利用 Python pyttsx3实现文字转语音(TTS)
今天,我想跟大家分享如何利用 Python 编程语言,来实现文字转换为语音的功能,也就是我们常说的 Text-to-Speech (TTS) 技术。
你可能会好奇,为什么学习这个?想象一下,如果你想把书本、文章、杂志的内容转换为语音来“听”,而不是单纯地“看”,这个技术就能派上用场。或者,如果你正在开发一个跨平台的系统,需要整合定制化的语音服务,TTS 也能提供强大的支持。甚至,如果你手头已经有写好的脚本,想快速转换为视频的旁白声音,TTS 也能大幅加快你的工作速度。
现在市面上其实已经有很多成熟的 TTS 服务了。比如说,Google 就提供相当高质量的 TTS 服务,发音自然,速度也快。不过,一旦超出了免费使用额度,就需要付费。台湾也有本地化的选择,像是“雅婷文字转语音”,它更贴近台湾口音,对于服务本地用户非常有帮助。这些商用服务质量通常比较好,处理速度也快。
但是,如果你的需求是比较轻量级的,例如只是想为自己打造一个小工具,或者开发一个不需要大规模部署的小型服务,那么使用 Python 的 pyttsx3 套件就会是一个非常方便且免费的选择。这个套件提供了相当完整的 API 文档,我个人觉得用起来非常直观。你可以去查询它的官方文档,我在文末也会提供相关链接或搜索提示。
好了,话不多说,我们来看看如何实际使用 pyttsx3 吧。

要使用这个套件,第一步当然是先安装它。安装很简单,通常就是通过 pip 指令。确认安装好之后,我们就可以在 Python 环境中开始写代码了。为了方便演示,我选择在 Jupyter Notebook 的环境下来进行。
首先,我们需要把 pyttsx3 套件导入到代码中:
import pyttsx3接着,我会定义一个变量 txt,把我们想要转换为语音的文字放在里面。这里先用一个简单的例子:
txt = "Hello Ryan"
再来,我们需要一个“引擎”来帮我们做转换的工作。我定义一个变量 engine 来代表这个对象:
engine = pyttsx3.init()初始化好引擎之后,之后的所有操作,几乎都是通过这个 engine 变量来进行。
下一步,我们告诉引擎要“说出”什么文字。套件提供了一个很直白的函数叫做 say():
