大数据-272 Spark MLib - 基础介绍 机器学习算法 线性回归
点一下关注吧!!!非常感谢!!持续更新!!!
Java篇开始了!
- MyBatis 更新完毕
- 目前开始更新 Spring,一起深入浅出!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 数据挖掘(已更完)
- Prometheus(已更完)
- Grafana(已更完)
- 离线数仓(已更完)
- 实时数仓(正在更新…)
- Spark MLib (正在更新…)
SparkMLib
基本介绍
逻辑回归(Logistic Regression)是机器学习中的一种分类模型,逻辑回归是一种分类算法,虽然名字汇总带有回归。由于算法的简单和高效,在实际中非常广泛。
应用场景
● 广告点击率
● 是否为垃圾邮件
● 是否患病
● 金融诈骗
● 虚假账号
看到上面的例子,可以发现其中的特点,那就是都属于两个类别之间的判断,逻辑回归就是解决二分类问题的利器。
逻辑回归原理
要想掌握逻辑回归,必须掌握两点:
● 逻辑回归中,其输入值是什么
● 如何判断逻辑回归的输出
输入函数
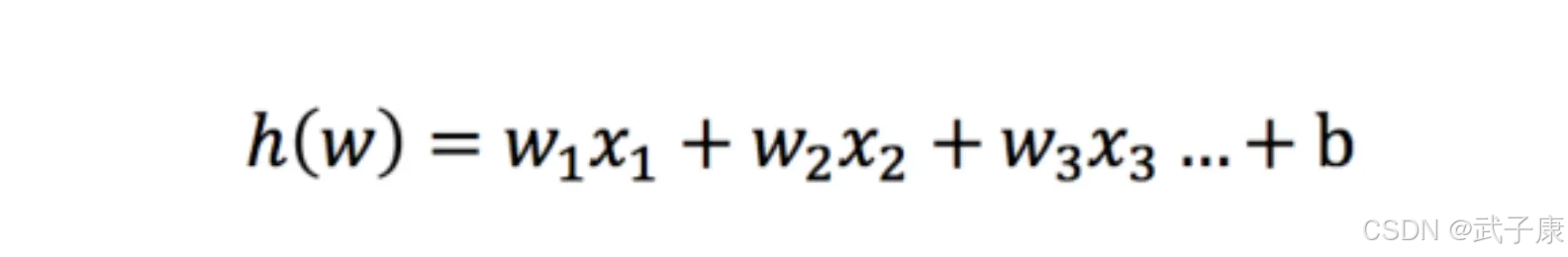
逻辑回归的输入就是一个线性回归的结果
激活函数
sigmoid 函数:
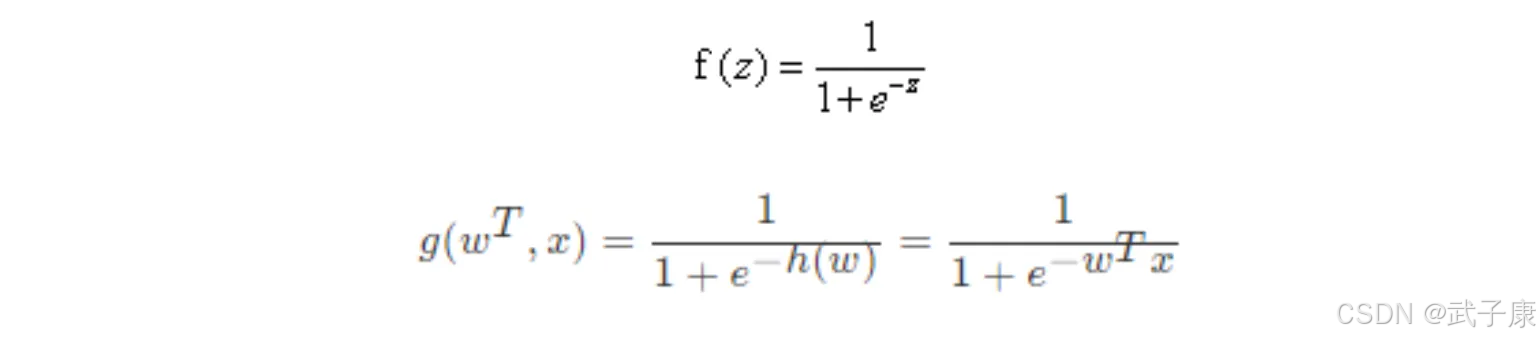
判断标准:
● 回归的结果输入到sigmod函数当中
● 输出结果:[0, 1]区间中有一个概率值,默认为0.5的阈值
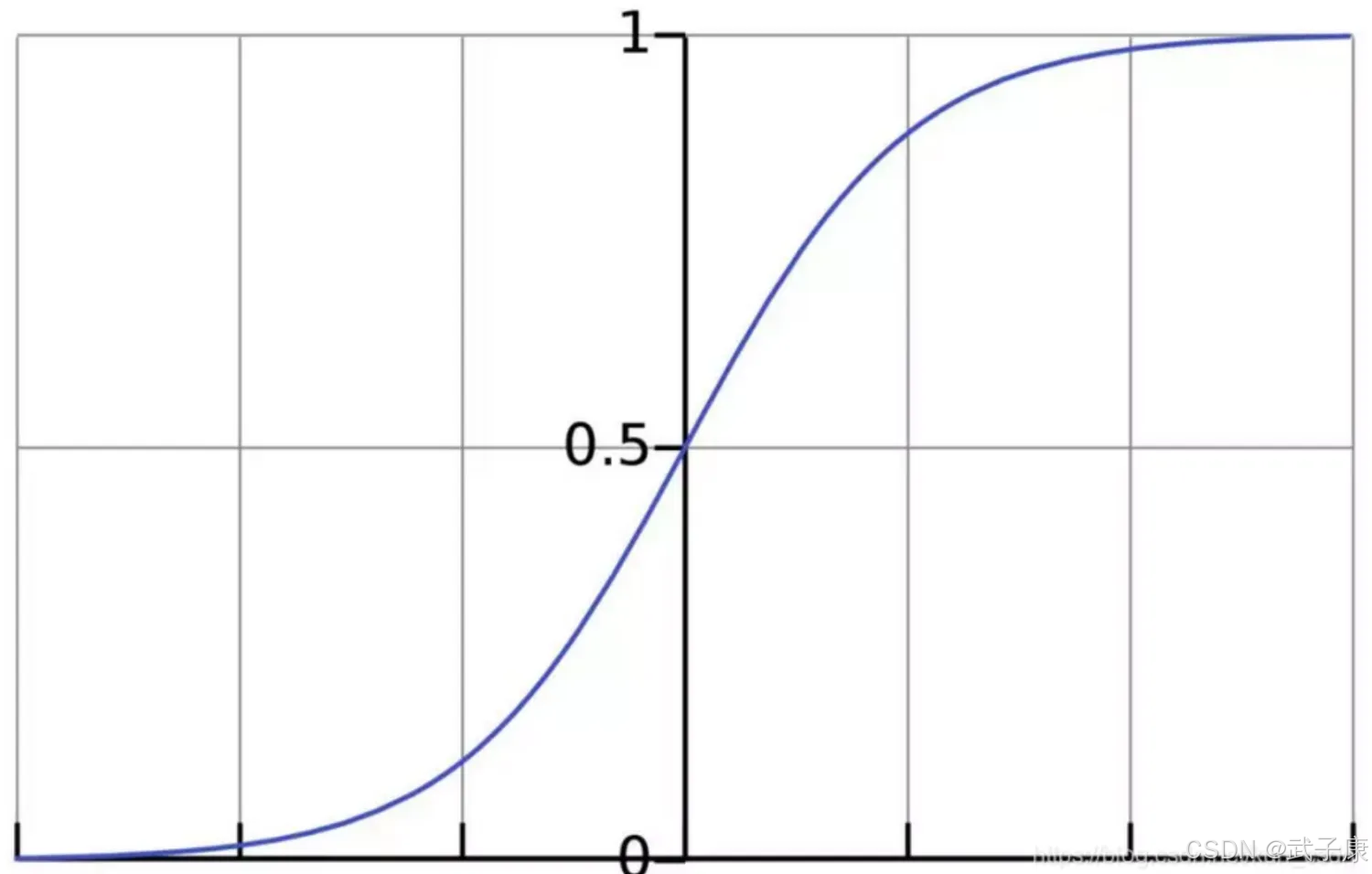
逻辑回归最终的分类是通过属于某个类别的概率值来判断是否属于某个类别,并且这个类别默认标记为1,另外的一个类别会标记为0。
输出结果的解释:假设有两个类别A、B,并且假设我们的概率值为属于A(1)这个类别的概率值,现在有一个样本输入到逻辑回归输出结果0.55,那么这个概率超过0,5,意味着我们训练或者预测的结果就是A(1)类别,那么反之,如果得出结果为0.3,那么训练或者预测的结果就是B(0)类别。
关于逻辑回归的阈值是可以进行改变的,比如上面举例中,如果你把阈值设置为0.6,那么输出结果0.55的话,就属于B类。
那么在逻辑回归中,当预测结果不对的时候,该怎么衡量其损失呢?
