面向复杂和不平衡数据的双模块深度学习网络入侵检测模型
大家读完觉得有帮助记得及时关注和点赞!!!
抽象
随着计算机网络的激增,网络入侵的严重性不断升级,凸显了网络入侵检测系统对维护安全的重要性。虽然深度学习模型在入侵检测方面取得了可喜的成果,但它们在管理高维、复杂的流量模式和不平衡的数据类别方面也面临着挑战。本文介绍了 CSAGC-IDS,这是一种基于深度学习技术的网络入侵检测模型。CSAGC-IDS 集成了 SC-CGAN,这是一种自我注意力增强的卷积条件生成对抗网络,可生成高质量数据以减轻类不平衡。此外,CSAGC-IDS 还集成了 CSCA-CNN,这是一种通过成本敏感学习和通道注意力机制增强的卷积神经网络,可以从复杂的流量数据中提取特征以进行精确检测。在 NSL-KDD 数据集上进行的实验。CSAGC-IDS 在五类分类任务中达到 84.55% 的准确率和 84.52% 的 F1 分数,在二元分类任务中达到 91.09% 的准确率和 92.04% 的 F1 分数。此外,本文还对所提出的模型进行了可解释性分析,使用 SHAP 和 LIME 来解释模型的决策机制。
关键字:
网络入侵检测 数据不平衡 深度学习1介绍
1.1背景
随着网络技术的广泛采用,网络攻击的后果越来越严重[1]和传统的网络安全技术[2]已不足以满足需求。基于网络的入侵检测系统可以有效监控网络流量并检测异常情况[1].机器学习,尤其是深度学习[3,4]在入侵检测方面表现出卓越的性能,但在处理不平衡数据和高维复杂数据方面面临挑战。虽然深度学习基于网络的入侵检测模型 (NIDM) 可以识别常见攻击,但它们检测罕见攻击的能力不足,从而影响了整体性能[5,6].此外,深度学习 NIDM 在处理高维和复杂数据时仍然遇到困难[7].高维交通数据意味着大量的特征、复杂的数据模式以及特征之间错综复杂的关系,这些因素以及模型复杂性的增加,对深度学习 NIDM 的功能和结构构成了挑战。因此,需要进一步研究来提高 NIDM 在高维、复杂和不平衡数据条件下检测罕见攻击的性能。
1.2研究内容和贡献
针对分析高维、错综复杂和不平衡的入侵流量数据的挑战,该文提出CSAGC-IDS入侵检测模型。
SC-CGAN。
针对数据不平衡的问题,该文提出一种不平衡数据处理算法SC-CGAN。这种方法利用自我注意机制和 CNN 来有效地融合条件信息并捕获复杂的特征依赖关系,最终生成更高质量的新数据。这个平衡的数据集可作为后续流量分类任务的宝贵资源。实验评估已验证 SC-CGAN 优于其他比较方法。
CSCA-CNN。
针对复杂高维流量数据的处理,该文提出一种流量分类算法CSCA-CNN。这种方法将频道注意力与成本敏感型学习相结合,以提取特征,并为少数群体分配更高的成本,以减少不平衡的偏见。实验结果表明,CSCA-CNN 优于其他比较方法。
CSAGC-IDS。
通过将 SC-CGAN 和 CSCA-CNN 集成,构建了 CSAGC-IDS。实验结果表明,该模型优于其他比较方法,证明了在高维、复杂和不平衡流量数据的网络入侵检测任务中的有效性和进步性。
1.3纸张结构
第 2 节专门介绍了该领域的相关工作。第 3 节详细介绍了所提出的入侵检测模型 CSAGC-IDS 及其两个组成部分:SC-CGAN 和 CSCA-CNN。第 4 节演示了评估。它将所提出的算法和模型的性能与现有方法进行了比较,同时还对 CSCA-CNN 进行了消融实验以进一步分析其有效性。第 5 节以总结结束了本文,并提供了对未来改进的潜在方向的见解。
2相关工作
2.1深度学习入侵检测方法
Gupta 等人通过结合成本敏感型深度学习和集成学习提出了 CSE-IDS,并在不平衡数据上取得了良好的性能[6].Li 等人结合了多个 CNN[8]实现更高的准确性和低复杂性[9].Shams 等人提出了 CAFE-CNN,它将交通数据转换为灰度图像并提取上下文感知特征[10].Fu 等人将 CNN 和双向 LSTM 相结合,以提高检测性能[11].Cui 等人将 CNN 和 LSTM 相结合[12]从堆叠自动编码器 (SAE) 中提取特征后形成流量分类,充分考虑数据之间的相关性,表现出良好的性能[7].
2.2不平衡的数据处理方法
合成少数过采样 (SMOTE)[13]可以合成新的少数样本以实现相对类平衡。江 et al. 使用 SMOTE 解决网络入侵检测中的数据不平衡问题[14].马 et al. 将对抗性强化学习与 SMOTE 相结合进行网络入侵检测[15].生成对抗网络 (GAN) 是 Goodfellow 提出的一种生成模型[16].Lee 等人使用 GAN 对少数类别的网络入侵数据进行了过度采样,其性能优于 SMOTE[17].Douzas 等人使用 CGAN[18]处理不平衡的数据,其性能优于其他方法[19].Cui 等人使用了 WGAN[20]结合 GMM 进行网络入侵检测数据均衡,实现性能显著提升[7].
