数据治理域——日志数据采集设计
摘要
本文主要介绍了Web页面端日志采集的设计。首先阐述了页面浏览日志采集,包括客户端日志采集的实现方式、采集内容及技术亮点。接着介绍了无线客户端端日志采集,包括UserTrack的核心设计、移动端与浏览器端采集差异以及典型应用场景崩溃分析。最后探讨了日志采集的挑战与解决方案,以及日志采集前置到用户终端的相关问题。
1. Web页面端日志采集
1.1. 页面浏览(展现)日志采集
记录页面加载和首次渲染的日志,是互联网产品最基础的统计来源。
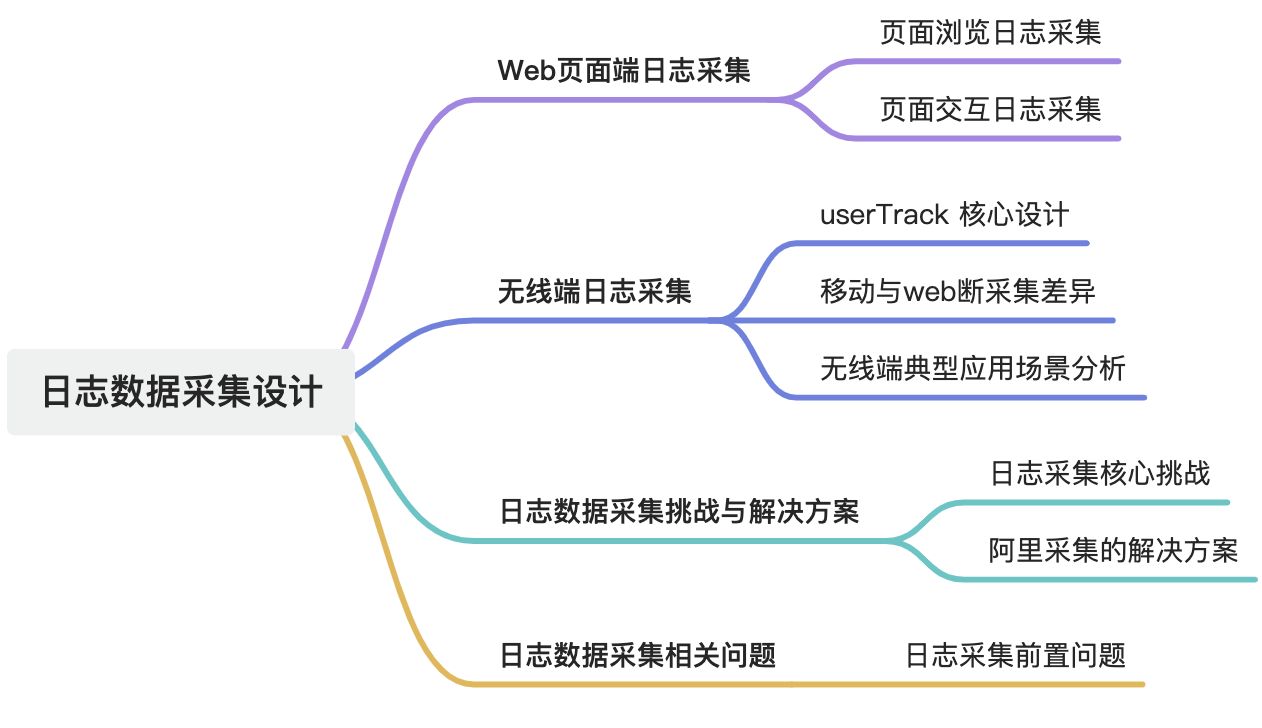
1.1.1. 客户端日志采集
实现方式:
- 动态脚本植入(占比高):由业务服务器在响应HTTP请求时,动态插入日志采集脚本(如通过模板引擎注入
<script>标签)。 - 优势:支持实时参数配置(如动态业务标识、AB实验参数),无需人工干预。
- 手动植入:开发人员在页面代码中手动嵌入SDK脚本,适用于定制化需求较高的场景。
采集内容:
- 页面参数:URL、Referrer(来源页)、页面标题等。
- 上下文信息:HTTP Referer(上一步页面)、用户行为轨迹(如点击事件)。
- 环境信息:UserAgent(浏览器类型/版本)、屏幕分辨率、时区等。
技术亮点:
- 防篡改机制:通过HMAC签名验证请求合法性,防止伪造日志。
- 跨域处理:使用JSONP或CORS解决跨域脚本加载问题。
1.1.2. 客户端日志发送
发送策略:
- 同步发送:优先在页面加载完成时立即发送,确保核心指标(PV/UV)实时性。
- 延迟发送:对非关键日志(如用户停留时长)采用异步上报,避免阻塞页面渲染。
技术实现:
- HTTP协议:通过GET/POST请求发送,参数拼接在URL或Body中(如
?t=1620000000&_m_h5_tk=xxx)。 - 可靠性保障:
-
- Beacon API:在页面卸载时使用
navigator.sendBeacon确保数据发送。 - 本地存储兜底:失败日志暂存LocalStorage,下次会话补传。
- Beacon API:在页面卸载时使用
优化措施:
- 请求合并:同页面多个日志合并为单次请求,减少连接数。
- 数据压缩:使用Gzip或Brotli压缩URL参数。
1.1.3. 服务器端日志收集
接收与响应:
- 快速响应:日志服务器收到请求后立即返回200状态码,避免影响页面加载性能。
- 异步写入:日志内容写入内存缓冲区(如Kafka Producer Buffer),非阻塞处理。
缓冲区设计:
- 分级存储:
-
- 热缓冲区:内存级存储,支持高吞吐写入(如Apache Pulsar内存队列)。
- 冷缓冲区:磁盘级存储,应对突发流量溢出(如本地文件队列)。
- 数据持久化:定期刷盘(如每5秒),防止数据丢失。
1.1.4. 服务器端日志解析存档
解析流程:
- 格式解码:解析URL参数或POST Body,提取结构化字段(如
_m_h5_tk解析为设备指纹)。 - 数据清洗:
-
- 字段校验:过滤非法字符(如XSS攻击特征)。
- 异常值处理:剔除异常时间戳(如未来时间或超长停留时长)。
