象后,可以生成图像进行打印。有两种方法实现:
- 使用脚本
doc/patter_tools/gen_pattern.py,参见Create calibration pattern - 使用函数
cv::aruco::CharucoBoard::generateImage()
cv::aruco::CharucoBoard 类提供了 cv::aruco::CharucoBoard::generateImage() 函数,可通过以下代码调用:
Mat boardImage;Size imageSize;imageSize.width = squaresX * squareLength + 2 * margins;imageSize.height = squaresY * squareLength + 2 * margins;board.generateImage(imageSize, boardImage, margins, borderBits);
-
第一个参数是输出图像的像素尺寸。如果该尺寸与棋盘尺寸不成比例,图像将居中显示。
-
第二个参数是包含Charuco棋盘的输出图像。
-
第三个参数是(可选的)边距像素值,确保所有标记都不会接触图像边框。
-
最后是标记边框的尺寸,类似于
cv::aruco::generateImageMarker()函数。默认值为1。
输出图像效果如下:

完整示例代码位于samples/cpp/tutorial_code/objectDetection/目录下的create_board_charuco.cpp文件中。
现在,示例程序create_board_charuco.cpp通过cv::CommandLineParser接收命令行输入。该文件的示例参数形式如下:
"_output_path_/chboard.png" -w=5 -h=7 -sl=100 -ml=60 -d=10
ChArUco 棋盘检测
当检测 ChArUco 棋盘时,实际上是在检测棋盘上的每个棋盘格角点。
ChArUco 棋盘上的每个角点都有一个唯一的标识符(id)。这些 id 从 0 开始编号,直到棋盘上的角点总数。ChArUco 棋盘检测的步骤可以分解如下:
- 获取输入图像
Mat image, imageCopy;inputVideo.retrieve(image);
需要检测标记点的原始图像。该图像对于在ChArUco角点进行亚像素级优化是必需的。
- 读取相机校准参数(仅适用于带相机校准的检测)
if(parser.has("c")) {bool readOk = readCameraParameters(parser.get<std::string>("c"), camMatrix, distCoeffs);if(!readOk) {throw std::runtime_error("Invalid camera file\n");}}
readCameraParameters 的参数说明如下:
-
第一个参数是相机内参矩阵和畸变系数的文件路径。
-
第二和第三个参数分别是 cameraMatrix 和 distCoeffs。
该函数接收这些参数作为输入,并返回一个布尔值,表示相机标定参数是否有效。若无需标定直接检测 charuco 角点,则无需此步骤。
- 标记检测与 charuco 角点插值
ChArUco 角点的检测基于先前检测到的标记。因此,首先检测标记,然后从标记中插值计算出 ChArUco 角点。检测 ChArUco 角点的方法是 cv::aruco::CharucoDetector::detectBoard()。
// detect markers and charuco cornerscharucoDetector.detectBoard(image, charucoCorners, charucoIds, markerCorners, markerIds);
detectBoard 的参数包括:
image- 输入图像。charucoCorners- 输出检测到的角点的图像位置列表。charucoIds- 输出charucoCorners中每个检测到的角点的 ID。markerCorners- 输入/输出检测到的标记角点向量。markerIds- 输入/输出检测到的标记标识符向量。
如果 markerCorners 和 markerIds 为空,该函数将检测 ArUco 标记及其 ID。
如果提供了校准参数,ChArUco 角点将通过以下步骤进行插值:首先,根据 ArUco 标记估计粗略姿态,然后将 ChArUco 角点重新投影到图像中。反之,如果未提供校准参数,则通过计算 ChArUco 平面与 ChArUco 图像投影之间的对应单应性来插值 ChArUco 角点。
使用单应性的主要问题是插值对图像畸变更敏感。实际上,单应性计算仅使用每个 ChArUco 角点最近的标记,以减少畸变的影响。
在检测 ChArUco 板的标记时,尤其是使用单应性时,建议禁用标记的角点细化。原因是由于棋盘格方块的邻近性,亚像素处理可能导致角点位置出现显著偏差,这些偏差会传播到 ChArUco 角点插值中,导致结果不佳。
注意:为避免偏差,棋盘格方块与 ArUco 标记之间的边距应大于一个标记模块的 70%。
此外,仅返回周围两个标记均被找到的角点。如果任一周围标记未被检测到,通常意味着该区域存在遮挡或图像质量不佳。无论如何,最好不考虑该角点,因为我们希望确保插值的 ChArUco 角点非常精确。
在插值 ChArUco 角点后,会执行亚像素细化。
一旦完成 ChArUco 角点的插值,我们可能需要绘制它们以检查检测是否正确。这可以通过 cv::aruco::drawDetectedCornersCharuco() 函数轻松实现:
aruco::drawDetectedCornersCharuco(imageCopy, charucoCorners, charucoIds, cv::Scalar(255, 0, 0));