3提出的网络入侵检测模型
3.1CSAGC-IDS 架构
CSAGC-IDS 由 SC-CGAN 和 CSCA-CNN 两个子模块算法组成。前者用于流量数据均衡以减少不平衡,而后者用于对流量进行分类和检测。
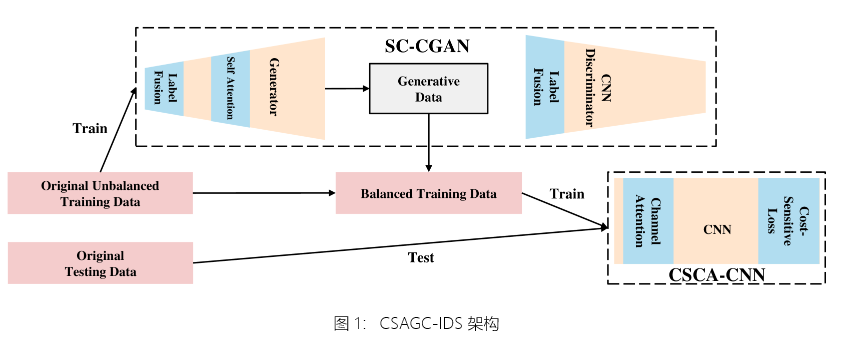
图 1:CSAGC-IDS 架构
整体架构如图 1 所示。SC-CGAN 使用原始训练集生成与原始数据相似的新数据,并与原始训练集形成类平衡数据来训练 CSCA-CNN。训练后,对 CSCA-CNN 进行测试,以获得最终的检测结果。 模型作过程如图 2 所示。
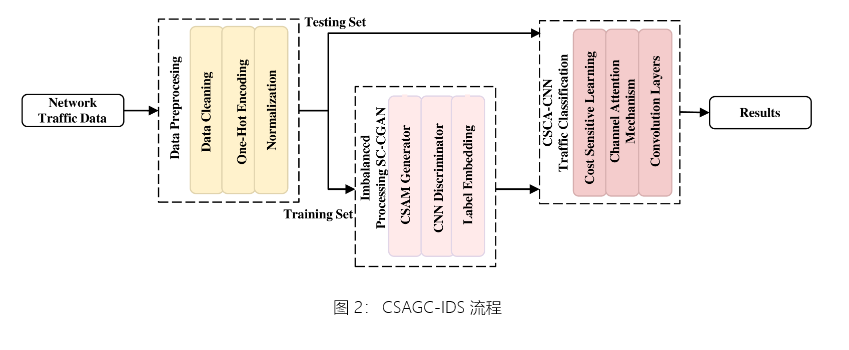
图 2:CSAGC-IDS 流程
数据预处理是一个重要的初始步骤。数值处理将特征转换为模型易于接受的 One Hot Encoding。这只会保留类别差异信息,以避免误导模型,从而使模型能够更好地理解特征。归一化将特征值转换为特定范围,例如 [0,1],从而消除不同特征值范围的影响。规范化可以使参数更新更稳定并更快地收敛。标准化是一种规范化:

它将原始数据转换为均值为 0 且标准差为 1 的分布,同时保留数据的原始特征。
下面将介绍其余步骤。
3.2不平衡数据处理算法 SC-CGAN
SC-CGAN (Self Attention Mechanism Convolution Conditional Generative Adversarial Network) 是一个集成了自注意力机制模块的生成器[21]基于常规的条件 GAN[18],判别器使用 CNN[8]来区分 true 或 false。生成器、判别器和自我注意模块将条件信息集成到它们的输入中,即流量数据分类标签。
SC-CGAN 用于生成高质量的交通数据,目的是平衡训练集、增加少数类的样本并减轻因数据不平衡而产生的模型偏差。评估结果表明,SC-CGAN 在生成高质量网络流量数据方面表现出优于现有方法的显著优势。 SC-CGAN 的结构如图 3 所示。
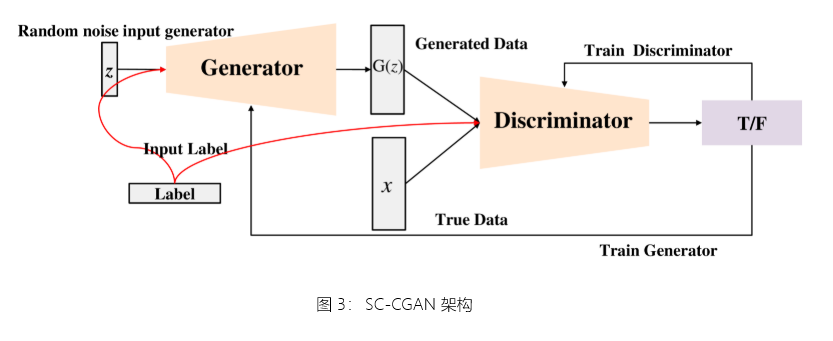
图 3:SC-CGAN 架构
3.2.1具有条件信息融合的生成对抗网络。
虽然 GAN 表现出卓越的生成能力,但在处理多类别训练数据时,它们仅依赖噪声输入是不够的,因为它缺乏控制特定类别生成的能力。为了解决这一限制,条件生成对抗网络 (CGAN)[18]将额外的条件信息引入生成器和判别器。
SC-CGAN 采用这种方法来生成交通数据,其中生成器将条件信息与随机噪声集成在一起,判别器将条件信息与要评估的输入样本相结合。生成器和判别器都将这些条件信息合并到各自的生成和判别任务中。具体来说,SC-CGAN 中的条件信息采用一个热编码类别标签的形式。SC-CGAN 的损失函数定义如下:
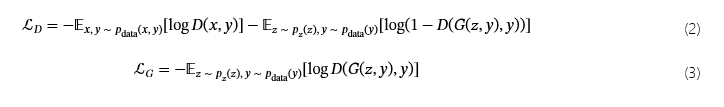
生成器的损失最小化目标是生成判别器认为真实的数据(即输出接近 1),而判别器旨在通过准确区分生成数据(输出 0)和真实数据(输出 1)来最小化其损失。在此过程中,生成器和判别器都包含条件信息 y。
利用类别信息,SC-CGAN 生成器生成指定类的样本。通过从少数类生成额外的样本,它旨在减轻原始数据集中存在的不平衡。
3.2.2条件自我注意机制生成器。
SC-CGAN 生成器与条件自注意力机制 (CSAM) 集成。变压器[21]代表了人工智能领域的一个重要里程碑,而 SAM 是其基石。值得注意的是,SAM 不仅在自然语言处理 (NLP) 领域实施[22],但它在图像生成领域也取得了重大成功[23].
