【Linux】Linux异步IO-io_uring
一、io_uring介绍
1.1 配置io_uring库文件
io_uring从 Linux 内核 5.1 开始引入,但其功能在后续版本中不断完善(如 5.6 支持文件打开 / 关闭异步操作,5.8 支持网络 I/O 等)。推荐使用内核 5.8 及以上版本,以获得更完整的功能。
可以使用下述命令,查看当前Linux的内核版本
uname -r

-
io_uring的系统调用接口(如io_uring_setup、io_uring_enter)直接与内核交互,但手动处理复杂,我们一般开发可以使用封装好的liburing库 -
通过下述命令下载对应的库文件
sudo apt install liburing-dev
1.2 io_uring 原理
io_uring主要通过双环形队列机制来实现高效、异步通讯
- 提交队列
Submission Queue,简称sq,用于用户提交I/O请求 - 完成队列
Completion Queue,简称cq,用于内核返回结果
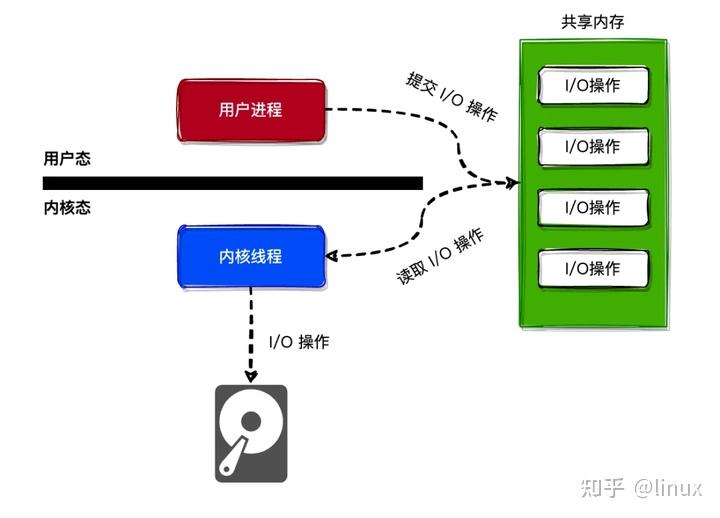
sq和cq在io_uring初始化时,由内核创建,并通过mmap将它们映射到用户空间,数据直接在共享内存中操作,无需用户空间和内核空间之间复制,提升了内存访问的效率
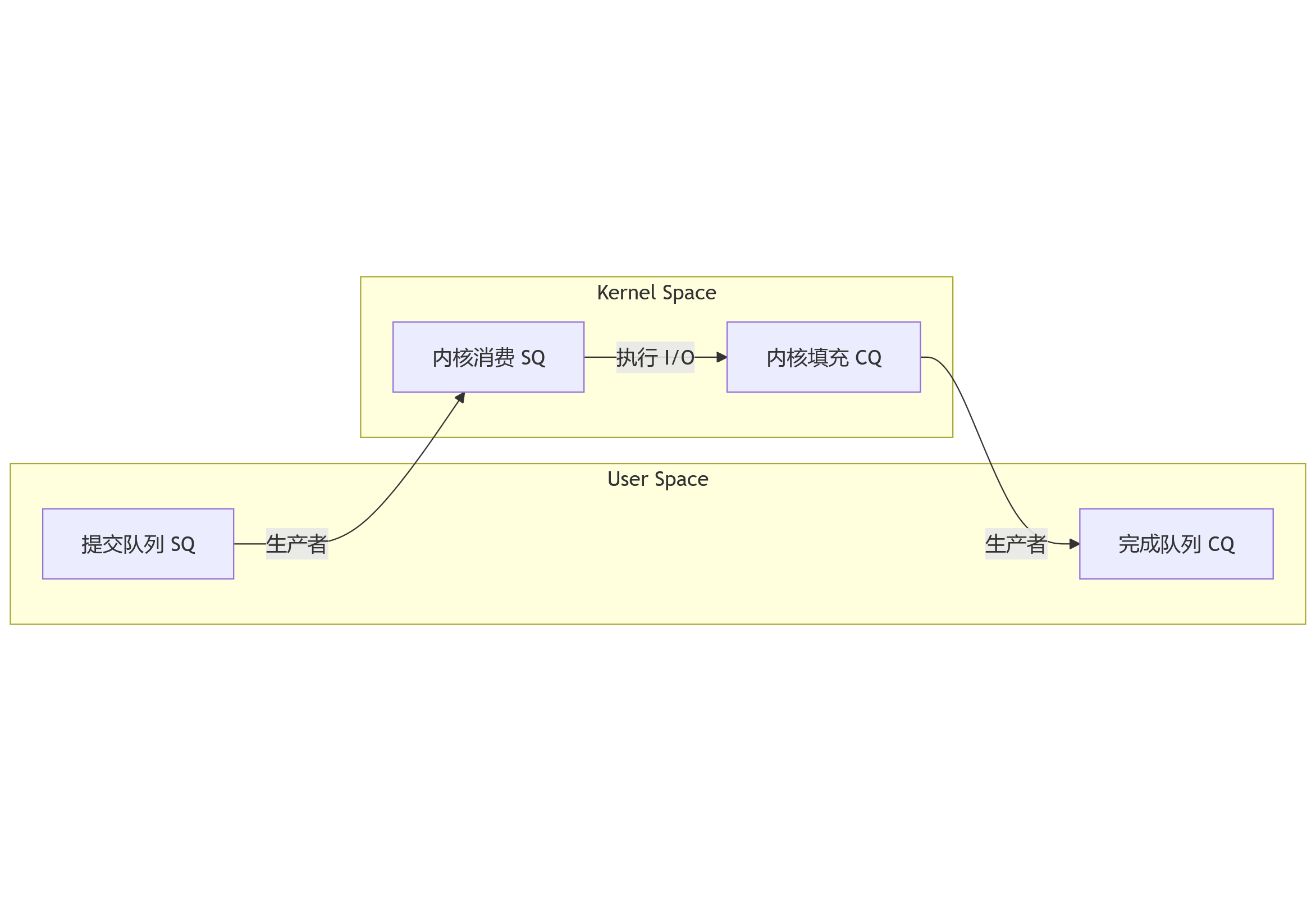
io_uring是真正的异步I/O,用户提交请求后无需等待,可执行后续任务- 内核完成
I/O操作后,通过cq来通知用户程序
1.2.1 提交队列sq
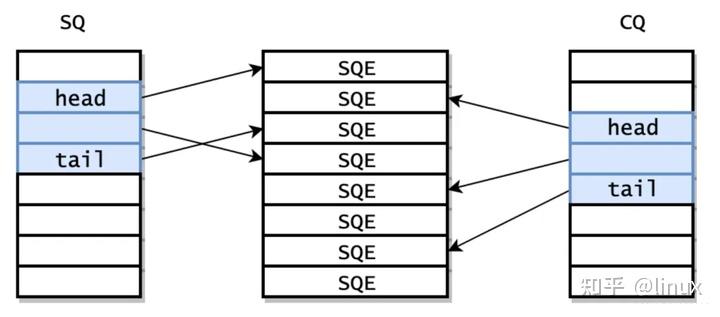
1. 环形队列设计