我们来看下图(下图中,设置阈值为0.6)

那么我们如何去衡量逻辑回归的预测结果与真实结果的差异呢?
损失以及优化
逻辑回归的损失,称之为对数似然损失,公式如下:
分开类别:
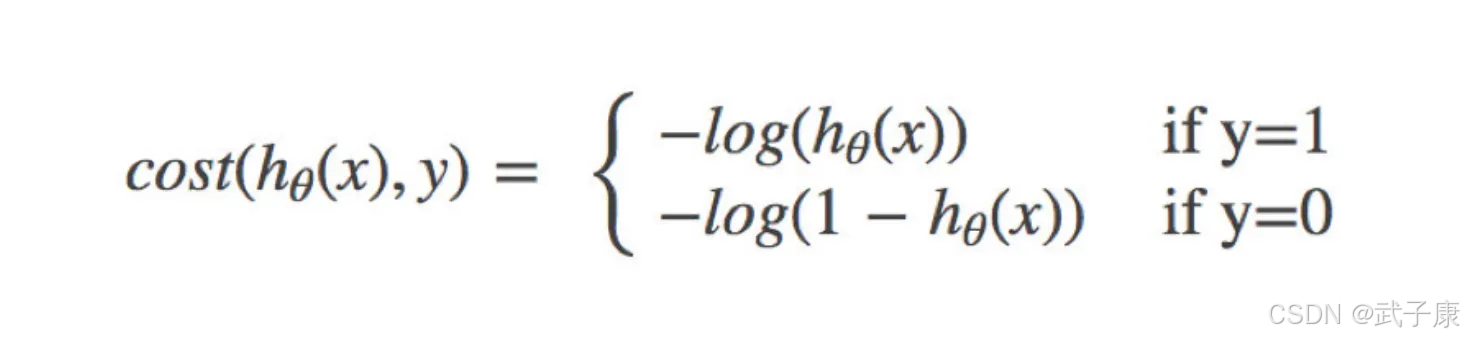
其中Y为真实值,hθ(x)为预测值
怎么理解单个的式子呢?这个要根据Log的函数图像来理解
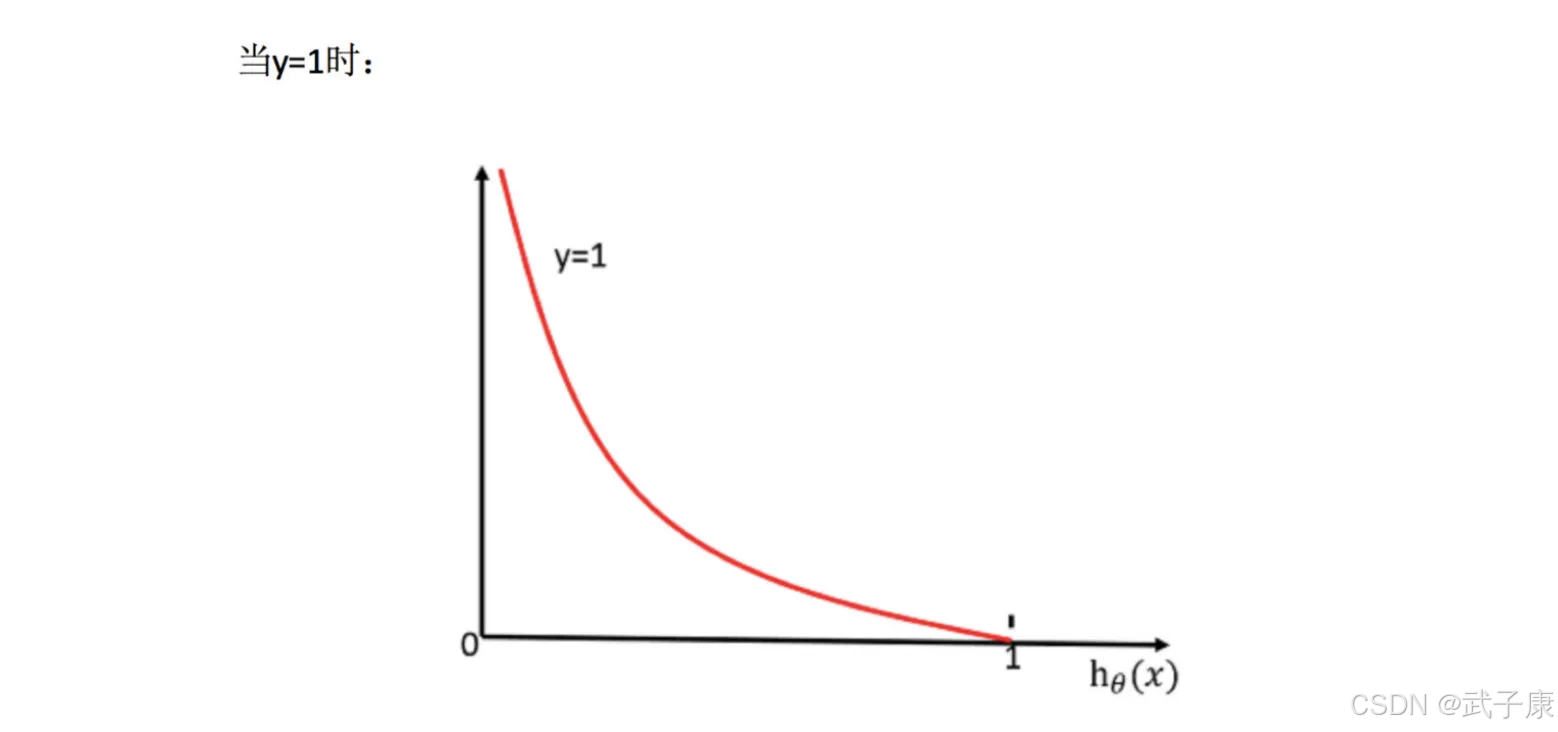
无论何时,我们都希望损失函数值,越小越好。
分情况讨论,对应的损失函数值:
● 当y=1时,hθ(x)值越大越好
● 当y=0时,我们希望hθ(x)值越小越好
● 综合完整损失函数
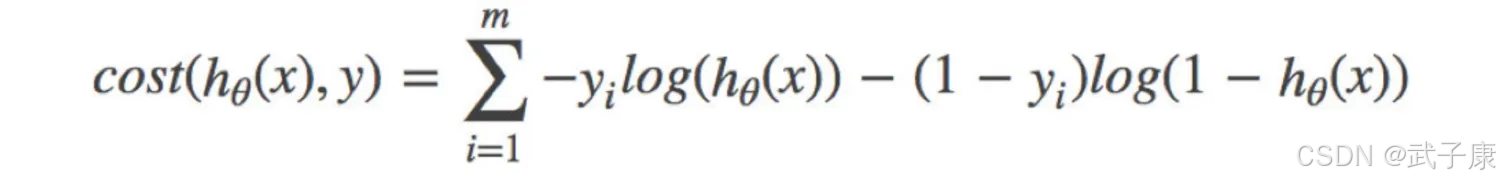
接下来我们呢带入上面那个例子来计算一遍,就能理解意义了。

优化逻辑
同样使用梯度下降优化算法,去减少损失函数的值,这样去更新逻辑回归前面对应的算法的权重参数,提升原本属于1类别的概率,降低原本是0类别的概率。
案例测试
数据准备
wget https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv -O pima.csv
编写代码
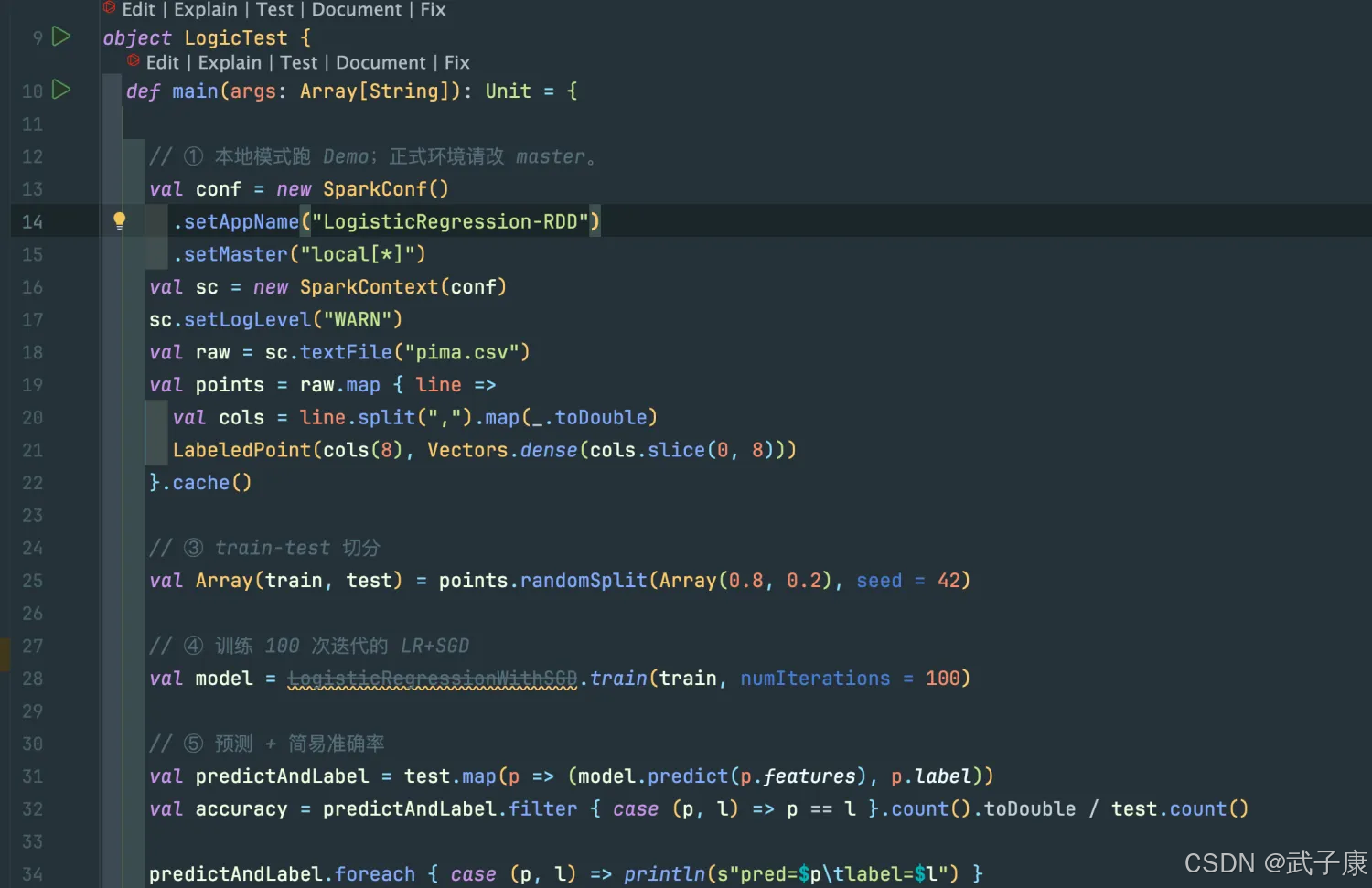
package icu.wzk.logicimport org.apache.spark.mllib.classification.LogisticRegressionWithSGD
