Gemma 3n:更智能、更快速、随时离线的AI新纪元
昨日,Google宣布推出其最新一代生成式AI模型——Gemma 3n。Gemma 3n体积小巧、速度极快,并专为手机等设备离线运行设计,将先进的AI能力带入你的日常设备。它不仅能理解音频、图片和文本,还具备极高的准确率,在Chatbot Arena测试中表现优于GPT-4.1 Nano。

本文将带你了解Gemma 3n背后的全新架构,深入解析其创新特性,并为你提供入门指南,助你轻松体验这一突破性模型。
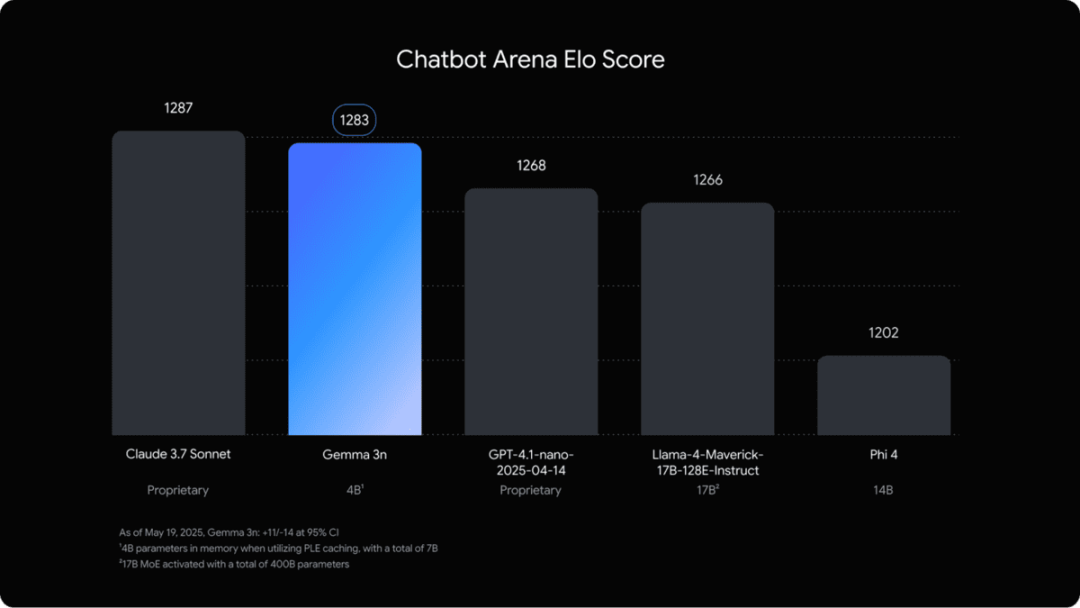
Gemma 3n全新架构
为了实现下一代设备端AI,Google DeepMind与Qualcomm Technologies、MediaTek和Samsung System LSI等领先的移动硬件创新者紧密合作,共同开发了全新架构。
该架构专为优化资源受限设备(如手机、平板和笔记本)上的生成式AI性能而设计,主要通过三大创新实现:逐层嵌入(PLE)缓存、MatFormer架构以及条件参数加载。
逐层嵌入(PLE)缓存
PLE缓存允许模型将逐层嵌入参数转存至高速外部存储,从而降低内存占用却不影响性能。这些参数在模型运行内存之外生成,并在执行过程中按需调用,即使在资源有限的设备上也能高效运行。
MatFormer架构
