【音视频】WebRTC-NetEQ 分析
参考文章:https://mp.weixin.qq.com/s/AvmwuIqsKHfUo3i5JoCUbw
一、NetEQ 简介
NetEQ 本质上就是一个音频的 JitterBuffer(抖动缓冲器),全称是 Network Equalizer(网络均衡器),
GIPS 语音引擎的两大核心技术之一就是包含丢包隐藏算法的高级自适应抖动缓冲器技术,称作 NetEQ。2010 年谷歌公司以6820万美元收购Global IP Solutions公司而获得的这项技术,另一个核心技术就是3A算法。随后,谷歌在2011年将其集成到 WebRTC 中对外开源发布。
NetEQ 集成了自适应抖动控制算法和语音丢包隐藏算法,并且与解码器进行集成,所以 NetEQ 能够在较高的丢包环境下始终能够保持较好的语音质量。
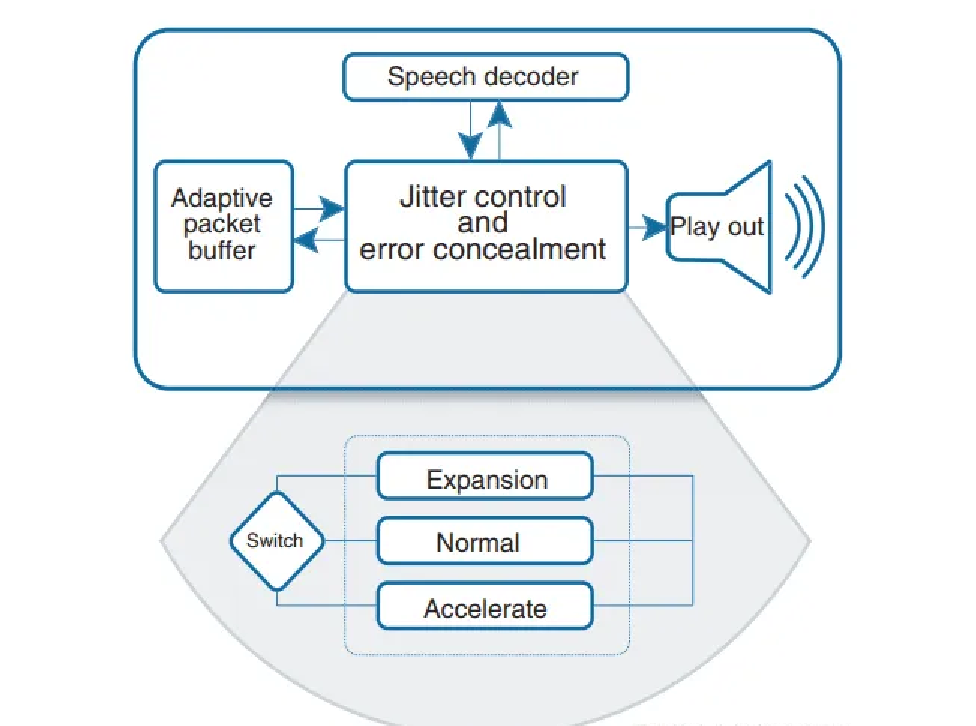
上图是NetEQ的模块框图,包括自适应缓冲器( Adaptive packet buffer)、语音解码器(Speech decoder)、抖动控制和丢包隐藏模块(Jitter control and error concealment)及播放(Play out)四大模块,其中最核心的就是抖动控制和丢包隐藏模块。
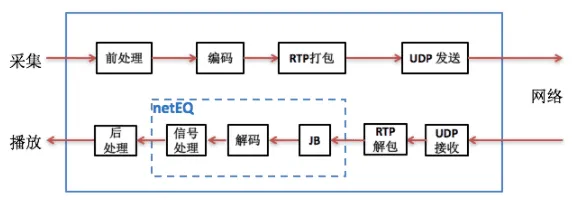
NetEQ在整个音频处理流程的位置如下图所示:
1.1 NetEQ的主要特性
- 大幅大度的提高语音质量
- 最小化抖动缓冲带来的延时影响,相比于最好的动态自适应抖动缓冲技术,NetEQ可以降低延时30~80ms
- 只需要部署在语音接收端
- 减少需要的网络配置
- 能够与所有标准的语音编码器兼容
1.2 自适应网络抖动估计
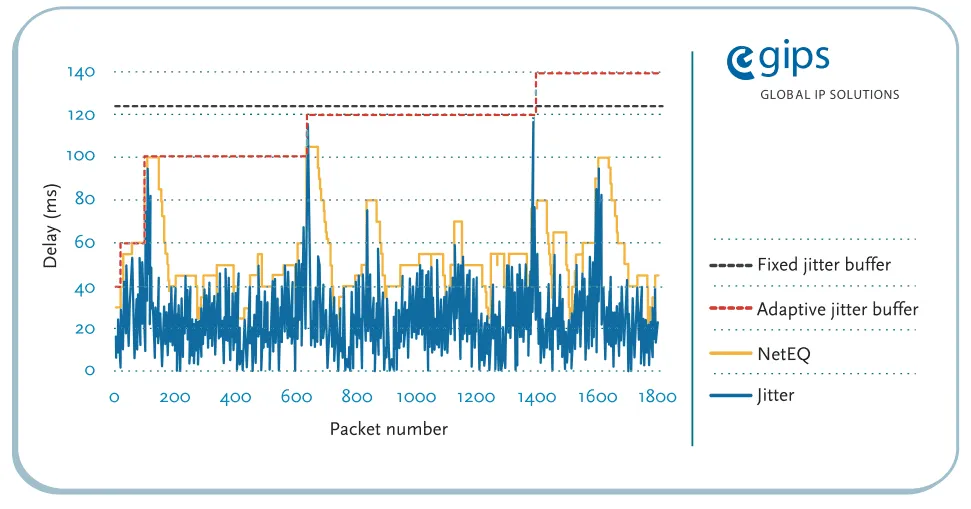
其中蓝色的线是网络延时,黄色的线就是NetEQ针对抖动做出的响应:
-
与传统的自适应网络抖动缓冲区设计相比,NetEQ实现了独特的非时序的处理机制。通过智能的抖动缓冲区调节机制和PLC(Packet Loss Concealment)成了一个独立的处理单元,NetEQ会探测当前的延时变化并在语音播放之前修正语音错误,从而产生高质量的语音信号。
-
NetEQ实现的高灵敏度的抖动缓冲区调节机制能够快速适应变换的输入抖动,并且其处理十分的高效
二、NetEQ 整体架构
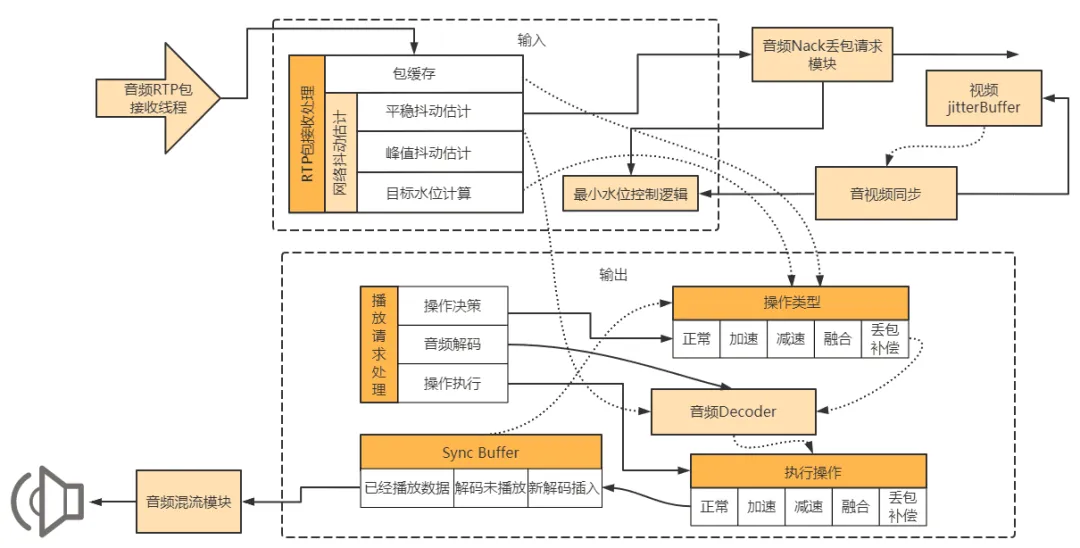
2.1 NetEQ 输入部分
- 服务收到RTP包后,调用NetEQ的InsertPacket函数进入接收模块中
- 对于带有RED冗余包的音频RTP包,对其进行解包,还原出原始包,忽略掉重复的原始包