- 补全信息:
-
- 关联业务数据:通过
_m_h5_tk关联用户画像(如地域、设备型号)。 - 时区校正:统一转换为UTC时间。
- 关联业务数据:通过
- 存储与分发:
-
- 标准日志文件:按小时切割存储至HDFS(如
/log/pv/2023100101.log)。 - 实时消息队列:推送到Kafka供下游实时计算(如Flink统计UV)。
- 标准日志文件:按小时切割存储至HDFS(如
1.2. 页面交互日志数据采集
记录用户与页面交互行为的日志(如点击、滚动、表单输入等),用于行为分析。
1.2.1. 阿里“黄金令箭”交互日志采集方案
1.2.1.1. 业务方注册与模板生成
元数据管理:
- 业务方在“黄金令箭”控制台注册:
-
- 业务标识(如“淘宝购物车”)。
- 场景维度(如“商品详情页曝光”)。
- 交互采集点(如“按钮点击”“输入框回车”)。
- 动态生成代码模板:系统根据配置生成轻量级JS SDK代码片段(如
goldendart.js)。
技术特点:无代码侵入:通过动态注入脚本,无需修改业务代码逻辑。
参数化配置:支持自定义事件参数(如按钮ID、输入内容)。
1.2.1.2. 交互代码植入与绑定
植入方式:
- 手动植入:开发人员将SDK代码嵌入HTML页面(如
<script src="goldendart.js"></script>)。 - 自动注入:通过阿里云ARMS等工具动态注入SDK(适用于动态页面)。
行为绑定:
- 通过事件监听器(如
addEventListener)绑定交互行为:
// 示例:监听按钮点击事件
goldendart.track('button_click', {button_id: 'add_to_cart',page_url: window.location.href
});- 上下文增强:自动附加环境信息(如设备类型、页面URL、时间戳)。
1.2.1.3. 日志触发与上报
触发时机:
- 同步触发:用户行为发生时立即上报(如点击事件)。
- 延迟触发:对高频行为(如滚动)采用防抖策略(如每500ms聚合一次)。
数据上报:
- HTTP协议:通过POST请求发送至日志服务器(如
https://log.taobao.com/golden_arrow)。 - 数据完整性:通过HMAC签名验证数据合法性,防止篡改。
- 数据格式:
POST /golden_arrow
{"event_type": "input_submit","biz_code": "taobao_cart","custom_data": {"item_id": "12345", "price": 99.9},"_m_h5_tk": "设备指纹","timestamp": 1620000000
}1.2.1.4. 服务器端处理与存储
日志接收:
- 快速响应:返回200状态码,避免阻塞业务请求。
- 异步写入缓冲区:数据写入Kafka或RocketMQ,支持削峰填谷。
数据解析策略:
- 非结构化存储:保留原始JSON数据,仅解析固定字段(如
biz_code、event_type)。 - 动态Schema支持:业务方可自定义字段(如电商场景的
