【Spark入门】Spark简介:分布式计算框架的演进与定位
目录
1 大数据计算框架的演进历程
1.1 Hadoop MapReduce:第一代分布式计算框架
1.2 Spark的诞生与革新
2 Spark的核心架构与优势
2.1 Spark架构概览
2.2 Spark的核心优势解析
3 Spark的适用场景与定位
3.1 典型应用场景
3.2 技术定位分析
4 Spark与Hadoop生态的关系
4.1 兼容与超越
4.2 共生的技术生态
5 总结
1 大数据计算框架的演进历程
大数据处理技术在过去十几年间经历了显著的演进过程,从最初的批处理系统发展到如今的实时流处理和多模式计算框架。这一演进过程反映了企业对数据处理需求的不断变化和技术能力的持续提升。
1.1 Hadoop MapReduce:第一代分布式计算框架

架构说明:
- 输入分片:将大数据集分割成固定大小的块(通常64MB或128MB)
- Map阶段:在各个节点上并行处理数据分片,生成键值对
- Shuffle阶段:按照键对Map输出进行排序和分组
- Reduce阶段:对分组后的数据进行聚合计算
- 输出结果:将最终结果写入HDFS或其他存储系统
MapReduce的局限性:
- 磁盘I/O瓶颈:每个MapReduce作业都需要将中间结果写入磁盘
- 编程模型复杂:需要手动编写Mapper和Reducer,开发效率低
- 实时性差:仅支持批处理模式,延迟通常在分钟级以上
- 迭代计算效率低:机器学习等需要多次迭代的算法性能不佳
1.2 Spark的诞生与革新
Spark最初由UC Berkeley AMPLab于2009年开发,2013年成为Apache顶级项目。它保留了MapReduce的可扩展性和容错性优点,同时通过以下创新解决了MapReduce的痛点:
| 特性 | Hadoop MapReduce | Apache Spark |
