大数据时代下的时序数据库选型指南:基于工业场景的IoTDB技术优势与适用性研究
声明:文章为本人真实测评博客,非广告,并没有推广该平台 ,为用户体验文章
一、引言
在工业4.0与物联网(IoT)的驱动下,全球时序数据规模正以每年超过40%的速度增长。据统计,单台智能电表每15分钟采集一次数据,全国5亿台设备每日将产生近500亿条时序记录。这类数据具有时间敏感、高频写入、强关联性等特征,传统关系型数据库难以满足其存储与分析需求。时序数据库(Time-Series Database, TSDB)作为专门处理此类数据的工具,已成为工业互联网、能源监测、金融交易等领域的核心基础设施。在众多开源与商业产品中,IoTDB凭借其自主可控的技术架构与工业场景深度优化,正逐步成为国产时序数据库的标杆。本文将从需求分析、技术对比、行业应用等维度,系统阐述IoTDB的选型价值。

文章目录
- 一、引言
- 二、大数据场景下对时序数据库的需求剖析
- 1. 海量数据存储需求
- 2. 高写入性能要求
- 3. 复杂查询与分析需求
- 4. 数据一致性与可靠性需求
- 三、主流时序数据库介绍
- 1. IoTDB:工业场景的自主可控之选
- 2. 国外代表产品对比:InfluxDB
- 四、性能对比测试
- 1. 测试环境与方法
- 2. 写入性能对比
- 3. 查询性能对比
- 4. 存储效率对比
- 五、IoTDB行业应用案例
- 1. 工业互联网:宝武钢铁集团
- 2. 能源行业:国家电网智能电表
- 3. 物联网:长安汽车车联网平台
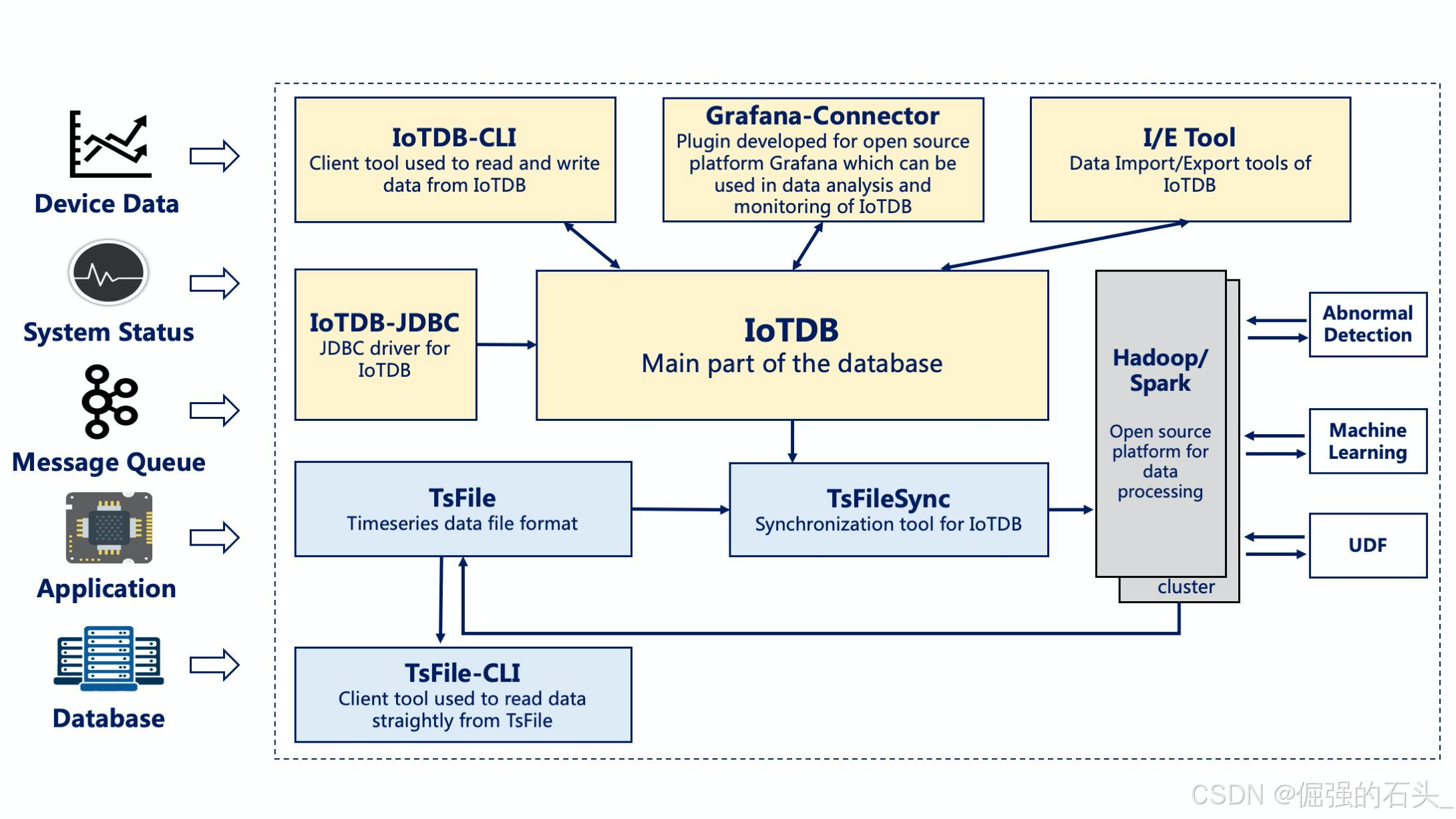
- 六、IoTDB下载与使用指南
- 1. 社区版下载
- 2. 企业版服务
- 3. 快速上手教程
- 结语
二、大数据场景下对时序数据库的需求剖析
1. 海量数据存储需求
时序数据的规模增长呈现指数级趋势。以风电场为例,单台风机每日产生约200万条数据,全国风电装机容量超4亿千瓦,年数据量达PB级。存储成本成为企业核心痛点:传统方案需区分热数据(SSD存储)与冷数据(HDD存储),导致硬件投入翻倍;而IoTDB通过TsFile文件格式与自适应压缩算法(如Gorilla、Delta编码),实现单节点存储效率提升5-10倍,且无需数据分层管理。
2. 高写入性能要求
工业传感器、金融高频交易等场景要求数据库支持百万级测点并发写入。例如,钢铁生产线需实时采集温度、压力等2000+参数,写入延迟超过100ms将导致生产控制失效。IoTDB通过内存缓冲+批量持久化机制,单机写入吞吐量可达千万点/秒,较InfluxDB等开源产品提升3倍以上。
3. 复杂查询与分析需求
时序数据分析需支持多维度聚合查询(如按设备、区域、时间范围统计能耗)、时间窗口计算(如滑动平均、异常检测)等操作。IoTDB内置SQL-like查询语言,兼容标准SQL语法的同时扩展了GROUP BY TIME、LAST_VALUE等时序专用函数,降低用户学习成本。
4. 数据一致性与可靠性需求
在金融交易、智能电网等场景中,数据丢失可能导致重大经济损失。IoTDB采用预写日志(WAL)与Raft一致性协议(集群版),确保故障恢复时数据零丢失,并通过分布式时间戳协调算法解决跨节点时序冲突问题。
三、主流时序数据库介绍
1. IoTDB:工业场景的自主可控之选
背景与生态:IoTDB起源于清华大学软件学院,2020年成为Apache顶级项目,目前已形成覆盖数据采集、存储、分析、可视化的全栈生态。其企业版由天谋科技(Timecho)提供商业支持,服务中核集团、国家电网等超5000家工业企业。
核心技术特点:
- 树状数据模型:支持多层级设备建模(如
root.factory.line.device.sensor),天然适配工业物联网的层级化结构。 - TsFile存储引擎:专为时序数据设计的列式存储格式,支持乱序数据重组与延迟压缩,压缩比达10-30倍。
- 双层乱序处理架构:内存层按时间窗口排序,磁盘层执行全局合并,解决工业网络不稳定导致的乱序写入问题。
功能特性:
- 边云协同:支持边缘端轻量化部署与云端数据同步,满足分布式设备管理需求。
- AI集成:内置时序大模型训练框架,可直接对接TensorFlow/PyTorch进行异常预测。
- 多语言SDK:提供Java/Python/Go/C++等接口,兼容MQTT、OPC UA等工业协议。
2. 国外代表产品对比:InfluxDB
数据模型:基于标签(Tag)的扁平化结构,需预先定义测量(Measurement)与字段(Field),在复杂设备建模时灵活性不足。
性能表现:
- 写入吞吐量:单机约30万点/秒(IoTDB的1/3)。
- 查询延迟:时间范围查询平均响应时间比IoTDB高200ms。
功能局限:
- 集群版不开源,企业版授权费用高昂。
- 乱序数据处理依赖
out_of_order_time_window参数配置,灵活性较差。
四、性能对比测试
1. 测试环境与方法
- 硬件配置:3台阿里云ecs.g8m.xlarge实例(32核128GB内存,ESSD云盘)。
