n8n工作流自动化平台的实操:利用本地嵌入模型,完成文件内容的向量化及入库
1.成果展示
1.1n8n的工作流
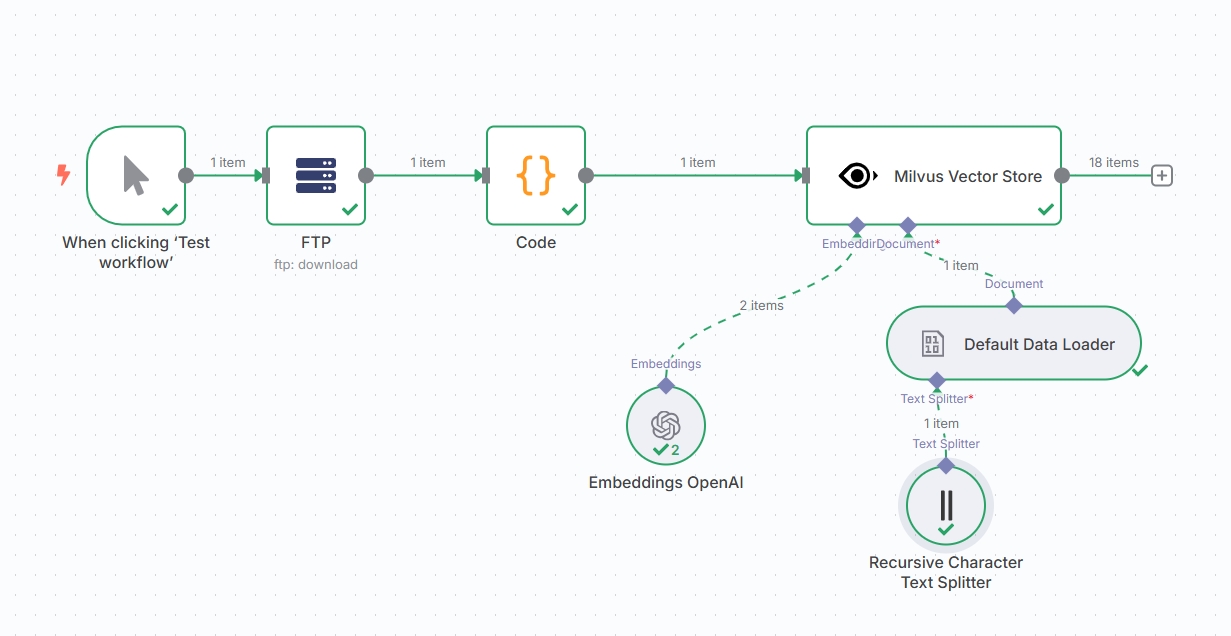
牵涉节点:FTP、Code、Milvus Vector Store、Embeddings OpenAI、Default Data