sku_id、游戏场景的level_id)。
数据关联:通过_m_h5_tk设备指纹关联PV日志与交互日志,构建用户行为时序链条。
1.2.2. 页面日志的服务器端清洗和预处理
| 处理阶段 | 处理原因 | 处理方法 | 技术手段 | 输出结果 |
| 识别虚假流量 | 过滤恶意流量(如爬虫、作弊、DDoS攻击),避免污染核心指标(如PV/UV)。 | - 基于机器学习模型识别异常模式(如高频点击、异常IP聚集) | - 机器学习(如XGBoost) | 清洗后的合法日志,剔除异常流量 |
| 数据缺项补正 | 统一数据口径,补充缺失字段(如用户登录后回补身份信息)。 | - 数据归一化(如统一时间戳格式) | - Flink实时计算 | 标准化结构化数据,字段完整率提升 |
| 无效数据剔除 | 去除冗余、错误或失效数据(如已下架商品的交互日志)。 | - 配置驱动的数据校验(如正则校验字段格式) | - 数据质量监控工具(如Apache Griffin) | 精简数据集,存储与计算资源消耗降低 |
| 日志隔离分发 | 满足数据安全(如隐私合规)或业务隔离需求(如区分核心业务与非核心业务日志)。 | - 基于RBAC的权限控制(如仅允许特定团队访问支付日志) | - 数据加密(如TLS传输) | 隔离后的日志按需分发至不同业务环境 |
2. 无线客户端端日志采集
2.1. UserTrack(UT)的核心设计
2.1.1. 事件分类机制
| 事件类型 | 定义 | 典型场景 | 技术实现差异 |
| 页面事件 | 页面生命周期事件(加载、卸载、曝光)。 | 页面PV/UV统计、停留时长计算。 | 监听 生命周期或前端路由变化。 |
| 控件点击事件 | 用户与界面元素的交互行为(按钮点击、滑动)。 | 按钮转化率分析、热力图生成。 | 注入事件监听器(如 )。 |
| 自定义事件 | 业务定制化行为(如支付成功、游戏通关)。 | 核心业务指标统计、用户路径分析。 | 通过UT API主动上报(如 )。 |
2.1.2. 关键技术挑战与解决方案
| 挑战 | 问题表现 | UT的解决方案 |
| 设备唯一性标识 | Android设备ID碎片化(IMEI/Android ID等)。 | 设备指纹算法:融合多维度信息(设备ID+IP+UserAgent+时间戳),生成哈希值 。 |
| Hybrid日志统一 | H5与Native日志格式不一致,数据难以关联。 | 桥接机制:通过JSBridge将H5事件转发至Native层统一上报。 |
| 网络不稳定 | 数据上传失败导致丢失。 | 本地存储+重试策略:失败日志暂存SQLite,网络恢复后批量重试。 |
| 数据解析复杂性 | 日志字段异构(如JSON与键值对混合)。 | 统一数据格式:所有日志序列化为Key-Value结构,支持动态Schema解析。 |
2.1.3. 数据上传策略
实时性分级:
- 高优先级(如崩溃日志):立即上传,失败时启用短信重试。
- 普通优先级(如点击事件):批量上传(每30秒或退出页面时)。
流量控制:
- 动态压缩(GZIP压缩率>70%)。
- 智能降频(弱网环境下采样率降至10%)。
2.2. 移动端与Web端采集差异
