结构模式识别理论与方法
我们在前文《模式识别的基本概念与理论体系》中就已经提及“模式分类”。
具体内容看我的CSDN文章:模式识别的基本概念与理论体系-CSDN博客
模式的识别方法主要有统计模式识别方法和结构模式识别方法两大类。统计模式识别方法提出得较早,理论也较成熟,其要点是提取待识别模式的一组统计特征,然后按照一定准则所确定的决策函数进行分类判决。例如在汉字识别中,国外学者大多采用这种方法,从效果上看,对单一字体的汉字识别效果较好,但对不同字体混排的印刷资料,由于这种方法没有考虑汉字的结构特征,因而很难适用。结构模式识别的要点是把待识别模式看作是由若干较简单子模式构成的集合,每个子模式再分为若干基元,这样,任何一个模式都可以用一组基元及一定的组合关系来描述,就像一篇文章由单字、词、短语和句子按语法规则构成一样,所以这种方法又称为句法模式识别。用这种方法描述汉字字形结构是比较合适的,因此它在手写汉字的识别方面已经得到了应用。把统计识别方法与结构识别方法结合起来是近年来发展的一种趋势,它既可以吸取统计识别方法的优点,又可利用结构识别方法所得到的结构信息,可取得较好的识别效果。
另外,随着模糊数学及人工智能中某些领域研究的发展,人们已开始逐渐将其有关技术应用于模式识别的各个环节之中。尤其是人工神经网络所取得的成就以及它与模式识别的结合,使模式识别的研究进人了一个新的发展阶段,出现了模糊模式识别及智能模式识别的提法。
接下来,我们将对统计模式识别、结构模式识别、模糊模式识别及智能模式识别进行讨论。
有关“统计模式识别”的内容:统计模式识别理论与方法-CSDN博客
结构模式识别通过分析模式的结构信息,将复杂模式分解为基本单元(基元),并利用文法规则描述基元间的组合关系,从而实现对模式的描述、分类与分析。相较于统计模式识别侧重数值特征的统计分布,结构方法更关注模式的层次化结构和句法规则,适用于图像、语言、化学分子等具有明显结构特征的领域。
一、结构模式识别的基本过程
结构模式识别的核心是从“基元”到“模式”的层次化解析,其基本流程包括预处理与分割、基元抽取、文法建模、句法分析与识别四个关键步骤。
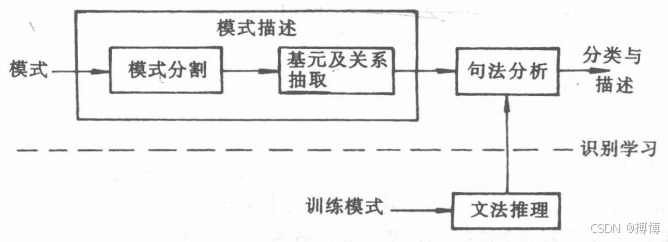
在上图中,模式分割用于将模式划分为若干子模式;基元及关系抽取用于选择并抽取基
元和基元间的关系,并按事先制订的语法或合成规则把模式用基元及其组合表示出来,例如可借助于链操作,把模式用一串链接起来的基元表示;句法分析用于对模式作句法检查,以判定它是按何种句法合成的,从而实现对它的识别。
在结构模式识别中,由于模式要被划分为子模式,子模式又被划分为基元,然后再由基元、子模式按某种合成规则把模式表示出来,这类似于语言中由字构成词,由词构成句子的过程。因此人们就在模式的结构和语言的文法之间建立起一种类推关系,把对模式的识别通过用一组给定的句法规则对模式结构进行句法分析来实现。通常一个文法表示一个模式类,上图中的句法分析就是用来判定当前待识别的模式遵循哪个文法,从而确定它应属哪一类的。一类模式的结构信息需要用一个文法来描述,以指出它与其它类的区别。为了得到文法,
就需要给它提供一组训练模式,使之通过推理进行学习,最后归纳出文法,这类似于统计模式识别中用训练模式来训练判决函数,图中的文法推理就是起这个作用的。
(一)预处理与分割
1. 目标:
将原始数据(如图像、符号序列)转换为可解析的结构化单元,去除噪声并分割出潜在基元。
2. 技术手段:
(1)图像预处理:
边缘检测(Canny算子、Sobel算子)提取轮廓:
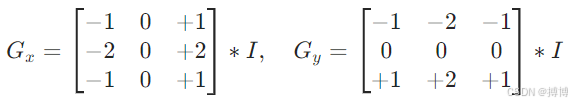
边缘强度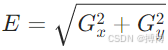 ,方向
,方向![]() 。
。
二值化与形态学操作(膨胀、腐蚀)连接断裂边缘。
(2)序列分割:
对符号序列(如DNA序列)进行分词,例如通过空格、标点或特定规则分割为基元候选。
3. 示例:手写数字“7”的预处理
