召回增强RAPTOR策略
原文地址: https://arxiv.org/pdf/2401.18059
参考:https://baoyu.io/translations/ai-paper/2401.18059-raptor-recursive-abstractive-processing-for-tree-organized-retrieval?utm_source=chatgpt.com
摘要
检索增强语言模型(Retrieval-Augmented Language Models)能够更好地适应世界状态的变化,并整合长尾知识。然而,大多数现有方法仅从检索语料库中检索短的连续文本块,限制了对整个文档上下文的整体理解。我们引入了一种新颖的方法,通过递归地嵌入、聚类和总结文本块,从底层向上构建具有不同摘要级别的树。在推理时,我们的 RAPTOR 模型从这棵树中检索,在不同抽象级别整合冗长文档中的信息。 对照实验表明,在多个任务上,递归摘要检索比传统检索增强型语言模型有显著改进。在涉及复杂、多步骤推理的问答任务中,我们展示了最先进的结果;例如,通过将 RAPTOR 检索与 GPT-4 结合使用,我们可以将 QuALITY 基准的最佳性能绝对准确率提高 20%。
1、引言
大型语言模型(LLMs)已成为推动技术变革的重要工具,在许多任务上表现出色。随着 LLM 的规模不断增长,它们可以作为非常有效的知识存储体,其参数中编码了大量事实(Petroni 等,2019;Jiang 等,2020;Talmor 等,2020;Rae 等,2021;Hoffmann 等,2022;Chowdhery 等,2022;Bubeck 等,2023;Kandpal 等,2023),并且可以通过在下游任务上的微调进一步提升性能(Roberts 等,2020)。然而,即使是大型模型,对于特定任务也可能缺乏足够的领域知识,而且世界持续变化,可能使得 LLM 中的事实失效。通过额外的微调或编辑来更新这些模型的知识是困难的,特别是在处理庞大的文本语料库时(Lewis 等,2020;Mitchell 等,2022)。一种替代方法是在开放域问答系统中开创的(Chen 等,2017;Yu 等,2018),即在一个单独的信息检索系统中索引大量文本,在将其分割成块(段落)后。然后,将检索到的信息与问题一起作为上下文提供给 LLM(“检索增强”,Lewis 等,2020;Izacard 等,2022;Min 等,2023;Ram 等,2023),使得系统可以轻松提供特定领域的最新知识,并实现易于解释和溯源的能力,而 LLM 的参数知识是难以追溯其来源的(Akyurek 等,2022)。
然而,现有的检索增强方法也存在缺陷。我们要解决的问题是,大多数现有方法仅检索少量短的连续文本块,这限制了它们表示和利用大规模话语结构的能力。这对于需要整合文本多个部分知识的主题性问题尤为重要,例如理解整本书的内容,如 NarrativeQA 数据集(Kočiskỳ 等人,2018)中的情况。以“灰姑娘”的童话故事为例,问题“灰姑娘是如何获得幸福结局的?”中,检索到的前 k 个短的连续文本可能无法提供足够的上下文来回答问题。
为了解决这个问题,我们设计了一个索引和检索系统,使用树结构来捕捉文本的高层次和低层次细节。如图 1 所示,我们的系统 RAPTOR 对文本块进行聚类,生成这些聚类的文本摘要,然后重复此过程,从底层向上构建树。这种结构使 RAPTOR 能够将代表文本不同层次的块加载到 LLM 的上下文中,从而能够有效地回答不同层次的问题。
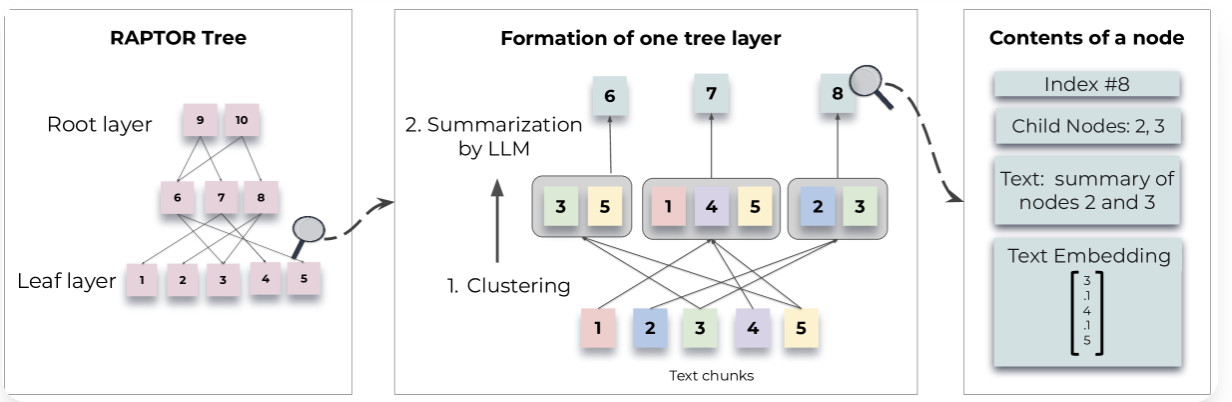
图 1: 构建知识树的过程:RAPTOR 通过分析文本块的深层含义,将它们归为一类,并为每一类生成简要概述,由此自下而上地构建出一棵知识树。归为一类的信息点成为兄弟节点;而每个父节点则包含了这一类信息的总结。
2、方法
2.1 文本块的嵌入和聚类
我们首先将文档分割成较小的文本块(例如段落或句子),然后使用预训练的语言模型(如 BERT)将每个文本块转换为向量表示。接下来,根据这些向量的相似性,将相似的文本块聚集在一起,形成一个个“簇”。
2.2 摘要生成与树结构构建
对于每个聚类,我们使用抽象式摘要模型生成一个简洁的摘要,代表该聚类的主要内容。然后,将这些摘要作为新的文本块,重复聚类和摘要生成的过程,逐层向上,直到形成一个树状结构的摘要层次。底层节点包含原始文本块,越往上层,信息越抽象,直到根节点代表整个文档的高层摘要。
3、实验与结果
我们在多个问答任务上进行了对比实验,验证了 RAPTOR 的有效性。实验结果表明,RAPTOR 在处理需要多步推理的复杂问题上表现突出。例如,在 QuALITY 基准测试中,结合 GPT-4 的 RAPTOR 模型将准确率提升了 20%。
4、讨论与未来工作
RAPTOR 提供了一种创新的方式,使语言模型在处理长文档和复杂问题时更加高效和准确。然而,在实际应用中,RAPTOR 可能面临一些挑战,如计算资源需求、索引构建时间、更新和维护等。此外,摘要质量、查询效率和多模态数据处理等方面也需要进一步研究和优化。未来的工作将致力于解决这些挑战,并探索 RAPTOR 在更多领域的应用。