SQ 是一个固定大小的环形数组,由三部分组成:
- SQ 环(SQ Ring):
包含head、tail、mask等元数据,用于管理队列的读写位置。 - SQE 数组(Submission Queue Entries):
存储实际的 I/O 请求描述符(struct io_uring_sqe)。 - CQ 环(Completion Queue Ring):
虽然属于完成队列,但与 SQ 密切相关,用于内核通知完成事件。
2. 关键元数据
head:
内核读取 SQE 的位置(由内核更新)。tail:
用户程序写入 SQE 的位置(由用户程序更新)。mask:
用于环形队列的索引计算(值为entries - 1,entries必须是 2 的幂)。flags:
控制队列行为的标志位(如SQ_RING_FLAG_ATOMIC表示原子操作)。
3. SQE结构
每个 SQE 是一个 struct io_uring_sqe,用于描述一个具体的 I/O 请求:
struct io_uring_sqe {__u8 opcode; // 操作码(如 IORING_OP_READ、IORING_OP_WRITE)__u8 flags; // 操作标志(如 IORING_SQE_ASYNC)__u16 ioprio; // I/O 优先级__s32 fd; // 文件描述符__u64 offset; // 偏移量(如文件读写位置)__u64 addr; // 缓冲区地址__u32 len; // 长度__u32 rw_flags; // 读写标志(如 O_DIRECT)__u64 user_data; // 用户自定义数据(完成时通过 CQE 返回)// 其他字段(如分散/聚集 I/O、超时设置等)...
