MySQL索引:7大类型+4维分类
索引是数据库高效查询的基石。理解MySQL的索引类型及其适用场景,是优化数据库性能的关键一步。本文将系统剖析MySQL支持的7大索引类型,结合底层原理、使用示例和选型建议,助你彻底掌握索引设计精髓。
一、索引分类全景图
MySQL索引可按不同维度分类:
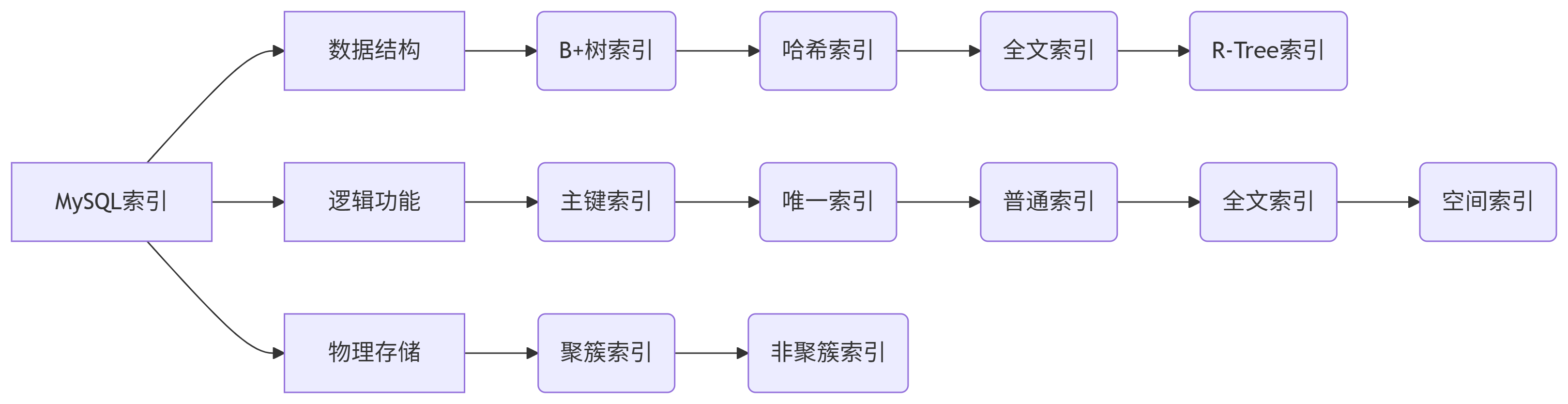
二、按数据结构分类(核心维度)
1. B+树索引(默认索引类型)
-
适用引擎:InnoDB、MyISAM、Memory
-
数据结构:多路平衡搜索树
-
核心特点:
-
叶子节点存储完整数据记录(InnoDB聚簇索引)或主键+指针(非聚簇索引)
-
叶子节点形成双向链表,支持高效范围查询
-
非叶子节点仅存储索引键值,降低树高度
-
-
适用场景:
-
等值查询(
=) -
范围查询(
>,<,BETWEEN) -
排序(
ORDER BY) -
分组(
GROUP BY)
-
-
示例:
-- 创建B+树索引 CREATE INDEX idx_name ON users(name);
2. 哈希索引
-
适用引擎:Memory引擎(InnoDB支持自适应哈希,但用户不可控)
-
数据结构:哈希表(数组+链表)
-
核心特点:
-
精确匹配极快(O(1)时间复杂度)
-
不支持范围查询、排序
-
存在哈希冲突问题
-
-
适用场景:
-
等值查询(
=) -
内存表快速查找
-
-
示例:
-- 创建内存表并添加哈希索引 CREATE TABLE temp_table (id INT, data VARCHAR(100),INDEX USING HASH (id) ) ENGINE=MEMORY;
3. 全文索引(FULLTEXT)
-
适用引擎:InnoDB(5.6+)、MyISAM
-
数据结构:倒排索引(Inverted Index)
-
核心特点:
-
对文本内容进行分词索引
-
支持自然语言搜索(
MATCH() AGAINST()) -
默认忽略停用词(the, is 等)
-
-
适用场景:
-
文本内容搜索(文章、日志)
-
替代低效的
LIKE '%keyword%'
-
-
示例:
-- 添加全文索引 ALTER TABLE articles ADD FULLTEXT ft_index (title, content);-- 全文搜索查询 SELECT * FROM articles WHERE MATCH(title, content) AGAINST('+MySQL -Oracle' IN BOOLEAN MODE);
4. R-Tree索引(空间索引)
-
适用引擎:MyISAM、InnoDB(5.7+)
-
数据结构:R树(多维平衡树)
-
核心特点:
-
专为地理空间数据设计
-
支持空间关系函数(
ST_Contains(),ST_Distance())
-
-
适用场景:
-
GIS地理坐标查询
-
地图应用(查找附近地点)
-
-
示例:
-- 创建空间索引 CREATE TABLE locations (id INT PRIMARY KEY,position POINT NOT NULL,SPATIAL INDEX(position) );-- 查询圆形区域内的点 SELECT * FROM locations WHERE ST_Contains(ST_Buffer(ST_GeomFromText('POINT(116.4 39.9)'), 0.1),position );
三、按逻辑功能分类
1. 主键索引(PRIMARY KEY)
-
特点:
-
唯一标识记录,不允许NULL值
-
InnoDB中必定是聚簇索引
-
自动创建且唯一
-
-
创建方式:
CREATE TABLE users (id INT AUTO_INCREMENT PRIMARY KEY -- 列级定义 );-- 或表级定义 ALTER TABLE users ADD PRIMARY KEY (id);
2. 唯一索引(UNIQUE)
-
特点:
-
保证列值唯一性,允许NULL值
-
可用于外键约束
-
-
与主键区别:
-
一个表只能有一个主键,但可有多个唯一索引
-
主键不能为NULL,唯一索引可以
-
-
示例:
CREATE UNIQUE INDEX uq_email ON users(email);
3. 普通索引(INDEX / KEY)
-
特点:
-
最基本的索引类型,无唯一性约束
-
纯粹加速查询
-
-
创建方式:
CREATE INDEX idx_age ON users(age);
4. 前缀索引(Prefix Index)
-
特点:
-
对文本列前N个字符建立索引
-
大幅减少索引空间
-
-
最佳实践:
-
计算选择性:
COUNT(DISTINCT LEFT(column, n)) / COUNT(*) -
选择使选择性 > 0.95 的最小长度
-
-
示例:
-- 对address列前10字符建索引 CREATE INDEX idx_addr_prefix ON users(address(10));
四、按物理存储分类(InnoDB核心机制)
1. 聚簇索引(Clustered Index)
-
特点:
-
数据行与索引存储在一起(索引即数据)
-
InnoDB中主键索引即聚簇索引
-
若未定义主键,自动选择第一个UNIQUE索引或生成隐藏ROW_ID
-
-
优势:
-
范围查询快(数据物理有序)
-
避免二次回表查询
-
-
缺点:
-
插入速度依赖插入顺序
-
更新主键代价高
-
2. 非聚簇索引(二级索引 / Secondary Index)
-
特点:
-
叶子节点存储主键值(非数据行指针)
-
查询需回表:通过主键值到聚簇索引中查找数据
-
-
包含列优化:
-- 创建覆盖索引(避免回表) CREATE INDEX idx_cover ON orders(user_id, amount); -- 查询只需访问索引 SELECT amount FROM orders WHERE user_id = 1001;