-
imageCopy是用于绘制角点的图像(通常与检测到角点的图像相同)。 -
outputImage将是带有绘制角点的inputImage克隆图像。 -
charucoCorners和charucoIds是通过cv::aruco::CharucoDetector::detectBoard()函数检测到的Charuco角点。 -
最后一个参数是(可选的)绘制角点所用的颜色,类型为
cv::Scalar。
对于这张图像:

带有Charuco板的图像
处理结果如下:

检测到的Charuco板
当存在遮挡时,如下图所示,虽然部分角点清晰可见,但由于遮挡导致其周围标记未被全部检测到,因此这些角点不会被插值计算:

存在遮挡的Charuco检测
示例视频:
完整示例代码位于 samples/cpp/tutorial_code/objectDetection/ 目录下的 detect_board_charuco.cpp 文件中。
示例程序 detect_board_charuco.cpp 现在通过 cv::CommandLineParser 接收命令行输入参数。该文件的示例参数格式如下:
-w=5 -h=7 -sl=0.04 -ml=0.02 -d=10 -v=/path_to_opencv/opencv/doc/tutorials/objdetect/charuco_detection/images/choriginal.jpg
ChArUco 姿态估计
ChArUco 标定板的最终目标是通过精确查找角点来实现高精度校准或姿态估计。
aruco 模块提供了便捷的 ChArUco 姿态估计功能。与 cv::aruco::GridBoard 类似,cv::aruco::CharucoBoard 的坐标系被设置在标定板平面内,Z 轴指向平面内部,原点位于标定板左下角中心。
注意:OpenCV 4.6.0 版本后,标定板坐标系发生了不兼容变更。现在坐标系设置在标定板平面内且 Z 轴指向平面内部(此前 Z 轴指向平面外部)。顺时针顺序的 objPoints 对应 Z 轴指向平面内部的情况,逆时针顺序的 objPoints 则对应 Z 轴指向平面外部的情况。详见 PR https://github.com/opencv/opencv_contrib/pull/3174
执行 ChArUco 标定板姿态估计时,应使用 cv::aruco::CharucoBoard::matchImagePoints() 和 cv::solvePnP() 函数:
// estimate charuco board posebool validPose = false;if(camMatrix.total() != 0 && distCoeffs.total() != 0 && charucoIds.size() >= 4) {Mat objPoints, imgPoints;charucoBoard.matchImagePoints(charucoCorners, charucoIds, objPoints, imgPoints);validPose = solvePnP(objPoints, imgPoints, camMatrix, distCoeffs, rvec, tvec);}
-
charucoCorners和charucoIds参数来自cv::aruco::CharucoDetector::detectBoard()函数检测到的ChArUco角点。 -
cameraMatrix和distCoeffs是相机标定参数,为姿态估计所必需。 -
最后,
rvec和tvec参数表示ChArUco板的输出姿态。 -
如果姿态估计正确,
cv::solvePnP()返回 true,否则返回 false。失败的主要原因是角点数量不足或它们位于同一直线上。
可以使用 cv::drawFrameAxes() 绘制坐标轴来验证姿态估计是否正确。结果将显示为:(X轴:红色,Y轴:绿色,Z轴:蓝色)

ChArUco板坐标轴
完整示例代码位于 samples/cpp/tutorial_code/objectDetection/ 目录下的 detect_board_charuco.cpp 文件中。
示例程序 detect_board_charuco.cpp 现在通过 cv::CommandLineParser 接收命令行输入参数。对于该文件,示例参数如下:
-w=5 -h=7 -sl=0.04 -ml=0.02 -d=10
-v=/path_to_opencv/opencv/doc/tutorials/objdetect/charuco_detection/images/choriginal.jpg
-c=/path_to_opencv/opencv/samples/cpp/tutorial_code/objectDetection/tutorial_camera_charuco.yml
生成于 2025 年 4 月 30 日 星期三 23:08:42,由 doxygen 1.12.0 为 OpenCV 生成
菱形标记检测
https://docs.opencv.org/4.x/d5/d07/tutorial_charuco_diamond_detection.html
上一教程: ChArUco标定板检测
下一教程: 使用ArUco和ChArUco进行校准
ChArUco菱形标记(简称菱形标记)是由3x3方格和4个位于白色方格内的ArUco标记组成的棋盘。虽然外观与ChArUco标定板相似,但两者在概念上存在本质区别。

无论是ChArUco标定板还是菱形标记,它们的检测都基于预先识别出的ArUco标记。对于ChArUco标定板,系统通过直接查看标记ID来筛选使用的标记。这意味着只要图像中出现标定板包含的标记,就会自动认定其属于该标定板。然而,如果同一标定板的多个标记出现在图像中,会导致系统无法确定应该使用哪个标记,从而产生歧义。