Loader、Recursive Character Text Splitter
12.向量库的结果
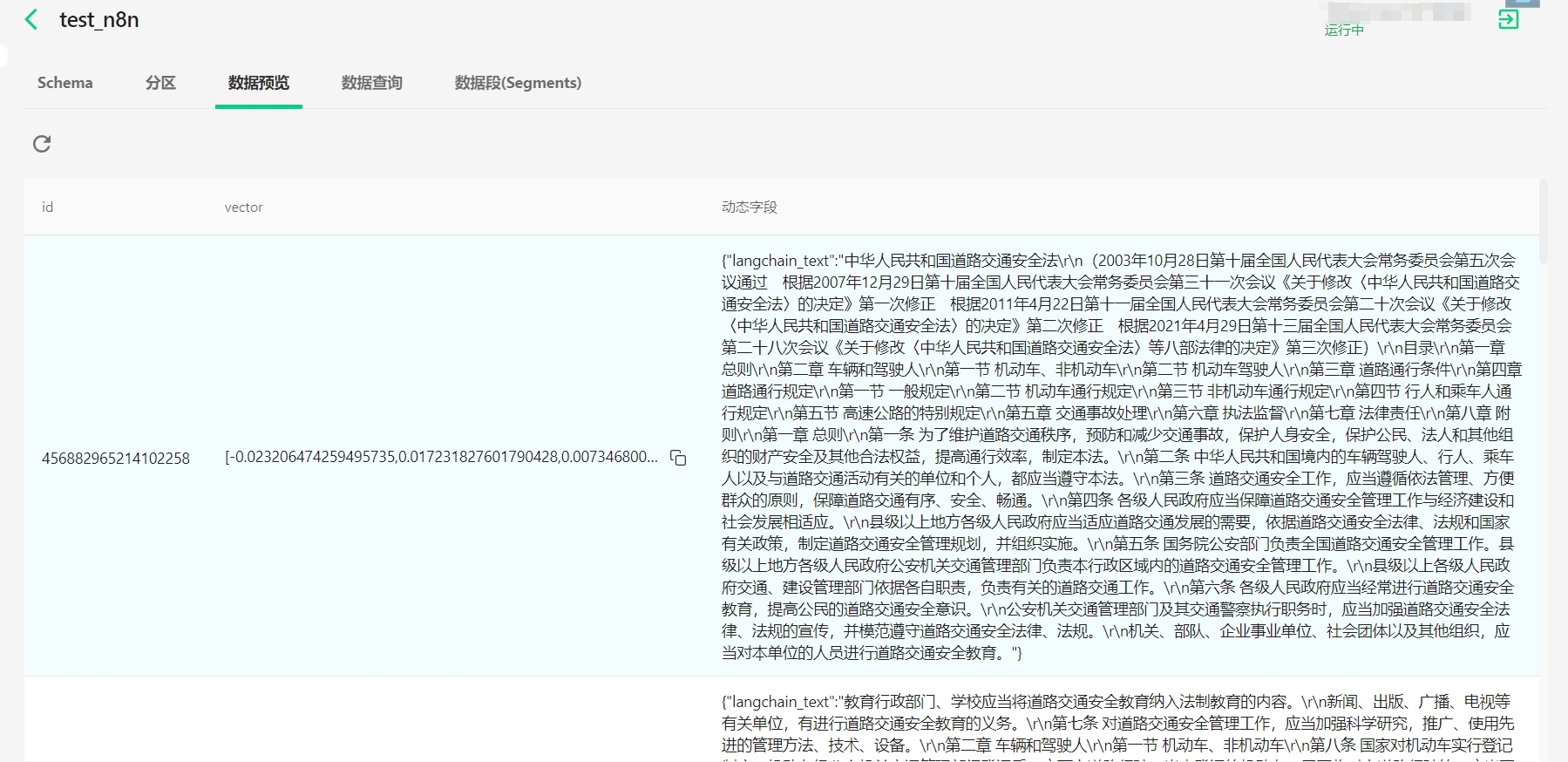
2.实操过程
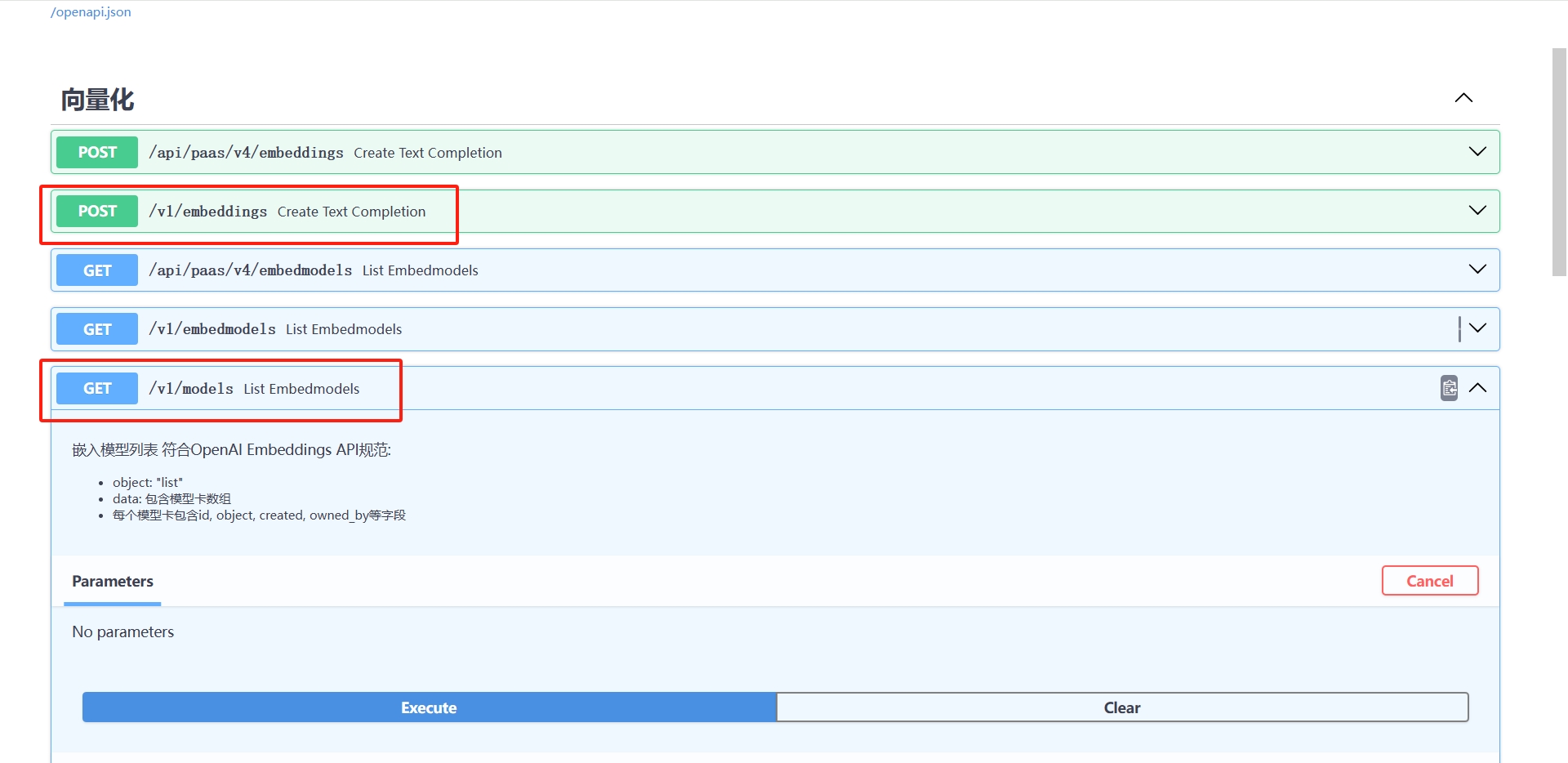
2.1发布本地嵌入模型服务