五、高级索引类型
1. 组合索引(Composite Index)
-
特点:
-
在多个列上建立的B+树索引
-
遵循最左前缀原则
-
-
最佳实践:
-
高频查询条件放左侧
-
避免冗余索引(
(a,b)已包含(a))
-
-
示例:
-- 联合索引 CREATE INDEX idx_name_phone ON contacts(last_name, first_name, phone);-- 有效查询(使用索引) SELECT * FROM contacts WHERE last_name = 'Wang' AND first_name = 'Lei';-- 无效查询(跳过左列) SELECT * FROM contacts WHERE first_name = 'Lei';
2. 覆盖索引(Covering Index)
-
特点:
-
索引包含查询所需全部字段
-
避免回表操作,性能提升显著
-
-
实现方式:
-- 创建包含额外列的索引 CREATE INDEX idx_cover ON sales(product_id, quantity, sale_date);-- 覆盖查询 SELECT product_id, quantity FROM sales WHERE sale_date BETWEEN '2023-01-01' AND '2023-12-31';
3. 函数索引(MySQL 8.0+)
-
特点:
-
对表达式计算结果建立索引
-
解决WHERE条件中函数导致的索引失效
-
-
示例:
-- 对JSON字段建函数索引 CREATE TABLE products (id INT PRIMARY KEY,specs JSON,INDEX idx_spec_weight ((CAST(specs->'$.weight' AS UNSIGNED))) );-- 使用索引查询 SELECT * FROM products WHERE CAST(specs->'$.weight' AS UNSIGNED) > 10;
六、索引选择决策树
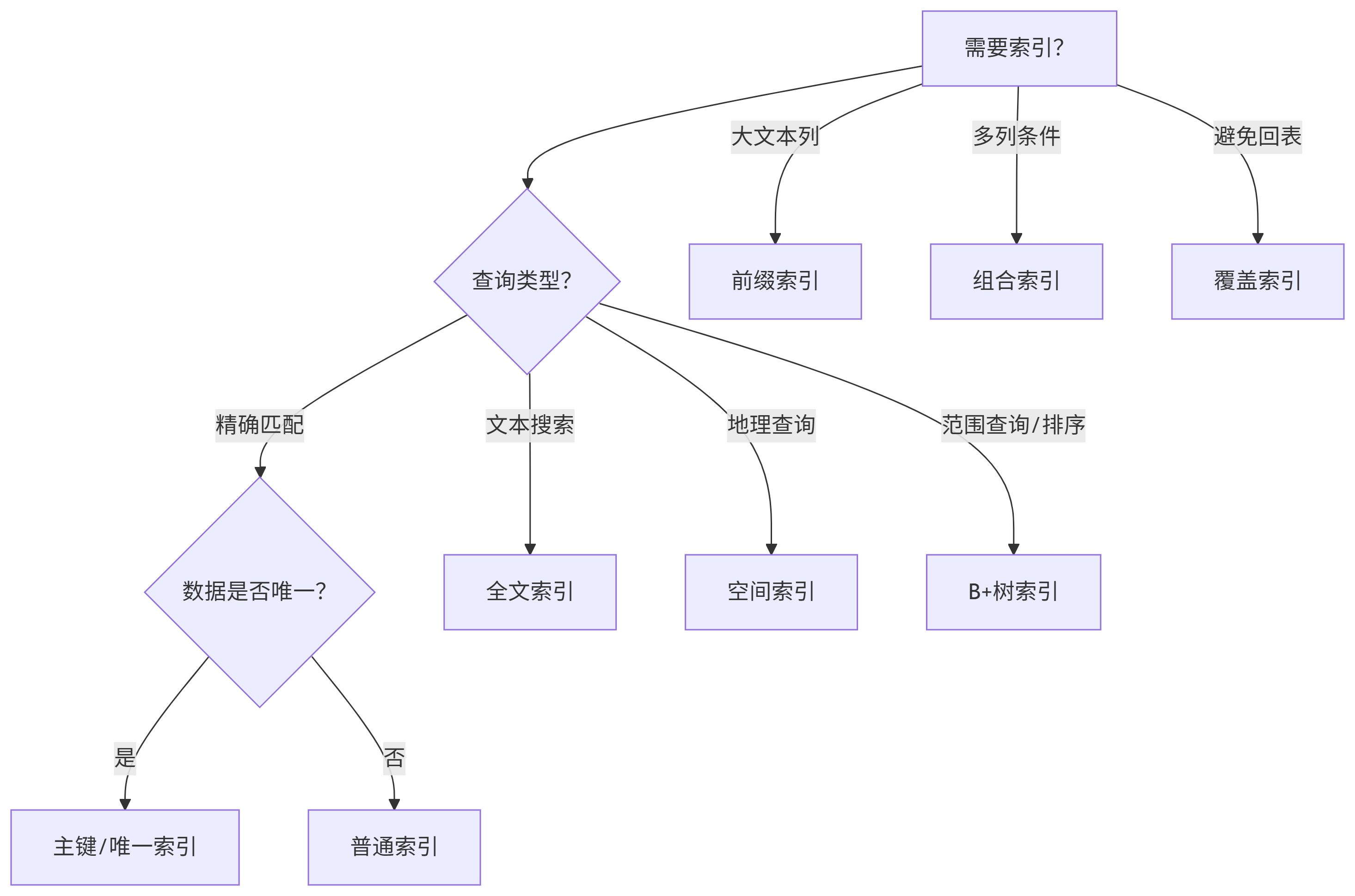
七、实战建议与避坑指南
-
索引不是越多越好
-
每个索引增加写操作成本(Insert/Update/Delete)
-
建议单表索引不超过5个
-
-
优先考虑选择性高的列
-
公式:
选择性 = COUNT(DISTINCT col) / COUNT(*) -
值越接近1,索引效果越好
-
-
避免索引失效场景
-
函数操作:
WHERE YEAR(create_time)=2023❌ -
隐式类型转换:
WHERE phone=13800138000(phone为varchar)❌ -
前导通配符:
WHERE name LIKE '%Lee'❌
-
-
监控索引使用率
-- 查看未使用的索引 SELECT * FROM sys.schema_unused_indexes;-- 索引使用统计 SHOW INDEX FROM table_name;