相比之下,菱形标记的检测不依赖于标记ID,而是基于标记之间的相对位置关系。因此,同一菱形或不同菱形中的标记ID可以重复,系统仍能无歧义地同时检测它们。不过,由于基于相对位置关系寻找标记的复杂性,菱形标记的尺寸被限制为3x3方格和4个标记。
与单个ArUco标记类似,每个菱形标记由4个角点和1个标识符组成。四个角点对应标记中棋盘的四个角,而标识符实际上是由4个数字组成的数组,代表菱形内四个ArUco标记的ID。
菱形标记特别适用于需要允许重复标记的场景,例如:
- 通过使用菱形标记进行标注,可以大幅增加单个标记的标识符数量。理论上可实现N^4种不同ID(N为所用字典中的标记数量)
- 为四个标记赋予不同的语义含义。例如,可以用其中一个标记ID表示标记的尺度(即方格大小),这样只需更改四个标记中的一个,就能让同一菱形在环境中以不同尺寸被检测到,用户无需手动指定每个标记的尺度。该用例已包含在模块示例文件夹的
detect_diamonds.cpp文件中
此外,由于菱形标记的角点是棋盘角点,它们可用于高精度的位姿估计。
菱形标记相关功能定义在opencv2/objdetect/charuco_detector.hpp头文件中。
ChArUco 菱形标记生成
使用 cv::aruco::CharucoBoard::generateImage() 函数可以轻松生成菱形标记图像。例如:
vector<int> diamondIds = {ids[0], ids[1], ids[2], ids[3]};aruco::CharucoBoard charucoBoard(Size(3, 3), (float)squareLength, (float)markerLength, dictionary, diamondIds);Mat markerImg;charucoBoard.generateImage(Size(3*squareLength + 2*margins, 3*squareLength + 2*margins), markerImg, margins, borderBits);
这将创建一个边长为200像素的正方形钻石标记图像,标记大小为120像素。标记ID通过第二个参数以cv::Vec4i对象形式给出。钻石布局中的标记ID顺序与标准ChArUco标定板相同,即顶部、左侧、右侧和底部。
生成的图像如下:

钻石标记
完整可运行示例位于samples/cpp/tutorial_code/objectDetection/目录下的create_diamond.cpp文件中。
示例程序create_diamond.cpp现在通过cv::CommandLineParser从命令行接收输入参数。对于该文件,示例参数格式如下:
"_path_/mydiamond.png" -sl=200 -ml=120 -d=10 -ids=0,1,2,3
ChArUco 菱形标记检测
与大多数情况类似,检测菱形标记需要先完成ArUco标记的检测。在检测到标记后,使用 cv::aruco::CharucoDetector::detectDiamonds() 函数来检测菱形标记:
vector<int> markerIds;vector<Vec4i> diamondIds;vector<vector<Point2f> > markerCorners, diamondCorners;vector<Vec3d> rvecs, tvecs;detector.detectDiamonds(image, diamondCorners, diamondIds, markerCorners, markerIds);
cv::aruco::CharucoDetector::detectDiamonds()函数接收原始图像以及先前检测到的标记角点和ID。如果markerCorners和markerIds为空,该函数将自动检测ArUco标记及其ID。输入图像对于在ChArUco角点执行亚像素级优化是必需的。该函数还接收正方形尺寸与标记尺寸的比例参数,该参数在以下两个步骤中都需要使用:根据标记的相对位置检测菱形,以及插值计算ChArUco角点。
函数通过两个参数返回检测到的菱形。第一个参数diamondCorners是一个数组,包含每个检测到菱形的四个角点。其格式与cv::aruco::ArucoDetector::detectMarkers()函数检测到的角点类似,且每个菱形的角点顺序与ArUco标记一致——即从左上角开始顺时针排列。第二个返回参数diamondIds包含diamondCorners中所有菱形角点对应的ID,每个ID实际上是由4个整数组成的数组,可用cv::Vec4i类型表示。
检测到的菱形可通过cv::aruco::drawDetectedDiamonds()函数进行可视化,该函数只需接收图像及菱形角点和ID作为参数:
if(diamondIds.size() > 0) {aruco::drawDetectedDiamonds(imageCopy, diamondCorners, diamondIds);
该结果与 cv::aruco::drawDetectedMarkers() 生成的相同,但会打印出菱形标记的四个ID:

检测到的菱形标记
完整可运行示例位于 samples/cpp/tutorial_code/objectDetection/ 目录下的 detect_diamonds.cpp 文件中。
现在,示例 detect_diamonds.cpp 通过 cv::CommandLineParser 接收命令行输入。对于该文件,示例参数如下所示:
-dp=path_to_opencv/opencv/samples/cpp/tutorial_code/objectDetection/detector_params.yml -sl=0.4 -ml=0.25 -refine=3
-v=path_to_opencv/opencv/doc/tutorials/objdetect/charuco_diamond_detection/images/diamondmarkers.jpg