将bge-m3嵌入模型,发布成满足open api接口规范的服务,必须包括(v1/embeddings和v1/models)这两个接口,具体实现详见https://platform.openai.com/docs/api-reference/embeddings/create,如下图:
2.2在milvus服务创建test_n8n集合
2.2.1创建test_n8n集合,如下图:
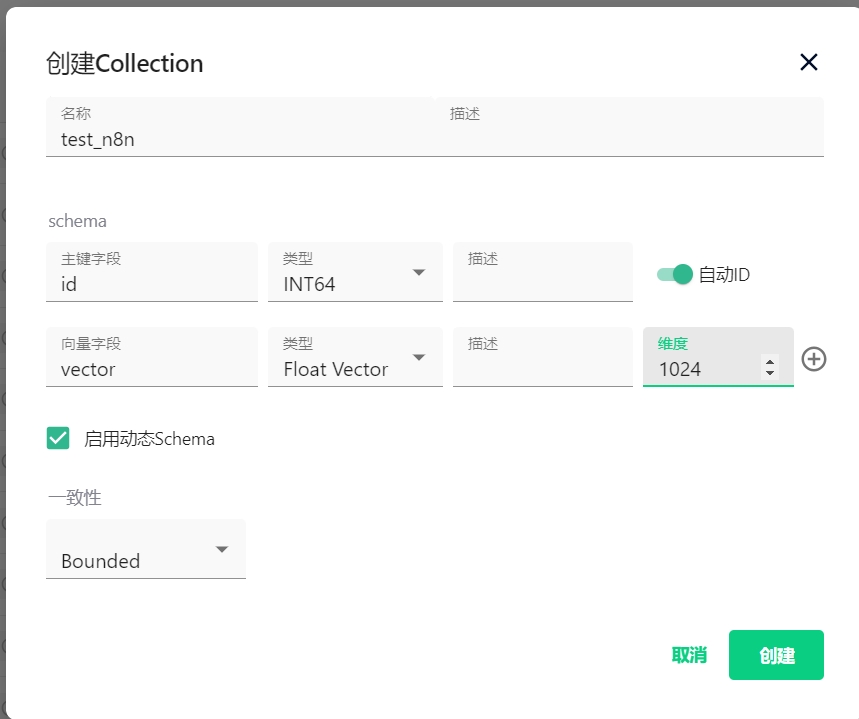
注:
1.必须勾选启用动态schema,否则后面会报错。
2.维度需要和前面发布的嵌入模型维度一致。bge-m3的维度是1024。
2.2.2创建索引,如下图:
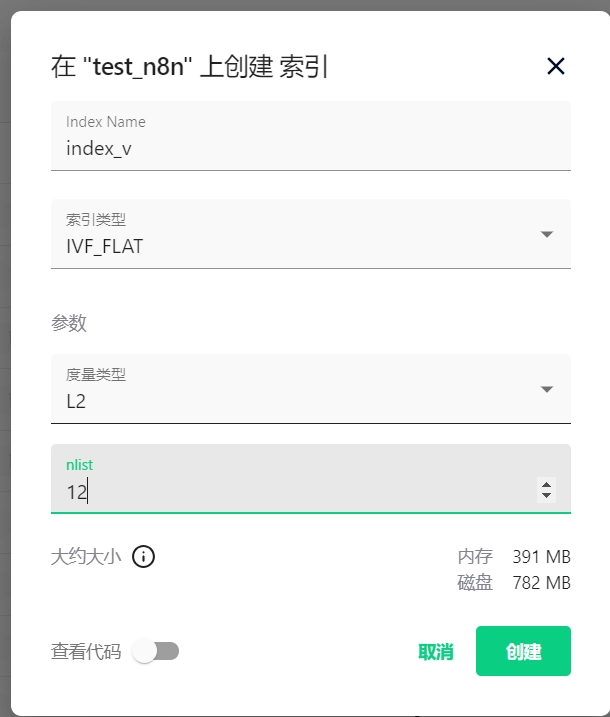
注:度量类型必须是L2,否则后面会报错,因为Milvus Vector Store默认是L2,如何设置成其他,还望有缘人告知。
2.3节点说明
2.3.1FTP节点:
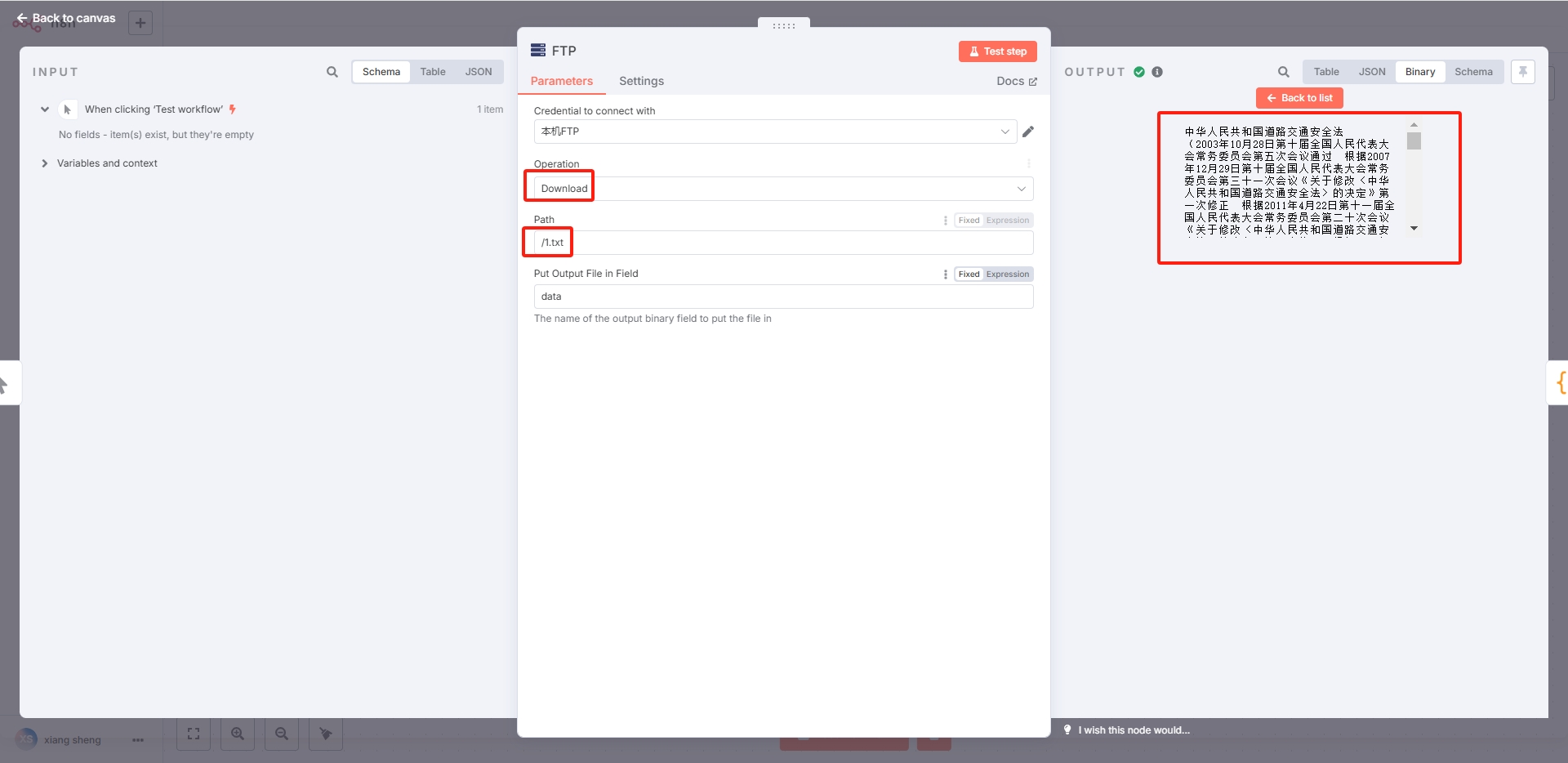