Matryoshka Transformer(MatFormer)采用嵌套式Transformer设计,将较小的子模型嵌入到更大的模型中,类似于俄罗斯套娃。该结构可选择性激活子模型,使模型能够根据任务动态调整规模和计算需求。这种灵活性降低了计算成本、响应时间和能耗,非常适合边缘端和云端部署。
条件参数加载
条件参数加载允许开发者跳过加载未使用的参数(如音频或视觉处理相关参数)进入内存。只有在需要时,这些参数才会在运行时动态加载,进一步优化内存使用,使模型能适配多种设备与任务。
Gemma 3n主要特性
Gemma 3n带来了多项创新技术和功能,重新定义了设备端AI的可能性:
-
优化的设备端性能与效率:Gemma 3n比前代(Gemma 3 4B)约快1.5倍,同时输出质量显著提升。
-
PLE缓存:通过PLE缓存系统,将参数存储在高速本地存储中。
-
MatFormer架构:根据具体请求,Gemma 3n可选择性激活模型参数。
-
条件参数加载:为节省内存资源,可在不需要时跳过加载视觉或音频等参数。
-
隐私优先 & 离线运行:AI功能可在本地运行,无需联网,确保用户隐私。
-
多模态理解:支持音频、文本、图片和视频输入,实现复杂、实时的多模态交互。
-
音频能力:提供自动语音识别(ASR)与语音转文本翻译,转录质量高且支持多语言。
-
多语言能力提升:在日语、德语、韩语、西班牙语和法语等语言上的表现大幅提升。
-
32K Token上下文:单次请求可处理大量数据。
如何快速上手
Gemma 3n为开发者提供了两种主要的轻松上手方式,助你高效集成和体验这一强大模型。