-cd=path_to_opencv/opencv/samples/cpp/tutorial_code/objectDetection/tutorial_dict.yml
ChArUco 菱形姿态估计
由于 ChArUco 菱形由其四个角点表示,其姿态估计方式与单个 ArUco 标记相同,即使用 cv::solvePnP() 函数。例如:
// estimate diamond posesize_t N = diamondIds.size();if(estimatePose && N > 0) {cv::Mat objPoints(4, 1, CV_32FC3);rvecs.resize(N);tvecs.resize(N);if(!autoScale) {// set coordinate systemobjPoints.ptr<Vec3f>(0)[0] = Vec3f(-squareLength/2.f, squareLength/2.f, 0);objPoints.ptr<Vec3f>(0)[1] = Vec3f(squareLength/2.f, squareLength/2.f, 0);objPoints.ptr<Vec3f>(0)[2] = Vec3f(squareLength/2.f, -squareLength/2.f, 0);objPoints.ptr<Vec3f>(0)[3] = Vec3f(-squareLength/2.f, -squareLength/2.f, 0);// Calculate pose for each markerfor (size_t i = 0ull; i < N; i++)solvePnP(objPoints, diamondCorners.at(i), camMatrix, distCoeffs, rvecs.at(i), tvecs.at(i));
该函数将获取每个菱形标记的旋转和平移向量,并将它们存储在 rvecs 和 tvecs 中。需要注意的是,菱形角点实际上是棋盘格方块的角点,因此进行姿态估计时需要提供方块边长而非标记长度。此外还需提供相机标定参数。
最后,可以通过调用 drawFrameAxes() 绘制坐标系来验证估计的姿态是否正确:

检测到的菱形坐标系
菱形姿态的坐标系将位于标记中心,Z轴向外延伸,这与简单的ArUco标记姿态估计方式一致。
示例视频:
此外,ChArUco菱形姿态也可以像ChArUco标定板一样进行估计:
for (size_t i = 0ull; i < N; i++) { // estimate diamond pose as Charuco boardMat objPoints_b, imgPoints;// The coordinate system of the diamond is placed in the board plane centered in the bottom left cornervector<int> charucoIds = {0, 1, 3, 2}; // if CCW order, Z axis pointing in the plane// vector<int> charucoIds = {0, 2, 3, 1}; // if CW order, Z axis pointing out the planecharucoBoard.matchImagePoints(diamondCorners[i], charucoIds, objPoints_b, imgPoints);solvePnP(objPoints_b, imgPoints, camMatrix, distCoeffs, rvecs[i], tvecs[i]);}
完整可运行示例位于 samples/cpp/tutorial_code/objectDetection/ 目录下的 detect_diamonds.cpp 文件中。
示例程序 detect_diamonds.cpp 现在通过 cv::CommandLineParser 接收命令行输入参数。对于该文件,示例参数格式如下:
-dp=path_to_opencv/opencv/samples/cpp/tutorial_code/objectDetection/detector_params.yml -sl=0.4 -ml=0.25 -refine=3
-v=path_to_opencv/opencv/doc/tutorials/objdetect/charuco_diamond_detection/images/diamondmarkers.jpg
-cd=path_to_opencv/opencv/samples/cpp/tutorial_code/objectDetection/tutorial_dict.yml
-c=path_to_opencv/opencv/samples/cpp/tutorial_code/objectDetection/tutorial_camera_params.yml
生成于 2025年4月30日 星期三 23:08:42,由 doxygen 1.12.0 为 OpenCV 创建
使用ArUco和ChArUco进行标定
https://docs.opencv.org/4.x/da/d13/tutorial_aruco_calibration.html
上一篇教程: 菱形标记检测
下一篇教程: ArUco模块常见问题
ArUco模块也可用于相机标定。相机标定的目的是获取相机内参和畸变系数。这些参数在相机光学组件未改动时保持不变,因此通常只需进行一次标定。
传统相机标定通常使用OpenCV的cv::calibrateCamera()函数。该函数需要多组三维空间点与其在相机图像中投影点的对应关系,这些对应点通常来自棋盘格图案的角点。更多细节可参考cv::calibrateCamera()函数文档或OpenCV标定教程。
