ONNX模型的动态和静态量化
引言
通常我们将模型转换为onnx格式之后,模型的体积可能比较大,这样在某些场景下就无法适用。最近想在移动端部署语音识别、合成模型,但是目前的效果较好的模型动辄几个G,于是便想着将模型压缩一下。本文探索了两种压缩方法,适用的场景也不相同。
对比
我觉得额两者之间最大的区别有两点,支持的模型类型、是否需要校准数据。
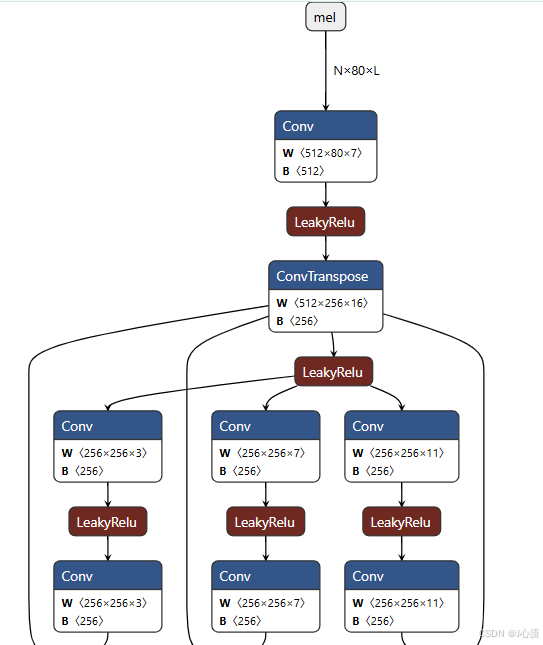
结合我的实践谈一下这两点,①在做语音合成模型量化的时候,模型中大量的卷积操作,使用netron打开后的结果如下图所示。因为一开始直接就用动态量化,但是搞了一圈发现各种报错。原因就是动态量化对卷积操作的支持力度不够,导致各种问题频出。于是兜兜转转又开始用静态量化的方法,最后才成功实现量化。 ②但是我当时量化的时候使用的校准数据是函数生成的,不是真是的输入数据,导致虽然模型量化成功了,但是效果却大打折扣。
下面给出两种方法的对比:
| 特性 | 动态量化 | 静态量化 |
|---|---|---|
| 量化时机 | 推理时动态量化(运行时对权重/激活量化) | 推理前离线量化(事先量化权重/激活) |
| 是否需要校准数据 | 不需要 | 需要标定数据进行校准 |
| 支持的模型类型 | RNN、Transformer 等支持良好 | CNN、稳定数据分布模型 |
| 部署复杂度 | 简单,一键量化 | 复杂,需要数据流过模型进行校准 |
| 加速效果 | 中等(通常1.2–2x) | 最优(通常2–4x) |
| 加速效果 | 小(但一般略大于静态) | 最小(通过校准降低损失) |
动态量化
直接贴代码进行分析
import onnx
from onnxruntime.quantization import QuantFormat, QuantType, quantize_dynamicname = 'model-steps-3'
# 加载原始 ONNX 模型
model_path = f"matcha-icefall-zh-baker/{name}.onnx"
quantized_model_path = f"matcha-icefall-zh-baker/{name}_quant.onnx"# 动态量化模型
quantize_dynamic(model_input=model_path, # 输入的原始模型路径model_output=quantized_model_path, # 输出的量化模型路径weight_type=QuantType.QInt8, # 权重量化类型,使用 INT8nodes_to_exclude=['/encoder/prenet/conv_layers.0/Conv', '/encoder/prenet/conv_layers.1/Conv_quant', 'Transpose'] op_types_to_quantize= ["MatMul", "Mul", "Add", "Constant", "Shape", "Unsqueeze", "Reshape", "Relu", "Sigmoid", "Softmax", "Tanh", "InstanceNormalization", "Softplus", "Slice", "Where", "RandomNormalLike", "Pad"
] # ['MatMul', 'Attention', 'LSTM', 'Gather', 'EmbedLayerNormalization', 'Conv']
)
# 如果不想量化某个算子,可以直接通过nodes_to_exclude忽略掉
# 也可以通过op_types_to_quantize选择要对哪些算子进行量化print(f"Quantized model saved to {quantized_model_path}")
静态量化
这个代码贴的比较长,其实主要就是针对量化前后的模型进行了分析。
import onnx
import numpy as np
import onnxruntime as ort
from onnxruntime.quantization import quantize_static, CalibrationDataReader, QuantType, QuantFormat
import os
import timeclass MelCalibrationDataReader(CalibrationDataReader):"""用于校准的数据读取器,提供MEL频谱图数据"""def __init__(self, batch_size=8, num_batches=10, input_shape=(80, 100)):"""初始化校准数据读取器Args:batch_size: 每批数据的大小num_batches: 批次数量input_shape: MEL频谱图的形状 (特征维度, 时间步长)"""self.batch_size = batch_sizeself.num_batches = num_batchesself.input_shape = input_shapeself.data_counter = 0# 创建随机数据,在实际应用中应替换为真实数据集self.data = []for _ in range(num_batches):# 随机生成FLOAT32类型的MEL频谱图数据mel_data = np.random.randn(batch_size, *input_shape).astype(np.float32) * 1.5self.data.append(mel_data)def get_next(self):"""返回下一批校准数据"""if self.data_counter >= self.num_batches:return Nonemel_batch = self.data[self.data_counter]input_feed = {'mel': mel_batch} # 'mel'是输入节点的名称,需要与模型匹配self.data_counter += 1return input_feeddef rewind(self):"""重置数据计数器"""self.data_counter = 0def load_real_calibration_data(data_path, batch_size=8, num_batches=10):"""加载真实的校准数据(如果有)Args:data_path: 数据目录路径batch_size: 每批数据的大小num_batches: 批次数量Returns:CalibrationDataReader实例"""# 这里实现从文件加载真实MEL数据的逻辑# 如果有特定格式的数据,应该在这里进行加载和预处理# 为简化示例,这里仍使用随机数据return MelCalibrationDataReader(batch_size, num_batches)def quantize_onnx_model(model_path, quantized_model_path, calibration_data_reader=None):"""对ONNX模型进行静态量化Args:model_path: 原始ONNX模型路径quantized_model_path: 量化后模型保存路径calibration_data_reader: 校准数据读取器"""# 加载原始模型model = onnx.load(model_path)# 输出原始模型信息print(f"原始模型输入: {[i.name for i in model.graph.input]}")print(f"原始模型输出: {[o.name for o in model.graph.output]}")# 设置量化参数# QuantType.QInt8 - 8位整数量化# QuantType.QUInt8 - 无符号8位整数量化quant_type = QuantType.QInt8# 量化格式选择# QuantFormat.QDQ - 使用QuantizeLinear/DequantizeLinear节点对# QuantFormat.QOperator - 使用量化算子quant_format = QuantFormat.QDQ# 指定需要量化的算子类型op_types_to_quantize = ['Conv' , 'ConvTranspose'] # # 指定不需要量化的节点名称(如果有的话)# nodes_to_exclude = ['某些不需要量化的节点名称']# 执行静态量化print(f"开始对模型 {model_path} 进行静态量化...")start_time = time.time()quantize_static(model_input=model_path,model_output=quantized_model_path,calibration_data_reader=calibration_data_reader,quant_format=quant_format,# op_types_to_quantize=op_types_to_quantize,per_channel=True, # 使用每通道量化可以提高精度weight_type=quant_type,activation_type=quant_type,# optimize_model=True # 在量化前优化模型)quantization_time = time.time() - start_timeprint(f"量化完成,耗时: {quantization_time:.2f} 秒")return quantized_model_pathdef compare_models(original_model_path, quantized_model_path):"""比较原始模型与量化模型的大小和性能Args:original_model_path: 原始模型路径quantized_model_path: 量化模型路径"""# 比较文件大小original_size = os.path.getsize(original_model_path) / (1024 * 1024) # MBquantized_size = os.path.getsize(quantized_model_path) / (1024 * 1024) # MBprint(f"原始模型大小: {original_size:.2f} MB")print(f"量化模型大小: {quantized_size:.2f} MB")print(f"压缩比: {original_size / quantized_size:.2f}x")# 创建测试数据test_input = np.random.randn(1, 80, 100).astype(np.float32)# 测试原始模型推理性能session_options = ort.SessionOptions()session_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL# 原始模型推理print("测试原始模型推理性能...")original_session = ort.InferenceSession(original_model_path, session_options)input_name = original_session.get_inputs()[0].namestart_time = time.time()num_runs = 100for _ in