C++进阶--C++11(03)
文章目录
- C++进阶--C++11(03)
- 可变参数模版
- 基本语法及其原理
- 参数包的解析问题
- emplace系列-效率问题
- 新的类功能
- 默认的移动构造和移动赋值
- 关键字default和delete
- STL容器变化
- 总结
- 结语
很高兴和大家见面,给生活加点impetus!!开启今天的编程之路!!
作者:٩( ‘ω’ )و260
我的专栏:Linux,C++进阶,C++初阶,数据结构初阶,题海探骊,c语言
欢迎点赞,关注!!

C++进阶–C++11(03)
可变参数模版
首先可变参数的问题,其实在c语言就有涉及,c语言中的printf函数中,就有类似表达

因为格式化打印是可以传递任意多个参数的,但是具体传递参数的个数需要由用户端来决定。所以这里可以理解为一个参数的集合,即参数包。
那么printf的底层是什么呢?
printf打印底层:底层开辟一个二维数组,对象存到二维数组中,然后取出对象,再来按照对应的格式打印。。
基本语法及其原理
1:C++11支持了可变参数模版,这个模版的参数个数和参数类型都可变的。即模版参数类型可能有多个,和模版参数实例化的对象可能有多个。前者被称为模版参数包,后者被称为函数参数包
我们来看基本语法格式:
template<class ... Args>
void Print(Args ...args) {}//普通函数template<class ... Args>
void Print(Args& ...args) {}//左值引用template<class ... Args>
void Print(Args&& ...args) {}//右值引用
这里的语法设置需要记忆:主要是三个点的顺序。
在模版参数列表中,三个点的位置是在class后面,模版参数的前面
在函数参数列表中,三个点的位置是在模版参数后面,对象前面
在函数体中,三个点的位置是在对象后面,这点后面会有体现。
2:在可变参数模版中,仍然是一个模版,我们使用了…(三个点)表示一个包,在模版参数列表中,使用class或者typename表示接下来的0个或多个参数类型,在函数参数列表中,类型名后跟…(三个点)表示0个或多个形参对象,函数参数包可以使用引用表示,可以使普通模版的形式,也可以使用左值引用,右值引用(万能引用)。但其实我们使用比较多的是万能引用,因为既能够减少拷贝次数,而且能够同时对左值和右值进行操作
3:可变参数模版和普通模版类似,还是在编译阶段的时候去推导对应参数类型和个数的多个函数。
sizeof…()的作用:能够推导参数包的个数

其实上述代码本质上推导的结果是这个:

参数包的解析问题
如果我们想要打印参数包的内容,也许你会想到,既然都是一个参数包,都是一个包了,应该使用数组存储的吧,而且printf的底层也是数组,这样类比过来,应该会使用一个数组来存储参数包的内容。
来看结果:
template<class ... Args>
void Print(Args&& ...args)
{cout << sizeof...(args) << endl;for (int i = 0; i < sizeof...(args); i++){cout << args[i] << endl;}
}
int main()
{Print(1, "111111", string("22222"));return 0;
}

其实不是的,可变参数模版底层其实是通过模版展开的。
那么我们该如何来打印呢?
void showlist()
{cout << endl;
}
template<class T, class ...Args>
void showlist(T x, Args ...args)
{cout << x << endl;showlist(args...);
}
template<class ... Args>
void Print(Args&& ...args)
{cout << sizeof...(args) << endl;showlist(args...);
}
int main()
{Print(1, "111111", string("22222"));return 0;
}
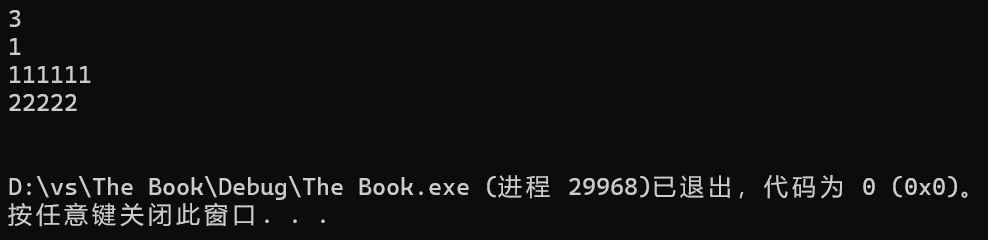
那这里是如何进行的呢?
这里你可以理解为是一个类似递归的形式,只不过是通过参数包来进行推导的不同函数,但是函数递归是同一个函数,这里是不同函数。
首先先来理解,既然你是递归,那就有递归出口,为什么你要把出口重新设计为一个函数而不是设计为一个判断条件呢?
因为我们模版是在编译时就推导好的,本质上编译器还是调用对应的函数。但是if判断条件的逻辑是在运行是决定的,即如果不写函数来决定递归出口而写if判断来决定递归出口,会报错未找到对应的重载函数