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.{SparkConf, SparkContext}object LogicTest {def main(args: Array[String]): Unit = {// ① 本地模式跑 Demo;正式环境请改 master。val conf = new SparkConf().setAppName("LogisticRegression-RDD").setMaster("local[*]")val sc = new SparkContext(conf)sc.setLogLevel("WARN")val raw = sc.textFile("pima.csv")val points = raw.map { line =>val cols = line.split(",").map(_.toDouble)LabeledPoint(cols(8), Vectors.dense(cols.slice(0, 8)))}.cache()// ③ train-test 切分val Array(train, test) = points.randomSplit(Array(0.8, 0.2), seed = 42)// ④ 训练 100 次迭代的 LR+SGDval model = LogisticRegressionWithSGD.train(train, numIterations = 100)// ⑤ 预测 + 简易准确率val predictAndLabel = test.map(p => (model.predict(p.features), p.label))val accuracy = predictAndLabel.filter { case (p, l) => p == l }.count().toDouble / test.count()predictAndLabel.foreach { case (p, l) => println(s"pred=$p\tlabel=$l") }println(f"accuracy = $accuracy%.4f")sc.stop()}
}
● 从本地文件 pima.csv 中读取每一行数据。
● 每一行用逗号分隔,转换为数组 cols。
● 假设每行有 9 个数值:前 8 个是特征,第 9 个(即 cols(8))是标签(label)。
● 构造 LabeledPoint 对象,这是 Spark MLlib 中表示训练样本的格式(包含特征和标签)。
● .cache() 把数据缓存在内存中,加快后续的训练速度。
● 将整个数据集按照 80%(训练)+ 20%(测试)随机划分。
● 使用固定的随机种子 42,确保每次运行结果一致。
● 使用 LogisticRegressionWithSGD(基于随机梯度下降的逻辑回归)对训练集数据进行训练。
● 设置迭代次数为 100,模型会训练 100 个迭代步来逼近最优解。
● 对测试集中每一个样本进行预测,返回一个 (预测值, 实际标签) 的元组。
● 使用简单的等值比较来判断预测是否正确。
● 计算正确预测数量占总测试样本数量的比例,得出预测准确率。
● 将每一个预测结果和对应标签输出到终端,便于人工对比观察。
● 打印最终的准确率,保留4位小数。
对应的截图如下所示: