图形学、人机交互、VR/AR领域文献速读【持续更新中...】
(1)笔者在时间有限的情况下,想要多积累一些自身课题之外的新文献、新知识,所以开了这一篇文章。
(2)想通过将文献喂给大模型,并向大模型提问的方式来快速理解文献的重要信息(如基础idea、contribution、大致方法等)。
(3)计划周更4-5篇文献。
(4)文章内容大多由AI产生,经笔者梳理而成。如果有误,敬请批评指正。
文章目录
- 一、Hier-SLAM: Scaling-up Semantics in SLAM with a Hierarchically Categorical Gaussian Splatting
一、Hier-SLAM: Scaling-up Semantics in SLAM with a Hierarchically Categorical Gaussian Splatting
作者:Boying Li, Zhixi Cai, Yuan-Fang Li, Ian Reid, and Hamid Rezatofighi
机构:Monash & MBZUAI
原文链接:https://arxiv.org/abs/2409.12518
代码链接:https://github.com/LeeBY68/Hier-SLAM
发表:ICRA 2025
摘要:
本文提出了 Hier-SLAM,这是一种基于语义的三维高斯溅射 SLAM 方法,具备全新的层级类别表示方式,能够实现精准的全局三维语义建图、良好的扩展性,以及三维世界中显式的语义标签预测。随着环境复杂度的增加,语义 SLAM 系统的参数量急剧上升,使得场景理解变得尤为困难且成本高昂。
为了解决这一问题,本文引入了一种紧凑的层级语义表示,将语义信息有效嵌入到 3D Gaussian Splatting 中,并借助大语言模型(LLM)的能力构建结构化语义编码。此外,本文设计了一种新的语义损失函数,通过层内(inter-level)和跨层(cross-level)联合优化,进一步提升层级语义信息的学习效果。本文还对整个 SLAM 系统进行了全面优化,显著提升了追踪建图性能及运行速度。
Hier-SLAM 在建图和定位精度方面均超越现有的稠密 SLAM 方法,并在运行速度上实现了 2 倍加速。同时,在语义渲染性能上也达到了与现有方法相当的水平,同时在存储开销与训练时间方面大幅下降。令人印象深刻的是,该系统的渲染速度可达每秒 2000 帧(含语义)或 3000 帧(无语义)。尤其重要的是,Hier-SLAM 首次展现了在超过 500 类语义场景中仍能高效运行的能力,充分体现了其强大的扩展性。
1. 什么是语义SLAM系统呢?
语义SLAM(Semantic SLAM)是同时定位与建图(SLAM)技术的升级版,它不仅构建环境的几何地图,还能识别并标注地图中物体的语义信息(如“椅子”“墙壁”“行人”),让机器真正“理解”周围场景。
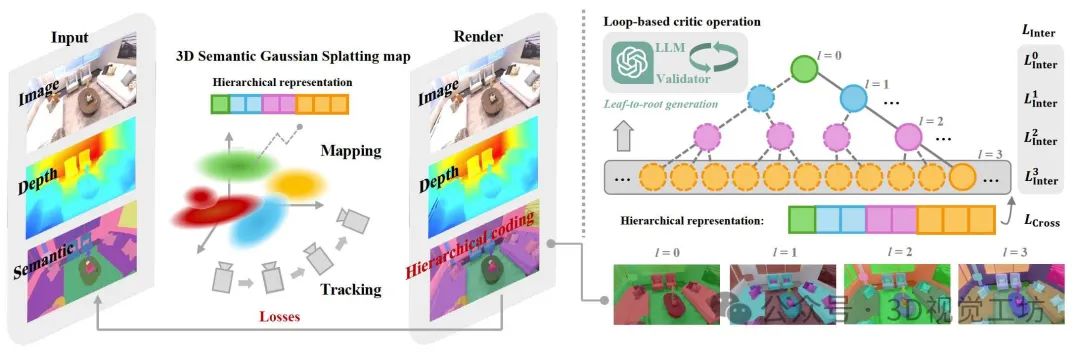
2. 本文是如何实现层级语义表示与3D高斯泼溅的融合的?
(1)层级树结构构建:
(i)语义树定义:将语义类别组织为树状结构 G=(V,E),其中节点 V 表示不同层级的语义类(如“背景→结构→平面→墙”),边 E 表示类别的从属关系。
(ii)LLM辅助生成:
- 输入一组语义标签(如ScanNet的550类),利用LLM(如GPT-4)自底向上迭代聚类,生成层次结构。
- 通过循环校验机制(Loop-based Critic)修正LLM输出:对比LLM生成的聚类结果与输入标签,剔除无关类别(Unseen
Classes)并补全遗漏节点(Omitted Nodes),直至所有标签被正确归类。
(2)紧凑编码设计:
每个3D高斯 primitive 的语义嵌入 h 由各层级嵌入h’拼接而成。

(3)语义优化策略:
- 层级内损失(Inter-level Loss):每层单独计算交叉熵损失,确保层级内分类正确性。
- 跨层级损失(Cross-level Loss):通过共享线性层 F 将层级编码映射为扁平概率分布,与真实标签计算全局交叉熵损失,保证层级间一致性。
通俗易懂的解释:
这篇文章的“语义压缩”方法,可以类比为整理一个杂乱的文件柜:
步骤1:用AI给文件分类(LLM建树)
把一堆未分类的文件(如550种物体标签)交给AI(如ChatGPT),让它按“大类→子类”自动整理。例如:第一层:“家具” vs “电器” 第二层:“家具”下分“椅子”“桌子”……
AI可能分错,所以加了自动修正程序:检查遗漏的标签(如“漏了台灯”),重新让AI补分,直到所有文件归位。
步骤2:给每个物体贴层级标签(紧凑编码)
以前:每个物体直接标记具体名称(如“办公椅”),需要大量标签。
现在:改为层级路径编码(如“家具/椅子/办公椅”),只需记录每层的选择(如1-2-3),大幅节省空间。
步骤3:双重检查(层级优化)
逐层检查:确保“椅子”确实属于“家具”。
整体检查:最终生成的标签(如“办公椅”)要与真实名称一致。
效果:
原本存1000种物体需要1000个标签,现在只需20个数字编码(类似压缩成文件夹路径)。
机器人看到“办公椅”时,既能知道它是“椅子”,也能明白它属于“家具”,适合高层决策(如“避开所有家具”)。
3.本文的核心贡献是什么?
(1)层次化语义表示:提出一种树状层次结构编码语义信息,利用大语言模型(LLM)生成语义类别的层次关系(如“背景→结构→平面→墙”),将语义信息压缩为紧凑的符号编码。例如,10层二叉树可覆盖1024个类别,仅需20维编码(每层2维Softmax)。通过几何与语义属性联合优化,构建多级树结构,显著减少存储需求(相比扁平表示降低66%)。
(2)层次化语义损失函数:设计跨层级(Cross-level)和层级内(Inter-level)联合优化损失,结合交叉熵损失,实现从粗到细的语义理解。
(3)高效SLAM系统:在3D高斯泼溅框架中集成层次化语义表示,优化跟踪(Tracking)与建图(Mapping)模块。系统在保持高精度(ScanNet数据集上ATE RMSE为3.2cm)的同时,实现2000 FPS(带语义)/3000 FPS(无语义)的实时渲染速度,存储需求降低至910.5MB(原需2.7GB)。
(4)扩展性验证:在包含550个语义类别的ScanNet数据集中,通过LLM辅助的层次化编码将语义参数压缩7倍,首次实现复杂场景的高效语义理解。