| 计算模式 | 基于磁盘 | 基于内存 |
| 延迟 | 高(分钟级) | 低(秒级) |
| 编程接口 | 低级API | 丰富的高级API |
| 执行引擎 | 单次执行 | DAG执行 |
| 迭代计算支持 | 差 | 优秀 |
| 实时流处理 | 不支持 | 支持 |
| 机器学习支持 | 有限 | 内置MLlib |
2 Spark的核心架构与优势
2.1 Spark架构概览
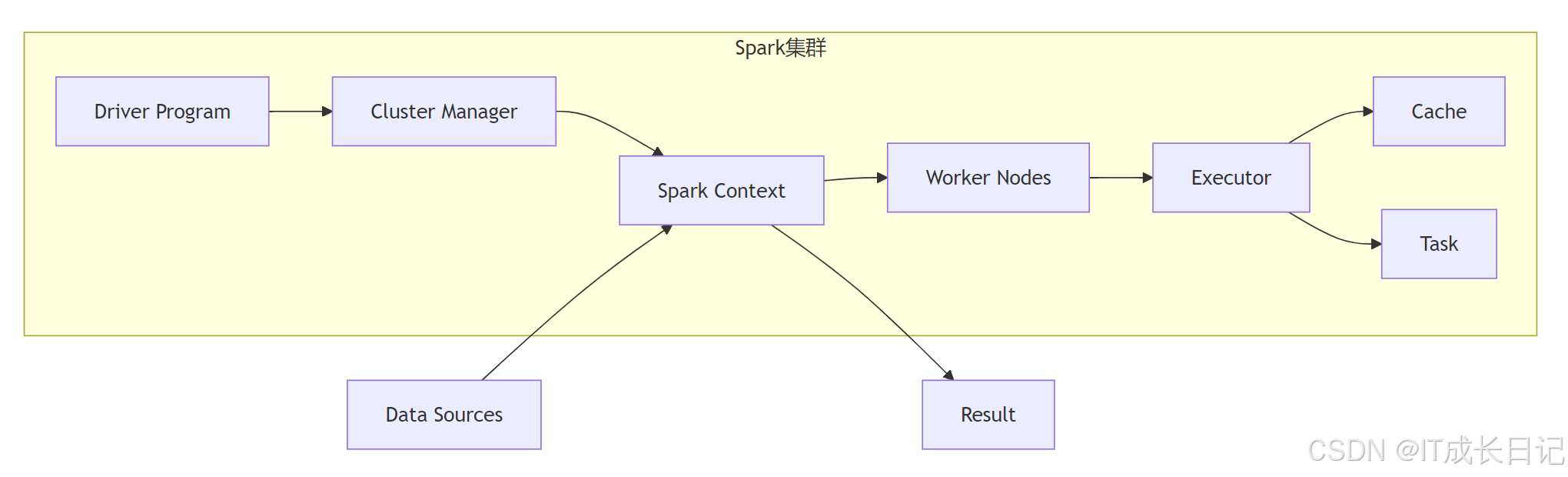
组件说明:
- Driver Program:运行用户应用程序的进程,包含SparkContext
- Cluster Manager:负责资源分配(Standalone/YARN/Mesos)
- Worker Node:执行计算任务的节点
- Executor:工作节点上的进程,执行具体任务并存储数据
- RDD:弹性分布式数据集(Resilient Distributed Dataset),Spark的核心数据抽象
2.2 Spark的核心优势解析
- 优势一:内存计算(In-Memory Computing)

关键概念:
- 弹性分布式数据集(RDD):不可变的分布式对象集合,支持故障恢复
- 惰性求值:转换操作(Transformation)不会立即执行,只有遇到动作操作(Action)时才触发计算
- 血统(Lineage):记录RDD的衍生过程,用于故障恢复而不需要数据复制
内存计算优势:
- 比MapReduce快10-100倍(官方基准测试)
- 迭代算法性能提升显著(如PageRank快20倍)
- 交互式查询响应时间从分钟级降到秒级
- 优势二:易用性与丰富的API
核心API:RDD操作(面向所有语言)结构化API:
- DataFrame(Python/R/Java/Scala)