- 将解出来的原始RTP包插入到Packet Buffer缓存中
- 对每一个原始包,得到时间轴上唯一的一个接收时刻,计算包与包之间的接收时间差,接收时间差除以包的发送频率20ms作为抖动估计的Iat(interarrival time)
- 每个包的 Iat 值经过核心的网络抖动估计模块(DelayManager)处理之后,得到最终的目标水位(TargetLevel)
2.2 NetEQ 输出部分
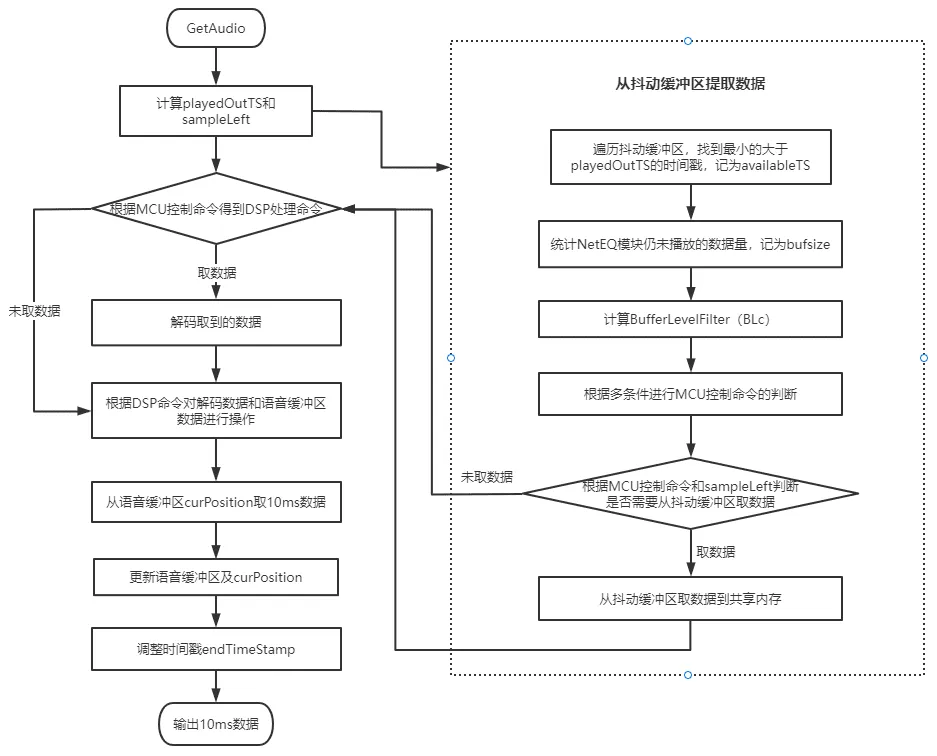
定时器每10ms调用GetAudio函数从NetEQ中取10ms的音频数据
-
将DSP的endTimeStamp赋值给PlayedOutTs,并计算SyncBuffer中等待播放的样本数sampleLeft
-
从抖动缓冲区提取数据
- 遍历抖动缓冲区数据包的时间戳,找到最小的大于playedOutTS的时间戳,记为可用时间戳availableTS,同时将小于playedOutTS的数据包视为迟到包丢弃。
- 统计进入NetEQ模块但仍未被播放的数据量,记为bufsize,可以看出bufsize为等待播放样本数sampleLeft 及抖动缓冲区数据之和。
- 根据bufsize计算BufferLevelFilter。
- 根据BufferLevelFilter、bufsize、playedOutTS、availableTS、上次播放模式等一系列因素进行MCU控制命令的判断。
- 根据MCU控制命令和等待播放样本数sampleLeft判断是否需要从抖动缓冲区取数据。
- 如果需要取数据,则从抖动缓冲区取数据写入共享内存
-
根据MCU控制命令进行调整得到对应的DSP处理命令
-
解码器从共享内存中取数据,并解码取到的数据
-
根据DSP操作命令进入相应的的播放模式对解码数据及语音缓冲区中数据进行相关操作
-
从语音缓冲区的curPosition作为起始位置取10ms数据
-
更新语音缓冲区及curPosition
-
调整时间戳endTimeStamp,输出取到的10ms数据
三、NetEQ 核心模块
3.1 NetEQ Buffer
3.1.1 抖动缓冲区PacketBuffer
- 作用:缓存数据包
- 本质:
std::list<Packet> - 特点:按timestamp有序4.上限:默认500
3.1.2 解码缓冲区DecodedBuffer
- 作用:存放解码后的pcm数据
- 本质:int16 array
3.1.3 算法缓冲区AlgorithmBuffer
- 作用: 存放Expend等dsp算法处理后的音频pcm数据
3.1.4 语音缓冲区SyncBuffer
- 作用:存放已经播放过的数据、解码后未播放的数据,通过curPosition区分
