东北大学“进化论”赋能具身导航!SE-VLN:基于多模态大模型的自进化视觉语言导航框架

- 作者:Xiangyu Dong1^{1}1, Haoran Zhao3^{3}3, Jiang Gao1,2^{1,2}1,2, Haozhou Li1^{1}1, Xiaoguang Ma1,2^{1,2}1,2, Yaoming Zhou3^{3}3, Fuhai Chen4^{4}4, Juan Liu5^{5}5
- 单位:1^{1}1东北大学佛山创新研究生院,2^{2}2东北大学机器人科学与工程学院,3^{3}3北京航空航天大学航空科学与工程学院,4^{4}4福州大学计算机科学与大数据学院,5^{5}5武汉大学计算机学院
- 论文标题:SE-VLN: A Self-Evolving Vision-Language Navigation Framework Based on Multimodal Large Language Models
- 论文链接:https://arxiv.org/abs/2507.13152v1
主要贡献
- 提出了基于多模态大语言模型(MLLM)的自进化视觉语言导航框架(SE-VLN),通过模拟自然智能体的进化过程,实现了无需大规模标注数据训练的自进化能力,为 VLN 领域提供了一种新的思路。
- 设计了层次化记忆模块,通过语言拓扑地图记录智能体在路径节点上的视觉观察和决策过程,作为短期记忆支持即时决策和经验提炼;同时结合经验库存储长期经验,增强后续任务的决策效率。
- 引入了检索增强型基于思考的推理模块,整合检索增强生成(RAG)技术和思维链(CoT)提示技术,通过检索相关历史经验来实现多步决策,提高了智能体决策的准确性。
- 引入了反思模块,基于任务评估结果对智能体的决策进行深入分析,实现长期经验的增量更新和智能体的持续进化。
研究背景