engine.say(txt)最后,也是关键的一步,调用 runAndWait() 函数。这个函数会执行语音转换的过程,并且会等待声音播放完毕:
engine.runAndWait()
好,到这里基本的操作就完成了。执行这段代码,你应该就能听到你的电脑将 "Hello Ryan" 这几个字说出来了。
不过,你可能会发现,默认的语音听起来速度好像有点快,而且语调不一定是最理想的。别担心,pyttsx3 允许我们进行调整。
前面提到,pyttsx3 的 API 文档很有用。通过查阅文档,我们可以找到像 getProperty() 这样的函数,用来获取引擎目前的属性设置。常用的属性有四种:语速 (rate)、语音 (voice)、可用的语音列表 (voices) 和音量 (volume)。
其中,rate 代表说话的速度。如果没有特别设置,默认值通常是每分钟 200 个字。
而 voices 会列出所有我们系统上可用的语音选项。这个列表是会根据你的操作系统而有所不同的。比如说,我目前用的是 Apple 的 macOS 系统,所以在列表中看到的语音 ID 会是 apple 开头的。
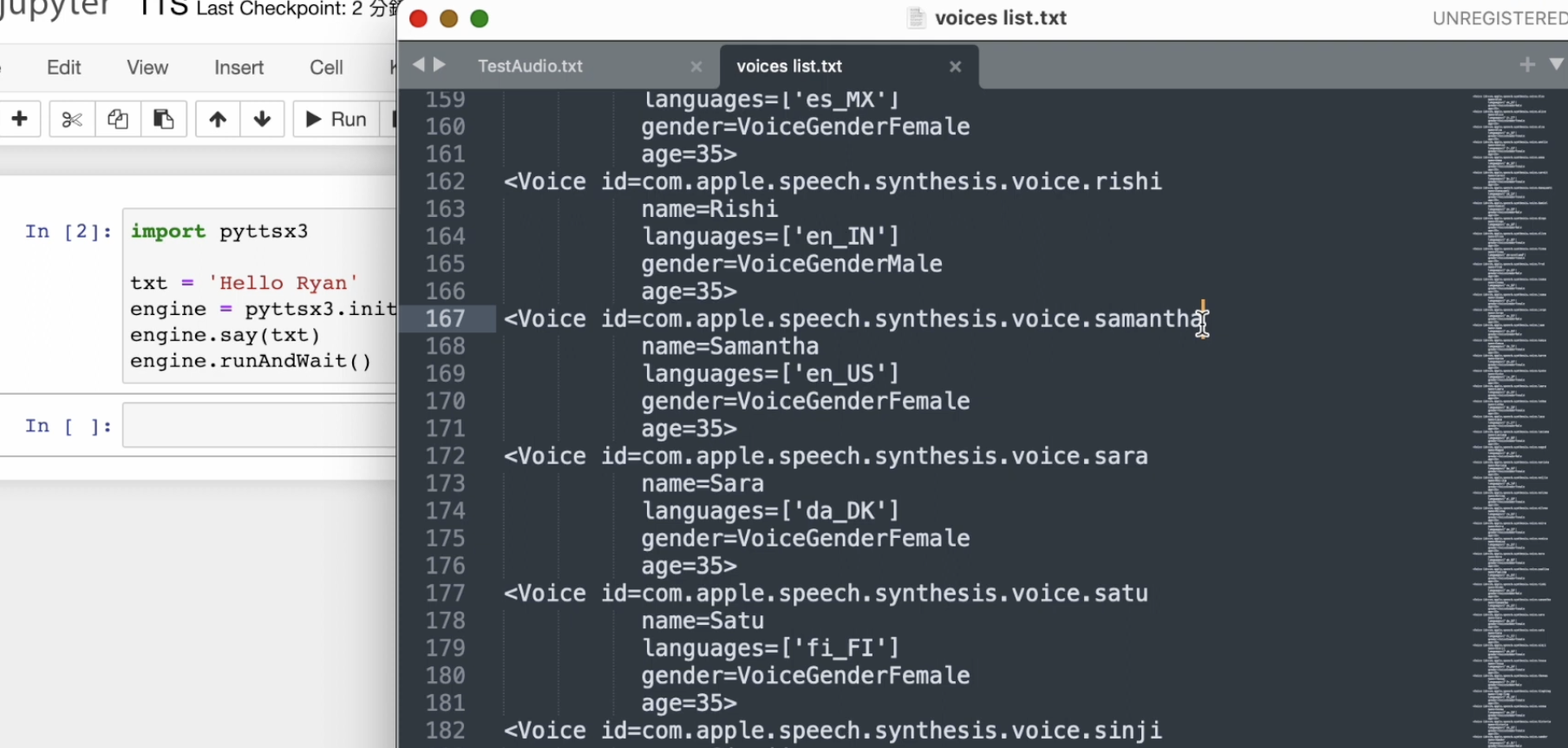
列表里面列出了很多语音选项,它们代表不同的语言和发音人。你可以通过 getProperty('voices') 来查看你系统上提供了哪些语音。每一个语音都有一个独特的 ID。
假设我在列表中看到一个名字叫做 samantha 的语音,它的语言是英文。我想使用这个语音来发音,并且希望速度慢一点,让声音更清晰。我可以这样设置:
首先,使用 setProperty() 函数来设置属性值:
voice_id = "你的英文语音ID,例如 apple speect:Samantha" # 替换成你系统上实际的英文语音ID
engine.setProperty('voice', voice_id)然后,设置语速。因为 "Hello Ryan" 只有两个单词,说太快一下就过去了,我把语速调低一点,例如设置为 50:
engine.setProperty('rate', 50) # 设置语速为每分钟 50 字设置完成后,再执行 say 和 runAndWait:
engine.say("Hello mike")
engine.runAndWait()听起来是不是比刚才好多了?