| 维度 | 移动端(UT) | 浏览器端(黄金令箭) |
| 设备标识 | 设备指纹(IMEI/Android ID+算法哈希) | Cookie+IP+UserAgent |
| 事件触发 | 依赖Native API(如Activity生命周期) | 基于浏览器事件(如 |
| 网络环境 | 需处理弱网、断网场景(如地铁、地下室) | 依赖稳定HTTP连接 |
| 数据格式 | 统一Key-Value结构,适配多语言(Java/Kotlin) | 基于URL参数或JSON,依赖JavaScript执行环境 |
2.3. 无线端日志采集典型场景
崩溃分析:捕获ANR(Android无响应)与Crash日志,关联设备信息快速定位问题。
// 示例:捕获Java异常并上报
try {// 业务代码
} catch (Exception e) {UT.track("crash", new HashMap<String, String>() {{put("stack_trace", e.toString());put("device_model", Build.MODEL);}});
}用户行为分析:追踪“加入购物车”按钮点击率,优化商品详情页布局。
性能监控:统计页面加载时长(onCreate到onResume耗时)。
3. 日志采集挑战与解决方案
3.1. 日志采集核心挑战
以下是整理后的表格:
| 问题分类 | 表现描述 | 核心难点 |
| 海量日志处理压力 | 日志量达亿级/日,大促期间近万亿级数据;全链路(采集、传输、解析、分析)存在性能瓶颈。 | 需协同优化峰值QPS、传输速度、实时解析吞吐量与计算资源分配,避免单一环节成为性能瓶颈。 |
| 日志结构化与规范化 | 日志类型多样、规模激增,需统一分类与标准化;避免资源浪费(如过度预处理)或覆盖不全(仅处理关键日志)。 | 动态业务需求下,如何灵活适配不同日志的解析规则(如URL正则匹配维护成本高),平衡规范化和灵活性。 |
| 实时性与业务深度平衡 | 高实时性场景(如推荐系统)要求端到端低延迟,但传统链路环节多(采集→传输→解析→分析),难以满足需求。 | 需权衡稳定性与扩展性(如增加实时计算能力可能引入故障风险),优化链路环节或采用轻量化处理方案。 |
| 资源分配与热点突发 | 流量热点(如大促页面)与常规模块共享资源,易导致关键业务被淹没。 | 在共享基础设施时实现优先级控制与分流,避免资源竞争,需动态调度策略(如基于SLA的资源隔离)。 |
| 动态配置与扩展性 | 业务快速迭代要求日志采集规则灵活调整,传统静态配置(季度/年更新)无法适应。 | 客户端和服务端协同实现高频更新(如周/月级)与配置化落地,需动态配置中心支持(如热更新、版本回滚)。 |
3.2. 阿里数据采集解决方案
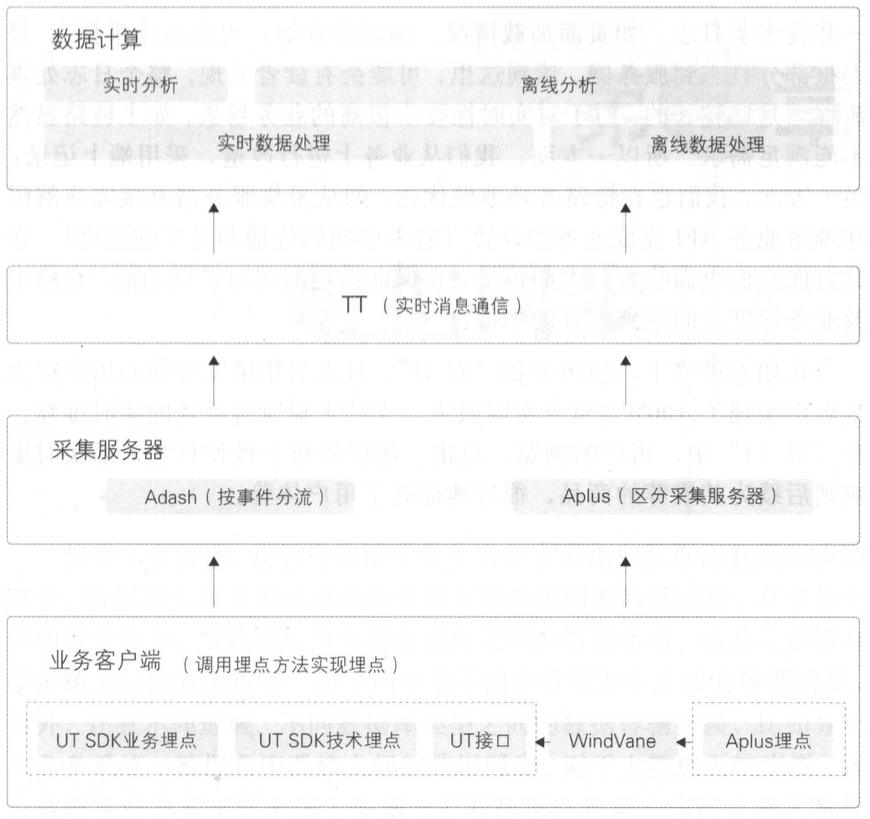
3.2.1. 日志采集链路的分层优化
推送式配置管理
- 服务端可动态下发采集配置,实现日志的实时采样、延迟上报、限流控制。
- 配置可针对具体应用、平台、事件或场景,实现精细化管理。
客户端前置分类与更新
- 将部分日志分类与逻辑前置到客户端,减少服务器端处理压力。