- 视觉语言导航 (VLN)是一种将人类自然语言与机器人视觉导航相结合的关键技术,旨在使智能体能够根据人类语言指令在未见环境中自主规划路径并完成视觉导航任务。近年来,随着大语言模型(LLM)的出现,VLN 方法在指令理解和任务推理方面展现出优秀的泛化能力,但受限于 LLM 的固定知识库和推理能力,无法有效整合经验知识,缺乏高效的进化能力。
- 自然智能体的导航能力,如马、候鸟、座头鲸等,能够通过经验不断进化和适应环境,为 VLN 提供了生物蓝图。然而,现有的 VLN 方法在经验利用、推理能力和自主进化方面存在局限性,例如将历史轨迹数据作为固定回放缓冲区,仅用于维持当前任务的决策一致性,未能从动态过程中提取可重用的通用知识;依赖预训练模型的静态知识调用,无法有效整合经验进行多步决策;进化过程高度依赖手动超参数调整和模型迭代,与自然智能体通过自然选择和神经可塑性实现自进化的机制完全不同。
研究方法
整体架构
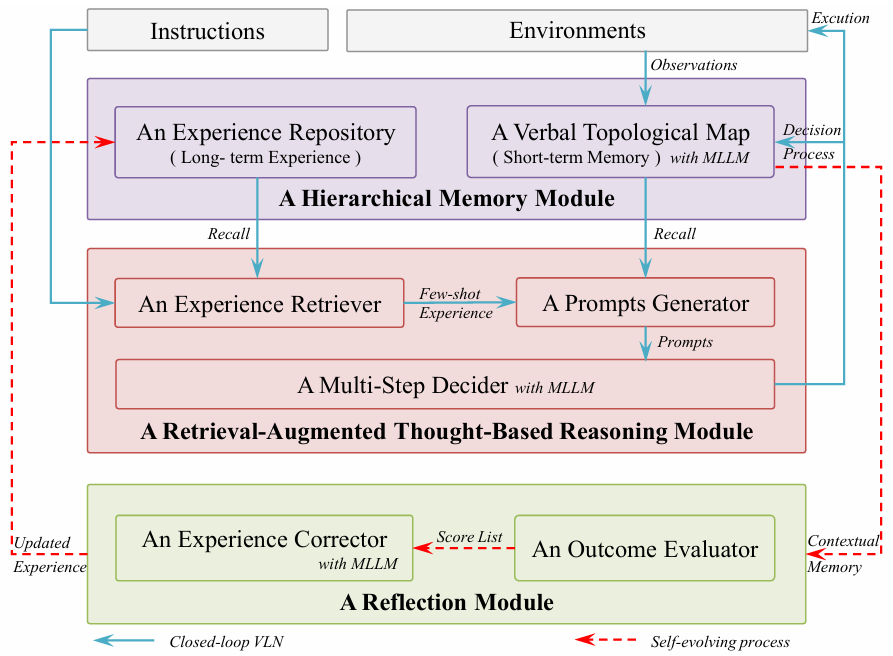
- SE-VLN 框架包含三个核心模块,即层次化记忆模块、检索增强型基于思考的推理模块和反思模块。
- 智能体首先根据当前任务的指令从经验库中检索少量经验,用于每一步的决策;
- 然后将环境观察更新到语言拓扑地图中,通过提示生成器整合信息并构建提示;
- 经过多步决策器的综合分析后输出动作与环境交互,同时将决策过程更新到语言拓扑地图中;
- 任务完成后,反思模块通过结果评估器对导航性能进行量化评估,并通过经验修正器识别和纠正不合理决策,将修正后的决策作为经验存回经验库,实现自进化。
层次化记忆模块
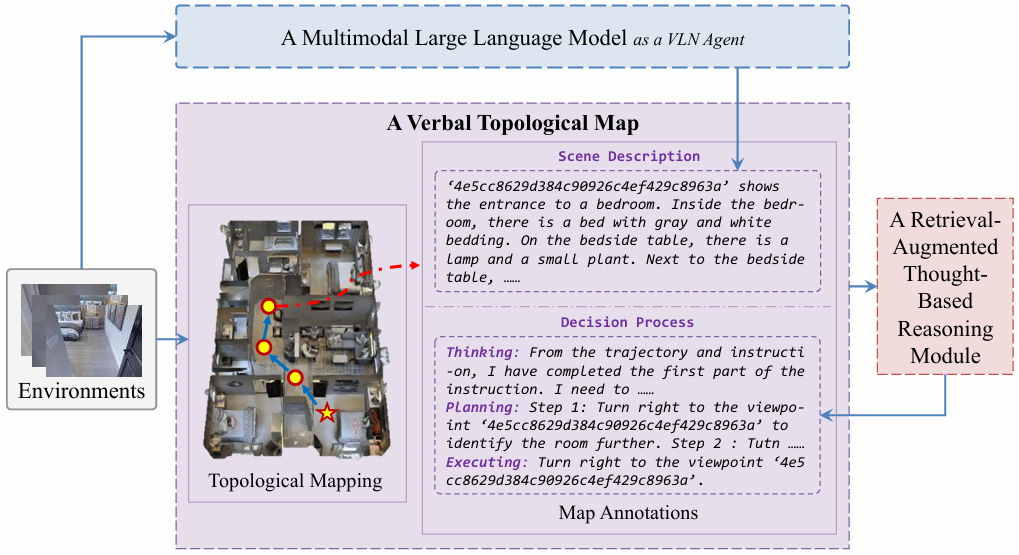
- 语言拓扑地图:作为短期记忆,实时记录关键信息,包括导航图、视觉观察的文字描述和决策过程(思考、规划和执行)。其构建涉及拓扑映射和地图注释两个关键过程。拓扑映射基于智能体的在线观察构建动态更新的图;地图注释则将视觉观察转换为文字描述,并将决策过程作为节点注释的一部分,辅助智能体进行后续决策和任务后反思。