};
1.2.2 完成队列cq
1. 环形队列设计
CQ 与 SQ 类似,也是一个固定大小的环形数组,由三部分组成:
- CQ 环(CQ Ring):
包含head、tail、mask等元数据,用于管理队列的读写位置。 - CQE 数组(Completion Queue Entries):
存储 I/O 操作的完成结果(struct io_uring_cqe)。 - SQ 环(Submission Queue Ring):
虽然属于提交队列,但与 CQ 密切相关,用于用户程序提交请求。
2. 关键元数据
head:
用户程序读取 CQE 的位置(由用户程序更新)。tail:
内核写入 CQE 的位置(由内核更新)。mask:
用于环形队列的索引计算(值为entries - 1,entries必须是 2 的幂)。overflow:
当 CQ 满时,新完成的事件会导致溢出计数增加。
3. CQE结构
每个 CQE 是一个 struct io_uring_cqe,用于存储 I/O 操作的结果:
struct io_uring_cqe {__u64 user_data; // 与 SQE 中对应的 user_data 值__s32 res; // 操作结果(如读取的字节数,负值表示错误)__u32 flags; // 完成标志(如 IORING_CQE_F_MORE 表示还有更多事件)
};
1.3 io_uring的使用流程
在io_uring最主要的是下面三个函数:
io_uring_setup
io_uring_enter
io_uring_register
但是我们并不会直接去使用这几个函数,而是使用liburing提供的函数来实现功能,而liburing的函数并不止这几个。
1.3.1 io_uring 的基本操作流程:
- 第一步:应用程序通过向
io_uring的sq提交 I/O 操作。 - 第二步:SQ 内核线程从
sq中读取 I/O 操作。 - 第三步:SQ 内核线程发起 I/O 请求。
- 第四步:I/O 请求完成后,SQ 内核线程会将 I/O 请求的结果写入到
io_uring的cq中。 - 第五步:应用程序可以通过从
cq中读取到 I/O 操作的结果。
1.4 io_uring常用api
下面介绍一些常用的liburing库的函数原型,更多api可以使用man手册查看,比如这里查看io_uring_queue_init函数
man io_uring_queue_init
如果不存在man手册,可以在liburing官网下载:https://github.com/axboe/liburing/tree/master/man
1. io_uring_queue_init_params
int io_uring_queue_init_params(unsigned entries, struct io_uring *ring, struct io_uring_params *params);
- 功能:
初始化io_uring实例,创建提交队列(SQ)和完成队列(CQ),并应用用户指定的参数配置。 - 参数:
entries:队列深度(通常为 2 的幂,如 128、256)。ring:指向struct io_uring的指针。params:指向struct io_uring_params的指针,用于配置队列特性。
- 返回值:
- 成功:返回 0。
- 失败:返回负数错误码(如
-ENOMEM、-EINVAL)。
io_uring_params 结构体详解
struct io_uring_params {__u32 sq_entries; // SQ 大小(由内核返回)__u32 cq_entries; // CQ 大小(由内核返回)__u32 flags; // 初始化标志__u32 sq_thread_cpu; // SQ 轮询线程绑定的 CPU__u32 sq_thread_idle; // SQ 轮询线程空闲时间(毫秒)__u32 features; // 内核支持的特性(由内核返回)__u32 wq_fd; // 工作队列文件描述符(用于多进程共享)__u32 resv[3]; // 保留字段struct io_sqring_offsets sq_off; // SQ 偏移量(由内核返回)struct io_cqring_offsets cq_off; // CQ 偏移量(由内核返回)
};
1. flags 字段(配置标志)
常用标志:
-
IORING_SETUP_SQPOLL:
启用 SQ 轮询模式,内核会创建专用线程自动处理 SQ 请求,减少系统调用。
适用场景:高吞吐量、低延迟的服务器应用。 -
IORING_SETUP_CQSIZE:
允许独立设置 CQ 大小(通过params->cq_entries),默认与 SQ 大小相同。 -
IORING_SETUP_ATTACH_WQ:
将当前io_uring实例附加到已有工作队列(通过params->wq_fd),实现多进程共享队列。
