Machine Learning HW2 report:语音辨识(Hongyi Lee)
任务要求:分类音素。
注意:原代码shift函数存在问题
优化思路
- 增加dropout layers,并测试不同dropout rates
- 标准化 Batch Normalization
- 增加layer和parameter,比较“narrower and deeper”和“wider and shallower”的效果
- 增加concat_nframes
- 增加epoch数量
结果
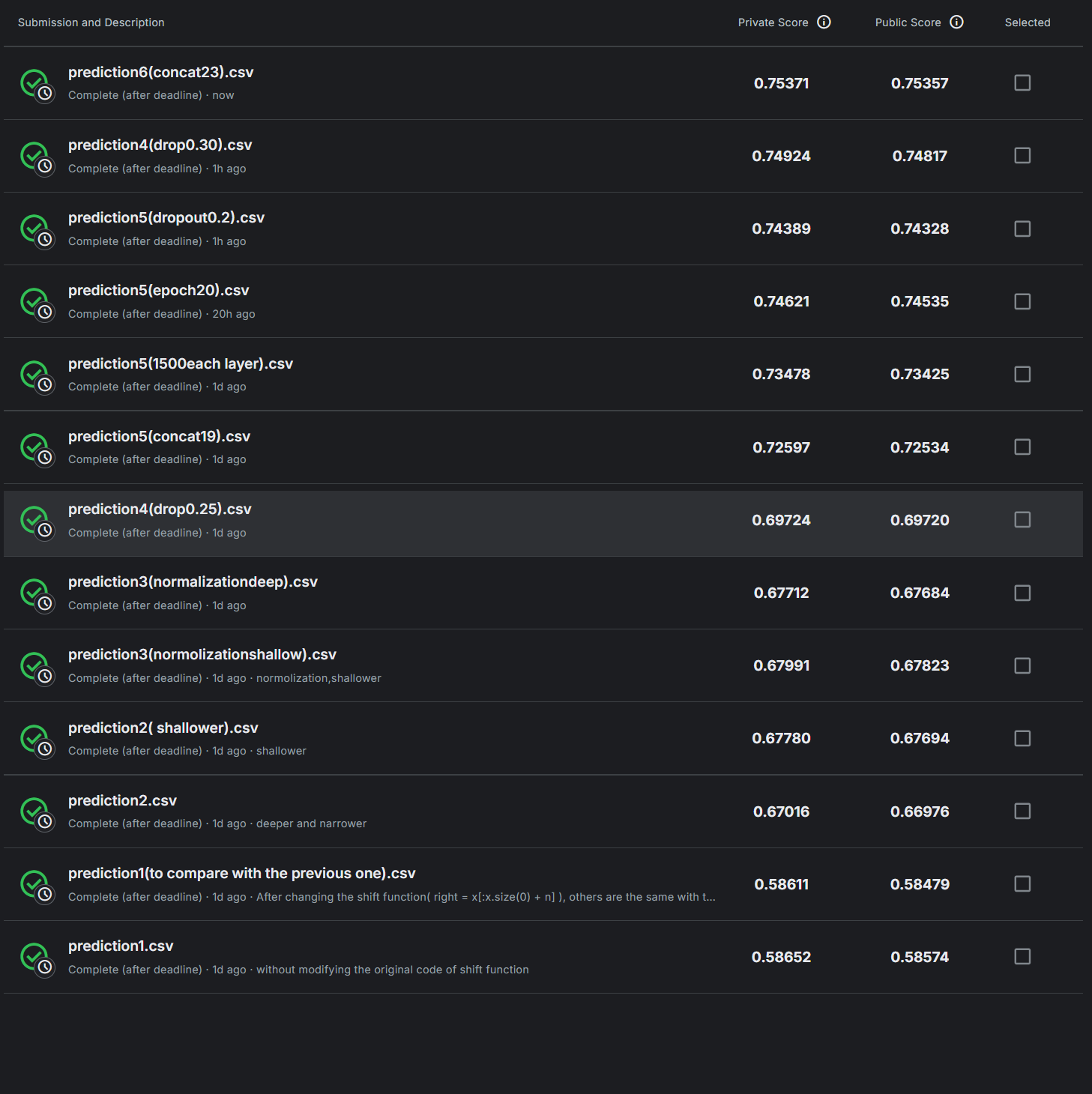
实验过程
- 第一次,没有任何修改,训练结果 acc 0.49579
- 第二次,发现原代码shift函数存在问题,shift函数是用于移动数据,便于concat_nframes,但原代码在n< 0时,right的逻辑有误,shift前后x零维的大小改变为2n的绝对值。所以把相应代码改为如下所示,但奇怪的是和第一次结果没有任何差别,怀疑是concat_nframes为3,太小了,所以恰好无影响。
right = x[:x.size(0) + n]
- 第三次,保持上述改动,将concat_nframes从3增加到11(增加前后五段),best accuracy: 0.58330,Kaggle得分0.58611(private)
- 将上述改动改回来,即使用原来的shift函数,best accuracy: 0.58461更高,Kaggle得分0.58652。非常奇怪的是比第三次效果好,但是原函数确实有逻辑问题,短期内可能“表现更好”,但其逻辑错误会导致不可预测的行为,尤其在部署时可能失败。所以后续全部采用修改的shift函数
- 增加参数数量,神经网络结构调整如下。best accuracy: 0.67552,似乎存在过拟合问题:最后一次Train Acc: 0.7988,Kaggle:0.67780
hidden_layers = 2 # the number of hidden layershidden_dim = 1700 # the hidden dim
- 调整神经网络,使总参数量与第五次(wider and shallower)一致,此次narrower and deeper。best accuracy: 0.66733,Kaggle:0.67016
hidden_layers = 6 # the number of hidden layershidden_dim = 1024 # the hidden dim
- 保留wider and shallower的架构,使用 Batch Normalization,在BasicBlock中nn.Sequential神经网络中加上一行代码。best accuracy: 0.67778,Kaggle:0.67991,private分数比起没使用Normalization有一点提升。
self.block = nn.Sequential(nn.Linear(input_dim, output_dim),nn.BatchNorm1d(output_dim), #Normalizationnn.ReLU(),)
- narrower and deeper架构 + Batch Normalization。best accuracy: 0.67453,Kaggle:0.67712
- 使用dropout layer, dropout_rate 设置为0.75。best accuracy: 0.53794。效果不好,但是训练进步速度非常快,10个epoch,每次都会更新best accuracy,从0.17涨到0.53。如果将epoch数量增加到30个,或许表现比以上的都要出色。
self.block = nn.Sequential( nn.Linear(input_dim, output_dim), nn.BatchNorm1d(output_dim), #batch normalization nn.ReLU(), nn.Dropout(dropout_rate) # 在ReLU后添加Dropout
)