- 本质:带播放标记的多频道的pcm数据数组,循环Buffer
3.2 抖动估计模块DelayManager
NetEQ根据数据包到达的时间间隔,统计出网络时延情况,具体步骤如下:
-
统计当前数据包绝对到达间隔Iat(以数据包个数为单位),提前到达的Iat为0,正常达到的Iat为1,Iat的最大值为64,以20ms发送一个包,则统计的最大延迟为1.28s
-
更新 Iat 从0到64的概率分布
- 用遗忘因子对概率分布进行遗忘
- 增大本次计算到的 Iat 的概率
- 更新遗忘因子,使其为递增趋势,即通话时间越长,包间隔的概率分布越稳定
- 调整本次计算到的 Iat 的概率,使整个 Iat 的概率分布之和近似为 1
f′={0,n=034×f+0.99934,n>0f' = \begin{cases} 0, & n = 0 \\ \frac{3}{4} \times f + \frac{0.9993}{4}, & n > 0 \end{cases} f′={0,43×f+40.9993,n=0n>0
- 统计满足95%概率的Iat值,作为目标水位值BLo(target_buffer_level)
3.2.3峰值抖动估计
-
NetEQ采用两个长度为 8 的数组来统计 Iat 的峰值,一个用来存储峰值幅度,另一个用来存储峰值间隔。
-
当 Iat 大于2倍的95%概率的Iat值时,判定为峰值,计算当前探测到的峰值距离上一次峰值的时间间隔。
- 当峰值间隔小于10s,则去掉数组中最早的数据,并将当前数据储存到数组中
- 当峰值间隔在10s 到 20s之间时,不作处理
- 当峰值间隔大于20s时,清空数组
-
如果峰值数组数据不足8个,峰值抖动估计不起作用,当峰值抖动估计起作用时,目标水位值设置为峰值数组的最大值。
3.2.4抖动延迟计算BufferLevelFilter
抖动延迟统计的是抖动缓冲区的自适应平均值,其计算公式如下:
BLc′=f×BLc+(1−f)×SBLpBL_c' = f \times BL_c + (1 - f) \times \frac{S_B}{L_p}BLc′=f×BLc+(1−f)×LpSB
f={251256,B=0.1252256,B=2,3253256,B=4,5,6,7254256,B>7f = \begin{cases} \frac{251}{256}, & B = 0.1 \\ \frac{252}{256}, & B = 2,3 \\ \frac{253}{256}, & B = 4,5,6,7 \\ \frac{254}{256}, & B > 7 \end{cases} f=⎩⎨⎧256251,256252,256253,256254,B=0.1B=2,3B=4,5,6,7B>7