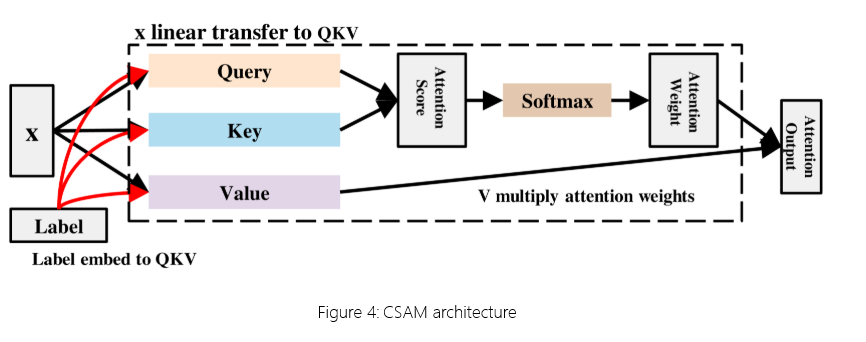
图 4:CSAM 体系结构
将 CSAM 集成到 SC-CGAN 生成器中有利于生成更高质量的流量数据。图 4 展示了 SC-CGAN 生成器中的 CSAM 架构,其中查询 (Q)、键 (K) 和值 (V) 都是通过输入的线性变换获得的。Query 检索并查询流量特征序列中的相关信息。Key 用于与 Query 的相似性匹配,而 Value 与 Key 相关联。将条件信息嵌入到 Query、Key 和 Value 中,并计算 Query 和 Key 的点积来确定流量数据特征之间的相似度。在 Softmax作之后,获得注意力权重 P 并将其应用于 Value 以进行注意力加权缩放,最终产生输出。SAM 的计算过程概述如下:
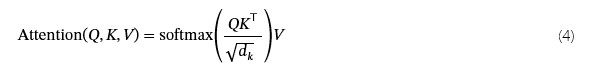
通过为此模块合并残差连接,可以缓解模型中梯度消失的问题[24],如图 5 所示。此外,此残差连接可确保保留流经 CSAM 期间可能丢失的任何原始输入信息。
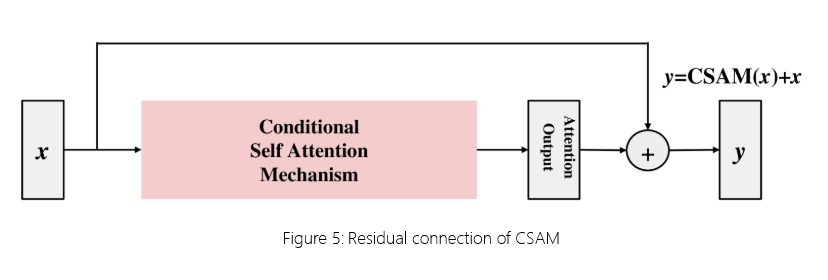
图 5:CSAM 的残差连接
CSAM 以以下重要方式为生成高质量的流量数据做出贡献:
捕获 Long-Range 依赖项。
CSAM 可以有效地捕获流量数据特征之间的依赖关系和关联关系,无论它们在序列中有多远。流量数据存在许多依赖关系,例如协议类型和端口号之间的关联。在生成流量数据时,请考虑依赖关系并生成符合实际的数据。在复杂的网络场景中,CSAM 用于自适应学习依赖模式。
添加条件信息。
CSAM 将条件信息嵌入到 Q、K 和 V 中。这种方法可以更精确地控制特定样品类别的生成。
增强模型学习能力。
Q、K 和 V 是从可学习的参数中获得的。该模型引入了更多参数以增强学习能力。
3.3流量分类算法 CSCA-CNN
CSCA-CNN(成本敏感通道注意力机制卷积神经网络)框架有效地集成了成本敏感学习 (CSL)[6]和通道注意力机制 (CAM)[25]在 CNN 架构中。CSL 解决了对多数阶层的偏见问题,确保对所有阶层的待遇更加平衡。另一方面,CAM 增强了关键信道特征的表示,从而提高了流量分类的整体性能。图 6 说明了 CSCA-CNN 的结构,展示了这两种机制是如何集成的。
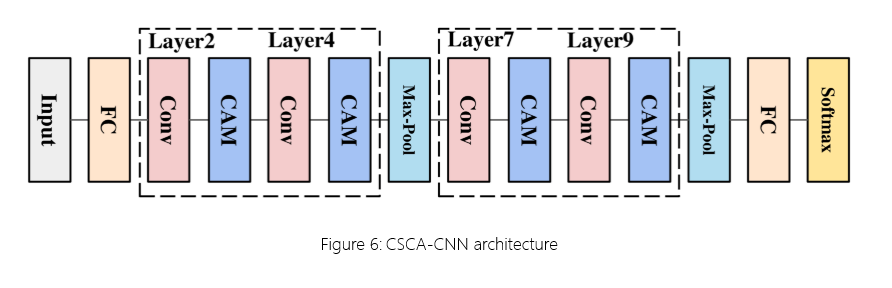
图 6:CSCA-CNN 架构
3.3.1成本敏感型学习。
在普通分类任务中,通常假设所有错误分类都会产生相同的成本,但在实际应用中,对不同类别的实例进行错误分类可能会导致截然不同的损失。为了解决这个问题,成本敏感学习 (CSL)[6],它为各种类型的错误分配不同的权重,并在训练过程中优先考虑最小化权重较高的错误。
CSCA-CNN 利用 CSL 来修改交叉熵损失函数。具体来说,实现了一个成本权重矩阵,为对应于不同类别的损失函数分配差分权重。这种方法对少数类中的实例进行错误分类会施加更重的惩罚,从而在参数更新期间增加模型对这些类的关注。成本敏感的交叉熵损失函数公式如下:

3.3.2Channel Attention 机制。
CSCA-CNN 采用从 CBAM(卷积块注意力模块)中提取通道注意力机制 (CAM) 特征[25]流量分类框架。这种方法旨在增强有效和关键信道特征的表示,同时最大限度地减少对冗余和不相关信道特征的关注,最终提高整体分类性能。 CAM 的具体过程如图 7 所示。
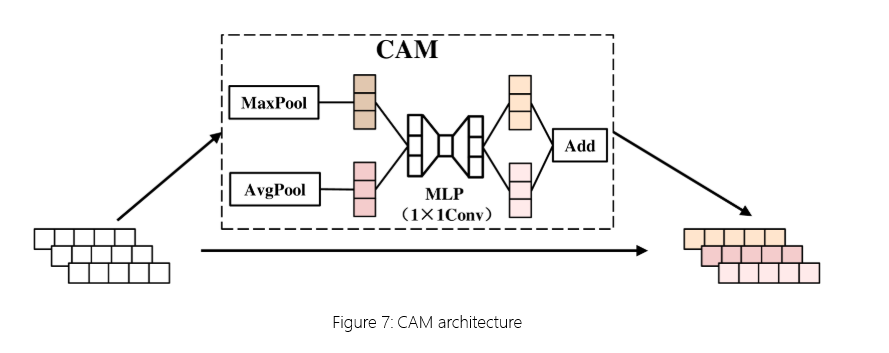
图 7:CAM 架构
4评估
本节进行了广泛的实验,以评估所提出的算法和模型的数据生成质量、分类性能和模型复杂性。获得的结果验证了我们提出的解决方案的优势。
4.1实验性配置环境
实验是在 Intel (R) Xeon (R) Gold 6240 CPU @ 2.60GHz 的计算环境中进行的。使用的 GPU 是 Tesla V100S-PCIE-32GB,作系统是 Ubuntu 18.04.3 LTS。所有代码均在 Python 3.7.6 中实现。框架采用 PyTorch 1.13.1+cu117。
4.2评估指标
实验利用多个分类性能指标来提供全面评估,包括准确率 (Acc)、精确率 (Pre)、召回率和 F1 分数。鉴于数据中存在显著的不平衡,仅依靠 Accuracy 作为指标是不够的。因此,我还包括了 precision、recall 和 F1-score 以获得更全面的评估。值得注意的是,F1 分数特别有价值,因为它同时考虑了精度和召回率,使其成为一个可靠且强大的指标[7].
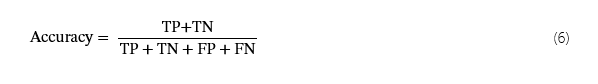