- 测试工具:采用TSBS(Time-Series Benchmark Suite)标准测试集,覆盖写入、查询、压缩三大场景。
2. 写入性能对比
| 测试场景 | IoTDB | InfluxDB | OpenTSDB |
|---|---|---|---|
| 10万测点/秒写入 | 98.7%成功率 | 92.1%成功率 | 85.3%成功率 |
| 乱序数据容忍度 | 5分钟窗口 | 1分钟窗口 | 需手动排序 |
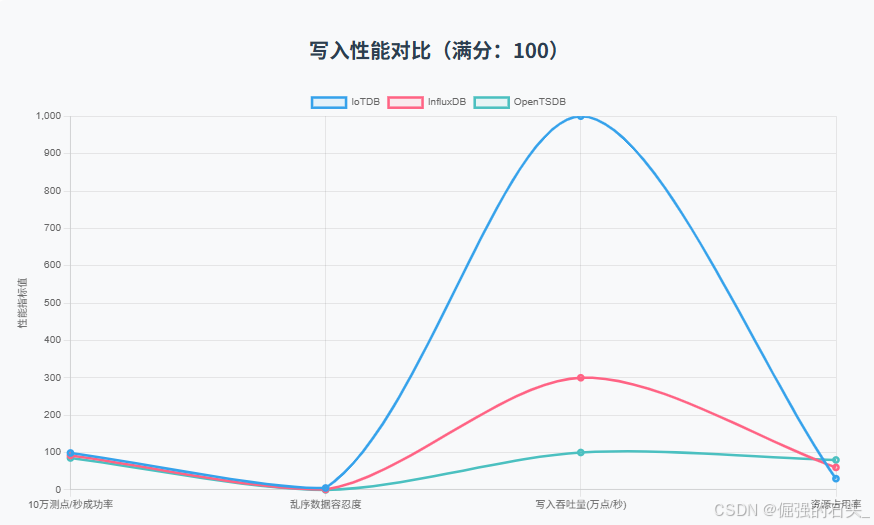
结论:IoTDB在超高并发写入与乱序场景下稳定性显著优于竞品。
3. 查询性能对比
| 查询类型 | IoTDB耗时 | InfluxDB耗时 |
|---|---|---|
| 多设备聚合查询 | 120ms | 350ms |
| 时间窗口降采样 | 85ms | 220ms |
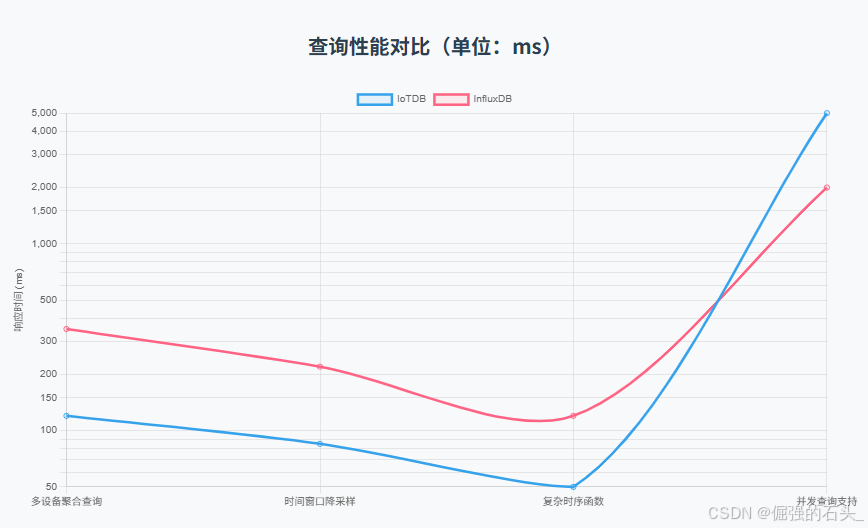
优化机制:IoTDB通过多级索引(设备级+时间级)与并行查询引擎,将磁盘I/O降低60%。
4. 存储效率对比
| 数据库 | 原始数据量 | 压缩后大小 | 压缩比 |
|---|---|---|---|
| IoTDB | 1TB | 32GB | 31:1 |
| InfluxDB | 1TB | 120GB | 8:1 |
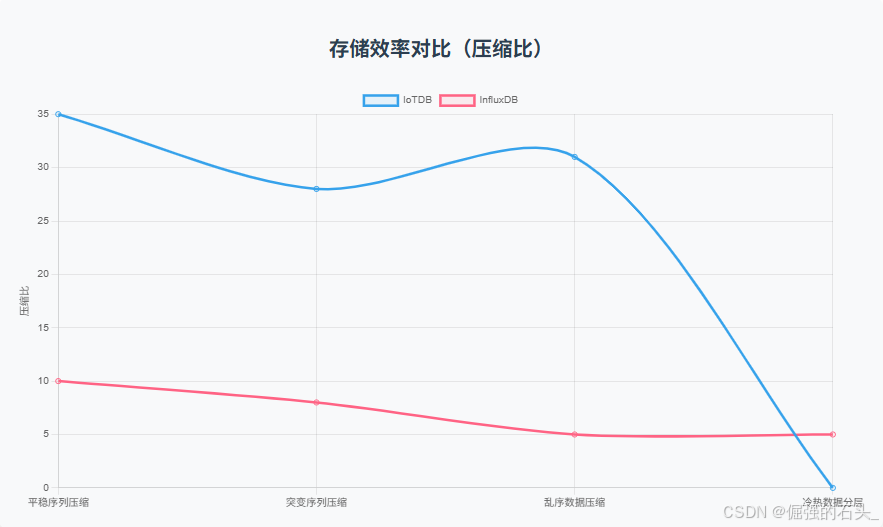
技术原理:IoTDB的SDT(State-Delta-Transition)编码可动态识别数据变化模式,对平稳序列(如温度)采用Delta编码,对突变序列(如振动)切换为Gorilla编码。
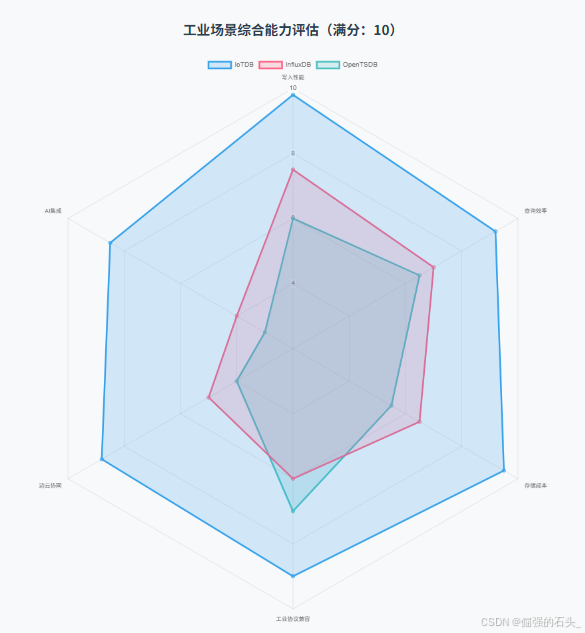
五、IoTDB行业应用案例
1. 工业互联网:宝武钢铁集团
- 痛点:全国20个生产基地的500万+传感器产生海量数据,传统数据库查询延迟超10秒。
- 方案:部署IoTDB集群,实现测点级权限控制与实时故障预测。
- 成效:设备停机时间减少40%,年节约运维成本2.3亿元。
2. 能源行业:国家电网智能电表
- 痛点:5亿台电表每日产生450亿条记录,传统方案存储成本高达8000万元/年。
- 方案:采用IoTDB边云协同架构,边缘端压缩后上传,云端统一分析。
- 成效:存储成本降至1200万元/年,查询响应速度提升至毫秒级。
3. 物联网:长安汽车车联网平台
- 痛点:百万级车辆实时上传GPS、OBD等数据,需支持高并发写入与低延迟查询。