其中 f 为计算均值的遗忘因子,B为统计满足95%概率的Iat值,可以看出B越大时,表示需要更多的样本来计算平均值。
如果经过加速或者减速播放,则
BLc′′=BLc′−sampleMemoryLpBL_c'' = BL_c' - \frac{sampleMemory}{L_p} BLc′′=BLc′−LpsampleMemory
SampleMemory 表示加速或慢速播放后数据长度的伸缩变化,当加减数播放后,BLc值会剧烈变化。
如果加速播放,BLc值会剧烈减少,如果减速播放,BLc值会剧烈增大。
此处 BLc 的大幅度变化保证了加速和减速不会长期持续,确保了音质的舒适度。
n' = level_factor_ * n + (1 - |level_factor_|) * |buffer_size_packets| - time_stretched_packetslevel_factor_的取值:
void BufferLevelFilter::SetTargetBufferLevel(int target_buffer_level) {if (target_buffer_level <= 1) {level_factor_ = 251;} else if (target_buffer_level <= 3) {level_factor_ = 252;} else if (target_buffer_level <= 7) {level_factor_ = 253;} else {level_factor_ = 254;}
}说明:算法里的1应该看成比例100%,或者256/256. 不是自然值1.buffer_size_packets的取值:
packet_buffer 的采样数 + sync_buffer剩余采样数time_stretched_packets:
变速不变调的packet数
3.3控制决策模块DecisionLogic
作用: 根据当前帧和上一帧的丢失/正常的2x2的组合,得出每一种场景下的数据处理决策
-
当前帧正常+前一帧正常:
上一帧和当前这一帧均接收正常,因此数据包进入正常的解码流程,并将解码后数据按照是否有抖动消除的需要而做出相应的输出。这种情况下, NetEQ 会做出正常、加速和减速播放三种操作,并由 MCU 控制选择。 -
当前帧丢失+前一帧正常:
如果当前帧丢失或延迟,那么进入 PLC 单元重建 LPC 系数和残差信号。这种情况下,NetEQ 会执行丢包隐藏的操作。NetEQ 最多会为延迟、丢包帧等待100ms,超过该时间则直接提取播放下一帧。 -
当前帧丢失+前一帧丢失:
如果发生连续多帧丢包,那么就需要多次进入 PLC 单元,并且需要利用正常接收且刚播过,或准备播放的某帧的帧状态信息。值得注意的是,越靠后面丢失的帧,越难以精确地重建补偿包,所以对连续丢包的补偿能量增益采用逐帧递减方式,以避免引入更大的信号失真。 -
当前帧正常+前一帧丢失:
如果上一帧丢失,但当前帧接收正常,则说明播放的上一帧是经过 PLC 产生的。为了使经过 PLC 补偿的帧与接下来没有丢包的帧保持语音连续,则需要根据前后帧的相关性进行平滑处理。此种情况下 NetEQ 一般会做出正常播放或融合操作(merge)响应
3.3.1加速播放发生条件
加速播放的原因是要播放的数据正常到达,但缓冲延迟已经大于网络延迟,因此要进行加速播放。
加速播放需要满足以下条件之一:
{1)BLc≥max(BL0,3⋅BL04+23)且 timescaleHoldOff=02)BLc≥4⋅BL0\begin{cases} 1) \ BL_c \geq \max\left(BL_0, \frac{3 \cdot BL_0}{4} + \frac{2}{3}\right) \text{ 且 } \text{timescaleHoldOff} = 0 \\ 2) \ BL_c \geq 4 \cdot BL_0 \end{cases} {1) BLc≥max(BL0,43⋅BL0+32) 且 timescaleHoldOff=02) BLc≥4⋅BL0
其中 timescaleHoldOff 初始化为 2的5次方,且每发生一次加速或减速播放则右移一位。
此参数是为了防止连续的加速或减速操作恶化人耳的听觉感受。
3.3.2减速播放发生条件
减速播放的原因是要播放的数据正常到达,但缓冲延迟小于网络延迟,则要进行减速播放。
减速播放的必要条件如下:
BLc<3⋅BLo4且timescaleHoldOff==0BLc<\frac{3⋅BL_o}{4} 且 timescaleHoldOff==0 BLc<43⋅BLo且timescaleHoldOff==0
丢包隐藏的原因是要播放的数据包还未接收,但此时抖动缓冲区可能有其他数据在缓冲。此时共分为3种情形:
- 连续进行丢包隐藏操作,NetEQ设定最多等待或补偿100ms的数据。
- 上一帧被正常接收,但当前需要播放的帧还未到达,因此是第一次做丢包隐藏
- 当抖动缓冲区为空时,只能做丢包隐藏来等待新包的到来
3.3.4融合控制发生条件
融合控制命令主要用于丢包隐藏后的数据与从抖动缓冲区中提取的数据的衔接过程。
融合发生需要满足以下条件之一:
- 丢包隐藏的限制次数还未到,但是此时抖动缓冲区中的缓冲延迟已经过大
- 抖动缓冲区中可以播放的数据帧之前的数据还未被补偿完但是丢包隐藏次数已经达到 10 次
- 抖动缓冲区中可以播放的数据帧之前的数据已经被补偿完
- 抖动缓冲区中可以播放的数据帧与需要播放的数据帧相差太远,即大于 100ms
3.4变速不变调算法
