深度学习中基于响应的模型知识蒸馏实现示例
在 https://blog.csdn.net/fengbingchun/article/details/149878692 中介绍了深度学习中的模型知识蒸馏,这里通过已训练的DenseNet分类模型,基于响应的知识蒸馏实现通过教师模型生成学生模型:
1. 依赖的模块如下所示:
import argparse
import colorama
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
import torchvision.models as models
import torchvision.transforms as transforms
from PIL import Image
import ast
import time
from pathlib import Path2. 支持的输入参数如下所示:
def parse_args():parser = argparse.ArgumentParser(description="model knowledge distillation")parser.add_argument("--task", required=True, type=str, choices=["train", "predict"], help="specify what kind of task")parser.add_argument("--src_model", type=str, help="source model name")parser.add_argument("--dst_model", type=str, help="distilled model name")parser.add_argument("--classes_number", type=int, default=2, help="classes number")parser.add_argument("--mean", type=str, help="the mean of the training set of images")parser.add_argument("--std", type=str, help="the standard deviation of the training set of images")parser.add_argument("--labels_file", type=str, help="one category per line, the format is: index class_name")parser.add_argument("--images_path", type=str, help="predict images path")parser.add_argument("--epochs", type=int, default=500, help="number of training")parser.add_argument("--lr", type=float, default=0.0001, help="learning rate")parser.add_argument("--drop_rate", type=float, default=0.2, help="dropout rate")parser.add_argument("--dataset_path", type=str, help="source dataset path")parser.add_argument("--temperature", type=float, default=2.0, help="temperature, higher the temperature, the better it expresses the teacher's knowledge: [2.0, 4.0]")parser.add_argument("--alpha", type=float, default=0.7, help="teacher weight coefficient, generally, the larger the alpha, the more dependent on the teacher's guidance: [0.5, 0.9]")args = parser.parse_args()return args3. 定义学生网络类StudentModel:
class StudentModel(nn.Module):def __init__(self, classes_number=2, drop_rate=0.2):super().__init__()self.features = nn.Sequential( # four convolutional blocksnn.Conv2d(3, 32, 3, padding=1),nn.BatchNorm2d(32),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2),nn.Conv2d(32, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2),nn.Conv2d(64, 128, 3, padding=1),nn.BatchNorm2d(128),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2),nn.Conv2d(128, 256, 3, padding=1),nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.AdaptiveAvgPool2d((1, 1)))self.classifier = nn.Sequential(nn.Linear(256, 128),nn.ReLU(inplace=True),nn.Dropout(drop_rate),nn.Linear(128, classes_number))def forward(self, x):x = self.features(x)x = x.view(x.size(0), -1)x = self.classifier(x)return x(1).为知识蒸馏设计的轻量级卷积神经网络,用作student模型来学习复杂teacher模型的知识。
(2).self.features为特征提取器,通过4个卷积块逐步提取从低级到高级的特征,因为使用了nn.AdaptiveAvgPool2d,可以支持不同大小彩色图像的输入。
(3).self.classifier为分类器,2个全连接层(第一个全连接层降维,第二个全连接层分类),dropout层防止过拟合。
4. 训练代码如下:
def print_student_model_parameters():student_model = StudentModel()print("student model parameters: ", student_model)tensor = torch.rand(1, 3, 224, 224)student_model.eval()output = student_model(tensor)print(f"output: {output}; output.shape: {output.shape}")def _str2tuple(value):if not isinstance(value, tuple):value = ast.literal_eval(value) # str to tuplereturn valuedef _load_dataset(dataset_path, mean, std, batch_size):mean = _str2tuple(mean)std = _str2tuple(std)train_transform = transforms.Compose([transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=mean, std=std), # RGB])train_dataset = ImageFolder(root=dataset_path+"/train", transform=train_transform)print(f"train dataset length: {len(train_dataset)}; classes: {train_dataset.class_to_idx}; number of categories: {len(train_dataset.class_to_idx)}")train_loader = DataLoader(train_dataset, batch_size, shuffle=True, num_workers=0)val_transform = transforms.Compose([transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=mean, std=std), # RGB])val_dataset = ImageFolder(root=dataset_path+"/val", transform=val_transform)print(f"val dataset length: {len(val_dataset)}; classes: {val_dataset.class_to_idx}")assert len(train_dataset.class_to_idx) == len(val_dataset.class_to_idx), f"the number of categories int the train set must be equal to the number of categories in the validation set: {len(train_dataset.class_to_idx)} : {len(val_dataset.class_to_idx)}"val_loader = DataLoader(val_dataset, batch_size, shuffle=True, num_workers=0)return len(train_dataset), len(val_dataset), train_loader, val_loaderdef _distillation_loss(student_logits, teacher_logits, labels, temperature, alpha):# hard label loss(student model vs. true label)hard_loss = nn.CrossEntropyLoss()(student_logits, labels)# soft label loss(student model vs. teacher model)soft_loss = nn.KLDivLoss(reduction='batchmean')(F.log_softmax(student_logits / temperature, dim=1),F.softmax(teacher_logits / temperature, dim=1)) * (temperature ** 2)return alpha * soft_loss + (1 - alpha) * hard_lossdef train(src_model, dst_model, device, classes_number, drop_rate, mean, std, dataset_path, epochs, lr, temperature, alpha):teacher_model = models.densenet121(weights=None)teacher_model.classifier = nn.Linear(teacher_model.classifier.in_features, classes_number)teacher_model.load_state_dict(torch.load(src_model, weights_only=False, map_location="cpu"))teacher_model.to(device)student_model = StudentModel(classes_number, drop_rate).to(device)train_dataset_num, val_dataset_num, train_loader, val_loader = _load_dataset(dataset_path, mean, std, 4)optimizer = optim.Adam(student_model.parameters(), lr)highest_accuracy = 0.minimum_loss = 100.for epoch in range(epochs):epoch_start = time.time()train_loss = 0.0train_acc = 0.0val_loss = 0.0val_acc = 0.0student_model.train()teacher_model.eval()for _, (inputs, labels) in enumerate(train_loader):inputs = inputs.to(device)labels = labels.to(device)with torch.no_grad():teacher_outputs = teacher_model(inputs)student_outputs = student_model(inputs)loss = _distillation_loss(student_outputs, teacher_outputs, labels, temperature, alpha)optimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item() * inputs.size(0)_, predictions = torch.max(student_outputs.data, 1)correct_counts = predictions.eq(labels.data.view_as(predictions))acc = torch.mean(correct_counts.type(torch.FloatTensor))train_acc += acc.item() * inputs.size(0)student_model.eval()with torch.no_grad():for _, (inputs, labels) in enumerate(val_loader):inputs = inputs.to(device)labels = labels.to(device)outputs = student_model(inputs)loss = nn.CrossEntropyLoss()(outputs, labels)val_loss += loss.item() * inputs.size(0)_, predictions = torch.max(outputs.data, 1)correct_counts = predictions.eq(labels.data.view_as(predictions))acc = torch.mean(correct_counts.type(torch.FloatTensor))val_acc += acc.item() * inputs.size(0)avg_train_loss = train_loss / train_dataset_numavg_train_acc = train_acc / train_dataset_numavg_val_loss = val_loss / val_dataset_numavg_val_acc = val_acc / val_dataset_numepoch_end = time.time()print(f"epoch:{epoch+1}/{epochs}; train loss:{avg_train_loss:.6f}, accuracy:{avg_train_acc:.6f}; validation loss:{avg_val_loss:.6f}, accuracy:{avg_val_acc:.6f}; time:{epoch_end-epoch_start:.2f}s")if highest_accuracy < avg_val_acc and minimum_loss > avg_val_loss:torch.save(student_model.state_dict(), dst_model)highest_accuracy = avg_val_accminimum_loss = avg_val_lossif avg_val_loss < 0.0001 or avg_val_acc > 0.9999:print(colorama.Fore.YELLOW + "stop training early")torch.save(student_model.state_dict(), dst_model)break(1).