那这里的底层是怎样的呢?
这里我们首先先传递showlist一个三个参数的参数包过去,其中第一个参数给到x,其他剩余的参数给到参数包args,第一次showlist总共有三个参数个数;再传递给showlist两个参数,其中第一个参数给到x,剩余的一个参数传递给参数包args,第二次showlist总共有两个参数个数;以此类推,直到参数个数是0。
因为showlist至少都需要一个参数(因为参数包的个数可以是0个),所以当没有参数的时候,需要重新写一个函数来停止类递归。
我们来看底层编译器推导过后的代码:
void showlist4()
{cout << endl;
}
void showlist3(string x)
{cout << x << endl;showlist4();
}
void showlist2( const char* x, string x3)
{cout << x << endl;showlist3(x3);
}
void showlist1(int x, const char*x2,string x3)
{cout << x << endl;showlist2(x2,x3);
}
void Print(int x1, const char*x2,string x3)
{showlist1(x1,x2,x3);
}
int main()
{Print(1, "111111", string("22222"));return 0;
}
我们能够发现,其实特别类似递归的逻辑,但是每次调用的不是一个相同的函数(函数的参数个数和类型不同),其实就是辛苦了编译器。
上述我的所讲述的其实就是包扩展的一种,是不是感觉特别繁琐,在c++17中,其实还有一种更加简洁的包扩展,这个我们以后再来讲解。
emplace系列-效率问题
在c++11中新增了emplace的接口,这种接口主要是在一些场景下,提高了对于插入操作的效率。
emplace其实也是一个可变参数模版。


那么都是插入接口,在哪些特定的场景下emplace会更胜一筹呢?
首先两种插入的区别:
emplace是一个模版,是在函数传递实参的时候才会去推导模版参数列表的,push_back是一个普通函数,其中的value_type是在类的实例化就进行了的。
我们直接来说明结论:
emplace效率比普通插入更高的情景:传参传的是构造底层对象的参数值时
为什么呢?假设我现在有一个list<pair<string,int>> ls;这个ls对象底层结点中存储的是pair<string,int>,如果我们这样传参:
ls.push_back({"111111",1});
//ls.emplace_back({"111111",1});//这种写法是不行的。
ls.emplace_back("111111",1);
首先push_back中的value_type在实例化对象的时候已经确定为pair<string,int>,但是我们传递的不是pair,此时会进行隐式类型转化,生成一个临时对象,先构造这个临时对象,临时对象是右值,调用移动构造构造结点中的对象。最后将临时对象析构。总体的调用过程是:构造->移动构造(左值的话就是拷贝构造)->析构
其次,emplace_back是在参数传递的过程中是分根据传递的实参推导模版的类型的。在这里,会推导一个const char*类型的参数和一个int类型的参数。这个参数会作为参数包向下传递,直到传递到构造对象的时候,会使用参数包的内容来对对象进行直接构造。总体调用的过程是:构造
这两种情况的差别就是一种其实是使用的临时对象来构造的,另一种是通过直接构造,那么我们怎么辨别呢?我们就看value_type的推导结果和可变参数模版的推导结果是否相同就行。
这里还有一个细节:为什么第二种写法是不行的呢?
首先,在c++中{}会直接识别为initializer_list,在c++11中这是一个类,其中存的数据必须是同一个类型的。所以我们不用{}将值给括起来。而是将每个值作为参数包中的内容去构造对象,如果参数包的内容无法满足对象需要的内容,直接报错</:font>,就比如这里我传递:
ls.emplace_back(1,1);
总结:emplace系列接口如果传递构造底层对象的参数值的时候,效率更高,可以使用这个。
新的类功能
默认的移动构造和移动赋值
在c++11之后,类的默认成员函数就会多添加2个,分别是默认的移动构造和移动赋值。
如果你默认没有实现移动构造函数,而且也没有实现析构,拷贝构造,赋值重载,那么编译器会默认自动生成一个移动构造函数。对内置类型实现值拷贝(浅拷贝),对自定义类型调用自定义类型的移动构造,自定义类型没有实现的话就调用拷贝构造。
为什么是没有实现移动构造且没有实现析构,拷贝构造,赋值重载呢?
首先移动构造是有资源的时候才会使用,也是类似于析构,拷贝,赋值,有资源的时候这三个都是必须同时写的。没有的话就相当于里面没有资源。没资源的话不管怎样都是不可能使用移动构造的。
移动赋值也是如此,没有实现移动赋值且没有实现析构,拷贝构造,赋值重载,那么编译器会默认自动生成一个移动构造函数,对内置类型实现值拷贝(浅拷贝),自定义类型调用自定义类型的移动赋值,没有的话调用拷贝赋值。
如果你提供了移动构造或者移动赋值,编译器不会自动提供拷贝构造和拷贝赋值。
关键字default和delete
假设你要使用某个默认的函数,但是因为一些原因这个函数没有默认生成,比如你实现了拷贝构造,此时编译器就不会实现移动构造了,但是如果使用default关键字可以是移动构造强制生成,使用delete关键字强制删除。
来看下列代码:
class Person
{Person(string name,int age):_name(name),_age(age){}Person(const Person& p){}Person(Person&& p) = default;//强制生成移动构造//Person(const Person& p) = delete;//使用关键字delete强制删除
private:stirng _name;int _age;
}
delete关键字与default关键字截然相反,其实在c++98中不让某一个默认成员函数生成的方法是:将这个默认成员函数在类中私有声明
为什么是私有?因为我只是声明,如果设置成公有的话可能造成用户在类外直接定义,声明的话就是向编译器承诺,我自己实现了这个函数,你就不用再默认生成了。
STL容器变化
在stl容器中,最有用的就是unordered系列了,因为底层是哈希表,而且效率也还不错。其次就是插入接口增加了左值右值插入,emplace插入,initializer_list类,最后就是范围for,这些在前面都已经提到过了。
总结
今天学习了可变参数模版基本定义,包扩展的语法形式,从基本语法,细节(三个点的位置),应用emplace系列(效率问题,与普通插入接口的区别,底层是怎样的,如何辨别(模版参数推导的是否相同)),c++11类的新改动。默认成员函数与两个关键字。
结语
感谢大家阅读我的文章,不足之处欢迎留言指出,感谢大家支持!!
学而不思则罔,思而不学则殆!!