- dropout_rate 设置为0.5,Total time: 11 min 8 sec,best accuracy: 0.64799
- dropout_rate 设置为0.25,运行时间10m 14s,best accuracy: 0.69419,Kaggle 0.69724,差一丝达到medium level,应该是不够深、参数不够多、concat_nframes还不够的问题。此外,发现运行速度并没有慢多少。
- dropout_rate 设置为0.25,concat_nframes改为19,Total time: 13 min 3 sec,best accuracy: 0.72252,kaggle:0.72597,达到了medium level
- hidden_dim = 1500,其余不变。效果很好,第一个epoch后acc 0.65176。Total time: 23 min 35 sec,best accuracy: 0.73143,kaggle:0.73478。此次训练没达到最佳效果:每一次都更新了best accuracy,只是最后两次幅度很小,应该增加epoch数量
- 将epoch数量改为20,并设置若连续5次没有改进,结束训练,其他不变,即使如此,也只有最后一次没有更新best accuracy。best accuracy: 0.74411,kaggle:0.74621。最后一次Train Acc: 0.78088,说明模型还不够好。
#if the model fails to improve for 5 times in a row, stop.
if sequential_useless_epoch>=5: print("the model fails to improve for 5 times in a row. Training stops.") break
else: print("Sequential Useless Epoch: ",sequential_useless_epoch)
- 因为本地训练实在太慢,故把代码上传到kaggle notebook进行训练,注意需要更改训练资料地址和输出结果地址。将epoch改为30,保留早退机制,把hidden layer增加到8。20个epoch后best accuracy为0.74421,与上一次几乎没有差距,说明此时增加参数量几乎没有提升。best accuracy:0.74714。
- 将hidden layer改回6,把dropout rate改为0.35,连续三次未更新退出训练。20个epoch后best accuracy为 0.73881,不如dropout rate = 0.25的情况。Total time: 27 min 57 sec, best accuracy: 0.74686
- dropout rate改为0.2,Total time: 19 min 19 sec, best accuracy: 0.74300,Kaggle:0.74389,不如训练20个epoch,dropout rate = 0.25的模型。
- dropout rate = 0.3,Total time: 26 min 16 sec, best accuracy: 0.74725。Kaggle:0.74924。
- 最后一次,dropout rate = 0.25,concat_nframes从19增加为23。Total time: 27 min 23 sec, best accuracy: 0.75230,Kaggle:0.75371,过了strong baseline
总结
- narrower and deeper和wider and shallower在此次任务上差别不大,后者表现略好
- Colab会限额,建议在kaggle notebook上训练,后者GPU性能和分配的时间都明显好于前者。
- kaggle notebook上训练时,记得改训练、测试用的数据文件地址和输出文件地址。
- kaggle notebook上训练完成后,在下载结果文件.csv前不要stop session,否则文件会被销毁!在如果要在自己电脑上运行
- 在增加参数或调整神经网络对结果没有明显提升时,可以考虑改变增加数据的feature