编译原理实验二:构建TINY语言的词法分析器
实验二 构建TINY语言的词法分析器
- 一、实验目的
- 二、实验要求
- 预习阶段
- 上机操作阶段
- 实验报告阶段
- 三、实验内容
- (一)熟悉FLEX工具
- (二)明确TINY语言词法规则
- (三)编写FLEX源程序
- (四)编写测试程序
- (五)调试与优化
- (六)记录与分析结果
- 四、拓展知识
- (一)词法分析器生成工具的多样性
- (二)词法分析的优化策略
- (三)词法分析在实际编程语言中的应用与挑战
- 五、示例代码
- 六、操作步骤
- 七,实验结果
一、实验目的
- 深入理解FLEX机制:通过构建TINY语言词法分析器,深入探究FLEX在词法分析过程中的工作原理,包括其如何依据正则表达式匹配输入字符流、如何管理状态转移以及如何将输入字符序列识别为词法单元。
- 熟练掌握词法分析器生成方法:熟练掌握使用FLEX工具生成词法分析器的具体流程和方法,涵盖FLEX源程序的编写规范、正则表达式的准确运用、动作代码的合理编写等,从而能够针对不同的编程语言需求,灵活运用FLEX构建高效、准确的词法分析器。
- 强化对TINY语言的认识:借助对TINY语言源程序的词法分析,加深对TINY语言词法结构的理解,清晰把握TINY语言中各类单词(如关键字、标识符、常量等)的特征和规则,为后续TINY语言的语法分析和语义处理奠定坚实基础。
- 提升问题解决与实践能力:在实验过程中,面对可能出现的各种问题,如正则表达式匹配错误、词法分析器生成失败、分析结果不准确等,通过自主思考、查阅资料、调试程序等方式进行解决,从而有效提升自身的问题解决能力和编程实践能力。
二、实验要求
预习阶段
- 全面查阅资料:广泛收集并研读与FLEX工具相关的技术文档、教程、案例等资料,充分了解FLEX的功能特性、使用方法和常见应用场景;同时,深入学习TINY语言的词法规则和语法规范,明确TINY语言中各类单词的定义和构成方式。
- 撰写预习报告:在充分学习和理解的基础上,认真撰写实验预习报告。报告内容应涵盖FLEX的基本工作原理概述、TINY语言词法规则总结、初步设计的FLEX源程序框架(包括正则表达式和动作代码的初步构思)以及对实验过程中可能出现问题的预估和解决方案设想。
上机操作阶段
- 精心编写FLEX源程序:依据TINY语言的词法规则,使用FLEX语言规范准确编写FLEX源程序。在程序中,精心设计正则表达式以精准匹配TINY语言中的各类单词,合理编写动作代码,确保在识别到单词后能够正确生成相应的二元组(如单词类别、单词值),并将其以规定格式显示到屏幕上。同时,对程序进行全面细致的注释,增强程序的可读性和可维护性。