使用PyTorch中的类ImageFolder和DataLoader加载数据集。
(2).蒸馏损失:
1).硬标签(one-hot)损失函数:交叉熵,nn.CrossEntropyLoss,来源于ground truth。
2).软标签(teacher预测概率分布)损失函数:KL散度,nn.KLDivLoss,来源于teacher输出,软标签携带了更多类别间的相似度信息,有助于student模型更好地泛化。
3).temperature和权重比例alpha参数:temperature越高,soft标签越"软",更能表达teacher的知识;通常alpha越大,表示更依赖teacher的指导。
(3).训练代码中加入了早停机制,当验证损失小于指定的值或验证准确度大于指定的值时停止训练。
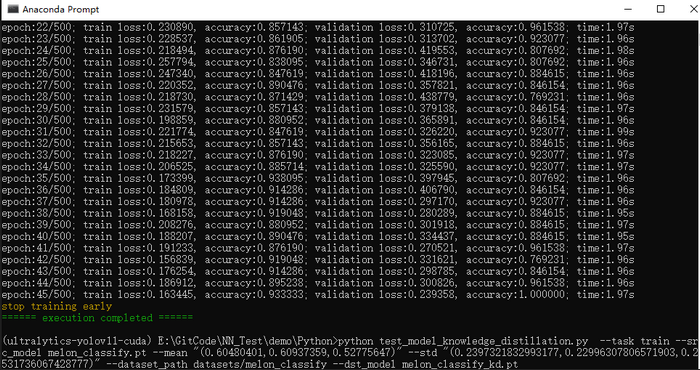
训练输出结果如下图所示:
5. 预测代码如下所示:
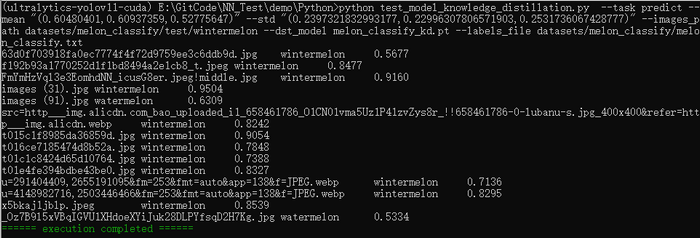
def _parse_labels_file(labels_file):classes = {}with open(labels_file, "r") as file:for line in file:idx_value = []for v in line.split(" "):idx_value.append(v.replace("\n", "")) # remove line breaks(\n) at the end of the lineassert len(idx_value) == 2, f"the length must be 2: {len(idx_value)}"classes[int(idx_value[0])] = idx_value[1]return classesdef _get_images_list(images_path):image_names = []p = Path(images_path)for subpath in p.rglob("*"):if subpath.is_file():image_names.append(subpath)return image_namesdef predict(model_name, labels_file, images_path, mean, std, device):classes = _parse_labels_file(labels_file)assert len(classes) != 0, "the number of categories can't be 0"image_names = _get_images_list(images_path)assert len(image_names) != 0, "no images found"mean = _str2tuple(mean)std = _str2tuple(std)model = StudentModel(len(classes)).to(device)model.load_state_dict(torch.load(model_name, weights_only=False, map_location="cpu"))model.to(device)model.eval()with torch.no_grad():for image_name in image_names:input_image = Image.open(image_name)preprocess = transforms.Compose([transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=mean, std=std) # RGB])input_tensor = preprocess(input_image) # (c,h,w)input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model, (1,c,h,w)input_batch = input_batch.to(device)output = model(input_batch)probabilities = torch.nn.functional.softmax(output[0], dim=0) # the output has unnormalized scores, to get probabilities, you can run a softmax on itmax_value, max_index = torch.max(probabilities, dim=0)print(f"{image_name.name}\t{classes[max_index.item()]}\t{max_value.item():.4f}")预测输出结果如下图所示:
6. 入口函数如下所示:
if __name__ == "__main__":colorama.init(autoreset=True)args = parse_args()# print_student_model_parameters()device = torch.device("cuda" if torch.cuda.is_available() else "cpu")if args.task == "train":train(args.src_model, args.dst_model, device, args.classes_number, args.drop_rate, args.mean, args.std,args.dataset_path, args.epochs, args.lr, args.temperature, args.alpha)else:predict(args.dst_model, args.labels_file, args.images_path, args.mean, args.std, device)print(colorama.Fore.GREEN + "====== execution completed ======")以上代码中不通过蒸馏直接通过StudentModel也可以生成分类模型,使用蒸馏的优势在于:
(1).可以学习到教师模型的"软知识",从头训练时,学生模型只能依赖硬标签(one-hot),无法知道类别之间的相似性。蒸馏中,学生会去拟合教师模型的软标签,这有助于学生模型泛化。
(2).从头训练时,学生模型需要足够多且多样化的数据才能学到泛化能力。有了教师模型,即使训练数据不多,学生也能通过教师的软标签进行监督。
(3).通过蒸馏会使学生模型训练更稳定,收敛更快。
(4).从头训练学生模型可能达不到教师模型的性能,而蒸馏能让学生模型模仿教师模型的决策边界,从而在计算量相同的情况下获得更好的准确率。
GitHub:https://github.com/fengbingchun/NN_Test