通过ArUco模块,可以利用ArUco标记角点或ChArUco角点进行标定。与传统棋盘格相比,ArUco标定具有更强的适应性,能容忍标记遮挡或局部可见的情况。
虽然可以使用标记角点或ChArUco角点进行标定,但强烈推荐使用ChArUco角点方案,因为其提供的角点坐标精度远高于普通标记角点。仅在无法使用ChArUco标定板的特殊场景下,才考虑使用标准ArUco板进行标定。
使用 ChArUco 标定板进行校准
要通过 ChArUco 标定板进行校准,需要从不同视角检测标定板,这与传统棋盘格图案的标准校准方法相同。不过,由于使用 ChArUco 的优势,允许存在遮挡和局部视角,并非所有角点都需要在所有视角中可见。

ChArUco 校准视角
使用 cv::calibrateCamera() 对 cv::aruco::CharucoBoard 进行校准的示例:
// Create charuco board object and CharucoDetectoraruco::CharucoBoard board(Size(squaresX, squaresY), squareLength, markerLength, dictionary);aruco::CharucoDetector detector(board, charucoParams, detectorParams);// Collect data from each framevector<Mat> allCharucoCorners, allCharucoIds;vector<vector<Point2f>> allImagePoints;vector<vector<Point3f>> allObjectPoints;vector<Mat> allImages;Size imageSize;while(inputVideo.grab()) {Mat image, imageCopy;inputVideo.retrieve(image);vector<int> markerIds;vector<vector<Point2f>> markerCorners;Mat currentCharucoCorners, currentCharucoIds;vector<Point3f> currentObjectPoints;vector<Point2f> currentImagePoints;// Detect ChArUco boarddetector.detectBoard(image, currentCharucoCorners, currentCharucoIds);
if(key == 'c' && currentCharucoCorners.total() > 3) {// Match image pointsboard.matchImagePoints(currentCharucoCorners, currentCharucoIds, currentObjectPoints, currentImagePoints);if(currentImagePoints.empty() || currentObjectPoints.empty()) {cout << "Point matching failed, try again." << endl;continue;}cout << "Frame captured" << endl;allCharucoCorners.push_back(currentCharucoCorners);allCharucoIds.push_back(currentCharucoIds);allImagePoints.push_back(currentImagePoints);allObjectPoints.push_back(currentObjectPoints);allImages.push_back(image);imageSize = image.size();}}
Mat cameraMatrix, distCoeffs;if(calibrationFlags & CALIB_FIX_ASPECT_RATIO) {cameraMatrix = Mat::eye(3, 3, CV_64F);cameraMatrix.at<double>(0, 0) = aspectRatio;}// Calibrate camera using ChArUcodouble repError = calibrateCamera(allObjectPoints, allImagePoints, imageSize, cameraMatrix, distCoeffs,noArray(), noArray(), noArray(), noArray(), noArray(), calibrationFlags);
在每个视角捕获的ChArUco角点和ChArUco标识符分别存储在向量allCharucoCorners和allCharucoIds中,每个视角对应一个元素。
calibrateCamera()函数将用相机标定参数填充cameraMatrix和distCoeffs数组,并返回标定得到的重投影误差。rvecs和tvecs中的元素将被填充为相机在每个视角下的估计姿态(相对于ChArUco标定板)。
最后,calibrationFlags参数决定了标定过程中的一些选项。
完整可运行示例位于samples/cpp/tutorial_code/objectDetection文件夹中的calibrate_camera_charuco.cpp文件。
现在示例通过cv::CommandLineParser接收命令行输入。对于该文件,示例参数如下:
"camera_calib.txt" -w=5 -h=7 -sl=0.04 -ml=0.02 -d=10
-v=path/img_%02d.jpg