2. sq_thread_cpu 和 sq_thread_idle
-
sq_thread_cpu:
指定 SQ 轮询线程绑定的 CPU 核心(需配合IORING_SETUP_SQPOLL使用)。
作用:减少 CPU 缓存失效,提升性能。 -
sq_thread_idle:
指定 SQ 轮询线程在没有请求时的空闲时间(毫秒),0 表示不空闲。
调优建议:根据负载情况调整,平衡 CPU 使用率和响应延迟。
3. features 字段(内核特性检测)
初始化后,内核会将支持的特性写入该字段,常见特性:
-
IORING_FEAT_FAST_POLL:
支持快速轮询模式,无需唤醒线程即可检测完成事件。 -
IORING_FEAT_NODROP:
保证 CQ 不会丢弃完成事件(即使队列已满)。
2. io_uring_queue_init()
int io_uring_queue_init(unsigned entries, struct io_uring *ring, unsigned flags);
- 功能:初始化
io_uring实例,创建提交队列(SQ)和完成队列(CQ)。 - 参数:
entries:队列深度(通常为 2 的幂,如 128、256)。ring:指向struct io_uring的指针。flags:配置标志(如IORING_SETUP_SQPOLL启用轮询模式)。
- 返回值:成功返回 0,失败返回负数错误码。
- 示例:
struct io_uring ring; int ret = io_uring_queue_init(256, &ring, 0); if (ret < 0) {perror("io_uring_queue_init");exit(1); }
3. io_uring_queue_exit()
void io_uring_queue_exit(struct io_uring *ring);
- 功能:清理
io_uring资源,释放队列占用的内存。 - 参数:
ring指向struct io_uring的指针。 - 注意:需确保所有 I/O 请求已完成或取消。
4. io_uring_get_sqe()
struct io_uring_sqe *io_uring_get_sqe(struct io_uring *ring);
- 功能:从提交队列获取一个空闲的 SQE(Submission Queue Entry)。
- 参数:
ring指向struct io_uring的指针。 - 返回值:成功返回 SQE 指针,失败返回
NULL(队列已满)。 - 示例:
struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);
if (!sqe) {fprintf(stderr, "提交队列已满\n");// 等待或处理完成队列
}
5. io_uring_prep_xxx()
// 常用操作示例
void io_uring_prep_read(struct io_uring_sqe *sqe, int fd, void *buf, unsigned nbytes, off_t offset);
void io_uring_prep_write(struct io_uring_sqe *sqe, int fd, const void *buf, unsigned nbytes, off_t offset);
void io_uring_prep_accept(struct io_uring_sqe *sqe, int fd, struct sockaddr *addr, socklen_t *addrlen, int flags);
void io_uring_prep_connect(struct io_uring_sqe *sqe, int fd, const struct sockaddr *addr, socklen_t addrlen);
- 功能:准备特定类型的 I/O 请求(如读、写、网络连接等)。
- 参数:
sqe:由io_uring_get_sqe()返回的 SQE 指针。fd:文件或套接字描述符。buf:数据缓冲区。nbytes:传输字节数。offset:文件偏移量(仅对文件 I/O 有效)。
示例:
io_uring_prep_read(sqe, fd, buffer, 1024, 0); // 从文件读取 1024 字节
6. io_uring_submit()
unsigned io_uring_submit(struct io_uring *ring);
- 功能:将 SQ 中已填充的请求提交给内核处理。
- 参数:
ring指向struct io_uring的指针。 - 返回值:成功提交的请求数量。
- 优化:可批量填充多个 SQE 后一次性提交,减少系统调用:
// 填充多个 SQE...