输入28×28灰度图像,二值化得到黑白图像 B。
应用Sobel算子检测边缘,得到边缘图 E,其中“7”由两条直线段组成(水平段和右斜段)。
(二)基元抽取与表示
1. 基元(Primitive)定义:
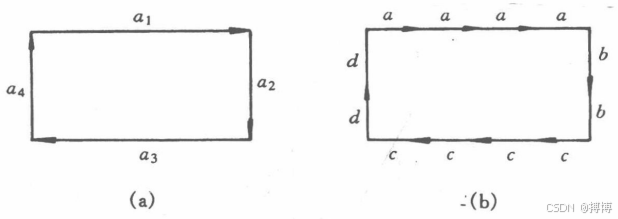
基元是构成模式的基本成分,对模式的识别起着重要作用,这就要求对基元的选择既要有利于对模式的识别,又能方便地进行抽取。但这是很难两全的,例如,笔划被认为是描述手写体汉字的较好基元,但它却不易被机器所抽取。因此,只能在这两者之间进行折衷。另外,由于受到模式自身的特征、用途、技术可行性等因素的影响,基元可在不同的情况下有不同的选择,没有固定的方法。例如,对图(a)所示的矩形,若不考虑每条边的长度,则可选用四条边作为基元,并且把该矩形用链接法表示为a1+a2+a3+a4。但若还要考虑每条边的长度,此时基元只能是边上的单位长度,对图(b)用链接法可表示为a+a+a+a+b+b+c+c+c+c+d+d。
基元是不可再分的最小结构单元,分为视觉基元(如图像中的线段、弧、角)和符号基元(如语言中的单词、化学中的化学键)。
视觉基元分类(以图像为例):
(1)按几何形状:直线段(→)、圆弧(⌒)、拐点(\corner)。
(2)按方向:定义8个方向基元![]() ,对应 0°、45°、…、315°。
,对应 0°、45°、…、315°。
2. 基元抽取算法:
(1)边缘跟踪法:从边缘图中提取连续边缘段,按方向变化点分割为基元。
算法步骤:
1)找到边缘起点 (x_0, y_0)。
2)沿边缘方向逐像素跟踪,记录方向序列 {d_i}。
3)当方向变化超过阈值(如30°)时,分割当前基元,开始新基元。
(2)符号化方法:将数值特征转换为符号,如将边缘方向量化为4个主方向 {→, ↗, ↑, ↖}。
3. 基元表示形式:
(1)符号表示:如 a, b, c 代表不同基元。
(2)属性向量:基元附带属性(长度、方向、曲率),如直线段基元表示为 (d, l, θ),其中 d 为类型,l 为长度,θ为方向角。
4. 示例:手写数字“7”的基元抽取
(1)边缘跟踪得到两条连续线段:
基元 1:水平线段(方向0°,长度15像素),符号 a。
基元 2:右斜线段(方向45°,长度20像素),符号 b。
(2)基元序列为 a → b(水平段后接右斜段)。
(三)文法建模(模式描述)
1. 形式文法(Formal Grammar)定义:
在结构模式识别中,人们希望有一种具有学习功能的推理机,它可以自动地从给定的模式集合中推断出文法来,但目前还缺少可达到这一目标的算法,因此当今多数情况下还需要设计者自己来设计所需要的文法。下面简要介绍一种称为串文法的一维文法,它又称为链文法。
文法 G = (V_T, V_N, S, P),其中:
V_T:终结符集合(基元符号,如 {a, b, c})。
V_N:非终结符集合(中间变量,如 {S, A, B},表示模式类别或子结构)。
S ∈ V_N:起始符,表示整个模式。
P:产生式规则集合(非空有限集),每个产生式有形式为 α→β,其中![]() 。
。
2. 文法类型(乔姆斯基层次):
| 类型 | 规则限制 | 对应自动机 | 应用场景 |
| 0 型 | 无限制文法 | 图灵机 | 理论研究 |
| 1 型 | 上下文有关文法(CSG) | 线性有界自动机 | 复杂结构(如自然语言) |
| 2 型 | 上下文无关文法(CFG) | 下推自动机 | 树形结构(如程序语言) |
| 3 型 | 正则文法(RG) | 有限状态自动机 | 字符串(如 DNA 序列) |
3. 模式文法构造示例:
手写数字“7”的正则文法:
(1)V_T = {a, b}(a 为水平段,b 为右斜段)
(2)V_N = {S}(起始符表示数字“7”)
(3)产生式 P:S → a b(“7”由水平段后接右斜段构成)
更复杂的上下文无关文法(用于描述带分支结构的模式):
描述化学分子式![]() :