- 客户端采集代码支持高频率更新(周/月级),并实现配置化,提高响应速度。
3.2.2. 日志分流机制
按优先级与业务分流
- 对日志进行优先级划分(如用户行为 vs 技术日志)。
- 根据业务特征和日志重要程度,将日志拆分至不同采集处理通道。
按业务类型路由分流
- 日志采集路径根据页面类型变化,早期进行路由分流,减少后端分支判断和资源消耗。
3.2.3. 采算一体应用链路
SPM 与 Goldlog 规范系统
- SPM(页面流量埋点)规范:支持页面访问日志结构化、归类、自动聚合分析。
- Goldlog(自定义事件埋点)规范:支持定制事件采集与可视化分析。
- 用户通过简单配置即可完成日志注册、采集、统计、展示的全流程。
元数据中心支持
- 埋点信息通过元数据注册,驱动采集与后端计算协同,降低手动配置成本。
3.2.4. 高性能日志处理与错峰限流
高峰期日志限流机制
- 对非关键日志延迟上传或采样上报,确保系统高可用性。
- 高峰期动态启用限流策略,平稳过渡后再恢复全量日志处理。
端上日志记录+本地计算
- 对于高实时性场景(如实时推荐),直接在采集节点完成部分业务逻辑处理,跳过部分中间层,提升处理
4. 日志数据采集相关问题
4.1. 日志采集前置到用户终端(如手机)是否有要求、以及是否会影响用户使用体验?
4.1.1. 是否对用户手机有要求?
原则上没有硬性要求
- 日志前置分类主要涉及客户端(如App)中嵌入的埋点逻辑和配置信息,不依赖手机的硬件特性。
- 适用于绝大多数智能手机终端(Android/iOS主流版本均支持)。
面向客户端更新的兼容性设计
- 采用配置化、模块化更新,避免因新功能导致旧版本手机不兼容。
- 若某些机型或系统版本不支持某项功能,可通过灰度发布、降级策略处理。
性能资源方面需适当控制
- 日志前置分类需要一定的 本地计算资源(CPU)、存储资源(缓存),但设计时通常考虑其开销微小。
- 会对设备带来极小的计算和存储负担,但远低于音视频渲染等任务。
4.1.2. 是否会影响用户使用体验?
正常使用几乎无感知
- 分类操作通常在页面加载/事件触发后异步执行,不占用主线程,不阻塞 UI 渲染。
- 日志写入与上传采用异步+批量策略,不会造成明显卡顿或延迟。
日志上传有节流策略
- 支持延迟上传、弱网暂停、仅 WiFi 上传等配置策略,避免在用户弱网或流量宝贵时频繁传输日志。
极端情况下的影响控制
- 在极端高频埋点场景(如滚动监听、滑动手势等)中,如果埋点密集、优化不当,可能会引起:页面卡顿、电量消耗稍高、应用包体增大(埋点 SDK 过重)
解决方法:
- 使用采样率控制 + 埋点聚合策略(如将滚动次数合并统计)
- 动态配置控制哪些埋点启用
- 定期清理本地缓存日志
4.1.3. 互联网大厂是怎么控制这类问题的?
- SDK 轻量设计:客户端 SDK 仅承担分类和缓存,不做复杂计算。
- 配置中心动态控制:可对特定设备型号/系统版本下发特定策略。
- 灰度与A/B测试机制:保障任何埋点和分类策略上线前都经过性能验证。
- 本地监控指标采集:检测客户端埋点对性能的影响,实时反馈和优化。
5. 博文参考
《阿里巴巴大数据实践》