- 编写测试程序:精心挑选或自行构造具有代表性的TINY语言源程序作为测试用例,涵盖TINY语言中的各种语法结构和单词类型,确保测试的全面性和有效性。编写测试程序,将TINY语言源程序输入到用FLEX生成的词法分析器中进行分析,并对分析结果进行详细记录和整理。
- 反复调试优化:对编写好的FLEX源程序和测试程序进行反复调试。当出现匹配错误、分析结果不准确等问题时,运用调试工具和方法,仔细排查问题根源,对程序进行针对性修改和优化,直至词法分析器能够准确无误地对TINY语言源程序进行词法分析,并正确输出单词的二元组信息。
实验报告阶段
- 完整呈现实验过程:在实验报告中,详细、准确地记录实验的全过程,包括实验目的、实验要求、实验原理(阐述FLEX工作原理以及TINY语言词法规则与词法分析器构建的关系)、实验步骤(详细描述FLEX源程序的编写思路、测试程序的设计方法以及调试过程中遇到的问题和解决方案)。
- 展示实验结果:完整展示词法分析器对测试用例的分析结果,以表格或文本形式清晰呈现识别出的单词及其对应的二元组信息。同时,对实验结果进行客观、深入的分析和讨论,对比预期结果与实际结果,剖析出现差异的原因,总结实验过程中的经验教训和收获。
- 规范报告格式:严格按照规定的格式和要求撰写实验报告,确保报告内容完整、条理清晰、语言准确、排版规范。报告应包含封面、目录、正文、参考文献等部分,各部分内容应相互呼应、逻辑连贯。
三、实验内容
(一)熟悉FLEX工具
- 深入学习工具特性:系统学习FLEX工具的基本功能、操作命令和使用方法,详细了解其如何将用户编写的正则表达式和动作代码转换为高效的词法分析器,以及在词法分析过程中如何进行状态管理和输入处理。
- 研读官方文档和示例:仔细研读FLEX的官方文档和相关示例代码,深入理解FLEX源程序的结构组成(如声明部分、规则部分、用户代码部分)、正则表达式的语法规则和匹配机制、动作代码的编写规范和执行逻辑。通过对示例代码的分析和模仿,初步掌握FLEX的编程技巧和应用方法。
(二)明确TINY语言词法规则
- 梳理单词类型:全面梳理TINY语言中的单词类型,明确其包括关键字(如“if”“then”“else”“while”等)、标识符(由字母开头,由字母和数字组成的字符串)、常量(整型常量等)、运算符(如“+”“-”“*”“/”“=”等)、界符(如“(”“)”“;”等)。
- 总结规则细节:深入总结每种单词类型的具体构成规则和特征。例如,关键字是固定的保留字,具有特定的拼写形式;标识符需遵循特定的命名规则;常量具有特定的数据格式等。为后续编写FLEX源程序提供精确的规则依据。
(三)编写FLEX源程序