- 经验库:基于向量数据库 Chroma 构建,记录智能体过去的导航记忆作为长期经验,用于指导后续任务决策。每条经验包含地标特征、场景描述、决策过程和修正后的决策过程四个关键要素。
检索增强型基于思考的推理模块
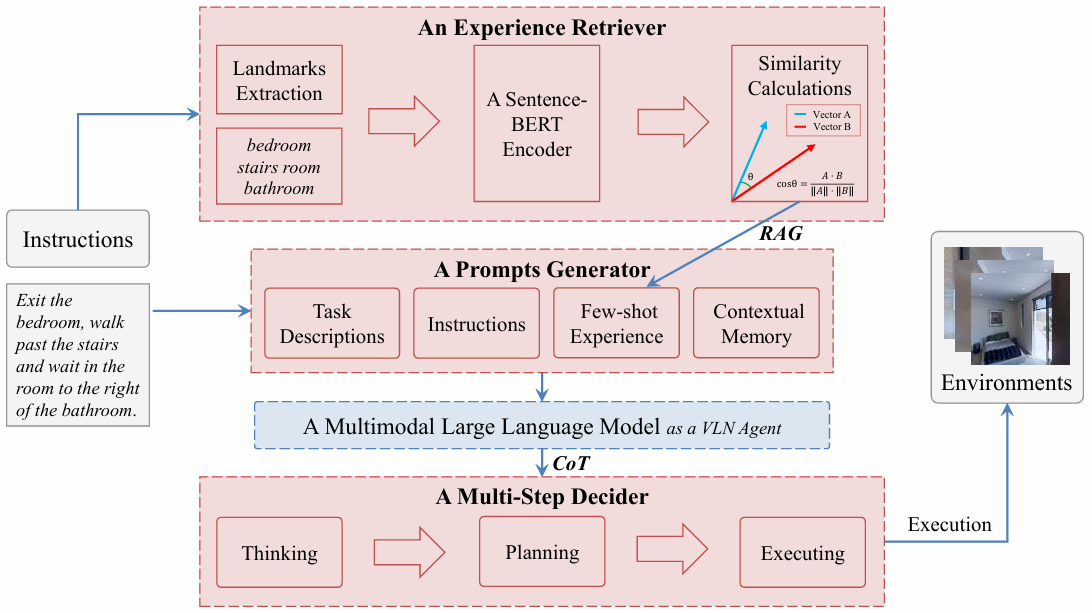
- 经验检索器:基于语义相似性,从经验库中提取与当前任务指令中核心地标特征相同的历史经验,避免因输入过多经验导致的维度爆炸问题。首先利用地标提取器从当前任务指令中提取地标特征,并将其编码为语义向量;然后计算该语义向量与经验库中经验的余弦相似度,选择相似度最高的前 N 条经验构成“少量经验”,注入到推理模块的提示中,帮助智能体参考过去经验做出更合理决策。
- 提示生成器:将任务描述、指令、语言拓扑地图的上下文记忆和少量经验整合为四个关键部分,为每一步决策生成定制化提示,引导智能体的决策过程。
- 多步决策器:基于思维链(CoT)推理,将复杂决策分解为可解释的逐步推理步骤。整个过程分为思考、规划和执行三个阶段。思考阶段智能体综合分析输入信息,生成详细推理步骤确定下一步行动及其依据;规划阶段根据思考结果制定具体路径和行动计划;执行阶段智能体根据规划阶段生成的路径执行具体动作,与环境交互。
反思模块
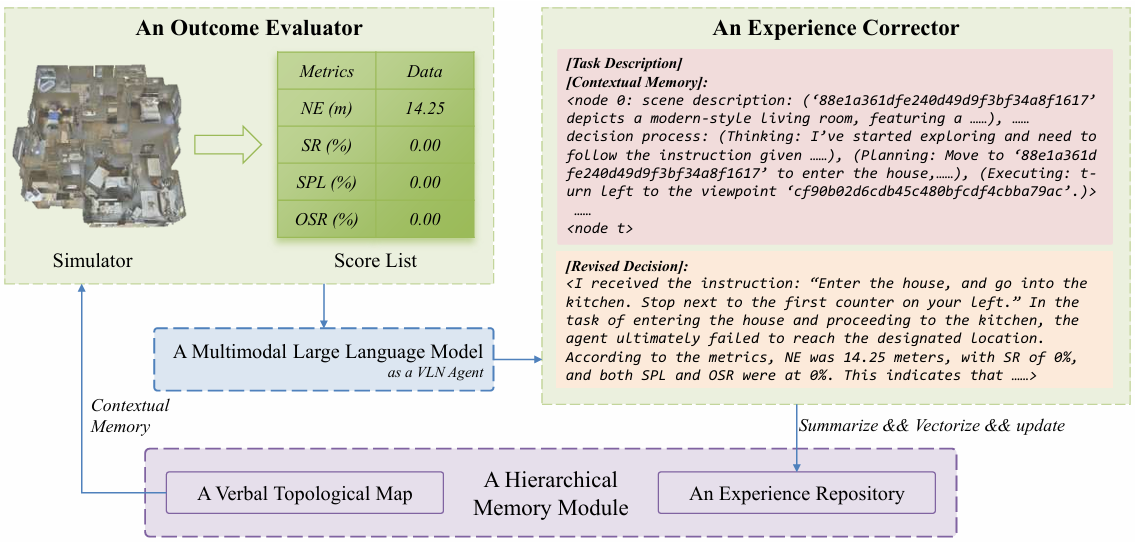
- 结果评估器:使用 MatterPort3D 模拟器提供的真实数据,计算当前导航任务的结果,包括导航误差(NE)、成功率(SR)、路径长度加权成功率(SPL)和最佳成功率(OSR)等指标,为反思模块提供准确的评估结果,帮助智能体识别和纠正不合理决策。
- 经验修正器:利用语言拓扑地图的上下文记忆作为提示,指导 MLLM 分析评估结果,找出不合理决策的原因,并提供正确的决策过程。最后,将地标特征作为键,与上下文记忆和正确决策过程一起形成经验,存入经验库。
