【DataWhale】快乐学习大模型 | 202507,Task03笔记
文章目录
- 1.计算词向量的相似性-公式拆解
- 2.自注意力机制
- 3. 掩码自注意力
注意力机制的三个核心变量:查询值 Query,键值 Key 和 真值 Value,这篇笔记将拆解教程中的公式,进行详细解释
1.计算词向量的相似性-公式拆解
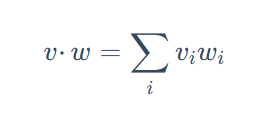
这里用到的是点积,如何理解用点积去计算向量的相似性呢?
首先是计算方式,点积的计算方式是把两个向量对应维度的值相乘,然后把所有乘积加起来。
- 如果两个向量在某个维度上都有大的正值,那么它们的乘积会很大且为正,对总和贡献大。
- 如果一个向量在某个维度是正值,另一个是负值,那么乘积是负的,会减小总和。
- 如果一个或两个向量在某个维度是零,那么该维度的乘积是零,没有贡献。
在词向量中的直观理解:假设词向量的每个维度代表词语的某种潜在语义特征。如果两个词向量的点积很大且为正,这通常意味着它们在许多相同的语义特征上都有相似的“强度”。
负的点积表示两个词语在某些语义特征上是“对立”的。在标准的词向量模型中,这种情况相对较少,因为词向量通常编码的是相似性而非反义。
计算Query和每一个键的相似程度
这里教程中用到的一个公式是:
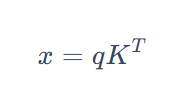
其中K展开如下图公式:

这里是做的一个矩阵乘法,得到的 x 即反映了 Query 和每一个 Key 的相似程度
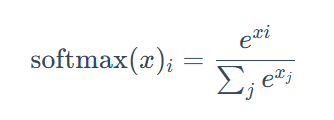
再通过softmax对 得到的x进行处理,就可以得到总和为1的权重。(Softmax 函数通常用于将一个任意实数向量的元素“压缩”到 (0,1) 区间内,并且使所有元素的和为 1。这使得它非常适合表示概率分布,这里就不赘述了)
Query (q) 向量与 Key (K) 矩阵的转置 K^T 相乘 qK^T。这个乘积的结果是一个向量,它的每个元素代表 Query 与一个 Key 的点积相似度。
例如,如果 q 是 fruit 的向量,K 包含 apple, banana, chair 的向量,那么 qK^T 得到的就是 [fruit·apple, fruit·banana, fruit·chair]。这些值越大,表示 Query 与对应的 Key 越相似。
将得到的注意力分数和值向量做对应乘得到注意力机制的基本公式:
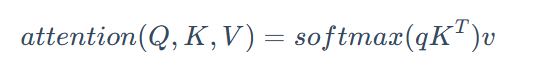
这里进一步拆解3个值
- Query (Q) 向量: 它代表了“我正在寻找什么信息?”或者“我的关注点是什么?”
- Key (K) 向量: 它代表了“我有什么信息可以被查找?”或者“我的特征是什么?”
- Value (V) 向量: 它代表了“如果我被选中,我能提供什么具体内容?”或者“我的实际信息载体是什么?”
所以我们在得到注意力分数即softmax(QK^T)后还需要和值向量V相乘。
进一步延申,将多个 Query 对应的词向量堆叠在一起形成矩阵 Q,得到公式:
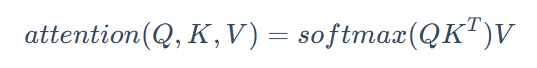
最后为了在反向传播中计算梯度的方便,为了将点积的方差稳定在 1 左右,上面的式子还需要除以一个值,旨在解决高维向量点积值过大导致 Softmax 梯度不稳定的问题,使训练过程更稳定。
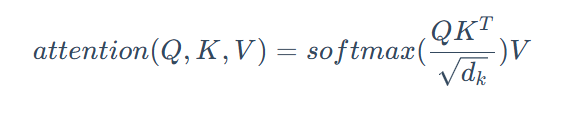
这一部分我查了一下大模型的解释:

2.自注意力机制
注意力机制的本质是对两段序列的元素依次进行相似度计算,寻找出一个序列的每个元素对另一个序列的每个元素的相关度,然后基于相关度进行加权,即分配注意力。
注意力机制实现代码:
'''注意力计算函数'''
def attention(query, key, value, dropout=None):'''args:query: 查询值矩阵key: 键值矩阵value: 真值矩阵'''
# 后面的省略
而自注意力机制则是是一种高度抽象的表示,它想表达的是:自注意力机制的 Q、K、V 都源于同一个输入 x,如下:
# attention 为上文定义的注意力计算函数
attention(x, x, x)
“拟合输入语句中每一个 token 对其他所有 token 的关系”。这是自注意力最强大的能力之一。它让模型能够理解一个词在句子中与前面或后面的词的关联性,捕捉长距离依赖,并为每个词建立一个富含上下文信息的表示。
句子“他喜欢吃苹果。”,当模型处理“苹果”这个词时:
- “苹果”作为 Query,去和“他”、“喜欢”、“吃”、“苹果”这些词作为 Key 进行匹配。
- 它可能会发现“吃”与“苹果”的相似度很高(因为“吃”通常后面接食物)。
- 然后,它会根据这些相似度(注意力权重),加权聚合“他”、“喜欢”、“吃”、“苹果”各自的 Value 向量。最终,“苹果”的输出表示就包含了“吃”的信息,因为模型“关注”到了“吃”这个词。
3. 掩码自注意力
# 创建一个上三角矩阵,用于遮蔽未来信息。
# 先通过 full 函数创建一个 1 * seq_len * seq_len 的矩阵
mask = torch.full((1, args.max_seq_len, args.max_seq_len), float("-inf"))
# triu 函数的功能是创建一个上三角矩阵
mask = torch.triu(mask, diagonal=1)
通过上面的代码可以生成下面的矩阵(假设输入是I like you)
mask = [[0, -inf, -inf],[0, 0, -inf],[0, 0, 0]]
将计算得到的注意力分数与这个掩码做和,再进行 Softmax 操作:
# 此处的 scores 为计算得到的注意力分数,mask 为上文生成的掩码矩阵
scores = scores + mask[:, :seqlen, :seqlen]
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
即masked_scores = scores + mask
得到这样一个矩阵,再做 Softmax 操作。
这个加法操作的目的是为了在 Softmax 之前,将模型不应该“看到”的未来位置的注意力分数置为负无穷,从而确保 Softmax 之后这些位置的注意力权重变为 0,达到遮蔽未来信息的目的。
最后总结:
掩码自注意力是 Transformer 解码器的核心,它巧妙地结合了自注意力机制和掩码技术:
- 并行计算: 整个序列可以一次性输入模型进行计算,提高了效率。
- 遵守时间顺序: 通过在注意力分数上应用上三角掩码,确保每个位置的词在计算其表示时,只能“看到”和“利用”它之前(包括它自己)的信息,而无法“偷看”未来的信息。
- 防止信息泄露: 保证了模型在生成文本时,严格按照从左到右、逐词预测的语言模型任务要求进行。