Operation选择Download
Path设置为/1.txt(1.txt是提前上传的文件)。
2.3.2code节点:
解决中文乱码问题,具体操作详见《中文乱码》
2.3.3Milvus Vector Store节点:
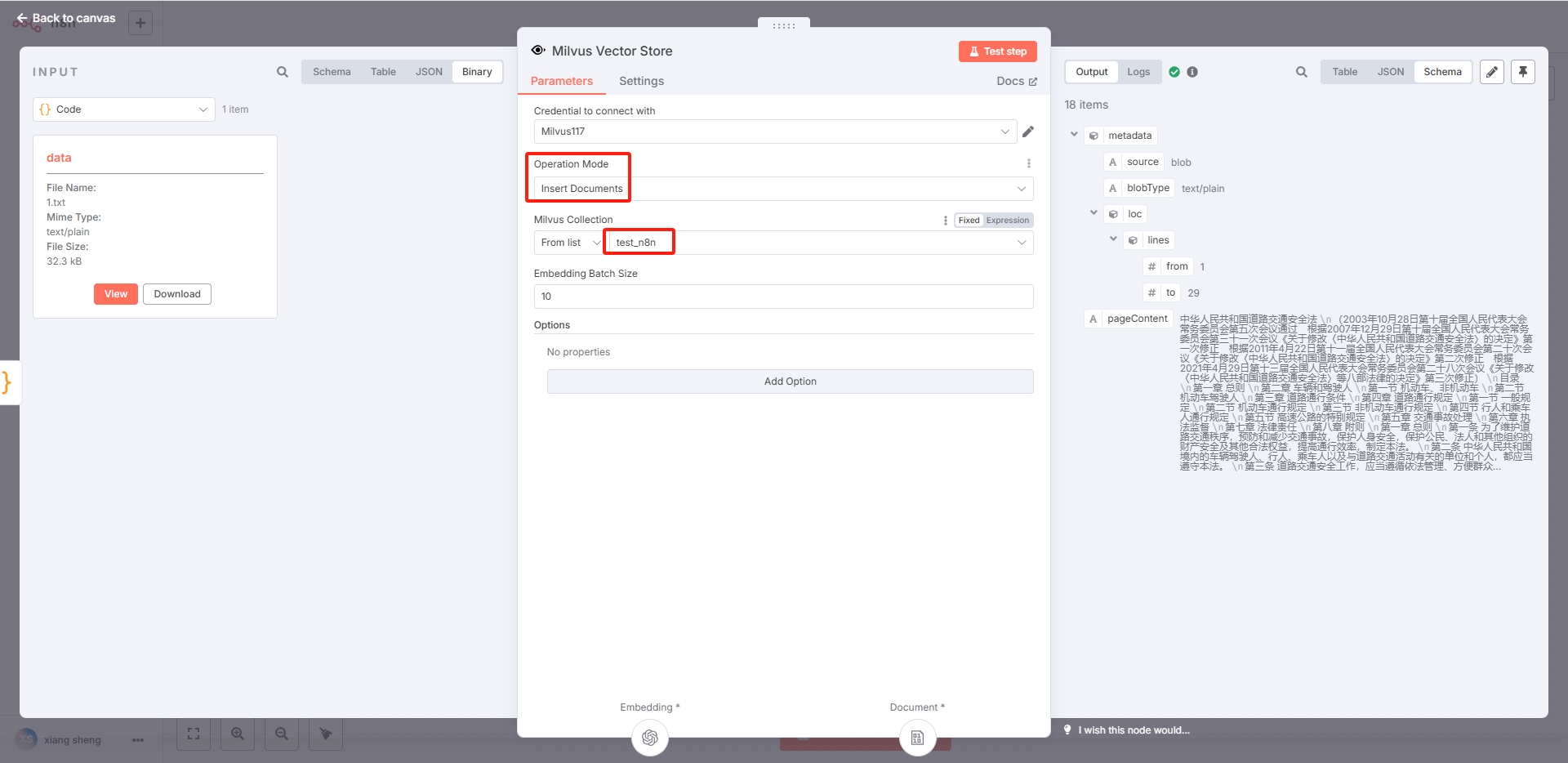