io_uring_submit(&ring); // 一次性提交所有请求
7. io_uring_wait_cqe()
int io_uring_wait_cqe(struct io_uring *ring, struct io_uring_cqe **cqe_ptr);
- 功能:阻塞等待完成队列中的事件。
- 参数:
ring:指向struct io_uring的指针。cqe_ptr:用于存储返回的 CQE 指针。
- 返回值:成功返回 0,失败返回负数错误码。
- 示例:
struct io_uring_cqe *cqe;
int ret = io_uring_wait_cqe(&ring, &cqe);
if (ret < 0) {perror("io_uring_wait_cqe");exit(1);
}
// 处理 cqe...
8. io_uring_peek_cqe()
int io_uring_peek_cqe(struct io_uring *ring, struct io_uring_cqe **cqe_ptr);
- 功能:非阻塞检查完成队列中是否有事件。
- 参数:同
io_uring_wait_cqe()。 - 返回值:
- 0:有可用事件,
*cqe_ptr指向该事件。 -EAGAIN:没有可用事件。
示例:
- 0:有可用事件,
struct io_uring_cqe *cqe;
if (io_uring_peek_cqe(&ring, &cqe) == 0) {// 处理 cqe...
} else {// 没有可用事件,继续其他工作
}
9. io_uring_cqe_seen()
`
void io_uring_cqe_seen(struct io_uring *ring, struct io_uring_cqe *cqe);
- 功能:标记 CQE 已处理,允许内核复用该位置。
- 参数:
ring:指向struct io_uring的指针。cqe:已处理的 CQE 指针。
- 注意:必须在处理完 CQE 后调用,否则内核不会继续填充该位置。
10. io_uring_peek_batch_cqe
int io_uring_peek_batch_cqe(struct io_uring *ring, struct io_uring_cqe **cqes, unsigned count);
- 功能:
非阻塞地从完成队列(CQ)中获取最多count个已完成的事件(CQE),并将它们的指针存储到cqes数组中。 - 参数:
ring:指向struct io_uring的指针。cqes:用于存储 CQE 指针的数组。count:期望获取的最大 CQE 数量。
- 返回值:
- 成功:返回实际获取的 CQE 数量(可能为 0)。
- 失败:返回负数错误码
11. io_uring_cqe_advance
void io_uring_cq_advance(struct io_uring *ring, unsigned count);
-
功能:
告知内核用户程序已处理count个完成事件(CQE),允许内核复用这些 CQE 位置。 -
参数:
ring:指向struct io_uring的指针。count:已处理的 CQE 数量。
-
举例:
struct io_uring_cqe *cqes[128];
int n_ready = io_uring_peek_batch_cqe(&ring, cqes, 128); // 获取多个 CQEfor (int i = 0; i < n_ready; i++) {// 处理每个 CQE...