在多类分类方案中,考虑所有类的全局性能至关重要。为此,请分别计算各种类别的 Pre、Recall 和 F1-score,并使用每种类型的数量的比率作为加权平均值。F1 分数计算如下:

衡量复杂性的指标是 Params 和 FLOPs。
4.3数据
实验使用 NSL-KDD[26]Benchmark 数据集,这是网络入侵检测领域广泛认可的资源。该数据集提供了全面、真实的网络入侵流量数据,表现出数据分布的自然不平衡以及高维复杂特征。这些使 NSL-KDD 成为评估入侵检测模型的有效性和稳健性的绝佳候选者。以下所有评估均在 KDDTest+ 上进行。
表 1:NSL-KDD 说明
| 类 | 描述 | 数量 | CI 比率 |
|---|---|---|---|
| 正常 | 正常流量(无攻击) | 77054 | 1 |
| DoS | 拒绝服务攻击(超载以中断服务) | 53385 | 1.44 |
| 探针 | 探测攻击(信息收集) | 14077 | 5.47 |
| R2L | 远程到本地攻击(未经授权的远程访问) | 3749 | 20.55 |
| U2R | User-to-Root 攻击(尝试获得超级用户权限) | 252 | 305.77 |
4.4不平衡处理算法的评估
4.4.1比较实验。
为了衡量各种不平衡处理算法的流量数据生成质量,我评估了在这些算法处理的数据上训练的分类器的性能。这种方法是合理的,因为分类器的性能可以作为训练数据质量的代理[19].实验评估了所提出的 SC-CGAN 方法,并将其与其他 8 种不平衡处理算法进行了比较。
表 2:为每个类生成的样本数
| 数据源 | 正常 | DoS | 探针 | R2L | U2R |
|---|---|---|---|---|---|
| 原始数据 | 67343 | 45927 | 11656 | 995 | 52 |
| 生成的数据 | 0 | 21416 | 55687 | 66348 | 67291 |
平衡实验数据的方法包括为每个类别生成额外的样本,并将它们整合到原始数据集中。此过程可确保每个类别中的样本数量相等。对于 KDDTrain+ 数据集,由于 Normal 类最初包含最高数量的样本,为 67,343,因此我为每个其他类别生成了等效数量的样本以匹配此数字。表 2 中列出了为每个类别生成的相应样本数量。
表 3:SC-CGAN、CVAE 和 CSCA-CNN 超参数
| 超参数 | 发电机 | 鉴别器 | CVAE | CSCA-CNN |
| 隐藏节点 | 100 | 60 | 60 | 40 |
| 噪声维度 | 123 | - | - | - |
| 注意力维度 | 30 | - | - | - |
| 激活 | 泄漏的 | 泄漏的 | 泄漏的 | 泄漏的 |
| 初始化 | 他 | 泽维尔 | 他 | 赛弗 |
| 批量大小 | 128 | 128 | 128 | 128 |
| 学习率 | 0.001 | 0.000005 | 0.0001 | 0.01 |
| 时代 | 30 | 30 | 120 | - |
| 优化 | 亚当[27] | 亚当 | 亚当 | 亚当 |
| 损失函数 | BCELoss | BCELoss | MSELoss | CSL-CELoss 公司 |
| 卷积核大小 | - | 3 | - | 3 |
| 辍学 | - | 0.3 | - | 0.3 |
| 最大池大小 | - | 2 | - | 2 |
| 潜在维度 | - | - | 32 | - |
| 层数 | 8 | 8 | 10 | 12 |
| CAM 挤压比 | - | - | - | 8 |
为了进行这些比较,我实现了 5 个基线分类器,并使用原始不平衡数据以及由 SC-CGAN 和上述 8 种算法处理的平衡数据对其进行训练。随后,我测试了这些经过训练的分类器的分类性能,以确定每种数据平衡方法的有效性。这种全面的评估可以深入了解不同算法生成的数据质量及其对分类器性能的影响。
表 4 和表 5 中所示的评估结果表明,SC-CGAN 在各种分类性能指标上都表现出显着的优势。这些发现表明 SC-CGAN 在生成平衡训练数据方面的有效性,从而显着提高了分类器的性能。
表 4:不同不平衡处理算法的性能 (%)
| 算法 | 美国有线电视新闻网 (CNN | 多层感知器 | ||||||
|---|---|---|---|---|---|---|---|---|
| 累积 | 前 | 召回 | F1 系列 | 累积 | 前 | 召回 | F1 系列 | |
| 原始数据 | 75.44 | 77.44 | 75.44 | 71.74 | 72.14 | 64.70 | 72.14 | 67.45 |