range(num_runs):original_output = original_session.run(None, {input_name: test_input})original_time = (time.time() - start_time) / num_runs# 量化模型推理print("测试量化模型推理性能...")quantized_session = ort.InferenceSession(quantized_model_path, session_options)input_name = quantized_session.get_inputs()[0].namestart_time = time.time()for _ in range(num_runs):quantized_output = quantized_session.run(None, {input_name: test_input})quantized_time = (time.time() - start_time) / num_runsprint(f"原始模型平均推理时间: {original_time*1000:.2f} ms")print(f"量化模型平均推理时间: {quantized_time*1000:.2f} ms")print(f"速度提升: {original_time/quantized_time:.2f}x")def evaluate_model_accuracy(original_model_path, quantized_model_path, test_data=None):"""评估量化模型的精度损失Args:original_model_path: 原始模型路径 quantized_model_path: 量化模型路径test_data: 测试数据,如果为None则生成随机数据"""# 创建测试数据if test_data is None:num_samples = 10test_data = np.random.randn(num_samples, 80, 100).astype(np.float32)# 创建会话original_session = ort.InferenceSession(original_model_path)quantized_session = ort.InferenceSession(quantized_model_path)# 获取输入输出名称input_name = original_session.get_inputs()[0].name# 计算均方误差和平均相对误差total_mse = 0total_rel_err = 0for i, sample in enumerate(test_data):# 添加批次维度sample = np.expand_dims(sample, axis=0)# 运行推理original_output = original_session.run(None, {input_name: sample})[0]quantized_output = quantized_session.run(None, {input_name: sample})[0]# 计算均方误差mse = np.mean((original_output - quantized_output) ** 2)total_mse += mse# 计算相对误差# 避免除以零epsilon = 1e-10rel_err = np.mean(np.abs((original_output - quantized_output) / (np.abs(original_output) + epsilon)))total_rel_err += rel_errif i < 3: # 只打印前几个样本的结果print(f"样本 {i+1} - MSE: {mse:.6f}, 相对误差: {rel_err:.6f}")avg_mse = total_mse / len(test_data)avg_rel_err = total_rel_err / len(test_data)print(f"平均均方误差 (MSE): {avg_mse:.6f}")print(f"平均相对误差: {avg_rel_err:.6f}")return avg_mse, avg_rel_errdef main():# 模型路径original_model_path = "./my_model.onnx" # 替换为实际模型路径quantized_model_path = "./my_model_quant.onnx" # 量化后模型的保存路径# 创建校准数据读取器# 在实际应用中,应使用真实数据替代随机数据calibration_data_reader = MelCalibrationDataReader(batch_size=8,num_batches=10,input_shape=(80, 100) # 根据实际输入形状调整)# 执行静态量化quantized_model_path = quantize_onnx_model(original_model_path,quantized_model_path,calibration_data_reader)# 比较模型大小和性能compare_models(original_model_path, quantized_model_path)# 评估量化精度evaluate_model_accuracy(original_model_path, quantized_model_path)print("ONNX模型静态量化完成!")if __name__ == "__main__":main()
总结
在对onnx进行量化时,我们要根据自己的模型的结构类型和是否能得到真实的校准数据来选择量化方法。