- 设计声明部分:在FLEX源程序的声明部分,准确定义用于匹配各类单词的正则表达式宏。例如,定义“[a-zA-Z][a-zA-Z0-9]*” 用于匹配标识符,“[0-9]+” 用于匹配整型常量等。同时,声明必要的变量和函数,用于存储和处理词法分析过程中的相关信息,如单词类别、单词值等。
- 编写规则部分:在规则部分,依据TINY语言的词法规则,精心编写正则表达式与动作代码的对应规则。对于每个单词类型,使用准确的正则表达式进行匹配,并在匹配成功时编写相应的动作代码,将识别出的单词转换为二元组形式(如使用自定义函数将单词类别和单词值组合成二元组),并通过标准输出函数将其显示到屏幕上。例如,对于关键字“if”,编写规则 “if { printf(“(关键字, if)\n”); }” 。
- 完善用户代码部分:在用户代码部分,编写必要的辅助函数和主程序逻辑。辅助函数可用于处理复杂的单词识别逻辑或对单词进行进一步的格式化处理;主程序逻辑主要负责调用FLEX生成的词法分析函数,启动词法分析过程,并进行必要的初始化和清理工作。
(四)编写测试程序
- 选择或构造测试用例:精心挑选或自行构造多个具有代表性的TINY语言源程序作为测试用例。测试用例应涵盖TINY语言中的各种语法结构和单词类型,包括简单的语句、复杂的控制结构、嵌套的表达式等,以全面检验词法分析器的准确性和可靠性。
- 编写测试逻辑:编写测试程序,将选定的TINY语言源程序逐个输入到用FLEX生成的词法分析器中。在输入过程中,合理设置输入方式(如文件输入或标准输入),并对词法分析器的输出结果进行详细记录和存储,以便后续进行分析和验证。
(五)调试与优化
- 排查错误:对编写好的FLEX源程序和测试程序进行全面调试。利用调试工具(如GDB等)或在程序中添加调试输出语句,仔细观察程序的执行过程和变量值的变化情况。当出现匹配错误、分析结果不准确或程序崩溃等问题时,深入排查问题根源,分析是正则表达式编写错误、动作代码逻辑错误还是其他方面的问题。
- 优化程序:根据调试过程中发现的问题,对FLEX源程序进行针对性修改和优化。调整正则表达式的匹配规则,使其更加精准地匹配各类单词;优化动作代码的逻辑,提高程序的执行效率和准确性;完善程序的错误处理机制,增强程序的健壮性。反复进行调试和优化,直至词法分析器能够准确、高效地对TINY语言源程序进行词法分析。
(六)记录与分析结果
- 记录输出信息:在词法分析器能够正确运行后,完整记录其对测试用例的分析结果。将识别出的单词及其对应的二元组信息以表格或文本形式详细记录下来,确保记录的准确性和完整性。