| ROS的 | 78.63 | 78.50 | 78.63 | 77.26 | 73.19 | 76.49 | 73.19 | 73.90 |
| 击打[13] | 79.40 | 80.58 | 79.40 | 78.27 | 72.37 | 75.93 | 72.37 | 73.64 |
| 边缘 SMOTE[28] | 77.86 | 78.61 | 77.86 | 75.38 | 72.72 | 79.41 | 72.72 | 72.91 |
| KMeans SMOTE[29] | 77.45 | 77.67 | 77.45 | 76.01 | 69.54 | 76.76 | 69.54 | 71.74 |
| SVM SMOTE[30] | 79.62 | 80.46 | 79.62 | 77.75 | 75.26 | 77.78 | 75.26 | 75.06 |
| CVAE[31,32] | 76.75 | 76.56 | 76.75 | 74.31 | 63.40 | 70.12 | 63.40 | 62.68 |
| CBN-CVAE 抗体[33] | 77.07 | 80.98 | 77.07 | 74.49 | 60.52 | 79.24 | 60.52 | 65.62 |
| CGAN 系列[18] | 77.72 | 80.48 | 77.72 | 75.09 | 72.25 | 82.15 | 72.25 | 75.46 |
| SC-CGAN 系列 | 80.96 | 83.04 | 80.96 | 78.78 | 78.28 | 81.74 | 78.28 | 78.81 |
表 5:不同不平衡处理算法的性能 (%)
| 算法 | 决策树 | 随机森林 | K - 最近邻 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 累积 | 前 | 召回 | F1 系列 | 累积 | 前 | 召回 | F1 系列 | 累积 | 前 | 召回 | F1 系列 | |
| 原始数据 | 75.88 | 79.32 | 75.88 | 72.74 | 77.07 | 80.81 | 77.07 | 73.64 | 72.82 | 72.61 | 72.82 | 67.98 |
| ROS的 | 77.02 | 79.14 | 77.02 | 73.84 | 76.54 | 81.50 | 76.54 | 73.00 | 74.71 | 78.55 | 74.71 | 71.70 |
| 击打 | 76.11 | 78.04 | 76.11 | 73.33 | 75.89 | 80.53 | 75.89 | 72.99 | 75.42 | 78.92 | 75.42 | 73.29 |
| 边缘 SMOTE | 75.89 | 78.73 | 75.89 | 73.59 | 76.63 | 79.91 | 76.63 | 73.59 | 74.94 | 78.41 | 74.94 | 72.08 |
| KMeans SMOTE | 76.13 | 79.03 | 76.13 | 72.81 | 76.29 | 79.07 | 76.29 | 72.56 | 75.25 | 79.22 | 75.25 | 72.76 |
| SVM SMOTE | 78.11 | 79.09 | 78.11 | 76.02 | 77.18 | 78.08 | 77.18 | 73.79 | 74.99 | 78.47 | 74.99 | 72.12 |
| CVAE | 78.45 | 79.10 | 78.45 | 77.18 | 77.36 | 81.71 | 77.36 | 74.07 | 77.87 | 80.07 | 77.87 | 74.85 |
| CBN-CVAE 抗体 | 79.40 | 80.69 | 79.40 | 78.19 | 77.78 | 81.42 | 77.78 | 74.95 | 72.57 | 77.10 | 72.57 | 69.52 |
| CGAN 系列 | 79.50 | 80.85 | 79.50 | 76.80 | 77.36 | 81.48 | 77.36 | 75.09 | 78.43 | 81.00 | 78.43 | 75.97 |
| SC-CGAN 系列 | 80.19 | 82.18 | 80.19 | 79.01 | 78.80 | 82.93 | 78.80 | 75.85 | 79.37 | 81.29 | 79.37 | 76.85 |
4.4.2用于可视化的降维。