operation Mode:选择Insert Documents
Milvus Collection:test_n8n(对应前面创建的集合)
其他采用默认设置
2.3.4Embeddings OpenAI节点:
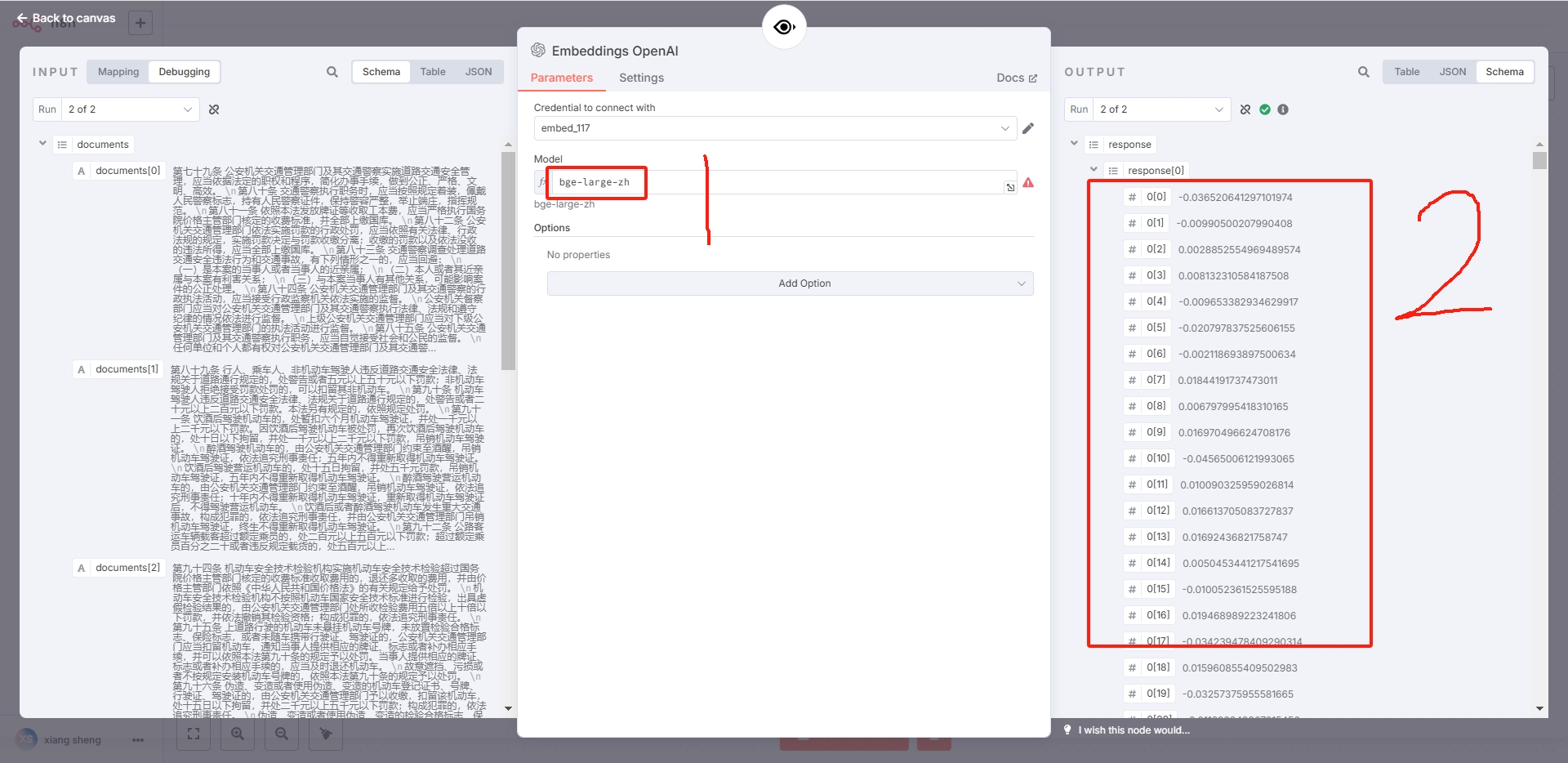