- Dataset(Scala/Java)
高级库:
- Spark SQL
- Spark Streaming
- MLlib(机器学习)
- GraphX(图计算)
- 示例
# WordCount in Spark (Python)
text_file = sc.textFile("hdfs://...")
counts = text_file.flatMap(lambda line: line.split(" ")) \.map(lambda word: (word, 1)) \.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://...")- 优势三:统一的生态整合
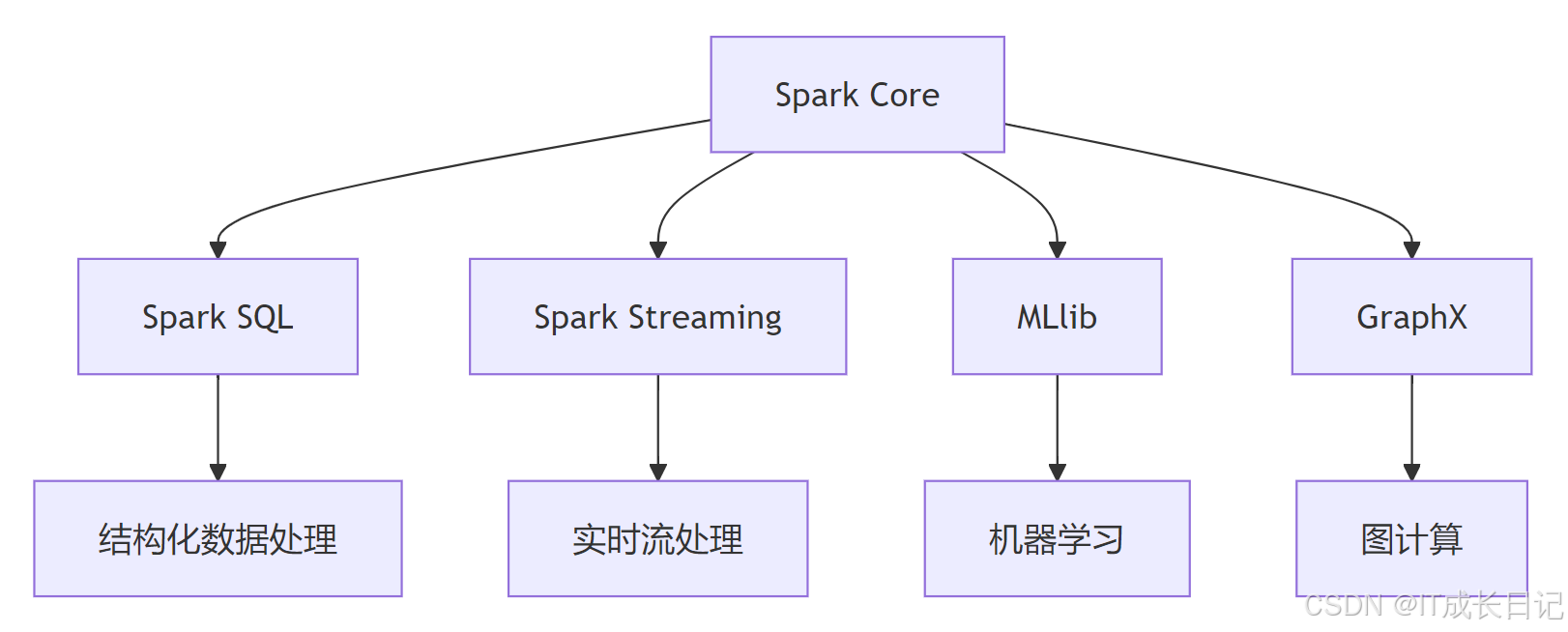
生态整合优势:一站式解决方案:批处理、流处理、机器学习、图计算统一平台数据源兼容性:
- 支持HDFS、HBase、Cassandra等大数据存储
- 支持JDBC连接传统数据库
- 支持Parquet、ORC、JSON等文件格式
部署灵活性:
- Standalone模式
- YARN/Mesos集群管理
- Kubernetes支持(Spark 2.3+)
3 Spark的适用场景与定位
3.1 典型应用场景
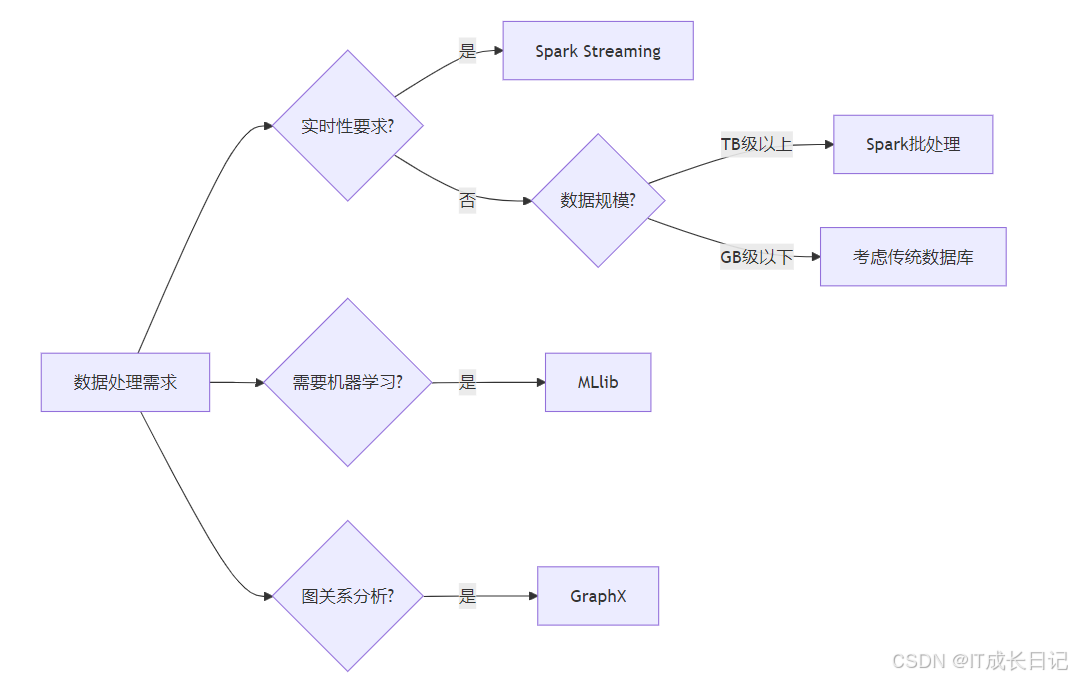
主要应用领域:
- ETL管道:大规模数据转换和加载
- 数据湖分析:对原始数据执行探索性分析
- 实时仪表盘:流数据处理和实时可视化
- 机器学习:特征工程、模型训练和预测
- 图分析:社交网络分析、推荐系统
3.2 技术定位分析
Spark的独特定位:
- 性能与易用性的平衡点:比MapReduce快,比Storm/Flink更易用
- 批流统一的处理能力:通过微批(Micro-batch)实现准实时处理