该过程需要通过采用 t 分布式随机邻居嵌入 (t-SNE) 等技术来降低高维流量数据的复杂性[34]和堆叠式自动编码器 (SAE)[7],最终将数据投影到二维空间中,以便通过散点图进行直观可视化。
图 8 显示了通过使用 t-SNE(如左图所示)和 SAE(如右图所示)降维算法实现的原始不平衡数据和 SC-CGAN 平衡数据的比较可视化。
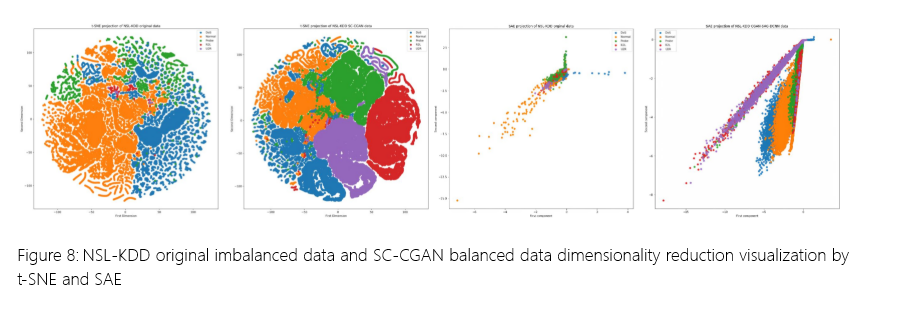
图 8:NSL-KDD 原始不平衡数据和 SC-CGAN 平衡数据降维可视化
观察结果,很明显,与原始数据相比,SC-CGAN 生成的平衡数据显着增加了稀有类别样本的存在,从而有效地缓解了数据不平衡。因此,各种类之间的决策边界变得更加明显,有利于分类任务。此外,通过 SC-CGAN 实现的数据增强扩大了数据覆盖范围,从而可能增强模型的泛化能力。
4.5流量分类算法评估
所有分类算法均基于 SC-CGAN 生成的平衡数据进行训练。为了评估 CSL 和 CAM 组件的有效性,进行了消融实验。在此之后,对基线分类算法和提出的 CSCA-CNN 进行了比较分析。最后,对 CSCA-CNN 的算法复杂性与其他相关研究中报告的复杂性进行了比较评估。
表 6:CSCA-CNN 的消融实验结果 (%)
| 算法 | 中超联赛 | 凸轮 | 美国有线电视新闻网 (CNN | 累积 | 前 | 召回 | F1 系列 |
|---|---|---|---|---|---|---|---|
| CSCA-CNN | ✓ | ✓ | ✓ | 84.55 | 85.70 | 84.55 | 84.52 |
| 仅限 CNN | - | - | ✓ | 80.96 | 83.04 | 80.96 | 78.78 |
| 无凸轮 | ✓ | - | ✓ | 82.66 | 83.37 | 82.66 | 82.30 |
| 无 CSL | - | ✓ | ✓ | 81.72 | 83.41 | 81.72 | 79.60 |
表 7:CSCA-CNN 与基线分类器的比较实验结果(%)
| 分类 | 累积 | 前 | 召回 | F1 系列 |
|---|---|---|---|---|
| 朴素贝叶斯 | 53.80 | 48.44 | 53.80 | 44.25 |
| Logistic 回归 | 77.04 | 79.68 | 77.04 | 73.67 |
| K - 最近邻 | 79.37 | 81.29 | 79.37 | 76.85 |
| 决策树 | 80.19 | 82.18 | 80.19 | 79.01 |
| 随机森林 | 78.80 | 82.93 | 78.80 | 75.85 |
| XGBoost[35] | 78.94 | 81.31 | 78.94 | 76.73 |
| 多层感知器 | 78.28 | 81.74 | 78.28 | 78.81 |
| CSCA-CNN | 84.55 | 85.70 | 84.55 | 84.52 |
表 8:CSCA-CNN 复杂性的比较实验结果
| 指示器 | 美国有线电视新闻网 (CNN | 1D-卷积神经网络 | DNN 2 层 | DNN 3 层 | DNN 4 层 | DNN 5 层 | CSCA-CNN |
|---|---|---|---|---|---|---|---|
| 引用 | [36] | [37] | [37] | [37] | [37] | [37] | - |
| 参数 | 126826 | 90373 | 841221 | 1235717 | 1366789 | 1399557 | 49469 |
| 失败 | - | 6886280 | 1680670 | 2469150 | 2731038 | 2796446 | 729000 |
消融研究明确证明了拟议增强的有效性。在流量分类领域,CSCA-CNN 脱颖而出,与传统的基线分类器相比,表现出相当大的优势。值得注意的是,CSCA-CNN 拥有较低的 Params 和 FLOPs,从而降低了存储要求和过拟合风险。此外,其高效的设计确保它需要更少的计算资源,使其成为交通分类任务的经济高效解决方案。
4.6入侵检测模型的评估
在评估 CSAGC-IDS 的性能时,与经典模型和研究人员近年来提出的最先进的人工智能模型进行了全面比较。最初,我分析 CSAGC-IDS 的二进制分类功能,区分正常流量和攻击模式。随后,我深入研究了五类分类模型的性能比较,这些模型将流量分为五个不同的类:正常、DoS、探测、R2L 和 U2R。
4.6.1二元分类。
为了评估 CSAGC-IDS 模型的二元分类性能,已与各种基准模型进行了比较,包括 LR、NB、SVM-rbf、DNN 1 层、DNN 5 层[38]、多 CNN[9]和 DLNID[11].