波形相似同步叠加法WSOLA
变速不变调算法可以分为时域调整和频域调整两类,WSOLA算法是典型的时域调整算法,对于语音信号可以得到较好的语音质量,而且计算量比频域算法要小。
3.4.1WSOLA算法原理
WSOLA 算法采用的是分解合成的思想,将原始语音信号以 L 为帧间距,以 N 为帧长进行分帧,以 aL 为帧间距进行合成。其中a为时长调整因子,a>1表示语音被压缩,反之则为拉伸。
为防止相邻帧合成时出现频谱断裂或相位不连续的状况,合成时需要在原始信号的对应周期采样点处的临域内移动,来寻找与分解后的第k帧信号波形最相关的波形,确定合成帧的起始位置。
WSOLA采用汉宁窗函数进行重叠相加,利用短时平均幅度差系数计算相似性
CA(k,δ)=∑n=0N−1∣x(n+τ(Lk−1)+Δk−1+L)−x(n+τ(Lk)+δ)∣C_{A}(k, \delta)=\sum_{n=0}^{N-1}\left|x\left(n+\tau\left(L_{k-1}\right)+\Delta_{k-1}+L\right)-x\left(n+\tau\left(L_{k}\right)+\delta\right)\right| CA(k,δ)=n=0∑N−1∣x(n+τ(Lk−1)+Δk−1+L)−x(n+τ(Lk)+δ)∣
基本原理:
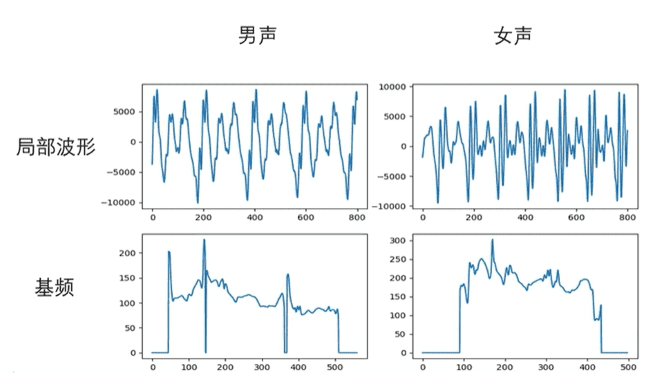
- (1) 语音音调由局部波形决定,如下图所示,男声周期长,基频低。女生反之
- (2) 可采用下图所示的间隔拼接的方式(OLA),保证变时不变调(音频长度改变,局部波形不变)
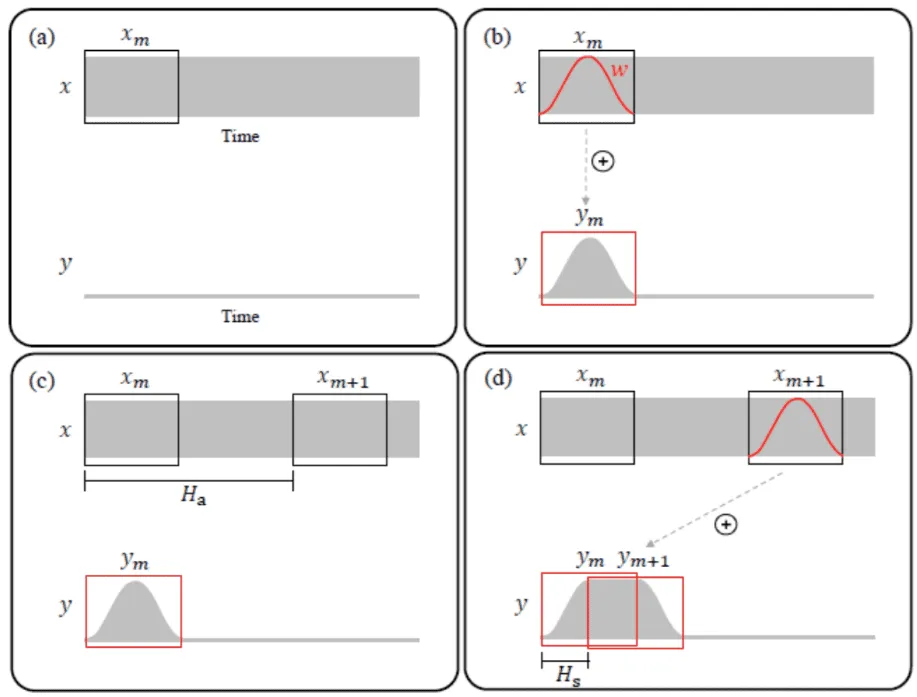
图中 x 和 y 分别表示处理前后的语音信息。变速的关键在 c 图和 d 图,能够看到 OLA 直接暴力的将 x(m+1)的波形拷贝到 y(m+1)处,并与 y(m)进行叠加。此时语音省略掉了 x(m)和 x(m+1)之间的信息,实现了快放。这个算法最简单,但是缺点也很明显,就是没有考虑到 x(m+1)和 y(m)之间的连续性
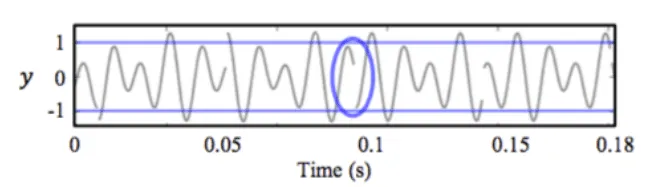
- (3) (2)中的方法过于粗暴,会带来音频不连续的问题,相邻帧重叠区域产生基频失真,如下图所示
- (4) 采用WSOLA方法,通过寻找相似度最大的两帧信号,可以解决音频不连续的问题
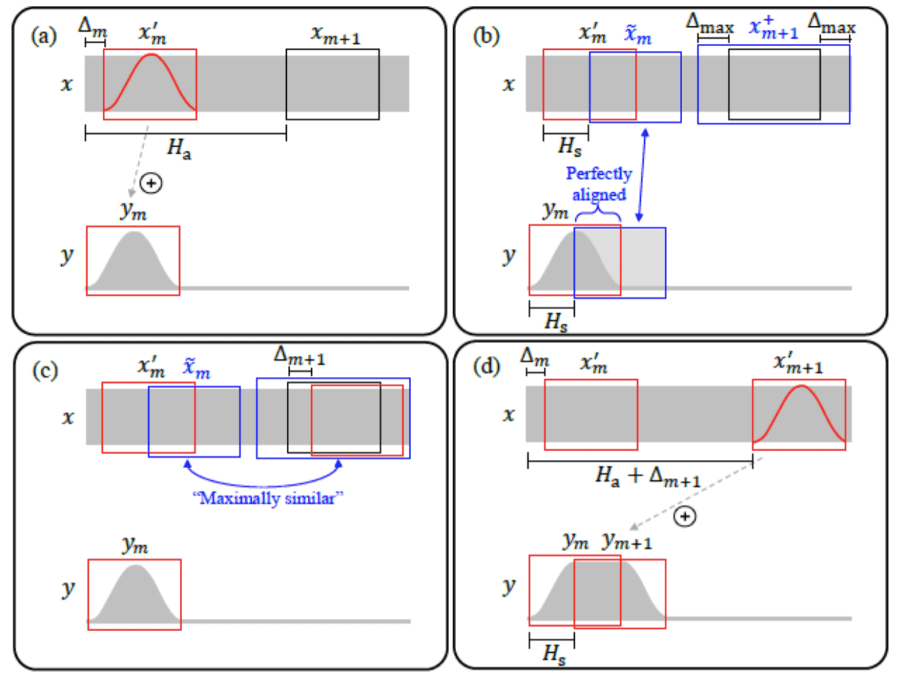
3.5 正常Normal
正常处理一般用于提取的数据包刚好合乎播放要求,然后将此包解码后直接输出到语音缓冲区中等待播放。正常处理时还需要考虑上次DSP(Digital Signal Processor)的处理类型,如下图所示:
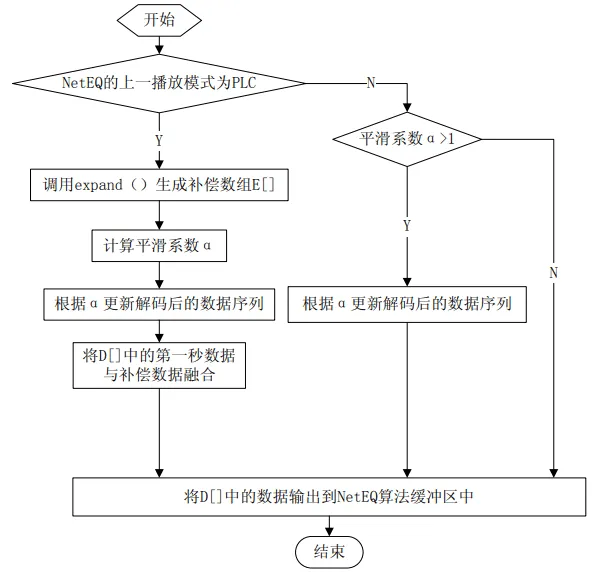
3.6 丢包隐藏Expand
源码参见 NetEQ 模块的expand 函数
NetEQ采用iLBC编解码器的丢包隐藏技术。iLBC 全称为 Internet Low Bit rate Codec,是 GIPS 开发的一种专为包交换网络通信设计的编解码,它是低比特率(8KHZ)的解码器,在丢包时具有的强大的健壮性
iLBC具体步骤:
-
重建线性预测系数(LPC),即采用了过去帧的最后一个子帧的 LPC 系数来重建。因为无论从空间上还是时间上最后一个子帧都与当前丢失的 LPC 具有最相关性。但是这种简单的复制在处理连续多帧时,也显然会引入更大的失真
-
重建残差信号。残差信号通常可以分为两部分组成:准周期成分和类噪声成分,其中准周期成分可以根据测量前一帧的基音周期来近似得到,类噪声成分则可以通过产生随机噪声得到,二者的能量比例也可以借鉴前一帧的比例关系。因此,首先要对前一帧进行基音检测,然后以基音同步的方式重建丢失帧的话音部分,接着利用相关性得到类噪声的增益,最后进行混合以重建整个残差信号。
-
在连续丢帧的情况下, PLC 所补偿的各个语音帧具有相同的频谱特性(相同的 LPC 造成)和基音频率,为了减少各个补偿帧之间的相关性,会将能量进行逐帧递减。
NetEQ并非每处理一个语音帧都计算其 LPC(线性预测系数),其做法是:当需要进行丢包隐藏时,从存储最近播放的 70ms 数据语音缓冲区中取出最新的一帧数据,并计算这帧数据的 LPC 系数即可。
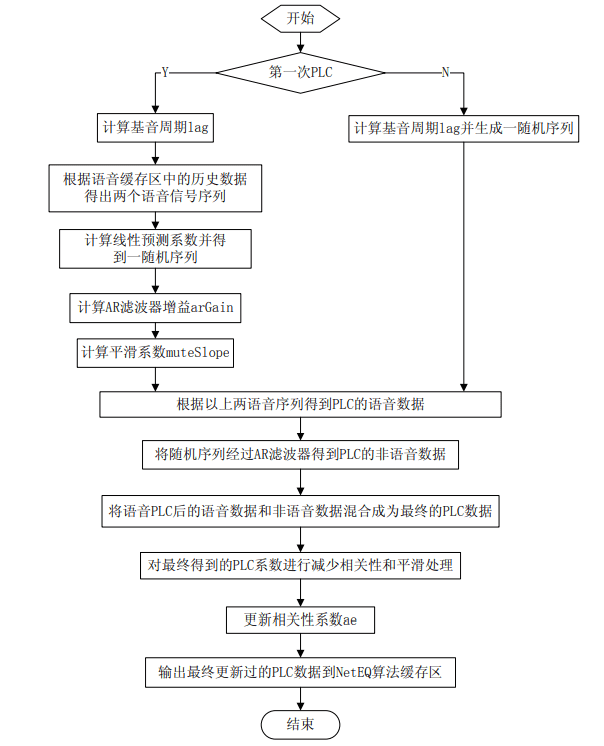
3.7 融合Merge
源码参见 NetEQ 模块的 merge 函数
融合处理发生在上一播放的帧与当前解码后的数据帧不是连续的情况下,此时需要融合处理的衔接与平滑。执行流程如下
-
首先进行丢包隐藏并得到长度为 202 个样本的补偿序列expanded,expanded 由剩余的未播放样本sampleLeft 及其经过expand操作后的数据拼接而成。
-
确定该补偿序列从第几个样本开始与解码后的数据序列相关性最大,设为P,满足P小于未播放的数据量 sampleLeft。
-
对解码端的数据进行平滑处理,如下图所示
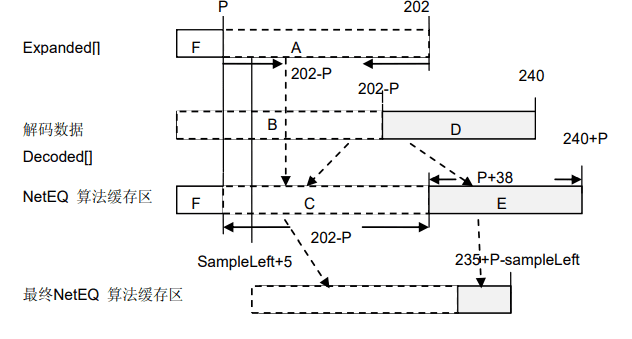
解码数据分为两部分,一部分用于与PLC的数据进行混合并平滑(区域B),一部分只用做平滑(区域D),NetEQ 采用每 1ms 让平滑系数递增 0.032 的方式对解码后的数据进行平滑处理,由于PLC 的数据采用递减的方式对数据平滑,而 merge 采用递增的方式进行平滑,从而让两段语音能更好的衔接。