1. Google AI Studio
登录Google AI Studio,进入工作室,选择Gemma 3n E4B模型,即可开始探索其多项功能。该平台适合开发者快速原型设计和测试创意,便于后续规模化实现。
你可以获取API密钥,并通过Msty应用将模型集成到本地AI聊天机器人中。
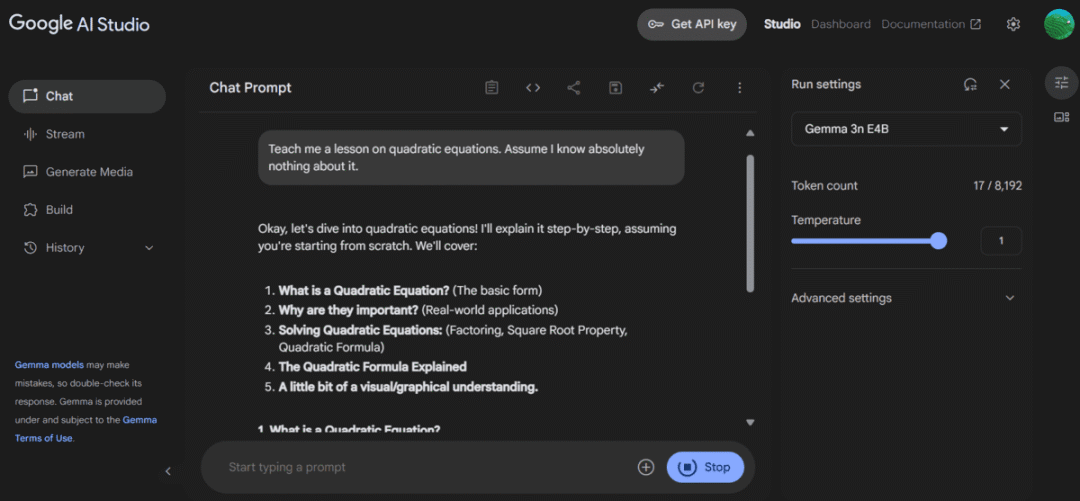
此外,还可通过Google GenAI Python SDK,仅需几行代码即可将模型集成到你的应用中。
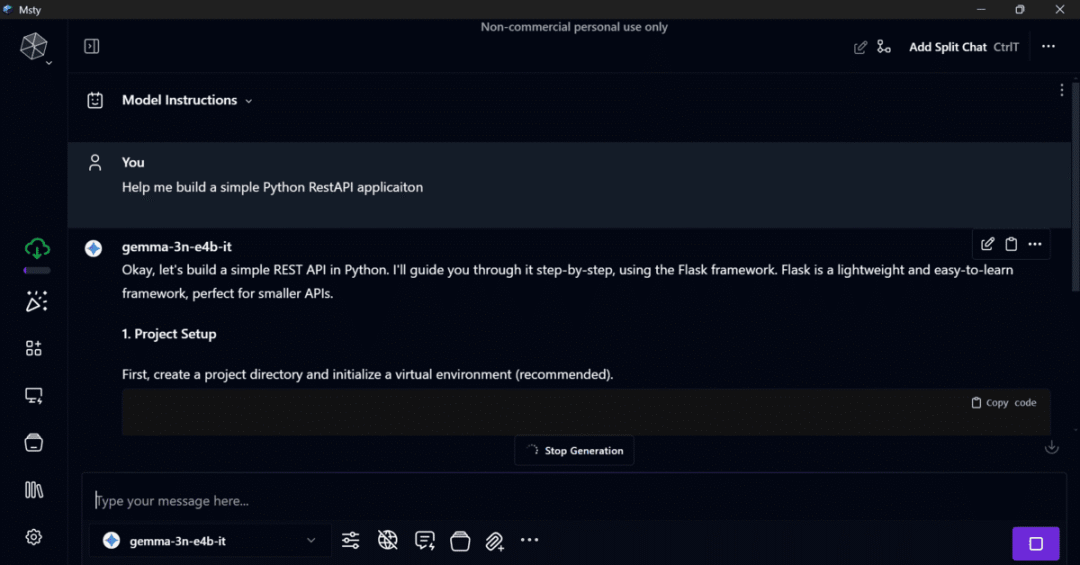
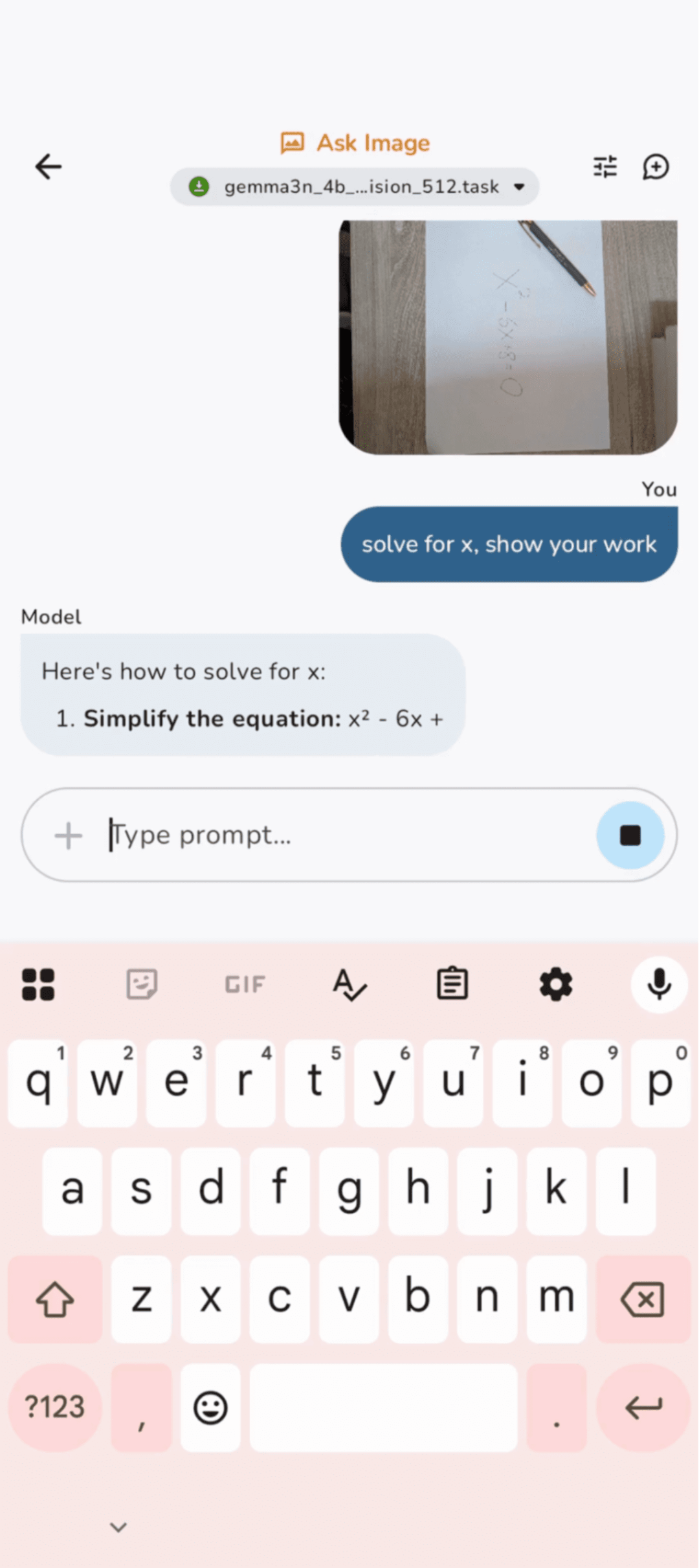
2. 使用Google AI Edge进行设备端开发
如需将Gemma 3n直接集成到你的应用中,Google AI Edge提供所需的开发工具和库,适合在Android和Chrome设备上本地构建应用,充分发挥Gemma 3n的设备端能力。
结语
许多专家和业内人士认为,Google正准备在未来几周内将Gemma 3n完全开源,向所有人开放。预计公司还将陆续推出更多增强功能,如更强大的图像和音频理解能力。目前预览版聚焦文本理解,未来这些新功能将进一步扩展模型的应用范围。
Gemma 3n是让大型AI模型走进小型设备的重要一步。通过本地运行,既保障了用户数据隐私,又带来了先进大语言模型的高速、多模态体验。