表 9:模型二元分类性能比较结果(%)
| 型 | 累积 | 前 | 召回 | F1 系列 |
|---|---|---|---|---|
| LR的[38] | 82.60 | 91.50 | 74.40 | 82.00 |
| 铌[38] | 82.90 | 86.50 | 80.50 | 83.40 |
| SVM-RBF[38] | 83.70 | 76.90 | 99.30 | 86.70 |
| DNN 1 层[38] | 80.10 | 69.20 | 96.90 | 80.70 |
| DNN 5 层[38] | 78.90 | 68.00 | 96.30 | 79.70 |
| 多 CNN[9] | 86.95 | 89.56 | 87.25 | 88.41 |
| DLNID 系列[11] | 90.73 | 86.38 | 93.17 | 89.65 |
| CSAGC-IDS公司 | 91.09 | 93.68 | 90.45 | 92.04 |
4.6.2五类分类。
对于 Siam-IDS[40]、 暹罗IDS[41]和 LIO-IDS[42],其中仅提供了 Pre、Recall 和 F1 分数的各种类别,我使用加权方法来计算总体指标以进行比较。
表 10:模型五分类性能比较结果(%)
| 型 | 累积 | 前 | 召回 | F1 系列 |
|---|---|---|---|---|
| J48 系列[26] | 81.05 | - | - | - |
| NBTree[26] | 82.02 | - | - | - |
| 随机树[26] | 81.59 | - | - | - |
| SVM[26] | 69.52 | - | - | - |
| 亚历克斯网络[14] | 77.02 | 78.54 | 77.24 | 77.88 |
| LeNet-5[14] | 79.91 | 82.95 | 80.01 | 80.45 |
| BiLSTM 的[14] | 79.43 | 81.14 | 79.65 | 80.39 |
| DNN 5 层[38] | 78.50 | 81.00 | 78.50 | 76.50 |
| 美国有线电视新闻网 (CNN[36] | 80.13 | - | - | - |
| 多 CNN[9] | 81.33 | - | - | - |
| 咖啡馆-CNN[10] | 83.34 | 85.35 | 83.44 | 82.60 |
| SCAD-RNN 系列[39] | 82.61 | - | - | - |
| 暹罗 IDS[40] | - | 77.39 | 77.41 | 75.65 |
| 暹罗IDS[41] | - | 78.77 | 80.32 | 78.81 |
| LIO-IDS 系列[42] | - | 81.13 | 80.80 | 80.77 |
| DQN[43] | 81.80 | - | - | - |
| SSDDQN[44] | 79.43 | 82.81 | 79.43 | 76.22 |
| AE-RL 系列[45] | 80.16 | 79.74 | 80.16 | 79.40 |
| 艾斯莫特[15] | 82.09 | 84.11 | 82.09 | 82.43 |
| AE-SAC 公司[37] | 84.15 | 84.27 | 84.15 | 83.97 |
| CSAGC-IDS公司 | 84.55 | 85.70 | 84.55 | 84.52 |
根据表 9 和表 10 中所示的结果,CSAGC-IDS 展示了卓越的性能,突出了其进步性和有效性。CSAGC-IDS 擅长学习数据的深度特征表示,与其他深度神经网络架构相比,它擅长管理复杂、高维和不平衡的数据。
4.7可解释性分析
虽然 CSAGC-IDS 表现出卓越的性能,但其深度学习结构和庞大的参数阻碍了可解释性[46],这是网络入侵检测的关键方面。鉴于错误成本高昂,管理员通常需要的不仅仅是标签来做出明智的决策[47].
为了提高可解释性,我使用了 LIME[48]和 SHAP[49]在 NSL-KDD 上剖析 CSAGC-IDS,以提供对模型决策过程的见解,从而培养信任并支持检测潜在错误。
4.7.1石灰。
LIME(Local Interpretable Model-agnostic Explanations,本地可解释模型解释)训练可解释模型,以接近单个样本的复杂决策边界,提供局部解释[48].