- 由于PLC 的数据先于解码的数据,因此混合方式是:混合后的最开始的数据与 PLC 的相关性最大,最末尾的数据与解码数据相关性最大,即 PLC 数据采用样本递减、解码数据采用样本递增方式混合。公式如下:
C[i]=202−P−i201−PA[i]+i+1201−PB[i]+0.5C[i] = \frac{202 - P - i}{201 - P} A[i] + \frac{i + 1}{201 - P} B[i] + 0.5 C[i]=201−P202−P−iA[i]+201−Pi+1B[i]+0.5
3.8 加速Accelerate
源码参见 NetEQ 模块的 accelerate 函数
-
作用:加速处理主要用于加速播放,也是抖动延迟累积过大时,在不丢包的情况下尽快减少抖动延迟的关键措施。
-
原理:加速处理是解决数据包在抖动缓冲区中的累积而使用 WSOLA 算法在时域上压缩语音信号。
-
加速播放步骤:
-
从Decode Buffer中获取一个语音帧,一帧语音数据长为20ms,以单声道48000采样率为例,一共960个样本。
-
根据短时自相关函数法计算经解码的一帧数据流的基音周期。
-
计算该数据流两个基音周期的相关性bestCorr。
textbestCorr=∑i=0p−1A[i]B[i]∑i=0p−1A[i]2⋅∑i=0p−1B[i]2\\text{bestCorr} = \frac{\sum_{i=0}^{p-1} A[i]B[i]}{\sqrt{\sum_{i=0}^{p-1} A[i]^2 \cdot \sum_{i=0}^{p-1} B[i]^2}}textbestCorr=∑i=0p−1A[i]2⋅∑i=0p−1B[i]2∑i=0p−1A[i]B[i] -
当相关性大于0.9时,将两个基音周期交叉混合并输出,否则按照正常处理直接输出。交叉混合公式如下:
C[i]=p−i1+pA[i]+i+11+pB[i]+0.5C[i] = \frac{p - i}{1 + p} A[i] + \frac{i + 1}{1 + p} B[i] + 0.5C[i]=1+pp−iA[i]+1+pi+1B[i]+0.5 -
加速处理就是将两个基音混合成一个,并替代原有的两个基音来缩短语音长度。因此,经过加速后的语音帧,长度减少了一个基音周期。加速后的语音数据存到AlgorithmBuffer中
-
3.9减速PreemptiveExpand
-
作用:减速处理是为了实现减速播放,一般当网络状况不好而导致数据到来较少时,为了人耳听觉的连续性,使用 WSOLA 算法在时域上拉伸信号,来延长等待网络数据的时间。
-
原理:减速处理原理与加速相同,减速处理是将两个基音混合成一个并插到两个基音之间来延长语音长度。因此,经过减速处理后的语音帧,长度增加了一个基音周期