- 分析结果准确性:对记录的分析结果进行深入分析,与预期结果进行细致对比。检查是否存在单词识别错误、二元组生成错误或输出格式不符合要求等问题。对于发现的问题,认真分析原因,总结经验教训,为今后的词法分析工作提供参考。
四、拓展知识
(一)词法分析器生成工具的多样性
- 其他主流工具介绍:除FLEX外,还存在众多功能强大的词法分析器生成工具,如LEX(FLEX的前身,具有相似的功能和使用方式)、JFlex(适用于Java平台,能够生成Java代码实现的词法分析器)、ANTLR(不仅可用于词法分析,还可用于语法分析,支持多种编程语言,具有强大的语法描述能力和代码生成功能)等。深入了解这些工具的特点、优势和适用场景,有助于在不同的项目需求下选择最合适的工具。
- 工具对比与选择策略:对不同词法分析器生成工具进行全面对比,从功能特性(如正则表达式支持程度、代码生成效率、错误处理能力等)、性能表现(如分析速度、内存占用等)、易用性(如学习曲线、文档丰富度等)、与其他工具的集成性(如是否便于与语法分析工具、编译器后端等集成)等多个维度进行分析。根据具体项目的需求和约束条件(如编程语言、项目规模、开发周期等),制定合理的工具选择策略,以提高开发效率和质量。
(二)词法分析的优化策略
- 算法优化:在词法分析过程中,可采用多种算法优化技术。例如,使用有限自动机的最小化算法(如Hopcroft算法)对由正则表达式转换得到的有限自动机进行优化,减少状态数量,降低空间复杂度,提高词法分析的效率;采用并行计算技术,将输入字符流划分为多个部分,在多核处理器上并行执行词法分析任务,加快分析速度。
- 数据结构优化:合理选择和优化数据结构对词法分析性能至关重要。例如,使用哈希表存储关键字,可实现快速的关键字查找,提高单词识别效率;采用压缩数据结构(如前缀树的压缩形式)存储标识符,减少存储空间占用,同时保持高效的查找和匹配性能。
- 代码生成优化:在词法分析器生成工具生成代码后,可对生成的代码进行手工优化。例如,对频繁执行的代码段进行内联展开,减少函数调用开销;合理运用编译器优化选项,对生成的代码进行编译优化,提高代码的执行效率。
(三)词法分析在实际编程语言中的应用与挑战
- 应用实例剖析:深入剖析实际编程语言(如C、Java、Python等)中词法分析的具体实现方式和应用场景。例如,C语言的词法分析器如何处理预处理器指令、字符串常量和注释;Java语言的词法分析器如何与语法分析器协同工作,实现对复杂语法结构的准确识别;Python语言的词法分析器如何处理动态类型和缩进敏感的特性。通过对这些实例的分析,了解词法分析在不同编程语言中的特点和差异。