你也可以尝试其他的语音设置。像我试过一个 ID 叫做 Fred 的语音设置,据说这是 1984 年乔布斯介绍第一台 Macintosh 电脑时,第一次使用电脑将文字转换为语音时的发音。虽然听起来年代感十足,但还挺清晰的。这就展现了选择不同语音的多样性。
除了直接在代码中写死文字,很多时候我们需要读取外部文件中的文字。pyttsx3 也完全支持这一点。
我可以在设置好属性的代码下方,加入读取文件的部分。我使用 Python 常用的 with open() 关键字来打开一个已经准备好的文字文件(假设我把文字内容储存在 my_article.txt 这个文件里)。我给这个打开的文件对象取名为 file。
接着,我使用一个 for 循环,一行一行地读取文件中的文字。在让引擎读出文字之前,我习惯先把它打印出来看看,确保读取的是正确的内容。
with open('my_article.txt', 'r', encoding='utf-8') as file: # 请注意编码设置for line in file:print(line.strip()) # 打印出该行文字engine.say(line) # 将该行文字加入待朗读队列读取完成后,别忘了最后调用 engine.runAndWait() 让引擎开始读:
engine.runAndWait()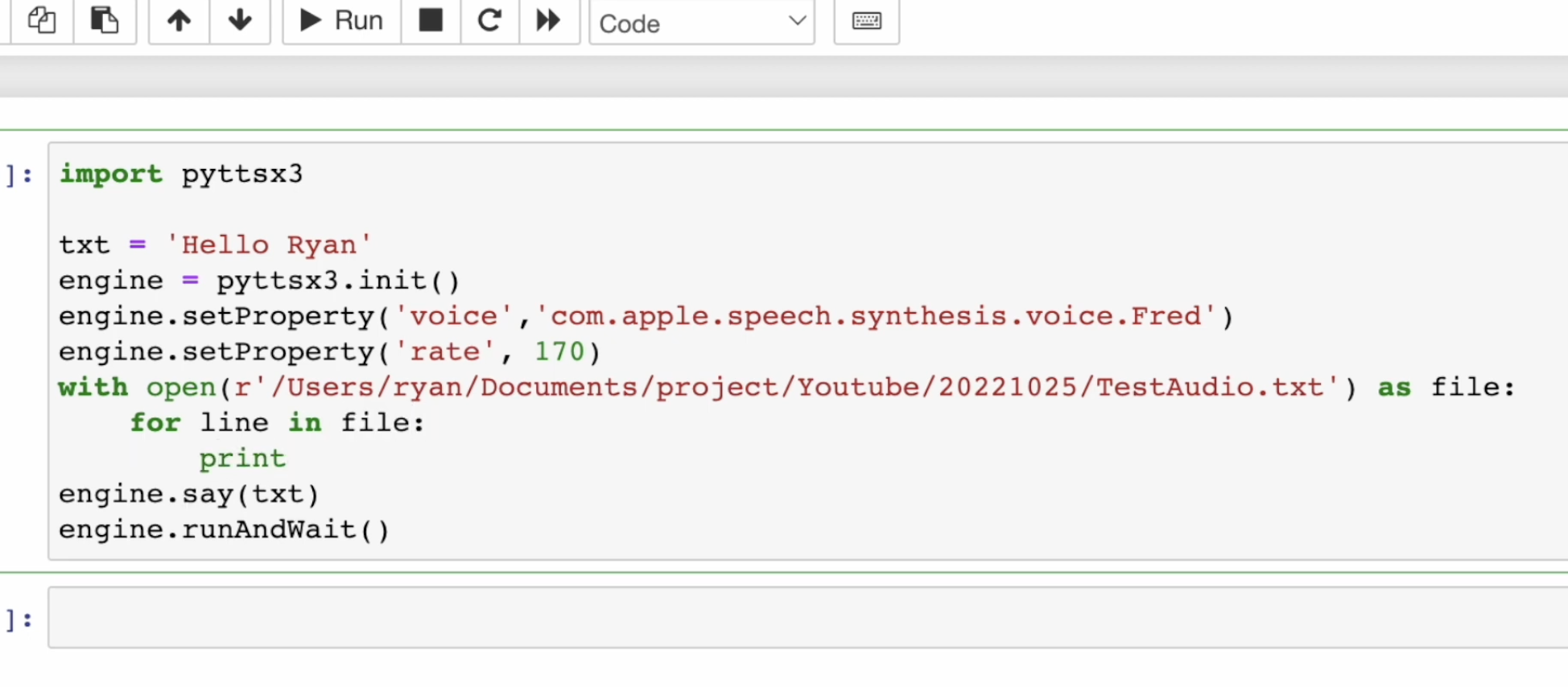
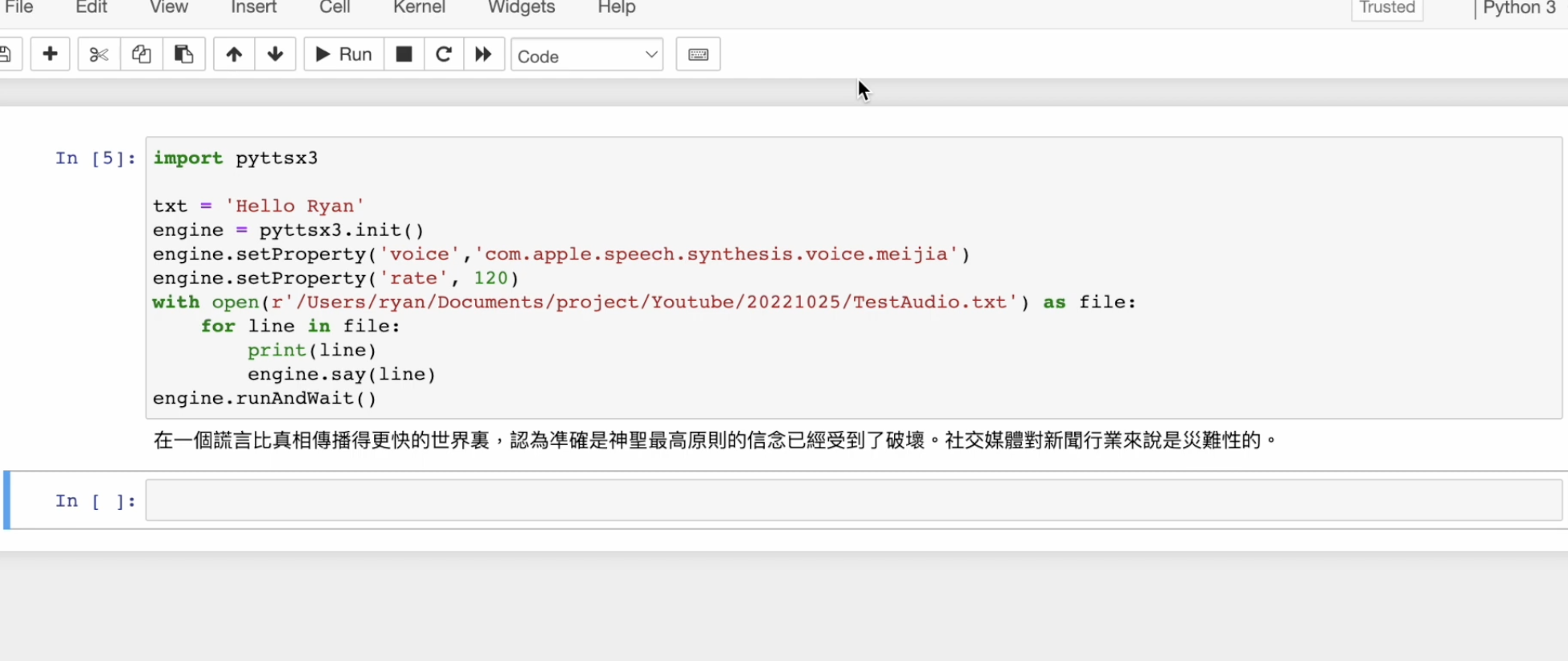