:![]() (ϵ 表示空串)
(ϵ 表示空串)
所谓“与上下文有关”,实际上是指仅当非终止符A出现在子串α1、α2的上下文之间时,才能被重写为β。而所谓“与上下文无关”是指允许非终止符A被串α替换,不考虑其上下文。在模式识别中,经常用到上下文有关文法及上下文无关文法,它们都可以在有穷步内判定一个模式是否属于某个确定的类别。
(四)句法分析与识别
1. 目标:
判断输入基元序列是否符合文法规则,即是否属于某个模式类,并解析其结构。
2. 句法分析算法:
正则文法:有限状态自动机(FSM)
状态转移图:初始状态 q_0,接收基元符号转移状态,终止状态 q_f 表示合法模式。
示例:正则文法 S → a S | b 的FSM:
(1)状态:q_0(初始),q_1(接收 a),q_f(接收 b,终止)
(2)转移:![]()
上下文无关文法:CYK 算法(Cocke-Younger-Kasami)
动态规划方法,构建 n×n 表格 T[i,j],表示从位置 i 到 j 的子串可由哪些非终结符推导。
算法步骤(输入串 w = x_1x_2... x_n):
(1)初始化:![]() (长度 1 的子串)。
(长度 1 的子串)。
(2)递推:对长度 l=2 到 n,计算
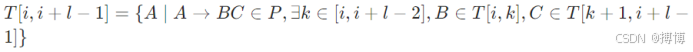
。
(3)判定:若 S ∈ T[1,n],则输入串合法。
3. 示例:CYK算法分析字符串ab**
文法 P: S → AB, A → a, B → b
(1)表格初始化:T[1,1] = {A}, T[2,2] = {B}
(2)长度 2:T[1,2] = {S}(因 S → AB,A∈T[1,1], B∈T[2,2])
(3)判定:S∈T[1,2],合法。
二、基元抽取与模式文法的深度解析
(一)基元设计的关键问题
1. 基元的选择原则:
(1)完备性:基元集合能表示所有目标模式(如识别手写数字需包含直线、曲线等基元)。
(2)独立性:基元间无冗余(如避免同时定义“水平线”和“0°方向线段”作为不同基元)。
(3)可分割性:能通过预处理算法可靠提取(如边缘检测后的连续线段)。
2. 基元属性的数学建模:
设基元 p 具有属性向量![]() ,如:
,如:
(1)线段基元:长度 l、方向θ、曲率κ(直线曲率为 0)。
(2)符号基元:词性(名词、动词)、语义类别(如WordNet中的概念标签)。
3. 基元抽取的不确定性处理:
当边缘分割存在噪声时,引入模糊基元,定义基元属于某类别的隶属度函数:
![]()
例如,某边缘段可能以0.8属于“直线”基元,0.2属于“曲线”基元。
(二)模式文法的扩展与应用
1. 树状文法(Tree Grammar):
用于描述层次化结构(如语法树、组织结构图),产生式规则定义父节点与子节点的关系:Sentence → NP、VP NP → Det Noun (NP = 名词短语,VP = 动词短语,Det = 冠词)
2. 图文法(Graph Grammar):
处理图结构模式(如电路图、分子结构),基元为图的节点和边,规则定义子图的替换:
(1)节点标签:V_T = {C, H, O}(化学元素)
(2)边标签:{单键, 双键}
(3)产生式:苯环结构 C-C-C-C-C-C(环状单双键交替)
3. 文法推断(Grammar Inference):
从样本集合中自动学习文法规则,分为生成式推断(学习产生式)和分析式推断(学习自动机状态转移)。
正则文法推断算法:
(1)收集正例(属于某类的基元序列)和反例(不属于的序列)。
(2)构建最小确定有限自动机(DFA),通过合并等价状态简化规则。
三、模式的识别与分析
(一)句法分析中的歧义与容错
1. 歧义处理:
当同一基元序列可被多个文法规则推导时(如自然语言中的结构歧义),需引入优先级规则或统计消歧:![]()
选择后验概率最大的文法 G_i。
2. 错误校正:
允许输入序列存在少量基元错误或缺失,通过编辑距离定义校正代价:
(1)基元操作:插入、删除、替换,代价分别为 c_i, c_d, c_r。
(2)校正后的最小代价路径:
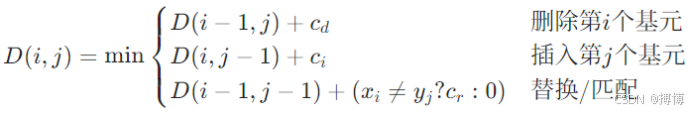
3. 示例:校正错误基元序列aab到合法序列ab**
假设 c_d = c_i = c_r = 1,编辑距离 D(3,2) = 1(删除第二个 a),判定为“7”类。
(二)结构匹配与模式分析
1. 树结构匹配:
计算两棵树的同构或最大公共子树,用于XML文档比对、程序代码克隆检测。
树编辑距离:节点插入、删除、替换的最小代价,递归定义:
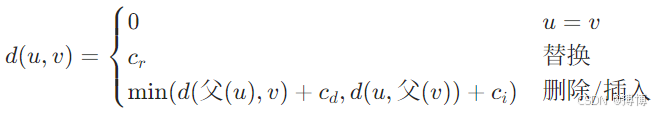
2. 图结构分析:
(1)子图同构:判断图 G1 是否包含与 G2 同构的子图,用于化学分子相似性检索。
(2)图不变量:计算图的特征值(如邻接矩阵的特征向量),转化为统计特征进行分类。
3. 示例:化学分子结构匹配
目标:检测分子图中是否存在苯环结构(6节点环状图,单双键交替)。
(1)提取分子图的邻接矩阵 A 和边标签矩阵 E。
(2)搜索所有6节点环,检查边标签是否符合单双键交替规则。
(三)结构模式识别与统计方法的结合
1. 混合模型:
(1)属性文法(Attribute Grammar):为文法规则附加数值属性,如基元的长度、角度作为约束条件:![]()
(2)随机文法(Stochastic Grammar):为产生式规则赋予概率,如 S → A B (0.7), S → C (0.3),结合统计概率进行模糊识别。
2. 应用案例:手写汉字识别
(1)基元层:提取笔画基元(横、竖、撇、捺),表示为带方向和长度的属性向量。
(2)文法层:上下文无关文法定义笔画间的结构关系(如“横”在“竖”上方,距离< 5像素)。
(3)识别层:CYK 算法结合属性约束,排除不符合结构规则的候选类别。
四、理论拓展与应用前沿
(一)结构模式识别的数学基础
1. 形式语言理论:
(1)乔姆斯基范式:将上下文无关文法转换为二叉树结构(A → BC 或 A → a),便于句法分析。
(2)泵引理:用于证明某个语言不属于某类文法(如证明非正则语言)。
2. 自动机理论:
(1)有限状态自动机(DFA/NFA)与正则文法的等价性:每个正则文法对应一个DFA,反之亦然。
(2)下推自动机(PDA)的栈机制用于处理上下文无关文法的递归结构。
(二)前沿应用领域
1. 生物医学工程:
(1)蛋白质结构分类:将蛋白质二级结构(α- 螺旋、β- 折叠)作为基元,用树文法描述三级结构。
(2)心电图波形分析:提取P波、QRS波、T波作为基元,用正则文法识别异常心律模式。
2. 计算机视觉:
(1)场景解析:将图像分割为物体(基元),用图文法描述物体间的空间关系(如“桌子上有杯子”)。
(2)手势识别:将手部关节运动轨迹分解为方向基元,用动态文法识别连续手势(如“挥手”“点赞”)。
3. 自然语言处理:
(1)句法分析:构建上下文无关文法解析句子结构,生成句法树(如Penn Treebank标注)。
(2)低资源语言处理:通过文法推断从少量语料中学习形态规则(如黏着语的词法分析)。
(三)挑战与未来方向
(1)高噪声环境下的基元分割:如何在复杂背景中准确提取基元(如遥感图像中的道路网分割)。
(2)动态结构处理:针对视频、时序数据,设计支持时间维度的动态文法(如事件序列的因果关系建模)。
(3)可解释性与深度学习结合:将神经网络提取的深层特征映射到结构基元,实现“端到端 + 可解释”的模式识别(如视觉问答中的句法 - 语义联合解析)。
五、总结
结构模式识别通过“基元 - 文法 - 句法分析”的三层架构,为具有层次化结构的模式提供了清晰的语义解析框架。从正则文法处理简单字符串到上下文无关文法解析复杂树结构,其核心优势在于对模式内部结构关系的显式建模。未来研究需聚焦于噪声鲁棒性、动态结构处理及与统计学习的深度融合,推动结构方法在跨模态、高维复杂数据中的应用,实现从“识别模式”到“理解结构”的跨越。