来自 opencv/samples/cpp/tutorial_code/objectDetection/tutorial_camera_charuco.yml 的相机标定参数是通过处理 该文件夹 中的 img_00.jpg-img_03.jpg 图像获取的。
使用ArUco标定板进行校准
如前所述,建议使用ChArUco标定板而非ArUco标定板进行相机校准,因为ChArUco角点比标记角点更精确。但在某些特殊情况下,可能需要使用基于ArUco标定板的校准方法。与之前的情况类似,该方法需要从不同视角检测ArUco标定板。

ArUco校准视角
使用cv::calibrateCamera()对cv::aruco::GridBoard进行校准的示例:
// Create board object and ArucoDetectoraruco::GridBoard gridboard(Size(markersX, markersY), markerLength, markerSeparation, dictionary);aruco::ArucoDetector detector(dictionary, detectorParams);// Collected frames for calibrationvector<vector<vector<Point2f>>> allMarkerCorners;vector<vector<int>> allMarkerIds;Size imageSize;while(inputVideo.grab()) {Mat image, imageCopy;inputVideo.retrieve(image);vector<int> markerIds;vector<vector<Point2f>> markerCorners, rejectedMarkers;// Detect markersdetector.detectMarkers(image, markerCorners, markerIds, rejectedMarkers);// Refind strategy to detect more markersif(refindStrategy) {detector.refineDetectedMarkers(image, gridboard, markerCorners, markerIds, rejectedMarkers);}
if(key == 'c' && !markerIds.empty()) {cout << "Frame captured" << endl;allMarkerCorners.push_back(markerCorners);allMarkerIds.push_back(markerIds);imageSize = image.size();}}
Mat cameraMatrix, distCoeffs;if(calibrationFlags & CALIB_FIX_ASPECT_RATIO) {cameraMatrix = Mat::eye(3, 3, CV_64F);cameraMatrix.at<double>(0, 0) = aspectRatio;}// Prepare data for calibrationvector<Point3f> objectPoints;vector<Point2f> imagePoints;vector<Mat> processedObjectPoints, processedImagePoints;size_t nFrames = allMarkerCorners.size();for(size_t frame = 0; frame < nFrames; frame++) {Mat currentImgPoints, currentObjPoints;gridboard.matchImagePoints(allMarkerCorners[frame], allMarkerIds[frame], currentObjPoints, currentImgPoints);if(currentImgPoints.total() > 0 && currentObjPoints.total() > 0) {processedImagePoints.push_back(currentImgPoints);processedObjectPoints.push_back(currentObjPoints);}}// Calibrate cameradouble repError = calibrateCamera(processedObjectPoints, processedImagePoints, imageSize, cameraMatrix, distCoeffs,noArray(), noArray(), noArray(), noArray(), noArray(), calibrationFlags);
完整可运行示例位于 samples/cpp/tutorial_code/objectDetection 文件夹中的 calibrate_camera.cpp 文件。
现在这些示例通过 cv::CommandLineParser 接收命令行输入。对于该文件,示例参数如下所示:
"camera_calib.txt" -w=5 -h=7 -l=100 -s=10 -d=10 -v=path/aruco_videos_or_images
生成于 2025年4月30日 星期三 23:08:42,由 doxygen 1.12.0 为 OpenCV 生成
ArUco 模块常见问题解答
https://docs.opencv.org/4.x/d1/dcb/tutorial_aruco_faq.html
上一教程: 使用ArUco和ChArUco进行标定
本文整理了关于使用aruco模块的常见问题。
- 我只想标记一些物体,应该使用什么?