我前面大部分演示都用了英文,现在来试试看中文的转换效果如何。要读中文,最好是将 voice 设置为中文的语音。语速方面,中文的速度感和英文不太一样,我设置为每分钟 120 个字试试看。
文字文件的内容,我找了一段中文文章的片段作为范例。这段文字可能来自一篇关于媒体转型、如何应对社交媒体挑战的讨论。将这段中文贴入文字档后,运行代码:
chinese_voice_id = "你的中文语音ID,例如 com.apple.ttsbundle.zh-CN_Yu-Mai" # 替换成你系统上的中文语音ID,注意可能需要找zh-CN开头的ID
engine.setProperty('voice', chinese_voice_id)
engine.setProperty('rate', 120) # 设置中文语速with open('chinese_article.txt', 'r', encoding='utf-8') as file:for line in file:print(line.strip())engine.say(line)engine.runAndWait()听听看效果如何。你会发现这组语音设置是我们经常听到的中文发音。除了我系统上的腔调,通常还会有其他中文发音选项(例如香港的粤语发音等),你可以根据需求自由选择。
pyttsx3 支持的语音语言非常多样,像是韩语、德语、日语等等。最好的实践就是根据你要转换的文字的语言,设置对应语言的语音,这样说出来的效果才是最自然的。你可以通过 getProperty('voices') 来探索所有你系统上支持的语言和语音。
我在日本福冈生活和工作了一段时间,我想测试一下日语的 TTS 效果如何,顺便分享一个我觉得很漂亮的景点——海中道海浜公园。特别是秋天,那里的花季非常美。这个公园很大,很适合亲子或朋友一起去散步。
我在福冈市政府的官网找到一段介绍这个公园的日文文字,将它复制贴到一个文字文件中。然后将语音设置改为日语发音,语速可以适当调整。
japanese_voice_id = "你的日语语音ID,例如 com.apple.ttsbundle.ja_JP_Kyoko" # 替换成你系统上的日语语音ID
engine.setProperty('voice', japanese_voice_id)
engine.setProperty('rate', 150) # 设置日语语速with open('japanese_info.txt', 'r', encoding='utf-8') as file:for line in file:print(line.strip())engine.say(line)engine.runAndWait()执行后,你就能听到这段日文被用日语发音朗读出来了。
除了直接播放语音,pyttsx3 还能将语音直接制作成文件。官方文档中有介绍,这也很简单,只要调用 save_to_file() 函数就行了。你可以指定输出文件名和文字内容,它会自动帮你保存成像是 mp3 或 wav 格式的音频文件。
output_file = "hello_ryan.mp3"
text_to_save = "Hello Ryan, this is a test."