实验
数据集
- 使用 R2R 和 REVERIE 数据集进行评估。
- R2R 数据集包含 90 个真实室内环境,涵盖住宅、公寓和办公室,共有 7,189 条轨迹,每条轨迹对应三条细粒度指令,平均指令长度为 29 个单词;
- REVERIE 数据集则增加了定位特定目标对象的任务,更具挑战性,包含 4,140 个目标对象和 21,702 条众包指令,平均指令长度为 18 个单词。
评估指标
采用标准的 VLN 任务评估指标,包括最佳成功率(OSR)、成功率(SR)、路径长度加权成功率(SPL)和导航误差(NE)。
消融实验
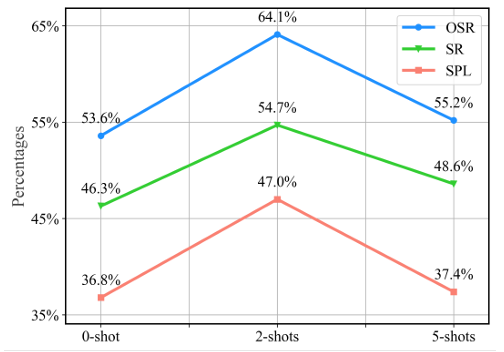
- 不同经验数量的影响:在 R2R 数据集的子样本上进行实验,发现引入 2 条最相似的过去经验时性能最佳,而引入 5 条经验时性能下降,说明增加历史经验并不一定能提升智能体性能,过多经验可能会占用大量上下文窗口,降低 LLM 处理其他相关感知信息的能力,甚至导致决策质量下降。
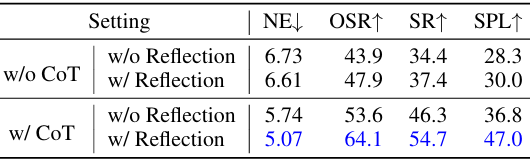
- 多步决策器的影响:基于思维链(CoT)推理的多步决策器对导航性能有显著影响,其与反思模块的协同作用能够显著提升关键性能指标。CoT 通过明确呈现中间推理步骤,增强了 LLM 的推理能力,使其更接近正确答案,并为反思提供了基础,有助于识别和纠正导航过程中的错误或不足,从而提高智能体的导航性能。
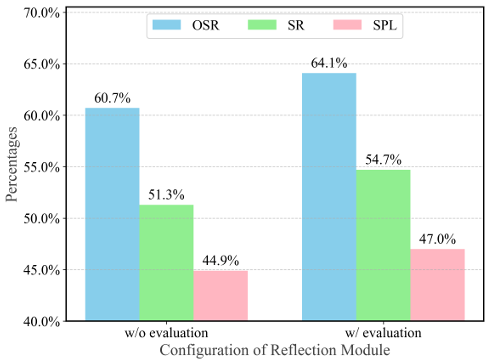
- 结果评估器的影响:引入结果评估器后,导航性能显著提高。即使是最先进的 LLM,也难以在没有额外指导的情况下准确识别错误。结果评估器使反思模块能够基于过去的决策进行更精确、更有针对性的调整和改进,从而增强整个导航系统的有效性。
