论文略读:Are Large Language Models In-Context Graph Learners?
arxiv 202502
- LLMs 在图数据上的效果不佳
将图结构转化为语义提示(即图 tokenization)会丢失关键的结构信息
- 节点与边之间的内在关系和依赖性,需要对空间结构和关系结构有更深入的理解,仅靠文本编码无法充分表达
- 尽管 LLMs 在非结构化任务中表现出色,但若未经微调,它们在图学习方面仍无法达到专门模型(如图神经网络 GNN)的效果。
- 在图数据方面,消息传递型图神经网络(简称 GNN) 是目前最有效的工具之一
- 它们通过从上下文中归纳地传播和聚合信息来进行学习,这一过程在概念上与 in-context learning 十分类似
- 尽管 LLMs 擅长理解上下文并处理非结构化数据,但它们是否能在图结构数据上实现 in-context 学习仍是一个开放问题。
- 论文研究了 LLM 在图数据上的 in-context 学习能力
- 初步结果显示:LLMs 并不擅长在图数据上进行 in-context 学习。即使是最先进的 LLMs,在节点分类任务中的表现也不如 GNN
- 与此同时,论文发现,GNN 的消息传递机制可以被解释为一种递归的 RAG 步骤,它对每个节点及其图上下文执行查询
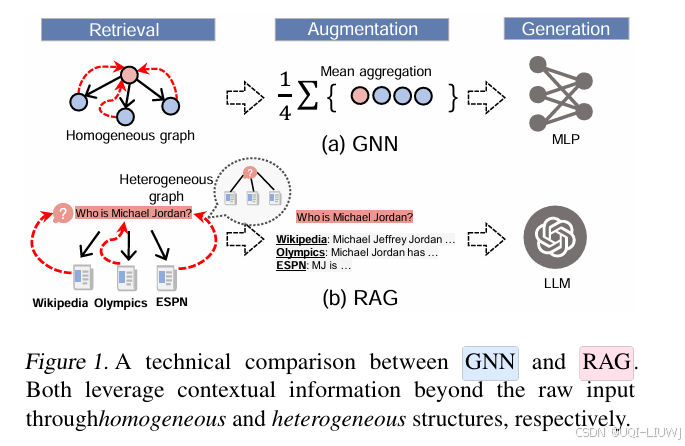
- ——>提出了一系列 基于 RAG 的图学习框架 —— QUERYRAG、LABELRAG 和 FEWSHOTRAG
- 利用图结构本身作为上下文来增强 LLM 的 in-context 学习能力
与标准 RAG 需要外部检索机制不同,该方法通过图的本地邻域结构内生地检索相关上下文。
QUERYRAG:从邻居节点检索特征;
LABELRAG:检索邻居的标签;
FEWSHOTRAG:检索邻居的特征和对应的标签