- 面临的挑战与应对措施:探讨词法分析在实际应用中面临的挑战,如处理不规则的词法规则(如自然语言处理中的文本分析,单词拼写和格式具有很大的灵活性)、应对大规模代码库的高效分析需求(如在大型软件项目中,需要快速准确地对大量代码进行词法分析)、解决跨语言和混合语言编程环境下的词法分析问题(如在C++/Python混合编程中,需要同时处理两种语言的词法规则)等。研究针对这些挑战的应对措施,如采用自适应词法分析技术、结合机器学习算法进行词法规则学习和优化等。
五、示例代码
shiyan2.l 源代码
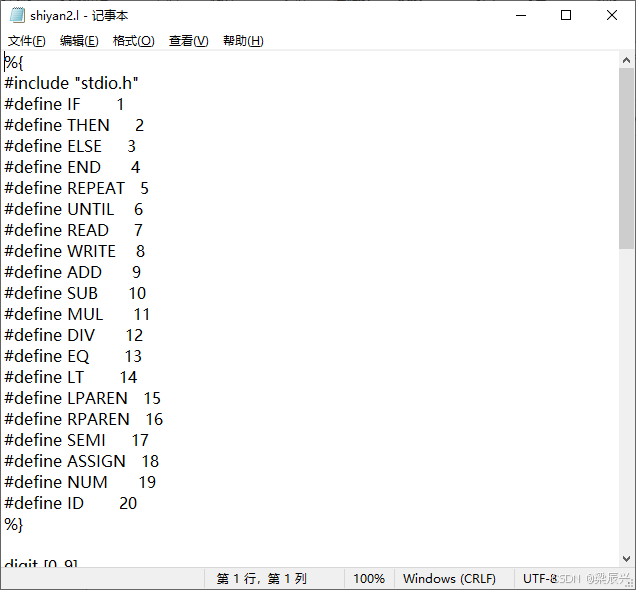
%{
#include "stdio.h"
#define IF 1
#define THEN 2
#define ELSE 3
#define END 4
#define REPEAT 5
#define UNTIL 6
#define READ 7
#define WRITE 8
#define ADD 9
#define SUB 10
#define MUL 11
#define DIV 12
#define EQ 13
#define LT 14
#define LPAREN 15
#define RPAREN 16
#define SEMI 17
#define ASSIGN 18
#define NUM 19
#define ID 20
%}digit [0-9]
number {digit}+
letter [a-zA-Z]
identifier {letter}+%%
if|IF { printf("(%d, %s)", IF, yytext); }
then|THEN { printf("(%d, %s)", THEN, yytext); }
else|ELSE { printf("(%d, %s)", ELSE, yytext); }
end|END { printf("(%d, %s)", END, yytext); }
repeat|REPEAT { printf("(%d, %s)", REPEAT, yytext); }
until|UNTIL { printf("(%d, %s)", UNTIL, yytext); }
read|READ { printf("(%d, %s)", READ, yytext); }
write|WRITE { printf("(%d, %s)", WRITE, yytext); }
"+" { printf("(%d, %s)", ADD, yytext); }
"-" { printf("(%d, %s)", SUB, yytext); }