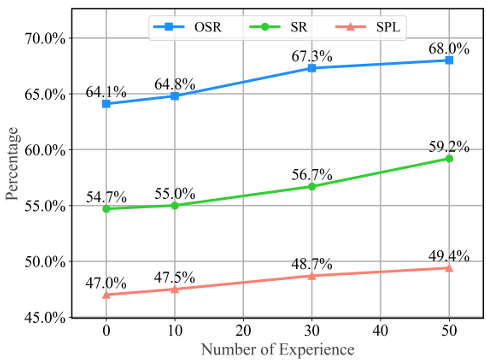
- 自进化能力的评估:随着经验库中经验数量的增加,SE-VLN 的整体性能呈上升趋势,OSR 从 64.1% 提高到 68.0%,SR 和 SPL 也随着经验的增加而提高,表明 SE-VLN 能够有效利用过去的经验实现跨任务的持续进化,逐步提升其导航性能。但随着任务数量的增加,自进化趋势逐渐趋于平缓,这可能是由于 LLM 的推理能力有限,导航经验逐渐趋于同质化。
与现有方法的比较
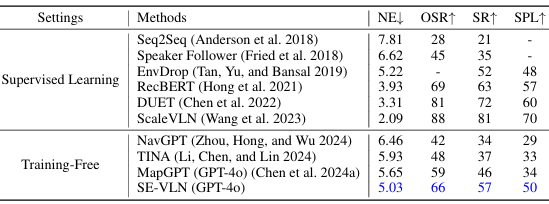
- 将 SE-VLN 与其他现有方法在 R2R 数据集的 72 个场景子样本和更大的验证集上进行比较。
- 结果显示,SE-VLN 在无需大规模数据训练的情况下,显著优于基于 GPT-4o 的 MapGPT 方法,分别在导航误差(NE)、最佳成功率(OSR)、成功率(SR)和路径长度加权成功率(SPL)上分别提高了 0.55 米、12.6%、18.1% 和 24.3%。
- 此外,在包含 11 个场景和 783 条轨迹的更大验证集上,SE-VLN 的性能进一步提升,SR 和 SPL 分别提高了 2.3% 和 3.0%。
- 这表明 SE-VLN 的经验库机制能够有效捕获跨任务的决策逻辑,当新任务中存在与经验库中相似的任务模式时,智能体可以快速迁移和重用相关经验,从而抵消由于分布差异导致的性能损失。
结论与未来工作
- 结论:
- 本文提出的基于多模态大语言模型(MLLM)的自进化视觉语言导航(VLN)框架(SE-VLN)通过模拟自然智能体的进化过程,实现了无需大规模标注数据训练的自进化能力。
- SE-VLN 通过持续积累和重用经验,展现出卓越的自进化能力,并在多个数据集上取得了最先进的性能。
- 未来工作:
- 计划探索引入多智能体协作推理方法,以促进自进化 VLN 在各个领域的应用。