}io_uring_cq_advance(&ring, n_ready); // 批量标记所有 CQE 已处理
二、使用io_uring实现高性能服务器
2.1 客户端实现
客户端我们简单实现,能够收发服务端消息即可,代码不涉及io_uring,不做讲解
#include <iostream>
#include <cstring>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <thread>#define PORT 9999
#define BUFFER_SIZE 1024// 接收服务器消息
void receive_messages(int socket) {char buffer[BUFFER_SIZE];while (true) {memset(buffer, 0, sizeof(buffer));ssize_t bytes_received = recv(socket, buffer, BUFFER_SIZE, 0);if (bytes_received <= 0) {std::cout << "服务器断开连接。" << std::endl;close(socket);return;}std::cout << "收到消息: " << buffer << std::endl;}
}int main() {int client_socket;struct sockaddr_in server_addr;// 创建客户端套接字client_socket = socket(AF_INET, SOCK_STREAM, 0);if (client_socket < 0) {std::cerr << "套接字创建失败。" << std::endl;return -1;}// 初始化服务器地址server_addr.sin_family = AF_INET;server_addr.sin_port = htons(PORT);server_addr.sin_addr.s_addr = inet_addr("127.0.0.1"); // 服务器 IP// 连接到服务器if (connect(client_socket, (struct sockaddr*)&server_addr, sizeof(server_addr)) < 0) {std::cerr << "连接服务器失败。" << std::endl;return -1;}std::cout << "成功连接服务器。" << std::endl;// 创建线程接收服务器消息std::thread receive_thread(receive_messages, client_socket);receive_thread.detach(); // 分离线程以便独立运行// 发送消息给服务器char message[BUFFER_SIZE];while (true) {std::cin.getline(message, BUFFER_SIZE);send(client_socket, message, strlen(message), 0);}close(client_socket);return 0;
}
2.2 服务端代码
2.2.1 实现流程
服务端使用liburing实现异步I/O的服务器,主要实现流程如下:
1. 服务器初始化
- 创建 TCP 套接字,绑定到指定端口(9999)并监听连接。
int initServer(unsigned int port);
2. 事件设置函数
- 每个函数获取一个提交队列项(SQE),设置对应的 I/O 操作(accept、recv、send),并将
connInfo结构体通过user_data关联到 SQE。
int setEventAccept(io_uring *ring, int sockfd, ...); // 初始化 accept 事件
int setEventRecv(io_uring *ring, int sockfd, ...); // 初始化读事件
void setEventSend(io_uring *ring, int sockfd, ...); // 初始化写事件
3. 主事件循环
- 提交请求后,通过完成队列(CQ)获取并处理 I/O 结果。
while (true) {io_uring_submit(&ring); // 提交请求到内核io_uring_wait_cqe(&ring, &cqe); // 等待完成事件// 批量处理完成事件...
}
2.2.2 具体实现
1. io_uring 初始化
io_uring_params params;
io_uring_queue_init_params(ENTRIES_LENGTH, &ring, ¶ms);
- 使用
io_uring_queue_init_params初始化,支持自定义队列参数,这里实际上只是默认参数
2. 自定义事件类型
struct connInfo {int fd; // 文件描述符int event; // 事件类型(EVENT_ACCEPT、EVENT_READ、EVENT_WRITE)
};
- 通过
user_data将connInfo与每个 I/O 请求关联,在完成时通过 CQE 获取上下文。
3. 事件处理流程
-
ACCEPT 事件:
- 接受新连接后,立即注册下一个 ACCEPT 事件(保持监听)。
- 为新连接的套接字注册 READ 事件。
-
READ 事件:
- 若读取到数据(
ret > 0),将数据原样返回(注册 WRITE 事件)。 - 若连接关闭(
ret == 0),关闭套接字。
- 若读取到数据(
-
WRITE 事件:
- 发送完成后,继续注册 READ 事件,保持会话持续。
4. 批量处理流程
int nReady = io_uring_peek_batch_cqe(&ring, cqes, 128);
io_uring_cq_advance(&ring, nReady);
- 使用
io_uring_peek_batch_cqe一次性获取多个完成事件,减少函数调用开销。 - 通过
io_uring_cq_advance批量标记事件已处理,提升效率。
2.2.3 完整代码
服务端的完整代码实现如下:
#include<iostream>
#include<liburing.h>
#include<unistd.h>
#include<netinet/in.h>
#include<cstring>