"*" { printf("(%d, %s)", MUL, yytext); }
"/" { printf("(%d, %s)", DIV, yytext); }
"=" { printf("(%d, %s)", EQ, yytext); }
"<" { printf("(%d, %s)", LT, yytext); }
"(" { printf("(%d, %s)", LPAREN, yytext); }
")" { printf("(%d, %s)", RPAREN, yytext); }
";" { printf("(%d, %s)", SEMI, yytext); }
":=" { printf("(%d, %s)", ASSIGN, yytext); }
{number} { printf("(%d, %s)", NUM, yytext); }
{identifier} { printf("(%d, %s)", ID, yytext); }
\n { printf("\n"); }
. { ; }
%%int main()
{yylex();return 0;
}int yywrap()
{return 1;
}
六、操作步骤
1,将编写好的shiyan2.l存放到文件夹实验二中。
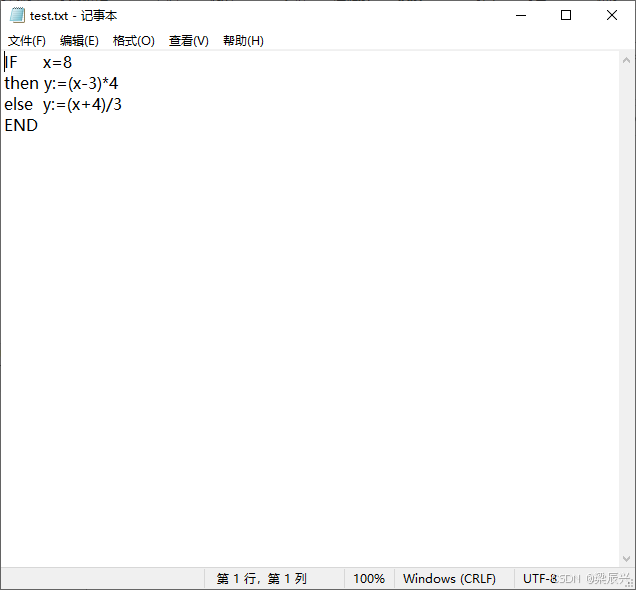
2,编写测试的文本文件。
IF x=8
then y:=(x-3)*4
else y:=(x+4)/3
END
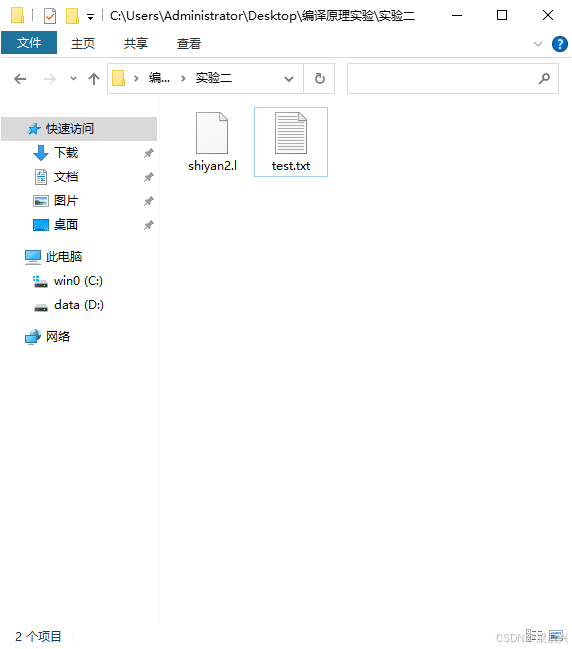
3,将两个文件均存放在实验二的文件夹中。
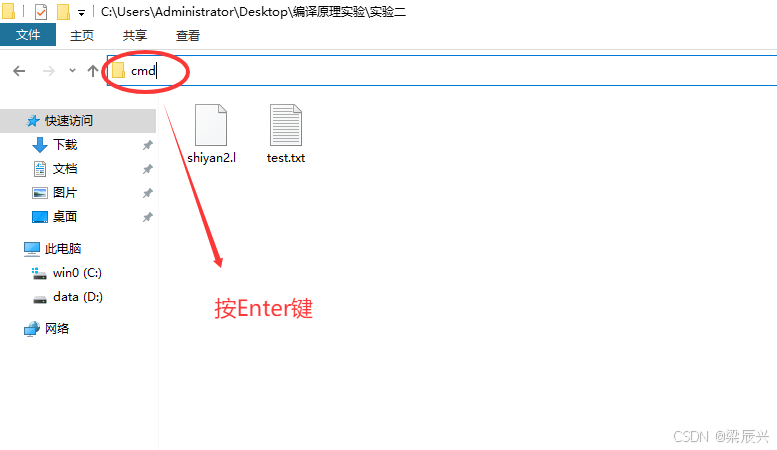
4,在实验二目录的地址栏中输入cmd,安回车键,打开命令行。
5,在命令行输入命令:flex shiyan2.l,生成词法分析器。
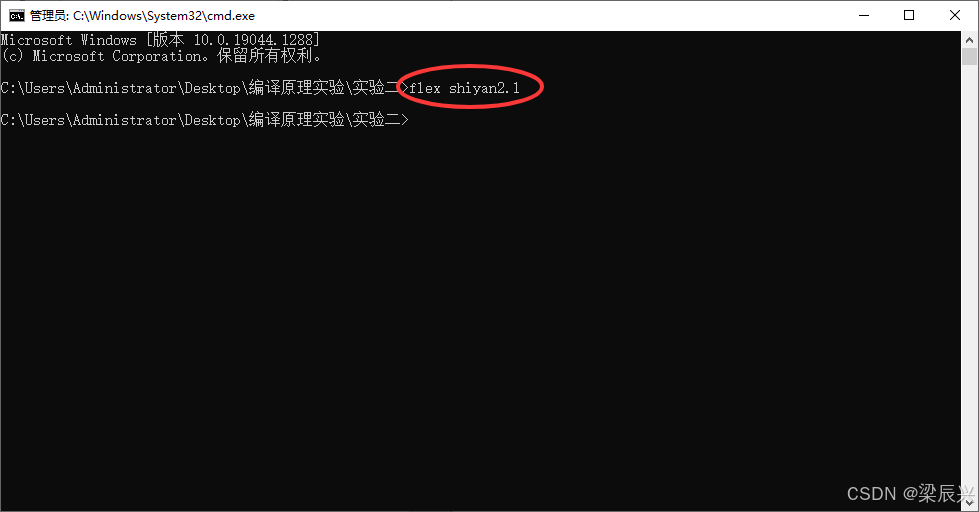
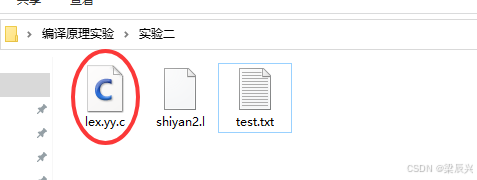
6,查看实验二目录,生成了一个c文件。
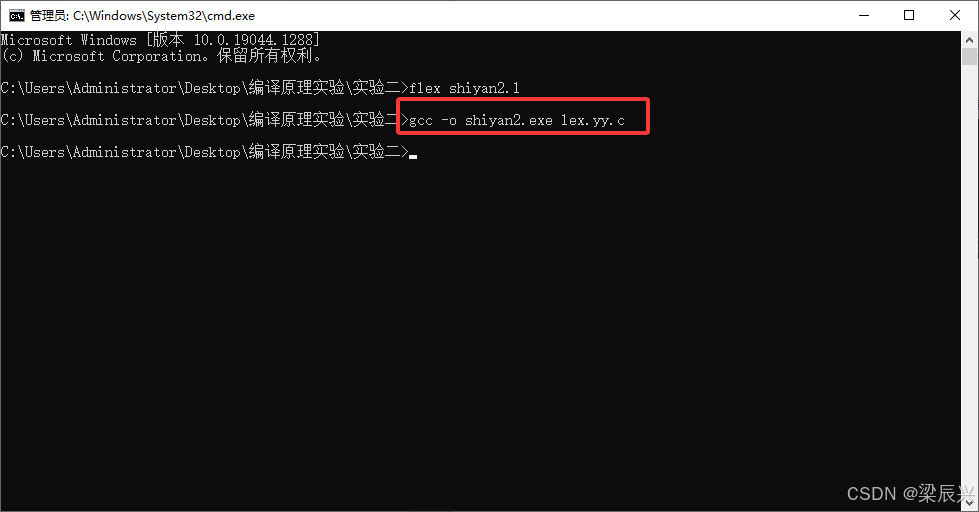
7,输入命令:gcc -o shiyan2.exe lex.yy.c,生成可执行文件。
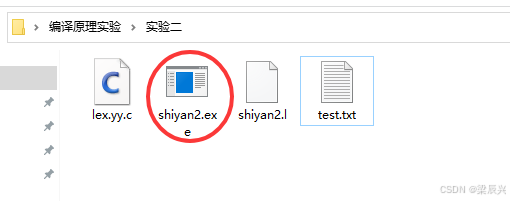
8,查看实验二目录,发现生成了一个exe的可执行文件。
9,输入命令:shiyan2.exe<test.txt,开始测试。
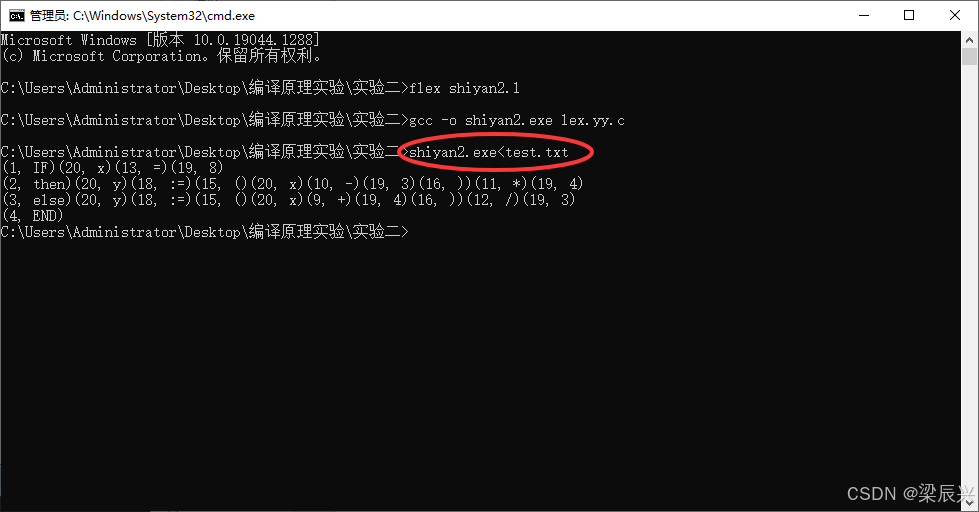
七,实验结果