对于 CSACG-IDS 在 NSL-KDD 上的二元分类任务,LIME 采用线性模型来模拟 CSACG-IDS。此可解释模型的系数量化了每个特征对预测的影响。我选择了 4 个正常样本并生成了 50,000 个扰动样本进行分析。
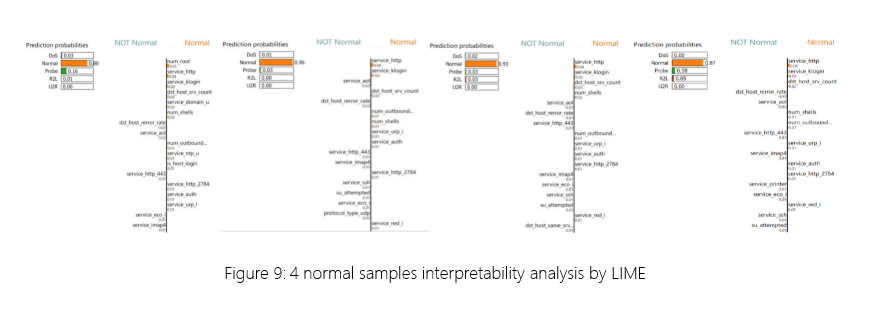
图 9:使用 LIME 进行 4 个正常样本的可解释性分析
如图 9 所示,通过整合 4 个正常样本的分析,很明显 service_http、dst_host_srv_count、service_klogin、service_urp_i 和 num_shells 等特征对预测 CSACG-IDS 中的正常类别有积极影响。相反,service_aol、service_eco_i、service_imap4 和 service_ssh 等功能会产生负面影响。service_http 表示 Internet 中经常出现的常见 HTTP 服务。它可能表示 DoS 等行为。该dst_host_srv_count反映了主机上服务的使用情况,这可能会揭示端口扫描和利用多个服务中的漏洞的尝试。该功能service_klogin指示 Kerberos 登录,这可能表明合法的用户身份验证行为。该num_shells可能显示恶意用户或脚本试图控制系统,这可能与 U2R 和 R2L 攻击有关。service_ssh 表示用于远程管理的 SSH 服务,这可能会揭示存在未经授权的远程访问和控制(U2R、R2L)。
4.7.2十八。
SHAP(SHapley 加法解释)评估每个特征的贡献,通过 Shapley 值量化其对模型结果的平均边际影响,为每个特征提供定量分析[49].
SHAP 为 CSAGC-IDS 提供二进制解释,在力图中可视化每个特征的 Shapley 值(图 10)。在这里,Shapley 值被描述为力,表示它们对结果的影响,红色表示正影响,蓝色表示消极影响。在攻击样本的预测中,service_http 等特征对预测攻击类别有积极影响,而 flag_REJ 等特征则有负面影响。
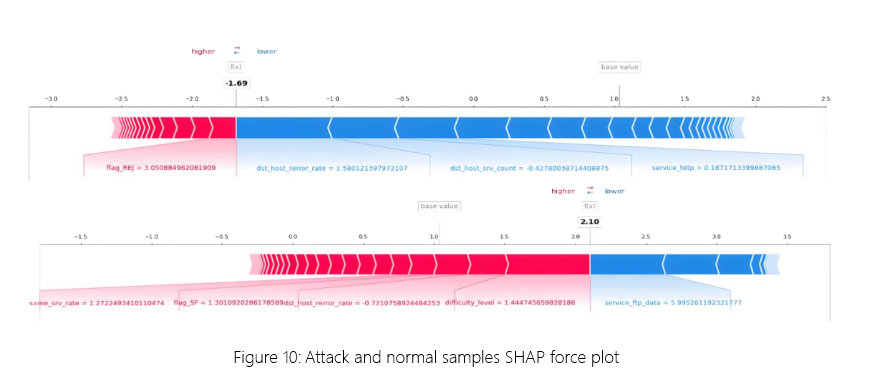
图 10:起音和法向样本 SHAP 力图
通过获取 100 个样本并在水平堆栈中绘制力图。如图 11 所示,样本 56 根据 service_http、dst_host_rerror_rate 和 service_imap4 特征的值被归类为攻击样本。此service_imap4可能会揭示利用 IMAP4 邮件服务进行攻击的行为。dst_host_rerror_rate 表示目标主机上的连接错误率,这可能表明主机正受到大量无效或恶意请求 (DoS) 的影响。
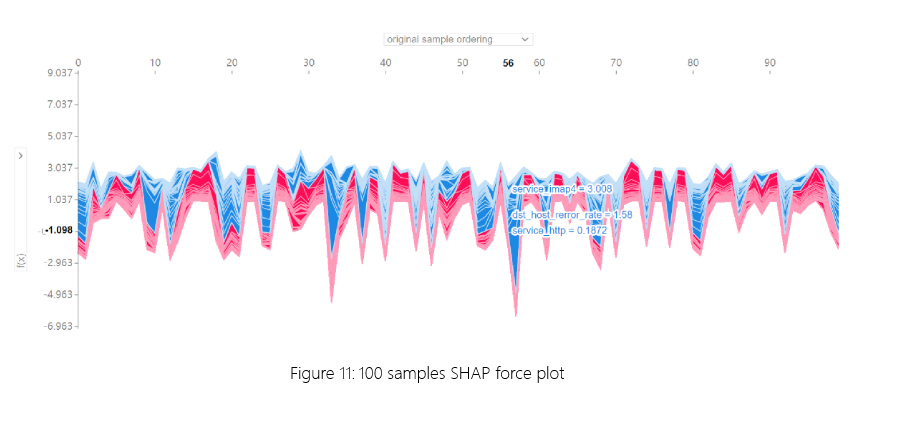
图 11:100 个样本 SHAP 力图
5结论
CSAGC-IDS 是一种深度学习网络入侵检测模型,它利用成本敏感学习和混合注意力机制来应对网络入侵检测中高维、复杂和不平衡数据分布的挑战。实验结果表明,它能有效地解决这些问题。
CSAGC-IDS 包括两种算法。SC-CGAN 将 CGAN 与 CSAM 和 CNN 集成,以融合条件信息、捕获特征依赖关系、生成高质量数据。用于流量分类的 CSCA-CNN 集成了 CAM 和 CSL,从复杂和高维数据中提取深度特征,为少数群体分配了更高的成本,以减少数据不平衡造成的偏差。最后,增强模型的可解释性为决策过程提供了解释。
基于本文,未来工作有几个前瞻性方向。首先,增强稳健性[43,50].其次,降低参数和计算复杂性[51,52].第三,考虑网络流量的时间特性[47].