这种情况下,只需使用单个ArUco标记即可。您可以在每个需要识别的物体上放置一个或多个不同ID的标记。
- 标记检测使用什么算法?
aruco模块基于原始ArUco库。完整的检测过程描述可参考:
S. Garrido-Jurado, R. Muñoz-Salinas, F. J. Madrid-Cuevas, and M. J. Marín-Jiménez. 2014、“Automatic generation and detection of highly reliable fiducial markers under occlusion”. Pattern Recogn. 47, 6 (June 2014), 2280-2292. DOI=10.1016/j.patcog.2014.01.005
- 我的标记无法正确检测,该怎么办?
可能有很多因素会影响标记的正确检测。您可能需要调整cv::aruco::DetectorParameters对象中的某些参数。首先可以检查标记是否被cv::aruco::ArucoDetector::detectMarkers()函数返回为被拒绝的候选。根据结果,您应该尝试修改不同的参数。
如果使用ArUco板,还可以尝试cv::aruco::ArucoDetector::refineDetectedMarkers()函数。如果使用大尺寸标记(400x400像素及以上),尝试增加cv::aruco::DetectorParameters::adaptiveThreshWinSizeMax值。同时避免ArUco标记周围过窄的边框(标记周长的5%或更少,可通过cv::aruco::DetectorParameters::minMarkerDistanceRate调整)。
- ArUco板有什么优点?有什么缺点?
使用标记板可以从一组标记中获取相机姿态,而不仅依赖单个标记。这样即使部分标记被遮挡,只要能看到一个标记就能获取姿态。
此外,由于通常使用更多角点进行姿态估计,其精度会比使用单个标记更高。
主要缺点是标记板不如单个标记灵活。
- ChArUco板相比ArUco板有什么优点?有什么缺点?
ChArUco板结合了棋盘格和ArUco板。因此,ChArUco板提供的角点比ArUco板(或单个标记)更精确。
主要缺点是ChArUco板不如ArUco板灵活。例如,ChArUco板是平面板且具有特定的标记布局,而ArUco板可以有任何布局,甚至是3D的。此外,ChArUco板中的标记通常更小,更难检测。
- 我不需要姿态估计,应该使用ChArUco板吗?
不需要。ChArUco板的主要目的是为姿态估计或相机标定提供高精度角点。
- ArUco板中的所有标记必须在同一平面吗?
不需要,ArUco板中的标记角点可以放置在其3D坐标系中的任何位置。
- ChArUco板中的所有标记必须在同一平面吗?
是的,ChArUco板中的所有标记必须在同一平面,且其布局由棋盘格形状固定。
cv::aruco::Board对象和cv::aruco::GridBoard对象有什么区别?
cv::aruco::GridBoard类是继承自cv::aruco::Board类的特定类型板。一个cv::aruco::GridBoard对象是其标记位于同一平面且呈网格布局的板。
- 什么是Diamond标记?