#include<cstdio>#define PORT 9999
#define ENTRIES_LENGTH 1024
#define BUFFER_LENGTH 1024#define EVENT_ACCEPT 0
#define EVENT_READ 1
#define EVENT_WRITE 2struct connInfo {int fd;int event;
};int initServer(unsigned int port){int sockfd = socket(AF_INET,SOCK_STREAM,0);struct sockaddr_in server_addr;memset(&server_addr,0,sizeof(sockaddr_in));server_addr.sin_family = AF_INET;server_addr.sin_port = htons(port);server_addr.sin_addr.s_addr = htonl(INADDR_ANY);int ret = bind(sockfd,(struct sockaddr*)(&server_addr),sizeof(sockaddr));if(ret == -1){perror("bind");return -1;}listen(sockfd,10);return sockfd;
}int setEventAccept(io_uring *ring,int sockfd,sockaddr_in *addr,socklen_t* addrlen,int flags){io_uring_sqe * sqe = io_uring_get_sqe(ring);connInfo info;info.event = EVENT_ACCEPT;info.fd = sockfd;io_uring_prep_accept(sqe,sockfd,(struct sockaddr*)addr,addrlen,flags);memcpy(&sqe->user_data,&info,sizeof(info));return 0;
}int setEventRecv(io_uring *ring,int sockfd,void *buf,size_t len,int flags){io_uring_sqe* sqe = io_uring_get_sqe(ring);connInfo info;info.event = EVENT_READ;info.fd = sockfd;io_uring_prep_recv(sqe,sockfd,buf,len,flags);memcpy(&sqe->user_data,&info,sizeof(info));return 0;
}void setEventSend(io_uring* ring,int sockfd,void *buf,size_t len,int flags){io_uring_sqe* sqe = io_uring_get_sqe(ring);connInfo info;info.event = EVENT_WRITE;info.fd = sockfd;io_uring_prep_send(sqe, sockfd, buf, len, flags);memcpy(&sqe->user_data, &info, sizeof(info));
}int main(){int sockfd = initServer(PORT);if(sockfd == -1){return -1;}io_uring_params params; memset(¶ms,0,sizeof(params));io_uring ring;io_uring_queue_init_params(ENTRIES_LENGTH,&ring,¶ms); char buffer[BUFFER_LENGTH];memset(buffer,0,sizeof(buffer));sockaddr_in clientaddr;socklen_t len = sizeof(clientaddr);setEventAccept(&ring,sockfd,&clientaddr,&len,0);while(true){io_uring_submit(&ring);io_uring_cqe *cqe;io_uring_wait_cqe(&ring,&cqe);io_uring_cqe* cqes[128];int nReady = io_uring_peek_batch_cqe(&ring,cqes,128);for(int i = 0 ; i < nReady ; ++i){io_uring_cqe* entries = cqes[i];connInfo info;memcpy(&info,&entries->user_data,sizeof(info));if(info.event == EVENT_ACCEPT){setEventAccept(&ring,sockfd,&clientaddr,&len,0);int connfd = entries->res;setEventRecv(&ring,connfd,buffer,BUFFER_LENGTH,0);}else if(info.event == EVENT_READ){int ret = entries->res;if(ret == 0){close(info.fd);}else if(ret > 0){setEventSend(&ring,info.fd,buffer,ret,0);}else{perror("EVENT_READ");}}else if(info.event == EVENT_WRITE){int ret = entries->res;setEventRecv(&ring,info.fd,buffer,BUFFER_LENGTH,0);}}io_uring_cq_advance(&ring,nReady);}io_uring_queue_exit(&ring);return 0;
}2.3 简单的通讯echo测试
启动客户端
./main2_client
编译、链接服务端代码,注意这里链接liburing.so
g++ main.cpp -o server -luring
运行服务端
./server
左侧是服务端,右侧是客户端,客户端向服务端发送消息,服务端将原消息再次发送给客户端

更多资料:https://github.com/0voice