深入理解 LangChain 文档处理机制:Document 类与文档加载器详解
Document 类简介
Document 类是 LangChain 中的核心组件,用于定义文档对象的结构,包含文本内容和对应的元数据。该类同时也是文档加载器、文档分割器、向量数据库、检索器等组件之间交互传递的状态数据。
在 LangChain 的旧版本中,Document 类曾支持 lookup 检索功能,而在新版本中,Document 类仅保留最基础的信息记录功能。
文档加载器的作用及应用场景
在我写的其他博客中,我们通常采用手动输入的方式来创建数据。但在实际的 RAG(Retrieval-Augmented Generation,检索增强生成)开发过程中,更常见的是从特定的数据源读取数据,例如:
- 本地 Markdown 文件
- HTML 网页
- PDF 文档
- DOC 文档
- URL 链接
随后,我们通常还需要对加载的原始文档进行特定规则的分割,并最终存储到向量数据库中。因此,实际开发中几乎不会手动录入数据。
更多详细信息请参考:
- 💡大模型中转API推荐
- ✨中转使用教程
- LangChain 文档加载器
在实际的 RAG 应用之外,通常会有一个额外的扩展模块,专门处理“数据读取 → 数据切割 → 数据存储”的完整流程。由于该流程较为耗时(例如上传一个 30MB 的文档需要经过加载、切割和文本嵌入等操作),一般会采用队列或异步方式进行处理。架构流程如下所示:
数据源 → 文档加载 → 文档切割 → 文本嵌入 → 向量数据库存储
文档加载器定义及方法说明
在上述新架构流程中,文档加载器的作用是将来自不同数据源的信息统一提取并转换为标准的 Document 对象,从而实现对不同类型文件读取方式的封装和抽象。
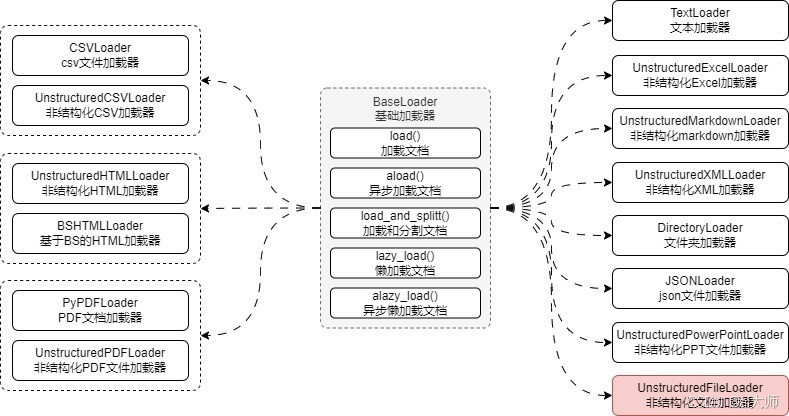
在 LangChain 中,所有文档加载器的基类均为 BaseLoader,该基类统一封装了以下 5 个方法:
| 方法名 | 描述 | 返回类型 |
|---|---|---|
load() / aload() | 同步/异步加载文档 | 文档列表 |
load_and_split(splitter) | 加载文档并使用指定的分割器进行分割 | 分割后的文档列表 |
lazy_load() / alazy_load() | 同步/异步懒加载文档,返回迭代器,适用于多文档数据源 | 文档迭代器 |
LangChain 内置了数百种文档加载器,几乎涵盖了所有常见文件类型,开发人员可以直接使用这些加载器快速完成数据加载,无需手动封装。
更多详细信息请参考:
- 💡大模型中转API推荐
- ✨中转使用教程
- LangChain 文档加载器