Diamond标记与3x3方格的ChArUco板非常相似。但与ChArUco板不同,Diamond的检测基于标记的相对位置。当您想为Diamond中的任何(或所有)标记赋予概念意义时,它们很有用。例如使用其中一个标记来提供Diamond的比例。
- 在进行板检测、ChArUco板检测或Diamond检测之前,是否需要先检测标记?
是的,单个标记的检测是aruco模块的基本功能。使用cv::aruco::DetectorParameters::detectMarkers()函数完成。其他功能都接收来自此函数的已检测标记列表。
- 我想校准相机,可以使用这个模块吗?
可以,aruco模块提供了使用ArUco板和ChArUco板进行相机标定的功能。
- 应该使用ChArUco板还是ArUco板进行标定?
强烈推荐使用ChArUco板进行标定,因为其精度更高。
- 应该使用预定义字典还是生成自己的字典?
通常使用预定义字典更简单。但如果需要更大的字典(就标记数量或位数而言),则应生成自己的字典。当您想最大化标记间距离以在识别步骤中实现更好的纠错时,字典生成也很有用。
- 我生成自己的字典耗时太长
字典生成只需在应用程序开始时执行一次,且只需几秒钟。如果在检测循环的每次迭代中都生成字典,这是错误的做法。
此外,建议使用cv::aruco::Dictionary::writeDictionary()将字典保存到文件,并在每次执行时用cv::aruco::Dictionary::readDictionary()读取,这样就不需要每次都生成。
- 我想使用已经打印的原始ArUco库中的一些标记,可以使用吗?
可以,预定义字典之一cv::aruco::DICT_ARUCO_ORIGINAL`可以检测原始ArUco库中具有相同标识符的标记。
- 可以在本模块中使用原始ArUco库的板配置文件吗?
不能直接使用,您需要将ArUco文件的信息适配到aruco模块的板格式。
- 可以使用本模块检测其他基于二进制基准标记的库的标记吗?
可能可以,但您需要将原始库的字典移植到aruco模块格式。
- 需要将字典信息存储在文件中以便在不同执行中使用吗?
如果使用预定义字典,则不需要。否则建议将其保存到文件。
- 需要将板信息存储在文件中以便在不同执行中使用吗?
如果使用cv::aruco::GridBoard或cv::aruco::CharucoBoard,只需存储提供给cv::aruco::GridBoard::GridBoard()构造函数或cv::aruco::CharucoBoard构造函数的板尺寸。如果手动修改板的标记ID,或使用不同类型的板,应将板对象保存到文件。
- aruco模块提供将字典或板保存到文件的功能吗?
可以使用cv::aruco::Dictionary::writeDictionary()和cv::aruco::Dictionary::readDictionary()处理cv::aruco::Dictionary。板类的数据成员是公开的,可以轻松存储。
- 好的,但如何渲染3D模型以创建增强现实应用?
为此,您需要使用外部渲染引擎库,如OpenGL。aruco模块仅提供获取相机姿态(即旋转和平移向量)的功能,这是创建增强现实效果所必需的。但您需要将旋转和平移向量从OpenCV格式适配到3D渲染库接受的格式。原始ArUco库包含如何为OpenGL和Ogre3D执行此操作的示例。
- 我在研究工作中使用了这个模块,如何引用?
您可以引用原始ArUco库:
S. Garrido-Jurado, R. Muñoz-Salinas, F. J. Madrid-Cuevas, and M. J. Marín-Jiménez. 2014、“Automatic generation and detection of highly reliable fiducial markers under occlusion”. Pattern Recogn. 47, 6 (June 2014), 2280-2292. DOI=10.1016/j.patcog.2014.01.005
- 姿态估计标记无法正确检测,该怎么办?
重要的是要注意,仅使用4个共面点进行姿态估计存在歧义。通常,如果相机靠近标记,可以解决歧义。但随着标记变小,角点估计的误差增大,歧义成为问题。尝试增大标记尺寸,也可以尝试使用非对称标记(aruco_dict_utils.cpp)以避免冲突。使用多个标记(ArUco/ChArUco/Diamonds板)和带有cv::SOLVEPNP_IPPE_SQUARE`选项的solvePnP()进行姿态估计。更多信息见此问题。
生成于 2025年4月30日 星期三 23:08:42,由 doxygen 1.12.0 生成
2025-07-19(六)