图中1对应v1/models返回的模型名称,图中2对应v1/embeddings返回的内容(向量化)
2.3.5Default Data Loader节点:
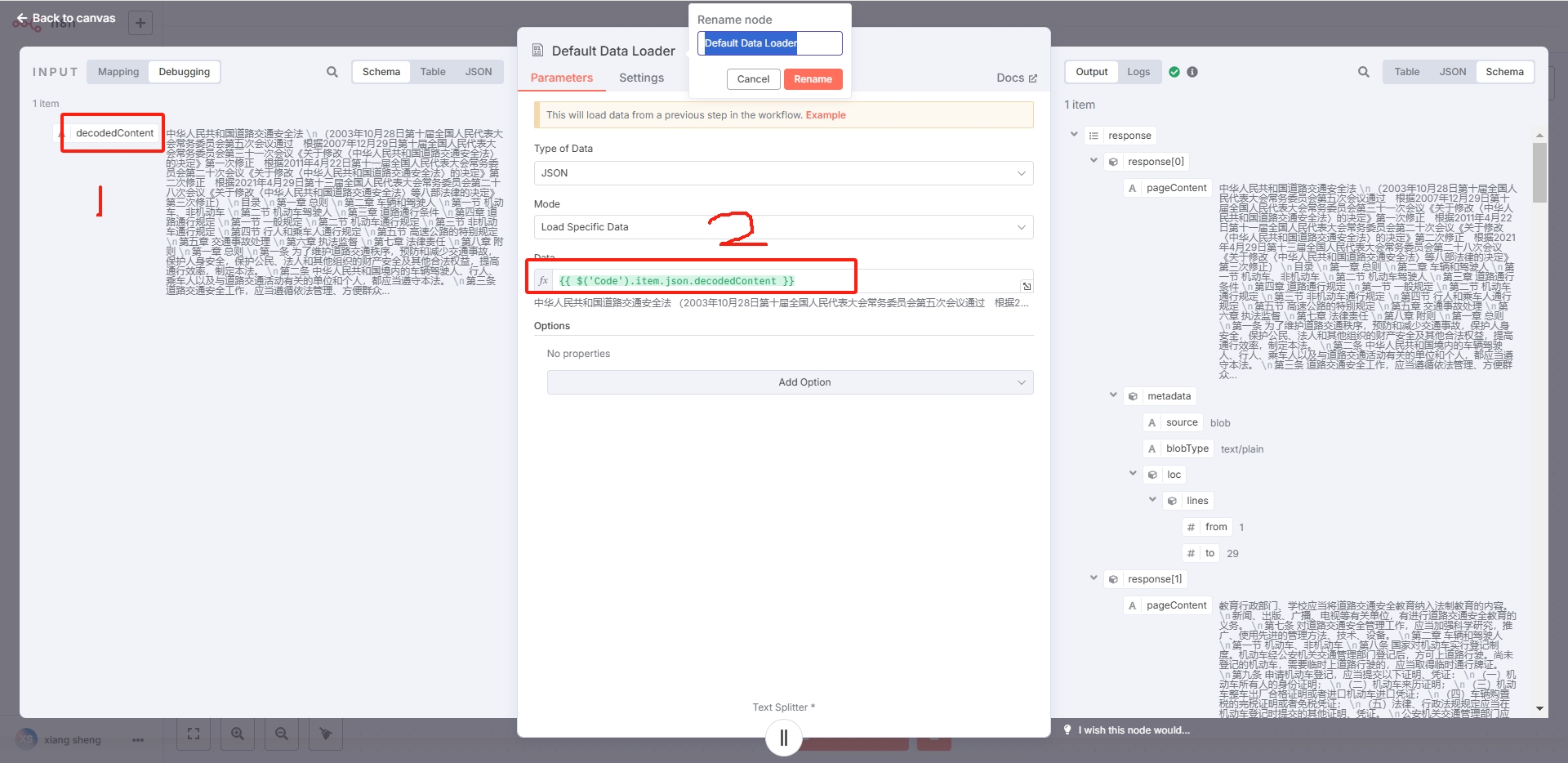
注红框1、2,其他默认就行
2.3.6Recursive Character Text Splitter节点:
默认设置就可以