engine.save_to_file(text_to_save, output_file)
engine.runAndWait() # 需要调用runAndWait来实际执行保存操作
print(f"语音已保存至 {output_file}")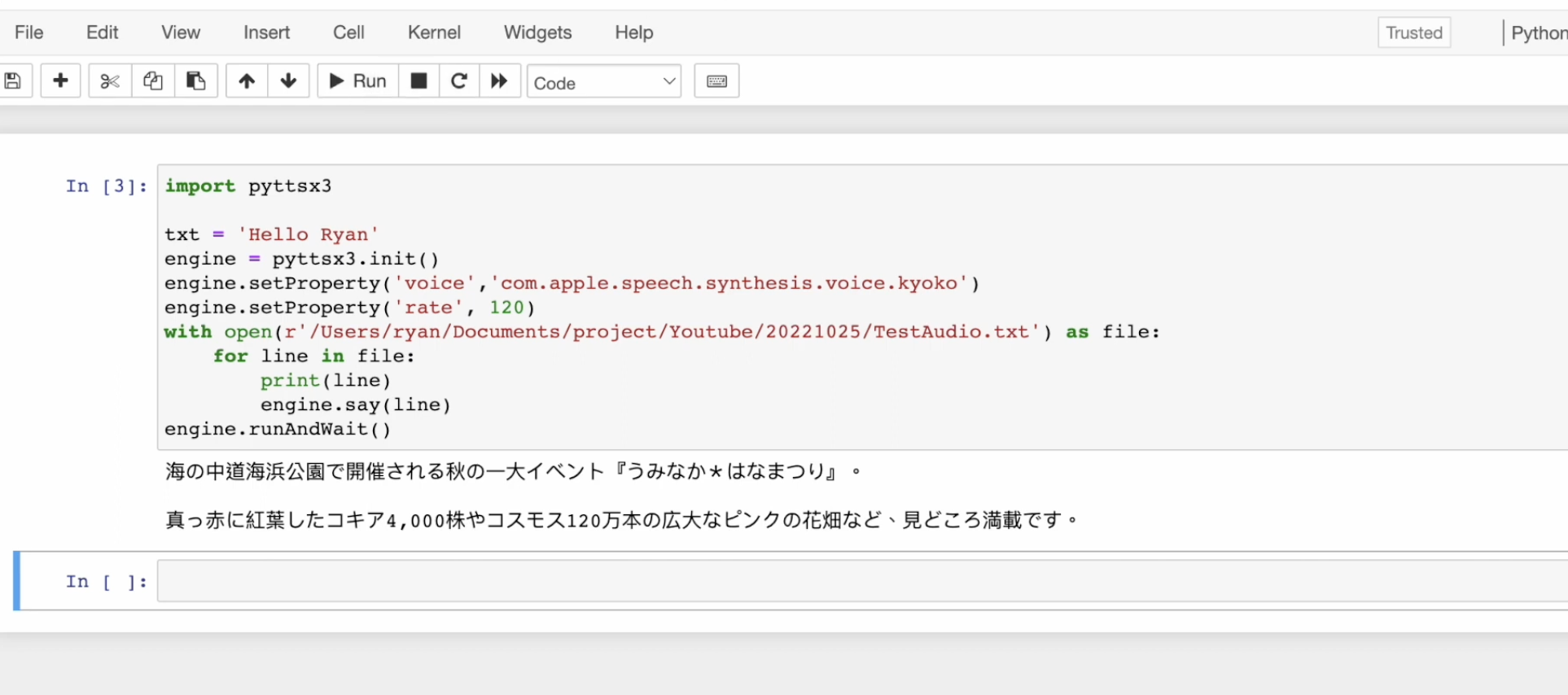
这样就能方便地将文字转换成可重复使用的音频文件了。
总结来说,pyttsx3 这个套件可以帮助我们快速地实现文字转语音服务。它的应用场景很广泛。例如,我们可以结合 Google API,读取你的日程安排、Email 内容,让电脑用读的方式提醒你今天的行程或重要邮件。又或者,如果你有爬取体育数据、股市信息的自动化系统,可以整合 pyttsx3,让系统具备语音提醒的功能,变成一个带有语音服务的自动化工具。
如果你对这种整合多种功能、提升效率的自动化系统感兴趣,其实有很多资源可以学习 Python 的自动化技巧。例如,学习如何自动化文件管理、Excel、Word 等文档软件操作。将重复性的工作自动化,真的可以大幅提高你的工作效率,节省很多宝贵的时间。你可以去搜索相关的 Python 自动化课程或教学资源。
希望这篇文章对你有所帮助和启发!如果觉得有用,欢迎分享给需要的朋友。有任何问题或想法,也欢迎在评论区留言讨论。