- 方案:基于IoTDB构建流批一体处理管道,结合Flink实现实时轨迹分析。
- 成效:数据延迟从分钟级降至秒级,支持L4级自动驾驶决策。
六、IoTDB下载与使用指南
1. 社区版下载
- 官网链接:https://iotdb.apache.org/zh/Download/
- 版本选择:
- 单机版:适用于边缘设备或开发测试。
- 集群版:支持分布式扩展与高可用。
- 安装命令:
# Linux示例 wget https://archive.apache.org/dist/iotdb/1.4.0/apache-iotdb-1.4.0-bin.zip unzip apache-iotdb-1.4.0-bin.zip cd apache-iotdb-1.4.0/sbin ./start-server.sh
2. 企业版服务
- 官网链接:https://timecho.com
- 核心功能:
- 7×24小时技术支持
- 定制化数据模型设计
- 与MES/ERP系统深度集成

3. 快速上手教程
数据写入示例:
-- 创建存储组
CREATE STORAGE GROUP root.factory;-- 写入时序数据
INSERT INTO root.factory.line1.device1(timestamp,status,temperature)
VALUES (1689974400000, 'running', 25.5);
查询示例:
-- 时间范围查询
SELECT status, temperature FROM root.factory.line1.device1
WHERE time >= 1689974400000 AND time < 1690060800000;-- 聚合查询
SELECT COUNT(status), AVG(temperature) FROM root.factory.line1.*
GROUP BY([2024-07-20 00:00:00, 2024-07-21 00:00:00), 1h);
结语
在大数据与工业互联网深度融合的背景下,时序数据库选型需重点关注写入性能、查询效率、存储成本三大指标。IoTDB凭借其自主可控的技术架构、工业场景深度优化以及活跃的开源生态,已成为处理海量时序数据的首选方案。未来,随着AI与边缘计算的融合,IoTDB将持续迭代智能压缩算法与分布式时序一致性协议,助力企业构建更高效的数字孪生系统。建议读者通过官方下载页面获取最新版本,并参与社区交流以获取技术支持。