- 内存计算先驱:推动了整个大数据生态向内存计算演进
- 学术与工业界的桥梁:既适合研究原型开发,也支持生产部署
4 Spark与Hadoop生态的关系
4.1 兼容与超越
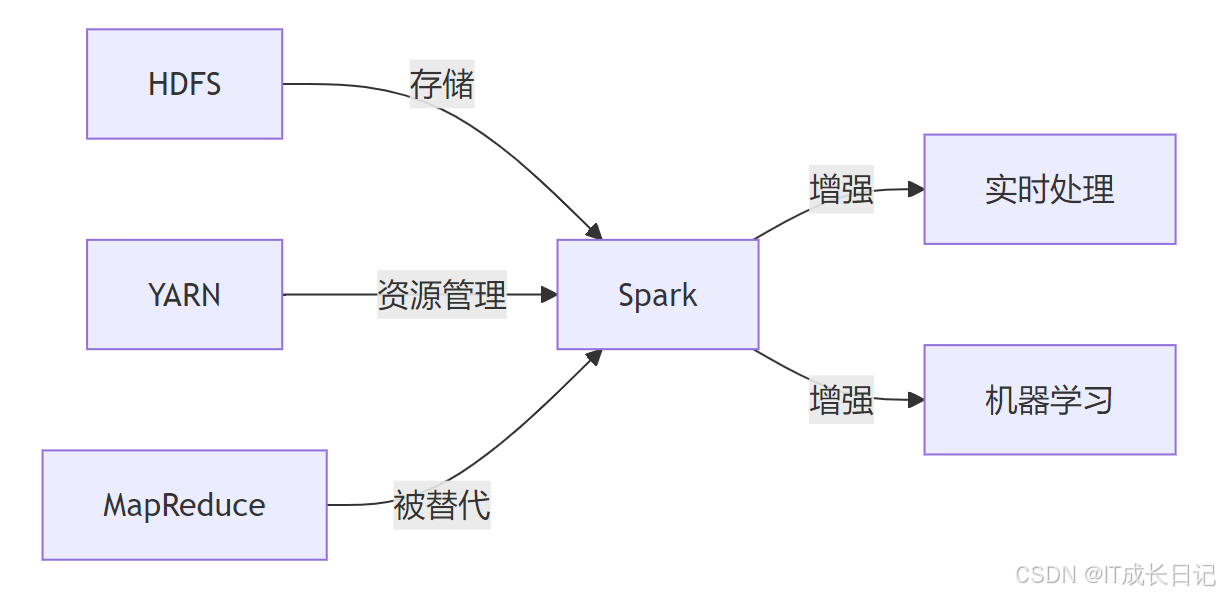
- 存储层兼容:Spark可以无缝使用HDFS作为存储后端
- 资源管理兼容:支持YARN作为集群资源管理器
- 计算层替代:Spark成为更高效的MapReduce替代品
- 功能扩展:提供了Hadoop生态原先缺乏的实时处理和机器学习能力
4.2 共生的技术生态
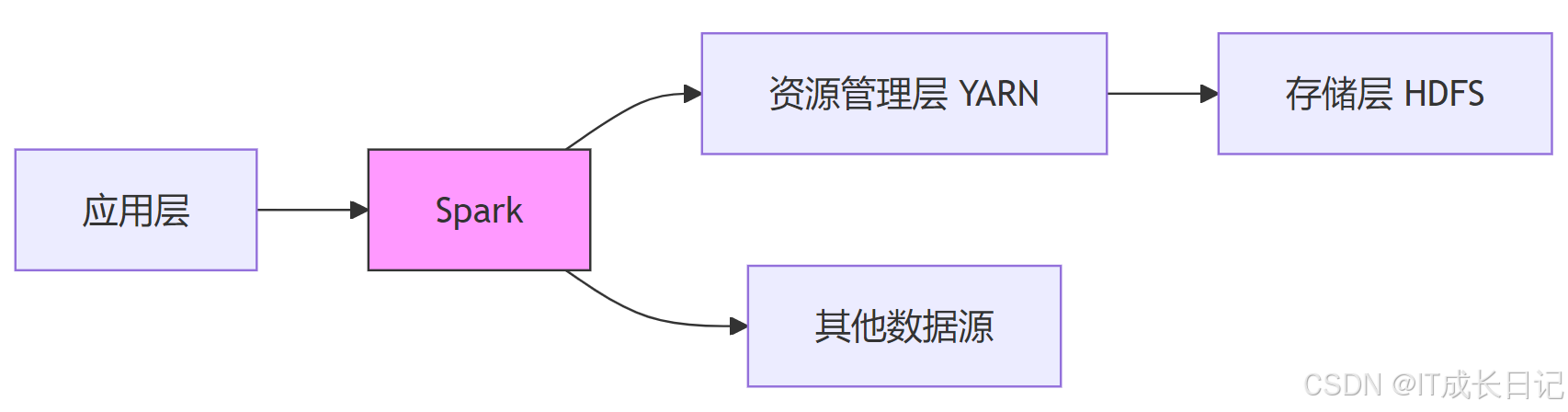
- 独立部署:小规模集群可使用Spark Standalone
- 混合部署:大规模生产环境通常与YARN/HDFS共存
- 云原生部署:Spark on Kubernetes逐渐成为新趋势
5 总结
Apache Spark作为第二代大数据计算框架的典型代表,通过内存计算、丰富的API和统一生态三大核心优势,成功解决了Hadoop MapReduce的主要痛点,推动了大数据处理能力的显著提升。
Spark持续创新:
- 结构化流(Structured Streaming)不断完善
- Koalas项目实现更好的Pandas兼容性
- GPU加速支持提升深度学习性能
生态融合发展:
- 与Delta Lake等数据湖技术深度整合
- 增强与AI生态(TensorFlow/PyTorch)的互操作性
- 云原生支持持续改进
新兴挑战者:
- Flink在纯流处理领域的竞争
- Ray在分布式AI场景的崛起
- 云厂商托管服务的替代效应
作为大数据工程师,理解其设计理念和核心优势,有助于我们在实际项目中做出合理的技术选型,并充分发挥Spark在大数据处理中的潜力。